


awk&sed!!!
awk&sed!!!awk&sed!!!awk&sed!!!awk&sed!!!
http://bbs.chinaunix.net/thread-702042-1-1.html
| 我觉着,如果是按行操作,就统统都用 sed 如果是不仅按行,还要按列操作,就统统都用 awk |
原帖由 jixunuli 于 2006-2-17 10:54 发表 对,waker 版主举的就是一个例子。 他那个问题用 sed 很容易解决,但是用 awk 就比较费劲。 其实这也就是我学习 Perl 的原因, shell 下工具众多,功能也互相重复, 最头疼的是,这些重复部分的语法还各不相同,(比如 grep awk sed 都有正则表达式匹配的功能,但是三者的正则表达式语法就不相同) 最最最头疼的是,每个工具还分 GNU 版和不是 GNU 版,之间的差别也很大, 最最最最最头疼的是,即使都是 GNU 版,那么版本号的细微差别也会带来很多差别。 但是,用 Perl 做这些事,统统都能办到,而且统统都不太复杂。 |
| 普通的行处理任务用sed很好,因为命令很简洁。 awk最好的部分是它按“列”或“字段”处理的方式和“关联数组”,但awk对正则表达式支持的程度比sed要差些,例如sub/gsub中不能用\1, \2这样的向前引用。gsed中的gensub是可以的,但必须写成\\1, \\2。 perl应该说结合了sed/awk的优点,尤其是强大的正则表达式是我的最爱。^_^不过据说有的unix平台下缺省没有安装。 有时间的话都学学吧。 |
awk&sed!!!awk&sed!!!awk&sed!!!awk&sed!!!
http://blog.jobbole.com/31026/
Sed&awk笔记之sed篇:简单介绍
最近在阅读《sed & awk(第二版)》,这本书是sed和awk相关书籍中比较经典的一本。我在读书的时候有一个习惯,就是会作一些笔记,如果有条件我会放到博客中。写博客不仅是给别人看的,更是写给自己看的,同时因为写给别人看,所以必然会在一些细节的地方写得很清楚明了,可以加深自己对原书的理解,同时以后回头看的时候,我自己也能快速的回忆起来。
另外一方面,我会选择英文原版来阅读而非中文翻译版,主要是出于英文版的内容更加准确、容易领会作者的本意这个方面的原因。毕竟翻译的内容一方面因为翻译的时候会丢失一些原版的意思,同时因为不同的人有不同的理解,在翻译中可能会夹杂着自己个人的理解。就好比这一系列的文章,许多内容都是出自原书,我只不过是翻译了些内容加了点注解而已,所心也只能称之为笔记。
文中对一些术语的翻译只是按本人自己的喜好而定,请见谅。
本系列包含两部分的内容:sed篇和awk篇。
sed篇总共分成6章:
awk篇暂时还未计划。
Sed是什么
《sed and awk》一书中(1.2 A Stream Editor)是这样解释的:
Sed is a “non-interactive” stream-oriented editor. It is stream-oriented because, like many UNIX
programs, input flows through the program and is directed to standard output.
Sed本质上是一个编辑器,但是它是非交互式的,这点与VIM不同;同时它又是面向字符流的,输入的字符流经过Sed的处理后输出。这两个特性使得Sed成为命令行下面非常有用的一个处理工具。
如果对sed的历史有兴趣,可以看书中2.1节”Awk, by Sed and Grep, out of Ed”,这里就不多介绍。
基本概念
sed命令的语法如下所示:
|
1
|
sed [options] script filename |
同大多数Linux命令一样,sed也是从stdin中读取输入,并且将输出写到stdout,但是当filename被指定时,则会从指定的文件中获取输入,输出可以重定向到文件中,但是需要注意的是,该文件绝对不能与输入的文件相同。
options是指sed的命令行参数,这一块并不是重点,参数也不多。
script是指需要对输入执行的一个或者多个操作指令(instruction),sed会依次读取输入文件的每一行到缓存中并应用script中指定的操作指令,因此而带来的变化并不会影响最初的文件(注:如果使用sed时指定-i参数则会影响最初的文件)。如果操作指令很多,为了不影响可读性,可以将其写到文件中,并通过-f参数指定scriptfile:
|
1
|
sed -f scriptfile filename |
这里有一个建议,在命令行中指定的操作指令最好用单引号引起来,这样可以避免shell对特殊字符的处理(如空格、$等,关于这一点可以参考简洁的Bash编程技巧续篇 – 9. 引号之间的区别)。这个建议同样适用grep/awk等命令,当然如果有时候确实不适合使用单引号时,记得对特殊字符转义。
无论是将操作指令通过命令行指定,还是写入到文件中作为一个sed脚本,必须包含至少一个指令,否则用sed就没有意义了。一般会同时指定多个操作指令,这时候指令之间的顺序就显得非常重要。而你的脑海中必须有这么一个概念,即每个指令应用后,当前输入的行会变成什么样子。要做到这一点首先必须要了解sed的工作原理,要做到“知其然,且知其所以然”。
每条操作指令由pattern和procedure两部分组成,pattern一般是用’/'分隔的正则表达式(在sed中也有可能是行号,具体参见Sed命令地址匹配问题总结),而procedure则是一连串编辑命令(action)。
sed的处理流程,简化后是这样的:
1.读入新的一行内容到缓存空间;
2.从指定的操作指令中取出第一条指令,判断是否匹配pattern;
3.如果不匹配,则忽略后续的编辑命令,回到第2步继续取出下一条指令;
4.如果匹配,则针对缓存的行执行后续的编辑命令;完成后,回到第2步继续取出下一条指令;
5.当所有指令都应用之后,输出缓存行的内容;回到第1步继续读入下一行内容;
6.当所有行都处理完之后,结束;
具体流程见下图:
简单例子
概念如果脱离实际的例子就会显得非常枯燥无趣,这本书在这一点上处理得很好,都是配上实际的例子来讲解的。不过有点遗憾的是,书中的例子大多是与troff macro有关的,我们很难有条件来实际测试例子,在笔记中我会尽量使用更加浅显易懂的例子来说明。
下面是摘自书中的一个例子,假设有个文件list:
|
1
2
3
4
5
6
7
8
|
John Daggett, 341 King Road, Plymouth MAAlice Ford, 22 East Broadway, Richmond VAOrville Thomas, 11345 Oak Bridge Road, Tulsa OKTerry Kalkas, 402 Lans Road, Beaver Falls PAEric Adams, 20 Post Road, Sudbury MAHubert Sims, 328A Brook Road, Roanoke VAAmy Wilde, 334 Bayshore Pkwy, Mountain View CASal Carpenter, 73 6th Street, Boston MA |
这个例子中用到的知识点都会在后文中介绍,你可以先知道有这个东西就行。
假如,现在打算将MA替换成Massachusetts,可以使用替换命令s:
|
1
2
3
4
5
6
7
8
9
|
$ sed -e 's/MA/Massachusetts/' listJohn Daggett, 341 King Road, Plymouth MassachusettsAlice Ford, 22 East Broadway, Richmond VAOrville Thomas, 11345 Oak Bridge Road, Tulsa OKTerry Kalkas, 402 Lans Road, Beaver Falls PAEric Adams, 20 Post Road, Sudbury MassachusettsHubert Sims, 328A Brook Road, Roanoke VAAmy Wilde, 334 Bayshore Pkwy, Mountain View CASal Carpenter, 73 6th Street, Boston Massachusetts |
这里面的-e选项是可选的,这个参数只是在命令行中同时指定多个操作指令时才需要用到,如:
|
1
2
3
4
5
6
7
8
9
|
$ sed -e 's/ MA/, Massachusetts/' -e 's/ PA/, Pennsylvania/' list John Daggett, 341 King Road, Plymouth, MassachusettsAlice Ford, 22 East Broadway, Richmond VAOrville Thomas, 11345 Oak Bridge Road, Tulsa OKTerry Kalkas, 402 Lans Road, Beaver Falls, PennsylvaniaEric Adams, 20 Post Road, Sudbury, MassachusettsHubert Sims, 328A Brook Road, Roanoke VAAmy Wilde, 334 Bayshore Pkwy, Mountain View CASal Carpenter, 73 6th Street, Boston, Massachusetts |
即使在多个操作指令的情况下,-e参数也不是必需的,我一般不会加-e参数,比如上面的例子可以换成下面的写法:
|
1
|
$ sed 's/ MA/, Massachusetts/;s/ PA/, Pennsylvania/' list |
操作指令之间可以用逗号分隔,这点和shell命令可以用逗号分隔是一样的。
这里提前说一点使用s替换命令需要小心的地方,不要忘记结尾的斜杠,如果你遇到下面的错误说明你犯了这个错误:
|
1
2
|
$ sed -e 's/ MA/, Massachusetts' listsed: -e expression #1, char 21: unterminated `s' command |
假如这时,我只想输出替换命令影响的行,而不想输出文件的所有内容,需要怎么办?这个时候可以利用替换命令s的p选项,它会将替换后的内容打印到标准输出。但是仅仅这样是不够的,否则输出的结果并非我们所想要的:
|
1
2
3
4
5
6
7
8
9
10
11
12
|
$ sed -e 's/ MA/, Massachusetts/p' listJohn Daggett, 341 King Road, Plymouth, MassachusettsJohn Daggett, 341 King Road, Plymouth, MassachusettsAlice Ford, 22 East Broadway, Richmond VAOrville Thomas, 11345 Oak Bridge Road, Tulsa OKTerry Kalkas, 402 Lans Road, Beaver Falls PAEric Adams, 20 Post Road, Sudbury, MassachusettsEric Adams, 20 Post Road, Sudbury, MassachusettsHubert Sims, 328A Brook Road, Roanoke VAAmy Wilde, 334 Bayshore Pkwy, Mountain View CASal Carpenter, 73 6th Street, Boston, MassachusettsSal Carpenter, 73 6th Street, Boston, Massachusetts |
从上面可以看出,文件的所有行都被打印到标准输出,并且被替换命令修改的行输出了两遍。造成这个问题的原因是,sed命令应用完所有指定之后默认会将当前行打印输出,所以就有了上面的结果。解决方法是在使用sed命令是指定-n参数,该参数会抑制sed默认的输出:
|
1
2
3
4
|
$ sed -n 's/ MA/, Massachusetts/p' listJohn Daggett, 341 King Road, Plymouth, MassachusettsEric Adams, 20 Post Road, Sudbury, MassachusettsSal Carpenter, 73 6th Street, Boston, Massachusetts |
正则表达式
书中的第3章的内容都是介绍正则表达式,这是因为sed的很多地方都需要用到正则表达式,比如操作指令的pattern部分以及替换命令中用到的匹配部分。关于正则这部分可以看Linux/Unix工具与正则表达式的POSIX规范,文章中已经讲得非常清楚了,我自已在忘记一些内容的时候也是去查阅这篇文章。
Sed&awk笔记之sed篇:模式空间与地址匹配
模式空间
在上一篇Sed&awk笔记之sed篇:简单介绍中,我们曾经介绍过简单的sed处理流程,这里首先回顾下:
1.读入新的一行内容到缓存空间;
2.从指定的操作指令中取出第一条指令,判断是否匹配pattern;
3.如果不匹配,则忽略后续的编辑命令,回到第2步继续取出下一条指令;
4.如果匹配,则针对缓存的行执行后续的编辑命令;完成后,回到第2步继续取出下一条指令;
5.当所有指令都应用之后,输出缓存行的内容;回到第1步继续读入下一行内容;
6.当所有行都处理完之后,结束;
由此可见,sed并非是将一个编辑命令分别应用到每一行,然后再取下一个编辑命令。恰恰相反,sed是以行的方式来处理的。另外一方面,每一行都是被读入到一块缓存空间,该空间名为模式空间(pattern space),这是一个很重要的概念,在后文中会多次被提及。因此sed操作的都是最初行的拷贝,同时后续的编辑命令都是应用到前面的命令编辑后输出的结果,所以编辑命令之间的顺序就显得格外重要。
简单例子
让我们来看一个非常简单的例子,将一段文本中的pig替换成cow,并且将cow替换成horse:
|
1
|
$ sed 's/pig/cow/;s/cow/hores/' input |
初看起来好像没有问题,但是实际上是错误的,原因是第一个替换命令将所有的pig都替换成cow,紧接着的替换命令是基于前一个结果处理的,将所有的cow都替换成horse,造成的结果是全部的pig/cow都被替换成了horse,这样违背了我们的初衷。
在这种情况下,只需要调换下两个编辑命令的顺序:
|
1
|
$ sed 's/cow/hores/;s/pig/cow/' input |
模式空间的转换
sed只会缓存一行的内容在模式空间,这样的好处是sed可以处理大文件而不会有任何问题,不像一些编辑器因为要一次性载入文件的一大块内容到缓存中而导致内存不足。下面用一个简单的例子来讲解模式空间的转换过程,如下图所示:

现在要把一段文本中的Unix System与UNIX System都要统一替换成The UNIX Operating System,因此我们用两句替换命令来完成这个目的:
|
1
2
|
s/Unix /UNIX /s/UNIX System/UNIX Operating System/ |
对应上图,过程如下:
1.首先一行内容The Unix System被读入模式空间;
2.应用第一条替换命令将Unix替换成UNIX;
3.现在模式空间的内容变成The UNIX System;
4.应用第二条替换命令将UNIX System替换成UNIX Operating System;
5.现在模式空间的内容变成The UNIX Operating System;
6.所有编辑命令执行完毕,默认输出模式空间中的行;
地址匹配
地址匹配在sed中是非常重要的一块内容,因为它限制sed的编辑命令到底应用在哪些行上。默认情况下,sed是全局匹配的,即对所有输入行都应用指定的编辑命令,这是因为sed依次读入每一行,每一行都会成为当前行并被处理,所以s/CA/California/g会将所有输入行的CA替换成California。这一点跟vi/vim是不一样的,众所周知,vim的替换命令默认是替换当前行的内容,除非你指定%s才会作全局替换。
可以通过指定地址来限制sed的处理范围,例如只想将替换包含Sebastopol的行:
|
1
|
Sebastopol/s/CA/California/ |
/Sebastopol/是一个正则表达式匹配包含Sebastopol的行,因此像行“San Francisco, CA”则不会被替换。
sed命令中可以包含0个、1个或者2个地址(地址对),地址可以为正则表达式(如/Sebastopol/),行号或者特殊的行符号(如$表示最后一行):
● 如果没有指定地址,默认将编辑命令应用到所有行;
●如果指定一个地址,只将编辑命令应用到匹配该地址的行;
●如果指定一个地址对(addr1,addr2),则将编辑命令应用到地址对中的所有行(包括起始和结束);
●如果地址后面有一个感叹号(!),则将编辑命令应用到不匹配该地址的所有行;
为了方便理解上述内容,我们以删除命令(d)为例,默认不指定地址将会删除所有行:
|
1
|
$ sed 'd' list |
指定地址则删除匹配的行,如删除第一行:
|
1
2
3
4
5
6
7
8
|
$ sed '1d' list Alice Ford, 22 East Broadway, Richmond VAOrville Thomas, 11345 Oak Bridge Road, Tulsa OKTerry Kalkas, 402 Lans Road, Beaver Falls PAEric Adams, 20 Post Road, Sudbury MAHubert Sims, 328A Brook Road, Roanoke VAAmy Wilde, 334 Bayshore Pkwy, Mountain View CASal Carpenter, 73 6th Street, Boston MA |
或者删除最后一行,$符号在这里表示最后一行,这点要下正则表达式中的含义区别开来:
|
1
2
3
4
5
6
7
8
|
$ sed '$d' list John Daggett, 341 King Road, Plymouth MAAlice Ford, 22 East Broadway, Richmond VAOrville Thomas, 11345 Oak Bridge Road, Tulsa OKTerry Kalkas, 402 Lans Road, Beaver Falls PAEric Adams, 20 Post Road, Sudbury MAHubert Sims, 328A Brook Road, Roanoke VAAmy Wilde, 334 Bayshore Pkwy, Mountain View CA |
这里通过指定行号删除,行号是sed命令内部维护的一个计数变量,该变量只有一个,并且在多个文件输入的情况下也不会被重置。
前面都是以行号来指定地址,也可以通过正则表达式来指定地址,如删除包含MA的行:
|
1
2
3
4
5
6
|
$ sed '/MA/d' list Alice Ford, 22 East Broadway, Richmond VAOrville Thomas, 11345 Oak Bridge Road, Tulsa OKTerry Kalkas, 402 Lans Road, Beaver Falls PAHubert Sims, 328A Brook Road, Roanoke VAAmy Wilde, 334 Bayshore Pkwy, Mountain View CA |
通过指定地址对可以删除该范围内的所有行,例如删除第3行到最后一行:
|
1
2
|
$ sed '2,$d' list John Daggett, 341 King Road, Plymouth MA |
使用正则匹配,删除从包含Alice的行开始到包含Hubert的行结束的所有行:
|
1
2
3
4
|
$ sed '/Alice/,/Hubert/d' list John Daggett, 341 King Road, Plymouth MAAmy Wilde, 334 Bayshore Pkwy, Mountain View CASal Carpenter, 73 6th Street, Boston MA |
当然,行号和地址对是可以混用的:
|
1
2
3
4
|
$ sed '2,/Hubert/d' list John Daggett, 341 King Road, Plymouth MAAmy Wilde, 334 Bayshore Pkwy, Mountain View CASal Carpenter, 73 6th Street, Boston MA |
如果在地址后面指定感叹号(!),则会将命令应用到不匹配该地址的行:
|
1
2
3
4
5
6
|
$ sed '2,/Hubert/!d' list Alice Ford, 22 East Broadway, Richmond VAOrville Thomas, 11345 Oak Bridge Road, Tulsa OKTerry Kalkas, 402 Lans Road, Beaver Falls PAEric Adams, 20 Post Road, Sudbury MAHubert Sims, 328A Brook Road, Roanoke VA |
以上介绍的都是最基本的地址匹配形式,GNU Sed(也是我们用的sed版本)基于此添加了几个扩展的形式,具体可以看man手册,或者可以看我之前写的Sed命令地址匹配问题总结一文。
上面说的内容都是对匹配的地址执行单个命令,如果要执行多个编辑命令要怎么办?sed中可以用{}来组合命令,就好比编程语言中的语句块,例如:
|
1
2
3
4
5
|
$ sed -n '1,4{s/ MA/, Massachusetts/;s/ PA/, Pennsylvania/;p}' list John Daggett, 341 King Road, Plymouth, MassachusettsAlice Ford, 22 East Broadway, Richmond VAOrville Thomas, 11345 Oak Bridge Road, Tulsa OKTerry Kalkas, 402 Lans Road, Beaver Falls, Pennsylvania |
Sed&awk笔记之sed篇:基础命令
在开始之前,首先回顾上一篇的重点内容:地址匹配。上一篇中介绍过,地址可以指定0个,1个或者2个。地址的形式可以为斜杠分隔的正则表达式(例如/test/),行号(例如3,5)或者特殊符号(例如$)。如果没有指定地址,说明sed应用的编辑命令是全局的;如果是1个地址,编辑命令只是应用到匹配的那一行;如果是一对地址,编辑命令则应用到该地址对匹配的行范围。关于地址匹配的内容具体可以看Sed命令地址匹配问题总结。
书中说,对于sed编辑命令的语法有两种约定,分别是
|
1
2
|
[address]command # 第一种[line-address]command # 第二种 |
第一种[address]是指可以为任意地址包括地址对,第二种[line-address]是指只能为单个地址。文中指出,例如i(后方插入命令)、a(前方追加命令)以及=(打印行号命令)等都属于第二种命令,但是实际上我在ArchLinux上测试,指定地址对也没有报错。不过为了兼容性,建议按作者所说的做。
以下是要介绍的全部基础命令:
| 名称 | 命令 | 语法 | 说明 |
|---|---|---|---|
| 替换 | s | [address]s/pattern/replacement/flags | 替换匹配的内容 |
| 删除 | d | [address]d | 删除匹配的行 |
| 插入 | i | [line-address]i\text | 在匹配行的前方插入文本 |
| 追加 | a | [line-address]a\text | 在匹配行的后方插入文本 |
| 行替换 | c | [address]c\text | 将匹配的行替换成文本text |
| 打印行 | p | [address]p | 打印在模式空间中的行 |
| 打印行号 | = | [address]= | 打印当前行行号 |
| 打印行 | l | [address]l | 打印在模式空间中的行,同时显示控制字符 |
| 转换字符 | y | [address]y/SET1/SET2/ | 将SET1中出现的字符替换成SET2中对应位置的字符 |
| 读取下一行 | n | [address]n | 将下一行的内容读取到模式空间 |
| 读文件 | r | [line-address]r file | 将指定的文件读取到匹配行之后 |
| 写文件 | w | [address]w file | 将匹配地址的所有行输出到指定的文件中 |
| 退出 | q | [line-address]q | 读取到匹配的行之后即退出 |
替换命令: s
替换命令的语法是:
|
1
|
[address]s/pattern/replacement/flags |
其中[address]是指地址,pattern是替换命令的匹配表达式,replacement则是对应的替换内容,flags是指替换的标志位,它可以包含以下一个或者多个值:
● n: 一个数字(取值范围1-512),表明仅替换前n个被pattern匹配的内容;
● g: 表示全局替换,替换所有被pattern匹配的内容;
● p: 仅当行被pattern匹配时,打印模式空间的内容;
● w file:仅当行被pattern匹配时,将模式空间的内容输出到文件file中;
如果flags为空,则默认替换第一次匹配:
|
1
2
|
$ echo "column1 column2 column3 column4" | sed 's/ /;/'column1;column2 column3 column4 |
如果flags中包含g,则表示全局匹配:
|
1
2
|
$ echo "column1 column2 column3 column4" | sed 's/ /;/g'column1;column2;column3;column4 |
如果flags中明确指定替换第n次的匹配,例如n=2:
|
1
2
|
$ echo "column1 column2 column3 column4" | sed 's/ /;/2'column1 column2;column3 column4 |
当替换命令的pattern与地址部分是一样的时候,比如/regexp/s/regexp/replacement/可以省略替换命令中的pattern部分,这在单个编辑命令的情况下没多大用处,但是在组合命令的场景下还是能省不少功夫的,例如下面是摘自文中的一个段落:
The substitute command is applied to the lines matching the address. If no address is specified, it is applied to all lines that match the pattern, a regular expression. If a regular expression is supplied as an address, and no pattern is specified, the substitute command matches what is matched by the address. This can be useful when the substitute command is one of multiple commands applied at the same address. For an example, see the section “Checking Out Reference Pages” later in this chapter.
现在要在substitute command后面增加(“s”),同时在被修改的行前面增加+号,以下是使用的sed命令:
|
1
|
$ sed '/substitute command/{s//&("s")/;s/^/+ /}' paragraph.txt |
这里我们用到了组合命令,并且地址匹配的部分和第一个替换命令的匹配部分是一样的,所以后者我们省略了,在replacement部分用到了&这个元字符,它代表之前匹配的内容,这点我们在后面介绍。执行后的结果为:
|
1
2
3
4
5
6
7
|
+ The substitute command("s") is applied to the lines matching the address. If noaddress is specified, it is applied to all lines that match the pattern, aregular expression. If a regular expression is supplied as an address, and no+ pattern is specified, the substitute command("s") matches what is matched by the+ address. This can be useful when the substitute command("s") is one of multiplecommands applied at the same address. For an example, see the section "CheckingOut Reference Pages" later in this chapter. |
替换命令的一个技巧是中间的分隔符是可以更改的(这个技巧我们在简洁的Bash编程技巧续篇 – 5. 你知道sed的这个特性吗?中也曾经介绍过),这个技巧在有些地方非常有用,比如路径替换,下面是采用默认的分隔符和使用感叹号作为分隔符的对比:
|
1
2
|
$ find /usr/local -maxdepth 2 -type d | sed 's//usr/local/man//usr/share/man/'$ find /usr/local -maxdepth 2 -type d | sed 's!/usr/local/man!/usr/share/man!' |
替换命令中还有一个很重要的部分——replacement(替换内容),即将匹配的部分替换成replacement。在replacemnt部分中也有几个特殊的元字符,它们分别是:
● &: 被pattern匹配的内容;
●\num: 被pattern匹配的第num个分组(正则表达式中的概念,\(..\)括起来的部分称为分组;
●\: 转义符号,用来转义&,\, 回车等符号
&元字符我们已经在上面的例子中介绍过,这里举个例子介绍下\num的用法。在Linux系统中,默认都开了几个tty可以让你切换(ctrl+alt+1, ctrl+alt+2 …),例如CentOS 6.0+的系统默认是6个:
|
1
2
3
|
[root@localhost ~]# grep -B 1 ACTIVE_CONSOLES /etc/sysconfig/init # What ttys should gettys be started on?ACTIVE_CONSOLES=/dev/tty[1-6] |
可以通过修改上面的配置来减少开机启动的时候创建的tty个数,比如我们只想要2个:
|
1
2
|
[root@localhost ~]# sed -r -i 's!(ACTIVE_CONSOLES=/dev/tty[1-)6]!12]!' /etc/sysconfig/init ACTIVE_CONSOLES=/dev/tty[1-2] |
其中-i参数表示直接修改原文件,-r参数是指使用扩展的正则表达式(ERE),扩展的正则表达式中分组的括号不需要用反斜杠转义”(ACTIVE_CONSOLES=/dev/tty\[1-)",这里[是有特殊含义的(表示字符组),所以需要转义。在替换的内容中使用\1来引用这个匹配的分组内容,1代表分组的编号,表示第一个分组。
删除命令: d
删除命令的语法是:
|
1
|
[address]d |
删除命令可以用于删除多行内容,例如1,3d会删除1到3行。删除命令会将模式空间中的内容全部删除,并且导致后续命令不会执行并且读入新行,因为当前模式空间的内容已经为空。我们可以试试:
|
1
2
|
$ sed '2,${d;=}' listJohn Daggett, 341 King Road, Plymouth MA |
以上命令尝试在删除第2行到最后一行之后,打印当前行号(=),但是事实上并没有执行该命令。
插入行/追加行/替换行命令: i/a/c
这三个命令的语法如下所示:
|
1
2
3
4
5
6
7
8
9
|
# Append 追加[line-address]a\text# Insert 插入line-address]i\text# Change 行替换 [address]c\text |
以上三个命令,行替换命令(c)允许地址为多个地址,其余两个都只允许单个地址(注:在ArchLinux上测试表明,追加和插入命令都允许多个地址,sed版本为GNU sed version 4.2.1)
追加命令是指在匹配的行后面插入文本text;相反地,插入命令是指匹配的行前面插入文本text;最后,行替换命令会将匹配的行替换成文本text。文本text并没有被添加到模式空间,而是直接输出到屏幕,因此后续的命令也不会应用到添加的文本上。注意,即使使用-n参数也无法抑制添加的文本的输出。
我们用实际的例子来简单介绍下这三个命令的用法,依然用最初的文本list:
|
1
2
3
4
5
6
7
8
9
|
$ cat listJohn Daggett, 341 King Road, Plymouth MAAlice Ford, 22 East Broadway, Richmond VAOrville Thomas, 11345 Oak Bridge Road, Tulsa OKTerry Kalkas, 402 Lans Road, Beaver Falls PAEric Adams, 20 Post Road, Sudbury MAHubert Sims, 328A Brook Road, Roanoke VAAmy Wilde, 334 Bayshore Pkwy, Mountain View CASal Carpenter, 73 6th Street, Boston MA |
现在,我们要在第2行后面添加'------':
|
1
2
3
4
5
6
7
8
9
10
11
12
|
$ sed '2a--------------------------------------' listJohn Daggett, 341 King Road, Plymouth MAAlice Ford, 22 East Broadway, Richmond VA--------------------------------------Orville Thomas, 11345 Oak Bridge Road, Tulsa OKTerry Kalkas, 402 Lans Road, Beaver Falls PAEric Adams, 20 Post Road, Sudbury MAHubert Sims, 328A Brook Road, Roanoke VAAmy Wilde, 334 Bayshore Pkwy, Mountain View CASal Carpenter, 73 6th Street, Boston MA |
或者可以在第3行之前插入:
|
1
2
3
4
5
6
7
8
9
10
11
12
|
$ sed '3i--------------------------------------' listJohn Daggett, 341 King Road, Plymouth MAAlice Ford, 22 East Broadway, Richmond VA--------------------------------------Orville Thomas, 11345 Oak Bridge Road, Tulsa OKTerry Kalkas, 402 Lans Road, Beaver Falls PAEric Adams, 20 Post Road, Sudbury MAHubert Sims, 328A Brook Road, Roanoke VAAmy Wilde, 334 Bayshore Pkwy, Mountain View CASal Carpenter, 73 6th Street, Boston MA |
我们来测试下文本是否确实没有添加到模式空间,因为模式空间中的内容默认是会打印到屏幕的:
|
1
2
3
4
|
$ sed -n '2a--------------------------------------' list-------------------------------------- |
通过-n参数来抑制输出后发现插入的内容依然被输出,所以可以判定插入的内容没有被添加到模式空间。
使用行替换命令将第2行到最后一行的内容全部替换成'----':
|
1
2
3
4
5
|
$ sed '2,$c--------------------------------------' listJohn Daggett, 341 King Road, Plymouth MA-------------------------------------- |
打印命令: p/l/=
这里纯粹的打印命令应该是指p,但是因为后两者(l和=)和p差不多,并且相对都比较简单,所以这里放到一起介绍。
这三个命令的语法是:
|
1
2
3
|
[address]p[address]=[address]l |
p命令用于打印模式空间的内容,例如打印list文件的第一行:
|
1
2
|
$ sed -n '1p' listJohn Daggett, 341 King Road, Plymouth MA |
l命令类似p命令,不过会显示控制字符,这个命令和vim的list命令相似,例如:
|
1
2
|
$ echo "column1 column2 column3^M" | sed -n 'l'column1tcolumn2tcolumn3r$ |
=命令显示当前行行号,例如:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
$ sed '=' list1John Daggett, 341 King Road, Plymouth MA2Alice Ford, 22 East Broadway, Richmond VA3Orville Thomas, 11345 Oak Bridge Road, Tulsa OK4Terry Kalkas, 402 Lans Road, Beaver Falls PA5Eric Adams, 20 Post Road, Sudbury MA6Hubert Sims, 328A Brook Road, Roanoke VA7Amy Wilde, 334 Bayshore Pkwy, Mountain View CA8Sal Carpenter, 73 6th Street, Boston MA |
转换命令: y
转换命令的语法是:
|
1
|
[address]y/SET1/SET2/ |
它的作用是在匹配的行上,将SET1中出现的字符替换成SET2中对应位置的字符,例如1,3y/abc/xyz/会将1到3行中出现的a替换成x,b替换成y,c替换成z。是不是觉得这个功能很熟悉,其实这一点和tr命令是一样的。可以通过y命令将小写字符替换成大写字符,不过命令比较长:
|
1
2
|
$ echo "hello, world" | sed 'y/abcdefghijklmnopqrstuvwxyz/ABCDEFGHIJKLMNOPQRSTUVWXYZ/'HELLO, WORLD |
使用tr命令来转换成大写:
|
1
2
|
$ echo "hello, world" | tr a-z A-Z HELLO, WORLD |
取下一行命令: n
取下一行命令的语法为:
|
1
|
[address]n |
n命令为将下一行的内容提前读入,并且将之前读入的行(在模式空间中的行)输出到屏幕,然后后续的命令会应用到新读入的行上。因此n命令也会同d命令一样改变sed的控制流程。
书中给出了一个例子来介绍n的用法,假设有这么一个文本:
|
1
2
3
4
5
|
$ cat text.H1 "On Egypt"Napoleon, pointing to the Pyramids, said to his troops:"Soldiers, forty centuries have their eyes upon you." |
现在要将.H1后面的空行删除:
|
1
2
3
4
|
$ sed '/.H1/{n;/^$/d}' text.H1 "On Egypt"Napoleon, pointing to the Pyramids, said to his troops:"Soldiers, forty centuries have their eyes upon you." |
读写文件命令: r/w
读写文件命令的语法是:
|
1
2
|
[line-address]r file[address]w file |
读命令将指定的文件读取到匹配行之后,并且输出到屏幕,这点类似追加命令(a)。我们以书中的例子来讲解读文件命令。假设有一个文件text:
|
1
2
3
4
|
$ cat textFor service, contact any of the following companies:[Company-list]Thank you. |
同时我们有一个包含公司名称列表的文件company.list:
|
1
2
3
4
|
$ cat company.list AlliedMayflowerUnited |
现在我们要将company.list的内容读取到[Company-list]之后:
|
1
2
3
4
5
6
7
|
$ sed '/^[Company-list]/r company.list' textFor service, contact any of the following companies:[Company-list]AlliedMayflowerUnitedThank you. |
更好的处理应当是用公司名称命令替换[Company-list],因此我们还需要删除[Company-list]这一行:
|
1
2
3
4
|
$ sed '/^[Company-list]/r company.list;/^[Company-list]/d;' textFor service, contact any of the following companies:[Company-list]Thank you. |
但是结果我们非但没有删除[Company-list],而且company.list的内容也不见了?这是怎么回事呢?
下面是我猜测的过程,读文件的命令会将r空格后面的所有内容都当成文件名,即company.list;/^\[Company-list]/d;,然后读取命令的时候发现该文件不存在,但是sed命令读取不存在的文件是不会报错的。所以什么事都没干成。
我们用-e选项将两个命令分开就正常了:
|
1
2
3
4
5
6
|
$ sed -e '/^[Company-list]/r company.list' -e '/^[Company-list]/d;' textFor service, contact any of the following companies:AlliedMayflowerUnitedThank you. |
写命令将匹配地址的所有行输出到指定的文件中。假设有一个文件内容如下,前半部分是人名,后半部分是区域名称:
|
1
2
3
4
5
6
7
8
|
$ cat text Adams, Henrietta NortheastBanks, Freda SouthDennis, Jim MidwestGarvey, Bill NortheastJeffries, Jane WestMadison, Sylvia MidwestSommes, Tom South |
现在我们要将不同区域的人名字写到不同的文件中:
|
1
2
3
4
5
6
7
8
9
10
11
|
$ sed '/Northeast$/w region.northeast> /South$/w region.south> /Midwest$/w region.midwest> /West$/w region.west' textAdams, Henrietta NortheastBanks, Freda SouthDennis, Jim MidwestGarvey, Bill NortheastJeffries, Jane WestMadison, Sylvia MidwestSommes, Tom South |
查看输出的文件:
|
1
2
3
4
5
|
$ cat region.region.midwest region.northeast region.south region.west $ cat region.midwest Dennis, Jim MidwestMadison, Sylvia Midwest |
我们也可以试试将所有的w命令放到一起用分号分隔,发现会出下面的错误,它把w空格后面的部分当作文件名,这样就验证了上面的猜测:
|
1
2
|
$ sed '/Northeast$/w region.northeast;/south$/w region.south;' textsed: couldn't open file region.northeast;/south$/w region.south;: No such file or directory |
退出命令: q
退出命令的语法是
|
1
|
[line-address]q |
当sed读取到匹配的行之后即退出,不会再读入新的行,并且将当前模式空间的内容输出到屏幕。例如打印前3行内容:
|
1
2
3
4
|
$ sed '3q' listJohn Daggett, 341 King Road, Plymouth MAAlice Ford, 22 East Broadway, Richmond VAOrville Thomas, 11345 Oak Bridge Road, Tulsa OK |
打印前3行也可以用p命令:
|
1
2
3
4
|
$ sed -n '3p' listJohn Daggett, 341 King Road, Plymouth MAAlice Ford, 22 East Broadway, Richmond VAOrville Thomas, 11345 Oak Bridge Road, Tulsa OK |
但是对于大文件来说,前者比后者效率更高,因为前者读取到第N行之后就退出了。后者虽然打印了前N行,但是后续的行还是要继续读入,只不会不作处理。
到此为止,sed基础命令的部分就介绍完了。
下面是我整理的一份思维导图(附.xmind文件下载地址):

Sed&awk笔记之sed篇:高级命令(一)
在上一篇中介绍的基础命令都是面向行的,一般情况下,这种处理并没有什么问题,但是当匹配的内容是错开在两行时就会有问题,最明显的例子就是某些英文单词会被分成两行。
幸运地是,sed允许将多行内容读取到模式空间,这样你就可以匹配跨越多行的内容。本篇笔记主要介绍这些命令,它们能够创建多行模式空间并且处理之。其中,N/D/P这三个多行命令分别对应于小写的n/d/p命令,后者我们在上一篇已经介绍。它们的功能是类似的,区别在于命令影响的内容不同。例如D命令与d命令同样是删除模式空间的内容,只不过d命令会删除模式空间中所有的内容,而D命令仅会删除模式空间中的第一行。
读下一行:N
N命令将下一行的内容读取到当前模式空间,但是下n命令不一样的地方是N命令并没有直接输出当前模式空间中的行,而是把下一行追加到当前模式空间,两行之间用回车符\n连接,如下图所示:

模式空间包含多行之后,正则表达式的^/$符号的意思就变了,^是匹配模式空间的最开始而非行首,$是匹配模式空间的最后位置而非行尾。
书中给的第一例子,是替换以下文本中的"Owner and Operator Guide"为"Installation Guide",正如我们在本篇开头说的Owner and Operator Guide跨越在两行:
|
1
2
3
|
Consult Section 3.1 in the Owner and OperatorGuide for a description of the tape drivesavailable on your system. |
我们用N命令试下手:
|
1
2
3
|
$ sed '/Operator$/{N;s/Owner and OperatornGuide/Installation Guide/}' textConsult Section 3.1 in the Installation Guide for a description of the tape drivesavailable on your system. |
不过这个例子有两个局限:
● 我们知道Owner and Operator Guide分割的位置;
● 执行替换命令后,前后两行拼接在一起,导致这行过长;
第二点,可以这样解决:
|
1
2
3
4
|
$ sed '/Operator$/{N;s/Owner and OperatornGuide /Installation Guiden/}' textConsult Section 3.1 in the Installation Guidefor a description of the tape drivesavailable on your system. |
现在去掉第1个前提,我们引入更加复杂的测试文本,这段文本中Owner and Operator Guide有位于一行的,也有跨越多行的情况:
|
1
2
3
4
5
6
7
8
9
10
11
|
$ cat textConsult Section 3.1 in the Owner and OperatorGuide for a description of the tape drivesavailable on your system.Look in the Owner and Operator Guide shipped with your system.Two manuals are provided including the Owner andOperator Guide and the User Guide.The Owner and Operator Guide is shipped with your system. |
相应地修改下之前执行的命令,如下所示:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
$ sed 's/Owner and Operator Guide/Installation Guide//Owner/{Ns/ *n/ /s/Owner and Operator Guide */Installation Guide/}' textConsult Section 3.1 in the Installation Guidefor a description of the tape drivesavailable on your system.Look in the Installation Guide shipped with your system.Two manuals are provided including the Installation Guideand the User Guide.The Installation Guide is shipped with your system. |
这里我们首先将在单行出现的Owner and Operator Guide替换为Installation Guide,然后再寻找匹配Owner的行,匹配后读取下一行的内容到模式空间,并且将中间的换行符替换成空格,最后再替换Owner and Operator Guide。
解释起来很简单,但是中间还是有些门道的。比如你可能觉得这里最前面的s/Owner and Operator Guide/Installation Guide/命令是多余的,假设你删除这一句:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
$ sed '/Owner/{> N> s/ *n/ /> s/Owner and Operator Guide */Installation Guide> /> }' textConsult Section 3.1 in the Installation Guidefor a description of the tape drivesavailable on your system.Look in the Installation Guideshipped with your system. Two manuals are provided including the Installation Guideand the User Guide.The Owner and Operator Guide is shipped with your system. |
最明显的问题是最后一行没有被替换,原因是当最后一行的被读入到模式空间后,匹配Owner,执行N命令读入下一行,但是因为当前已经是最后一行,所以N读取替换,告诉sed可以退出了,sed也不会继续执行接下来的替换命令(注:书中说最后一行不会被打印输出,我这边测试是会输出的)。所以这里需要在使用N的时候加一个判断,即当前行为最后一行时,不读取下一行的内容:$!N,这一点在很多场合都是有用的,更改后重新执行:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
$ sed '/Owner/{> $!N> s/ *n/ /> s/Owner and Operator Guide */Installation Guide> /> }' textConsult Section 3.1 in the Installation Guidefor a description of the tape drivesavailable on your system.Look in the Installation Guideshipped with your system. Two manuals are provided including the Installation Guideand the User Guide.The Installation Guideis shipped with your system. |
上面只是为了用例子说明N的用法,可能解决方案未必是最好的。
删除行:D
该命令删除模式空间中第一行的内容,而它对应的小d命令删除模式空间的所有内容。D不会导致读入新行,相反它会回到最初的编辑命令,重要应用在模式空间剩余的内容上。
后面半句开始比较难以理解,用书中的一个例子来解释下。现在我们有一个文本文件,内容如下所示,行之间有空行:
|
1
2
3
4
5
6
7
8
9
10
|
$ cat textThis line is followed by 1 blank line.This line is followed by 2 blank lines.This line is followed by 3 blank lines.This line is followed by 4 blank lines.This is the end. |
现在我们要删除多余的空行,将多个空行缩减成一行。假如我们使用d命令来删除,很简单的逻辑:
|
1
2
3
4
5
6
7
8
|
$ sed '/^$/{N;/^n$/d}' textThis line is followed by 1 blank line.This line is followed by 2 blank lines.This line is followed by 3 blank lines.This line is followed by 4 blank lines.This is the end. |
我们会发现一个奇怪的结果,奇数个数的相连空行已经被合并成一行,但是偶数个数的却全部被删除了。造成这样的原因需要重新翻译下上面的命令,当匹配一个空行是,将下一行也读取到模式空间,然后若下一行也是空行,则模式空间中的内容应该是\n,因此匹配^\n$,从而执行d命令会将模式空间中的内容清空,结果就是相连的两个空行都被删除。这样就可以理解为什么相连奇数个空行的情况下是正常的,而偶数个数就有问题了。
这种情况下,我们就应该用D命令来处理,这样做就得到预期的结果了:
|
1
2
3
4
5
6
7
8
9
10
|
$ sed '/^$/{N;/^n$/D}' textThis line is followed by 1 blank line.This line is followed by 2 blank lines.This line is followed by 3 blank lines.This line is followed by 4 blank lines.This is the end. |
D命令只会删除模式空间的第一行,而且删除后会重新在模式空间的内容上执行编辑命令,类似形成一个循环,前提是相连的都是空行。当匹配一个空行时,N读取下一行内容,此时匹配^\n$导致模式空间中的第一行被删除。现在模式空间中的内容是空的,重新执行编辑命令,此时匹配/^$/。继续读取下一行,当下一行依然为空行时,重复之前的动作,否则输出当前模式空间的内容。造成的结果是连续多个空行,只有最后一个空行是保留输出的,其余的都被删除了。这样的结果才是我们最初希望得到的。
打印行:P
P命令与p命令一样是打印模式空间的内容,不同的是前者仅打印模式空间的第一行内容,而后者是打印所有的内容。因为编辑命令全部执行完之后,sed默认会输出模式空间的内容,所以一般情况下,p和P命令都是与-n选项一起使用的。但是有一种情况是例外的,即编辑命令的执行流程被改变的情况,例如N,D等。很多情况下,P命令都是用在N命令之后,D命令之前的。这三个命令合起来,可以形成一人输入输出的循环,并且每次只打印一行:读入一行后,N继续读下一行,P命令打印第一行,D命令删除第一行,执行流程回到最开始重复该过程。
|
1
|
$ echo -e "line1nline2nline3" | sed '$!N;P;D' |
不过多行命令用起来要格外小心,你要用自己的大脑去演算一遍执行的过程,要不然很容易出错,比如:
|
1
|
$ echo -e "line1nline2nline3" | sed -n 'N;1P' |
你可能期望打印第一行的内容,事实上并没有输出。原因是当N继续读入第二行后,当前行号已经是2了,我们在第二篇笔记中曾经说过,行号只是sed在内部维护的一个计数变量而已,每当读入新的一行,行号就加一:
|
1
2
3
|
$ echo -e "line1nline2nline3" | sed -n '$!N;='23 |
我们依然用替换Unix System为Unix Operating System作为例子,介绍N/P/D三个命令是如何配合使用的。
示例文本如下所示,为了举例方便,这段文本仅有三行内容,刚好可以演示一个循环的处理过程:
|
1
2
3
4
|
$ cat textThe UNIXSystem and UNIX... |
执行的命令:
|
1
2
3
4
5
6
7
8
9
|
$ sed '/UNIX$/{> N> s/nSystem/ Operating &/> P> D> }' textThe UNIX Operating System and UNIX... |
执行过程如下图所示:
以上三个命令的用法与之前介绍的基础命令是截然不同的,有些同学可能都没有接触过。在下一篇中,我会介绍更多高级的命令,同时为引入一个新的概念:保持空间(Hold Space)。
Sed&awk笔记之sed篇:高级命令(二)
上一篇中介绍了N/D/P三个命令,它们可以形成多行的模式空间,在一点程度上弥补了单行模式空间的不足,我们用sed编辑文本的能力又进了一步。模式空间是sed内部维护的一个缓存空间,它存放着读入的一行或者多行内容。但是模式空间的一个限制是无法保存模式空间中被处理的行,因此sed又引入了另外一个缓存空间——模式空间(Hold Space)。
保持空间
保持空间用于保存模式空间的内容,模式空间的内容可以复制到保持空间,同样地保持空间的内容可以复制回模式空间。sed提供了几组命令用来完成复制的工作,其它命令无法匹配也不能修改模式空间的内容。
操作保持空间的命令如下所示:
| 名称 | 命令 | 说明 |
|---|---|---|
| 保存(Hold) | h/H | 将模式空间的内容复制或者追加到保持空间 |
| 取回(Get) | g/G | 将保持空间的内容复制或者追加到模式空间 |
| 交换(Exchange) | x | 交换模式空间和保持空间的内容 |
这几组命令提供了保存、取回以及交换三个动作,交换命令比较容易理解,保存命令和取回命令都有大写和小写两种形式,这两种形式的区别是小写的是将会覆盖目的空间的内容,而大写的是将内容追加到目的空间,追加的内容和原有的内容是以\n分隔。
基本使用
我们随便试试这几个命令,假设有如下测试文本:
|
1
2
3
4
5
6
7
|
$ cat text121122111222 |
1. 首先,仅使用h/H或者g/G命令:
使用h命令:
|
1
2
3
4
5
6
7
|
$ sed 'h' text121122111222 |
使用G命令:
|
1
2
3
4
5
6
7
8
9
10
11
12
|
$ sed 'G' text121122111222 |
前者返回的结果正常,因为复制到保持空间的内容并没有取回;后者每一行的后面都多了一个空行,原因是每行都会从保持空间取回一行,追加(大写的G)到模式空间的内容之后,以\n分隔。
2. 使用x命令交换空间
|
1
2
3
4
5
6
7
|
$ sed 'x' text121122111 |
命令执行后,发现前面多了一个空行并且最后一行不见了。我在前面一直强调sed命令用好,要有用大脑回顾命令执行过程的能力:
* 当读入第一行的时候,模式空间中的内容是第一行的内容,而保持空间是空的,这个时候交换两个空间,导致模式空间为空,保持空间为第一行的内容,因此输出为空行;
* 当读入下一行之后,模式空间为第2行的内容,保持空间为第一行的内容,交换后输出第1行的内容;
* 依次读入每一行,输出上一行的内容;
* 直到最后一行被读入到模式空间,交换后输出倒数第二行的内容,而最后一行的内容并没有输出,此时命令执行结束。
深入使用
上面的例子简单地介绍了保持空间命令的基本使用方法,这些命令单个使用可能效果不大,但是组合起来的效果是非常好的。
1.第一个例子: 使用逗号拼接行
|
1
2
|
$ sed 'H;$!d;${x;s/^n//;s/n/,/g}' text1,11,2,11,22,111,222 |
上面的命令执行过程是这样的,使用H将每一行都追加到保持空间,这里利用d命令打断常规的命令执行流程,让sed继续读入新的一行,直接到将最后一行都放到保持空间。这个时候使用x命令将保持空间的内容交换到模式空间,模式空间的内容现在是这样的:\n1\n11\n2\n11\n22\n111\n222。替换的步骤分成两个,首先去掉首个回车符,然后把剩余的回车符替换成逗号。
其实上面的过程可以包装成一个常用的函数:
|
1
2
3
4
5
6
|
$ function join_lines()> {> sed 'H;$!d;${x;s/^n//;s/n/,/g}' $1> }$ join_lines text1,11,2,11,22,111,222 |
进一步,我们可以让分隔符可以通过参数设置,另外一方面删除文件名的参数,而改成常见的过滤器命令形式(即通过管道传递输入):
|
1
2
3
4
5
6
7
|
$ function join_lines()> {> local delim=${1:-,}> sed 'H;$!d;${x;s/^n//;s/n/'$delim'/g}'> }$ cat text | join_lines ';'1;11;2;11;22;111;222 |
但是如果我们要用&作为符号,就会出现问题:
|
1
2
3
4
5
6
7
8
|
$ cat text | join_lines '&'11121122111222 |
上面并没有&作为分隔符,这是因为&是元字符,表示匹配的部分,这里刚好是回车符\n。因此我们需要对分隔符进行转义:
|
1
2
3
4
5
6
7
|
$ function join_lines()> {> local delim=${1:-,}> sed 'H;$!d;${x;s/^n//;s/n/'$delim'/g}'> } $ cat text | join_lines '&'1&11&2&11&22&111&222 |
2.第二个例子:将语句中的特定单词转换成大写
现在有这样的文本,有许多类似这样的find the Match statement语句,其中Match是语句的名称,但是这个单词的大小写不统一,有些地方是小写的,有些地方是首字符大写,现在我们要做的是把这个单词统一转换成大写。
容易联想到的是Sed&awk笔记之sed篇:基础命令中介绍的y命令,利用y命令确实可以做到小写转换成大写,转换的命令是这样的:
|
1
|
y/abcdefghijklmnopqrstuvwxyz/ABCDEFGHIJKLMNOPQRSTUVWXYZ/ |
但是y命令是会把模式空间的所有内容都转换,这样不能满足我们的需求。但是我们可以利用保持空间保存当前行,然后处理模式空间中的内容:
|
1
2
3
4
5
6
7
|
/the .* statement/{hs/.*the (.*) statement.*/1/y/abcdefghijklmnopqrstuvwxyz/ABCDEFGHIJKLMNOPQRSTUVWXYZ/Gs/(.*)n(.*the ).*( statement.*)/213/} |
老规矩一条一条过上面的命令,为了方便说明,每个命令解释后我都会给出当前模式空间和保持空间的内容。
首先找到需要处理的行(假设当前行为find the Match statement)。
|
1
|
Pattern space: find the Match statement |
将当前行保存到保持空间:
|
1
2
|
Pattern space: find the Match statementHold space: find the Match statement |
然后利用替换命令获取需要处理的单词:
|
1
2
|
Pattern space: MatchHold space: find the Match statement |
然后通过转换命令将其转换成大写:
|
1
2
|
Pattern space: MATCHHold space: find the Match statement |
现在再利用G命令将保持空间的内容追加到模式空间最后:
|
1
2
|
Pattern space: MATCH\nfind the Match statementHold space: find the Match statement |
最后再次利用替换命令处理下:
|
1
2
|
Pattern space: find the MATCH statementHold space: find the Match statement |
流程控制
一般情况下,sed是将编辑命令从上到下依次应用到读入的行上,但是像d/n/D/N命令都能够在一定程度上改变默认的执行流程,甚至利用N/D/P三个命令可以形成一个强大的循环处理流程。除此之外,其实sed还提供了分支命令(b)和测试(test)两个命令来控制流程,这两个命令可以跳转到指定的标签(label)位置继续执行命令。标签是以冒号开头的标记,如下例中的:top标签:
|
1
2
3
4
5
|
:topcommand1command2/pattern/b topcommand3 |
当执行到/pattern/b top时,如果匹配pattern,则跳转到:top标签所在的位置,继续执行下一个命令command1。
如果没有指定标签,则将控制转移到脚本的结尾处。也许这只是一个默认的行为,但是有时候如果用得好也是非常有用的,例如:
|
1
2
3
4
|
/pattern/bcommand 1command 2command 3 |
当执行到/pattern/b时,如果匹配pattern,则跳转到最后。这种情况下匹配pattern的行可以避开执行后续的命令,被排除在外。
下一个例子中,我们利用分支命令的跳转效果达到类似if语句的效果:
|
1
2
3
4
5
|
command1/pattern/b endcommand2:endcommand3 |
当执行到/pattern/b end时,如果匹配pattern,则跳转到:end标签所在的位置,跳过command2而不执行。
进一步地,利用两个分支命令可以达到if..else的分支效果:
|
1
2
3
4
5
6
|
command1/pattern/b dothreecommand2b:dothreecommand3 |
这个例子中,当执行到/pattern/b dothree时,若匹配pattern则中转到:dothree标签,此时执行command3;若不匹配,则执行command2,并且跳转到最后。
上面的例子都是用到了分支命令,分支命令的跳转是无条件的。而与之相对的是测试命令,测试命令的跳转是有条件的,当且仅当当前行发生成功的替换时才跳转。
为了说明测试命令的用法,我们用它来实现前文定义过的join_lines函数:
|
1
2
|
$ sed ':a;$!N;s/n/,/;ta' text1,11,2,11,22,111,222 |
在最前面我们添加了一个标签:a,然后在再最后面利用测试命令跳转到该标签。可能,你会觉得这里也可以用分支命令,但是事实上分支命令会导致死循环,因为在它里他没有结束的条件。
但是测试命令就不同了,这一点直到最后才体现出来。当最后一行被N命令读入之后,回车替换成逗号,此时ta继续跳转到最开头,因为所有行都已经被读入,所以$!不匹配,同时模式空间中的回车已经全部被替换成逗号,所以替换也不会发生。之前我们说过,当且仅当当前行发生成功的替换时测试命令才跳转。所以此时跳转不会发生,退出sed命令。
我们可以利用sedsed这个工具来验证上面的过程,sedsed可以用来调试sed脚本。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
$ ./sedsed -d -e ':a;$!N;s/n/,/;ta' textPATT:1$HOLD:$COMM::aCOMM:$ !NPATT:1n11$HOLD:$COMM:s/n/,/PATT:1,11$HOLD:$COMM:t aCOMM:$ !NPATT:1,11n2$HOLD:$......COMM:$ !NPATT:1,11,2,11,22,111,222n1111$HOLD:$COMM:s/n/,/PATT:1,11,2,11,22,111,222,1111$HOLD:$COMM:t aCOMM:$ !NPATT:1,11,2,11,22,111,222,1111$HOLD:$COMM:s/n/,/PATT:1,11,2,11,22,111,222,1111$HOLD:$COMM:t aPATT:1,11,2,11,22,111,222,1111$HOLD:$1,11,2,11,22,111,222,1111 |
看第27行替换命令发生的时候,此时模式空间的内容为PATT:1,11,2,11,22,111,222,1111$,因此替换失败,ta命令不会发生跳转,脚本执行退出。
而如果在这里把测试命令换成分支命令,整个执行过程就会陷入死循环了:
|
1
2
3
4
5
6
7
8
9
10
|
COMM:b aCOMM:$ !NPATT:1,11,2,11,22,111,222,1111$HOLD:$COMM:s/n/,/PATT:1,11,2,11,22,111,222,1111$HOLD:$COMM:b aCOMM:$ !NPATT:1,11,2,11,22,111,222,1111$ |
高级命令总结
到此为止,所有高级命令的用法就已经介绍完了。最后一段内容由于时间的关系,写得比较仓促。高级命令的用法比起基础命令相对复杂一点,而且容易出错,需要十分小心,如果不确定可以用上面介绍的sedsed工具来调式下,而且便于加深各种命令行为的理解。
Sed&awk笔记之sed篇:实战
相信大家肯定用过grep这个命令,它可以找出匹配某个正则表达式的行,例如查看包含"the word"的行:
|
1
|
$ grep "the word" filename |
但是grep是针对单行作匹配的,所以如果一个短句跨越了两行就无法匹配。这就给我们出了一个题目,如何用sed模仿grep的行为,并且支持跨行短句的匹配呢?
当单词仅出现在一行时很简单,用普通的正则就可以匹配,这里我们用到分支命令,当匹配时则跳转到最后:
|
1
|
/the word/b |
当单词跨越两行,容易想到用N命令将下一行读取到模式空间再做处理。例如我们同样要查找短句"the word",现在的文本是这样的:
|
1
2
3
|
$ cat textwe want to find the phrase theword, but it appears across two lines. |
当用N玲读入下一行时,模式空间的内容如下所示:
|
1
|
Pattern space: we want to find the phrase the\nword, but it appears across two lines. |
因此,需要将回车符号删除,然后再作匹配。
|
1
2
3
|
$!Ns/ *\n/ //the word/b |
可是这里会有一个问题,如果短句恰好在读入的第二行的话,虽然匹配,但是会打印出模式空间中的所有内容,这样不符合grep的行为,只显示包含短句的那一行。所以这里要再加一个处理,将模式空间的第一行内容删除,再在第二行中匹配。但是在此之前,首先要保存模式空间的内容,否则可没有后悔药可吃。
h命令可以将模式空间的内容保存到保持空间,然后利用替换命令将模式空间的第一行内容清除,然后再作匹配处理:
|
1
2
3
4
|
$!Nhs/.*\n///the word/b |
如果不匹配,则短句可能确实是跨越两行,这时候我们首先用g命令将之前保存的内容从保持空间取回到模式空间,替换掉回车后再进行匹配:
|
1
2
3
|
gs/ *\n/ //the word/b |
这里如果匹配则直接跳转到最后,并且输出的内容是替换后的内容。
但是我们要输出的是匹配的原文,而原文现在在保持空间还有一份拷贝,因此当匹配时,需要将原文从保持空间取回:
|
1
2
3
4
5
6
|
gs/ *\n/ //the word/{gb} |
同样地,我们要考虑不匹配的情况,不匹配的时候也要将会原文从保持空间取回,并且将模式空间的第一行删除,继续处理下一行:
|
1
2
3
4
5
6
7
8
|
gs/ *\n/ //the word/{gb}gD |
将所有的sed脚本合在一起,假设我们将以下内容保存到phrase.sed文件中:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
/the word/b$!Nhs/.*\n///the word/bgs/ *\n///the word/{gb}gD |
接下来,我们用一段文本来测试下以上的脚本是否正确:
|
1
2
3
4
5
6
7
8
9
|
$ cat textWe will use phrase.sed to print any line which containsthe word. Or if the word appears across two lines, likebelow:It will print this line, because theword appears across two lines.You can run sed -f phrase.sed text to test this. |
执行命令如下所示:
|
1
2
3
4
|
$ sed -f phrase.sed textthe word. Or if the word appears across two lines, likeIt will print this line, because theword appears across two lines. |
上面的命令中的"the word"其实可以是一个变量,这样我们就可以将这个功能写成一个脚本或者函数,用在更多地方:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
$ cat phrase.sh #! /bin/sh# phrase -- search for words across lines# $1 = search string; remaining args = filenamessearch=$1for file in ${@:2}; do sed "/$search/b $!N h s/.*n// /$search/b g s/ *n/ / /$search/{ g b } g D" $filedone$ chmod +x phrase.sh$ ./phrase.sh 'the word' textthe word. Or if the word appears across two lines, likeIt will print this line, because theword appears across two lines. |
这只是一个开头,或者你也可以在此基础上扩展更多的功能。sed的命令从单个看来并没是很复杂,但是要用得好就有点难度了,所以需要多多实践,多多思考,这一点跟正则表达式的学习是一样的。如果觉得没有现成的学习环境,sed1line是一个不错的开始。
http://www.cnblogs.com/caibird2005/archive/2009/04/27/1444647.html
LINUX的awk和sed的常用用法
awk的用法
a w k语言的最基本功能是在文件或字符串中基于指定规则浏览和抽取信息
调用awk
有三种方式调用a w k,
第一种是命令行方式,如:
awk –F : ‘commands’ input-files
第二种方法是将所有a w k命令插入一个文件,并使a w k程序可执行,然后用a w k命令作为脚本的首行,以便通过键入脚本名称来调用它。
第三种方式是将所有的a w k命令插入一个单独文件,然后调用:
awk –f awk-script-file input-files
awk脚本
模式和动作
在命令中调用a w k时,a w k脚本由各种操作和模式组成。模式包括两个特殊字段B E G I N和E N D。
使用B E G I N语句设置计数和打印头。B E G I N语句使用在任何文本浏览动作之前。E N D语句用来在a w k完成文本浏览动作后打印输出文本总数和结尾状态标志。
实际动作在大括号{ }内指明。
域和记录
$ 0,意即所有域
• 确保整个a w k命令用单引号括起来。
• 确保命令内所有引号成对出现。
• 确保用花括号括起动作语句,用圆括号括起条件语句。
awk中的正则表达式
+ 使用+匹配一个或多个字符。
? 匹配模式出现频率。例如使用/X Y?Z/匹配X Y Z或Y Z。
awk '{if($4~/Brown/) print $0}' tab2
等效于
awk '$0 ~ /Brown/' tab2
内置变量
awk '{print NF,NR,$0}END{print FILENAME}' tab1
NF 域的总数
NR已经读取的记录数
FILENAME
awk '{if(NR>0 && $2~/JLNQ/) print $0}END{print FILENAME}' tab1
显示文件名
echo "/app/oracle/ora_dmp/lisx/tab1" | awk -F/ '{print $NF}'
定义域名
awk '{owner=$2;number=$3;if(owner~/SYSADMIN/ && number!=12101)print $0}END{print FILENAME}' tab1
awk 'BEGIN{NUM1=7}{if($1<=NUM1) print $0}END{print FILENAME}' tab1
当在a w k中修改任何域时,重要的一点是要记住实际输入文件是不可修改的,修改的只是保存在缓存里的a w k复本
awk 'BEGIN{NUM1=7}{if($1<=NUM1) print $1+2,$2,$3+100}END{print FILENAME}' tab1
只打印修改部分:用{}
awk 'BEGIN{NUM1=7}{if($1<=NUM1){$2="ORACLE"; print $0}}END{print "filename:"FILENAME}' tab1
可以创建新的域
awk 'BEGIN{NUM1=7;print "COL1"tCOL2"tCOL3"tCOL4"}{if($1<=NUM1){$4=$1*$3;$2="ORACLE"; print $0}}END{print "filename:"FILENAME}' tab1
打印总数:
awk 'BEGIN{NUM1=7;print "COL1"tCOL2"tCOL3"tCOL4"}{if($1<=NUM1){tot+=$3;$4=$1*$3;$2="ORACLE"; print $0}}END{print "filename:"FILENAME "total col3:" tot}' tab1
使用此模式打印文件名及其长度,然后将各长度相加放入变量t o t中。
ls -l | awk '/^[^d]/ {print$9""t"$5} {tot+=$5}END{print "total KB:" tot}'
内置字符串函数
gsub 字符要用引号,数字不用
awk 'gsub(/12101/,"hello") {print $0} END{print FILENAME}' tab1
awk 'gsub(/12101/,3333) {print $0} END{print FILENAME}' tab1
index
awk '{print index($2,"D")""t";print $0}' tab1
awk '{print index($2,"D")""t" $0}' tab1
length
awk '{print length($2)""t" $0}' tab1
ma
awk '{print match($2,"M")""t" $0}' tab1
split
awk '{print split($2,new_array,"_")""t" $0}' tab1
sub 替换成功返回1,失败返回0
awk '{print sub(/SYS/,"oracle",$2)""t" $0}' tab1
substr
awk '{print substr($2,1,3)""t" $0}' tab1
从s h e l l中向a w k传入字符串
echo "Stand-by" | awk '{print length($0)""t"$0}'
8 Stand-by
file1="tab1"
cat $file1 | awk '{print sub(/ADMIN/,"sss",$2)""t"$0}'
字符串屏蔽序列
" b 退格键 " t t a b键
" f 走纸换页 " d d d 八进制值
" n 新行 " c 任意其他特殊字符,例如" "为反斜线符号
" r 回车键
awk printf修饰符
- 左对齐
Wi d t h 域的步长,用0表示0步长
. p r e c 最大字符串长度,或小数点右边的位数
如果用格式修饰输出,要指明具体的域,程序不会自动去分辨
awk '{printf "%-2d %-10s %d"n", $1,$2,$3}' tab1
输出结果
9 SYSADMIN 12101
9 SYSADMIN 12101
14 SYSADMIN 121010000012002
9 SYSADMIN 12101
2 JLNQ 12101
2 JLNQ 12101
7 SYSADMIN 12101
7 SYSADMIN 12101
6 ac_ds_e_rr_mr 13333
向一行a w k命令传值
awk 'BEGIN{SYS="SYSADMIN"}{if($2==SYS) printf "%-2d %-10s %d"n", $1,$2,$3}' tab1
在动作后面传入
awk '{if($2==SYS) printf "%-2d %-10s %d"n", $1,$2,$3}' SYS="SYSADMIN" tab1
awk脚本文件
SED用法
sed怎样读取数据
s e d从文件的一个文本行或从标准输入的几种格式中读取数据,将之拷贝到一个编辑缓冲区,然后读命令行或脚本的第一条命令,并使用这些命令查找模式或定位行号编辑它。重复此过程直到命令结束。
调用s e d有三种方式
使用s e d命令行格式为:
sed [选项] s e d命令 输入文件。
记住在命令行使用s e d命令时,实际命令要加单引号。s e d也允许加双引号。
使用s e d脚本文件,格式为:
sed [选项] -f sed脚本文件 输入文件
要使用第一行具有s e d命令解释器的s e d脚本文件,其格式为:
s e d脚本文件 [选项] 输入文件
使用s e d在文件中定位文本的方式
x x为一行号,如1
x , y 表示行号范围从x到y,如2,5表示从第2行到第5行
/ p a t t e r n / 查询包含模式的行。例如/ d i s k /或/[a-z]/
/ p a t t e r n / p a t t e r n / 查询包含两个模式的行。例如/ d i s k / d i s k s /
p a t t e r n / , x 在给定行号上查询包含模式的行。如/ r i b b o n / , 3
x , / p a t t e r n / 通过行号和模式查询匹配行。3 , / v d u /
x , y ! 查询不包含指定行号x和y的行。1 , 2 !
sed编辑命令
p 打印匹配行
= 显示文件行号
a" 在定位行号后附加新文本信息
i" 在定位行号后插入新文本信息
d 删除定位行
c" 用新文本替换定位文本
s 使用替换模式替换相应模式
r 从另一个文件中读文本
w 写文本到一个文件
q 第一个模式匹配完成后推出或立即推出
l 显示与八进制A S C I I代码等价的控制字符
{ } 在定位行执行的命令组
n 从另一个文件中读文本下一行,并附加在下一行
g 将模式2粘贴到/pattern n/
y 传送字符
n 延续到下一输入行;允许跨行的模式匹配语句
sed编程举例
打印单行 sed -n '2p' quo*
打印范围 sed -n '1,3p' quote.txt
打印有此模式的行 sed -n '/disco/'p quote.txt
使用模式和行号进行查询 sed -n '4,/The/'p quote.txt
sed -n '1,/The/'p quote.txt 会打印所有记录?
用.*代表任意字符 sed -n '/.*ing/'p quote.txt
打印行号 sed -e '/music/'= quote.txt 或sed -e '/music/=' quote.txt
如果只打印行号及匹配行,必须使用两个s e d命令,并使用e选项。
第一个命令打印模式
匹配行,第二个使用=选项打印行号,格式为sed -n -e /pattern/p -e /pattern/=。
sed -n -e '/music/p' -e '/music/'= quote.txt
先打印行号,再打印匹配行
sed -n -e '/music/=' -e '/music/'p quote.txt
替换
sed 's/The/Wow!/' quote.txt
保存到文件
sed '1,2 w filedt' quote.txt
读取文件,在第一行后面读取
sed '1 r sedex.txt' quote.txt
替换字符系列
如果变量x含有下列字符串:
x="Department+payroll%Building G"
要实现以下转换:
+ to 'of'
% to located
语句: echo $x | sed 's/"+/ of /g' | sed 's/"%/ located /g'
--------------------------------------------------------------
多交流,多思考,多总结,坚持学好ORACLE !
E-mail:dlut_lsx@163.com
QQ:23336581
awk&sed!!!awk&sed!!!awk&sed!!!awk&sed!!!
http://zhouyuqin.blog.51cto.com/5132926/967141
事前准备
1.主机
node1:172.16.133.11
2.作为实验的文件
/etc/passwd

/etc/fstab

qinqin

- cp /etc/passwd .
- cp /etc/fstab .
一、grep用法详解
1.grep是干什么的
grep的全名是Galobal research Regular Expression and Pringtiong,即搜索正则表达式,也就是说grep简单来讲就是用来搜索匹配字符的
2.grep分类
grep有基本正则表达式和扩展正则表达式之分,不过她们的作用域和使用方法大同小异
3.grep用法及选项
首先普通的用法:grep [option] 'PATTERN' file file2...
例:grep 'root' /etc/passwd搜索在/etc/passwd中的root字符的那一行
选项:
--color将搜索到的字符予以颜色加以标识,易于辨认
grep --color 'root' passwd

-v取反,即除了匹配到的行其余都显示
grep -v 'root' passwd

-i忽略大小写进行匹配
grep -i 'label' fstab
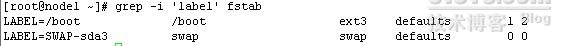
-o仅显示匹配到的字符串
grep -o 'root' passwd
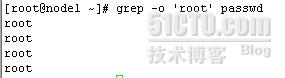
单独显示本机ip地址和子网掩码
- ifconfig | grep -E -o --color "\<([1-9]|[1-9][0-9]|1[1-9][1-9]|2[1-5][0-5])\>.\<([1-9]|[1-9][0-9]|1[1-9][1-9]|2[1-5][0-5])\>.\<([1-9]|[1-9][0-9]|1[1-9][1-9]|2[1-5][0-5])\>.\<([1-9]|[1-9][0-9]|1[1-9][1-9]|2[1-5][0-5])\>"

-q静默模式,不输出,在shell脚本中经常用到
grep -q 'root' passwd
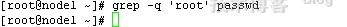
-A匹配到的行向下多显示n行,匹配到root后,连其后的n行一并显示
grep -A 2 'root' fstab

-B匹配到的行向上多显示n行,匹配到root后,连其上的n行一并显示
grep -B 3 'student' passwd

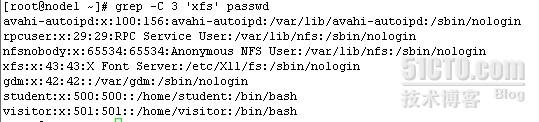
-C匹配到的行多显示其上下n行,匹配到root后,其上下n行一并显示
grep -C 3 'xfs' passwd
4.基本正则表达式
.(点号):表示匹配任意单个字符;
grep -o "r." passwd

*匹配前面一个字符任意次(可以是0次)
grep 'ab*c' qinqin
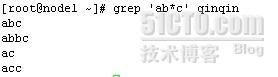
.*:表示任意长度的任意字符(两个一起用时,贪婪模式,能匹配多长就匹配多长)
grep -o "r.*" passwd
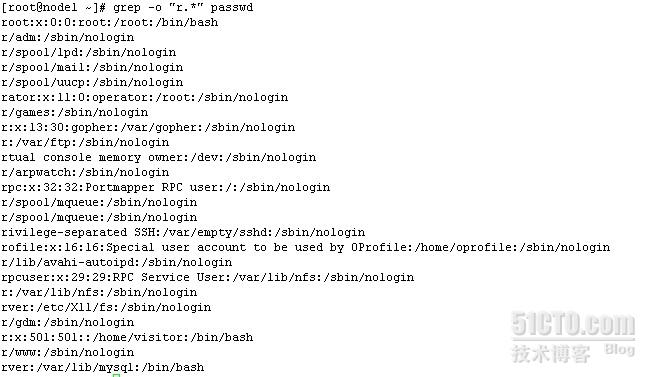
[]指定范围内的任意单个字符[^a-z]指定范围内之外的字符
grep "a[a-z]c" qinqin

X\{m,n\}:X出现大于m次,小于n次
grep "ab\{1,3\}c" qinqin

X\{m,\}:X出现大于m次,无上限
grep "ab\{2,\}c" qinqin

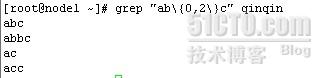
X\{0,n\}:X出现小于n次
grep "ab\{0,2\}c" qinqin
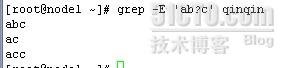
?:匹配其前面的字符0次或一次(-E,使用扩展表达式)
grep -E 'ab?c' qinqin
锚定符:
^:锚定行首(行首匹配)
grep "^root" passwd

$:锚定行尾(行尾匹配)
grep "bash$" passwd

^$:空白行
\<或者\b:锚定词首;
grep "\<root" passwd

\>或者\b:锚定词尾
grep "bash\>" passwd

\(\):分组后向引用:\1,\2
grep "l\([0-9]\{1,\}\):\1:.* \1" /etc/inittab

5.扩展正则表达式
extended regexp:扩展正则表达式(egrep支持这种)
\{\}-->{}
\(\)-->()
+:做次数匹配,表示匹配其前的字符一次或多次
|:或者 a|b,C|cat:C,cat;(C|c)at:Cat,cat
明标签时使用 :label的格式,跳转时不用冒号;
二、sed命令详解
1.sed是什么
Sed全名为Stream EDitor,即流式编辑器,行编辑器
2.sed常用用法
sed [options] 'script(模式命令)' input_file...
sed [options] -f script_file(sed脚本) input_file...
sed 'ADDR1,ADDR2command' input_file;例如sed '1,2d' fstab(可输出重定向到别的文件)
sed '1,2!(对命令取反)d' fstab除了第一行,第二行,其余全删除

sed '/PATTERN/command' input_file(使用基本正则表达式的原字符,而不实用grep)
sed '/PATTERN1/,/PATTERN2/command' input_file从第一次被模式PATTERN1匹配到的行到第一次被PATTERN2匹配到的行执行命令command
3.sed常用选项及模式
(1).常用选项
-n静默模式,不打印模式空间中的内容,例如sed '1,3p' fstab会显示所有文件,其中前三行,显示两次,加了-n之后只会显示前三行
sed -n '1,3p' fstab
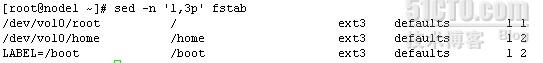
-i直接操作原文件
-i
sed -i '5d' fstab

-r使用扩展正则表达式
-e多脚本处理
sed -e 's/a/e/g' -e 's/b/f/g' -e 's/c/g/g' qinqin
(2).常用模式
d删除指定行
p模式空间中的文本在处理之前,每一次都会先显示:p,显示,指定行会被显示两次
$表示最后一行
a \:在模式匹配到的行后面添加新内容
sed '/a/a \this is a comment line.\n' qinqin

r FILE:读文件追加到别的文件后面
sed '2r qinqin' fstab
i \:在模式匹配到的行前面添加新内容
sed '/abc/i \this is a test' qinqin

w FILE:把这个文件中模式所匹配到的行写到另一个文件中
sed -n '/root/w qinqin' fstab

s :s/PATTERN/string/ 例如:s@/dev/vo10/root@/dev/sda2/
g:匹配全文
i:忽略大小写
s/PATTERN/&string/在前面匹配到的PATTERN后面加上string
sed 's/root/qinqin/g' fstab

n:读取下一行,以覆盖方式,一次读进来
sed 'n;p' fstab

N:读取下一行,以追加方式,在模式空间中两行做一行处理(N;N三行一起处理)
sed 'N;p' fstab

扩展sed 'N;s/\n/ /g' fstab

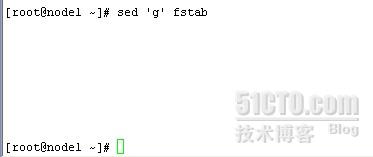
g:将保留空间中的内容复制到模式空间,覆盖的方式
sed 'g' fstab
G:将保留空间中的内容复制到模式空间,追加的方式
sed 'G' fstab

h:将模式中的模式空间复制到保留空间,覆盖的方式
sed -n 'h;n;G;h;n;G;p' fstab

H:将模式中的模式空间复制到保留空间,追加的方式
sed -n 'H;n;G;h;n;G;p' fstab

b label:跳转 例如:sed -n '3b;p'跳转到第三行 seb '\#b' test跳过有#号的行
x:将保留空间和模式空间对调
t label: 测试:前面的s命令执行成功就跳转到标记位置
三、awk命令详解
awk常用用法
awk [options] 'script' file1, file2, ...
awk [options] 'PATTERN { action }' file1, file2, ...
-F指定分隔符
1.awk的输出:
(1).print
print的使用格式:
print item1, item2, ...
要点:
①.各项目之间使用逗号隔开,而输出时则以空白字符分隔;
②.输出的item可以为字符串或数值、当前记录的字段(如$1)、变量或awk的表达式;数值会先转换为字符串,而后再输出;
③.print命令后面的item可以省略,此时其功能相当于print $0, 因此,如果想输出空白行,则需要使用print "";
例子:
awk 'BEGIN { print "line one\nline two\nline three" }'
awk -F: '{ print $1, $2 }' passwd

④.内置变量:
ORS(output record separator)
OFS(output field separator)
FS: field separator,默认是空白字符;
RS: Record separator,默认是换行符;
NR: The number of input records,awk命令所处理的记录数;如果有多个文件,这个数目会把处理的多个文件中行统一计数;
NF:Number of Field,当前记录的field个数;
FNR: 与NR不同的是,FNR用于记录正处理的行是当前这一文件中被总共处理的行数;
ARGV: 数组,保存命令行本身这个字符串,如awk '{print $0}' a.txt b.txt这个命令中,ARGV[0]保存awk,ARGV[1]保存a.txt;
ARGC: awk命令的参数的个数;
(2).printf
printf命令的使用格式:
printf format, item1, item2, ...
要点:
①.其与print命令的最大不同是,printf需要指定format;
②.format用于指定后面的每个item的输出格式;
③.printf语句不会自动打印换行符;\n
④.format格式的指示符都以%开头,后跟一个字符;如下:
%c: 显示字符的ASCII码;
%d, %i:十进制整数;
%e, %E:科学计数法显示数值;
%f: 显示浮点数;
%g, %G: 以科学计数法的格式或浮点数的格式显示数值;
%s: 显示字符串;
%u: 无符号整数;
%%: 显示%自身;
⑤.修饰符:
N: 显示宽度;
-: 左对齐;
+:显示数值符号;
例子:
awk -F: '{printf "%-15s %i\n",$1,$3}' passwd

2.awk输出重定向
print items > output-file
print items >> output-file
print items | command
特殊文件描述符:
/dev/stdin:标准输入
/dev/sdtout: 标准输出
/dev/stderr: 错误输出
/dev/fd/N: 某特定文件描述符,如/dev/stdin就相当于/dev/fd/0;
例子:
awk -F: '{printf "%-15s %i\n",$1,$3 >> "qinqin" }' passwd

3.awk的操作符:
(1).算术操作符:
-x: 负值
+x: 转换为数值;
x^y:
x**y: 次方
x*y: 乘法
x/y:除法
x+y:
x-y:
x%y:
(2).字符串操作符:
只有一个,而且不用写出来,用于实现字符串连接;
(3).赋值操作符:
=
+=
-=
*=
/=
%=
^=
**=
++
--
需要注意的是,如果某模式为=号,此时使用/=/可能会有语法错误,应以/[=]/替代;
(4).布尔值
awk中,任何非0值或非空字符串都为真,反之就为假;
(5).比较操作符:
x < y True if x is less than y.
x <= y True if x is less than or equal to y.
x > y True if x is greater than y.
x >= y True if x is greater than or equal to y.
x == y True if x is equal to y.
x != y True if x is not equal to y.
x ~ y True if the string x matches the regexp denoted by y.
x !~ y True if the string x does not match the regexp denoted by y.
subscript in array True if the array array has an element with the subscript subscript.
(6)表达式间的逻辑关系符:
&&
||
(7).条件表达式:
selector?if-true-exp:if-false-exp
(8).函数调用:
function_name (para1,para2)
4.awk的模式:
awk 'program' input-file1 input-file2 ...
其中的program为:
pattern { action }
pattern { action }
常见的模式类型:
(1).Regexp: 正则表达式,格式为/regular expression/
(2).expresssion: 表达式,其值非0或为非空字符时满足条件,如:$1 ~ /foo/ 或 $1 == "magedu",用运算符~(匹配)和~!(不匹配)。
(3).Ranges: 指定的匹配范围,格式为pat1,pat2
(4).BEGIN/END:特殊模式,仅在awk命令执行前运行一次或结束前运行一次
(5).Empty(空模式):匹配任意输入行;
常见的Action有:
(1).Expressions:
(2).Control statements
(3).Compound statements
(4).Input statements
(5).Output statements
/正则表达式/:使用通配符的扩展集。
关系表达式:可以用下面运算符表中的关系运算符进行操作,可以是字符串或数字的比较,如$2>%1选择第二个字段比第一个字段长的行。
模式匹配表达式:
模式,模式:指定一个行的范围。该语法不能包括BEGIN和END模式。
BEGIN:让用户指定在第一条输入记录被处理之前所发生的动作,通常可在这里设置全局变量。
END:让用户在最后一条输入记录被读取之后发生的动作。
5.awk控制语句:
(1).if-else
语法:if (condition) {then-body} else {[ else-body ]}
例子:
awk -F: '{if ($1=="root") print $1, "Admin"; else print $1, "Common User"}' passwd

awk -F: '{if ($1=="root") printf "%-15s: %s\n", $1,"Admin"; else printf "%-15s: %s\n", $1, "Common User"}' passwd

awk -F: -v sum=0 '{if ($3>=500) sum++}END{print sum}' passwd
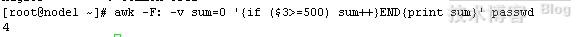
(2).while
语法: while (condition){statement1; statment2; ...}
(3).do-while
语法: do {statement1, statement2, ...} while (condition)
(4).for
语法: for ( variable assignment; condition; iteration process) { statement1, statement2, ...}
for循环还可以用来遍历数组元素:
语法: for (i in array) {statement1, statement2, ...}
(5).case
语法:switch (expression) { case VALUE or /REGEXP/: statement1, statement2,... default: statement1, ...}
(6).break 和 continue
常用于循环或case语句中
(7).next
提前结束对本行文本的处理,并接着处理下一行;
6.awk中使用数组:
array[index-expression]
index-expression可以使用任意字符串;需要注意的是,如果某数据组元素事先不存在,那么在引用其时,awk会自动创建此元素并初始化为空串;因此,要判断某数据组中是否存在某元素,需要使用index in array的方式。
要遍历数组中的每一个元素,需要使用如下的特殊结构:
for (var in array) { statement1, ... }
其中,var用于引用数组下标;
例子:
netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'
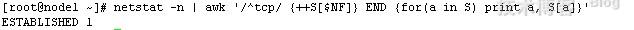
每出现一被/^tcp/模式匹配到的行,数组S[$NF]就加1,NF为当前匹配到的行的最后一个字段,此处用其值做为数组S的元素索引;
awk '{counts[$1]++}; END {for(url in counts) print counts[url], url}' /var/log/httpd/access_log
用法与上一个例子相同,用于统计某日志文件中IP地的访问量
7.awk的内置函数:
split(string, array [, fieldsep [, seps ] ])
功能:将string表示的字符串以fieldsep为分隔符进行分隔,并将分隔后的结果保存至array为名的数组中;
netstat -ant | awk '/:80/{split($5,clients,":");IP[clients[1]]++}END{for(i in IP){print IP[i],i}}' | sort -rn | head -50
length([string])
功能:返回string字符串中字符的个数;
substr(string, start [, length])
功能:取string字符串中的子串,从start开始,取length个;start从1开始计数;
system(command)
功能:执行系统command并将结果返回至awk命令
systime()
功能:取系统当前时间
本文出自 “周钰钦” 博客,请务必保留此出处http://zhouyuqin.blog.51cto.com/5132926/967141

 浙公网安备 33010602011771号
浙公网安备 33010602011771号