


SQl 2005 For XMl 简单查询(Raw,Auto,Path模式)(2)
2010-04-26 18:48 苏飞 阅读(3931) 评论(5) 收藏 举报文章导航 SQL Server 2005 学习笔记系列文章导航
在SQl 2005 For XMl 简单查询(Raw,Auto,Path模式)(1) 里我们说了关于Path,Raw和Auto模式的用法,其实里面不仅仅 是这些简单的操作,还有一些其它的特性,比如说Type或OpenXml方法,sp_xml_preparedocument存储过程 等这些增加的东东,我们来一个一个的看吧,
第一个Type关键字,Type大家都 知道 英文意思是类型,在这里也是和类型相关的,意思就是说让子集里面类型和集合的类型统一,具体 是怎么统一的这个我也不懂,大家还得自己去查或是找找MS的网站吧,我们还用上一节的数据库和表来实现具体表的结构还请大家参考SQl 2005 For XMl 简单查询(Raw,Auto,Path模式)(1)里面的 我们来做写一个这样的子查询
SELECT SID,SName,(SELECT ClassInfo.CName from ClassInfo WHERE ClassInfo.CID=Students.CID FOR xml raw)
FROM Students
ORDER BY CID FOR xml auto
我们可以清楚的看到子查询返回的是一个Xml类型的而外面的集合也是一个Xml类型的,这个时候如果我们直接执行的话就会发生错误
消息 6809,级别 16,状态 1,第 1 行
不能将未命名的表用作 XML 标识符,也不能将未命名的列用于属性名称。请在 SELECT 语句中使用 AS 对未命名的列/表进行命名。
我们知道 如果是正常的情况下是可以的,无非就是这一列没有列名,但是是不会报错的,那这个时候我们就可以这样来写了
FROM Students
ORDER BY CID FOR xml auto
只要在子集的后面加上一个Type就可以了,我们的Type就是在这种情况下使用的,也可能是我了解的太少了,我个人感觉 这个东东是没有什么太大的用处的,我们可以这样来写
FROM Students
ORDER BY CID FOR xml auto
只要我们给这一列起一个别名,无论你使用那种模式都 不用加什么Type了,所以最少在这个时候基本不用使用谁会让一列没有名称呢?
大家把语句直接执行就Ok了,
我们来看第二个OpenXml方法,他其实要和sp_xml_preparedocument存储过程合起来用比较好,我们来看个例子吧
 代码
代码

set @docxml='
<st>
<row>
<SID>1</SID>
<SName>苏飞</SName>
<CName><row><CName>博客园一班</CName></row></CName>
</row>
<row>
<SID>2</SID>
<SName>金色海洋</SName>
<CName><row><CName>博客园一班</CName></row></CName>
</row>
</st>';
DECLARE @handel int;
EXEC sp_xml_preparedocument @handel output, @docxml
SELECT * from OPENXML(@handel,'/st/row',2)
WITH(SID int ,SName varchar(50),CName varchar(50))
查询得到的结果
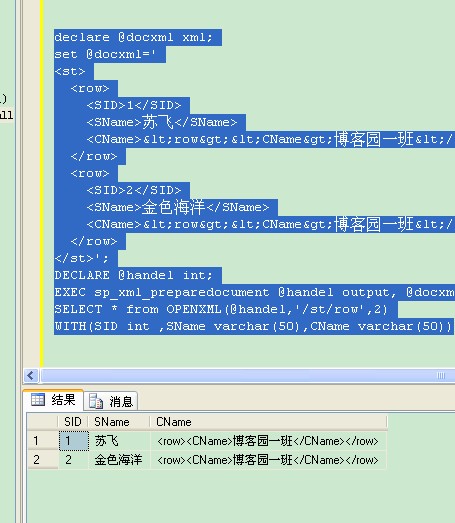
一个一个的分析一下吧,sp_xml_preparedocument是把一个Xml文件转成XmlDocument文档形式
而OpenXml是在XmlDocument中查询出相应的内容关转成Table形式输出也可以是视图,OPENXML 是一个行集提供程序,类似于表或视图,提供内存中 XML 文档上的行集。OPENXML 通过提供 XML 文档内部表示形式的行集视图,允许访问 XML 数据,就像它是关系行集一样。行集中的记录可以存储在数据库表中。OPENXML 可在用于指定源表或源视图的 SELECT 和 SELECT INTO 语句中使用。
首先 sp_xml_preparedocument 存储过程分析 XML 文档。分析后的文档是 XML 文档中各节点(元素、属性、文本和注释)的树状表示形式。然后,OPENXML 引用此经过分析的 XML 文档,并提供此 XML 文档全部或部分内容的行集视图。使用 OPENXML 的 INSERT 语句可将数据从这样的行集插入数据库表中。可以使用多个 OPENXML 调用来提供 XML 文档中各部分的行集视图,并对它们进行处理,例如,将它们插入不同的表中。此过程也称为“将 XML 拆分到表中”。
OPENXML 是一个 Transact-SQL 关键字,对内存中的 XML 文档提供与表或视图相似的行集。OPENXML 允许像访问关系行集一样访问 XML 数据。它通过提供以内部形式表示的 XML 文档的行集视图来实现这一点。行集中的记录可以存储在数据库表中。
无论行集提供程序(视图或 OPENROWSET)可以在何处作为源出现,都可以在 SELECT 和 SELECT INTO 语句中使用 OPENXML。有关 OPENXML 语法的信息,请参见 OPENXML (Transact-SQL)。
若要使用 OPENXML 编写对 XML 文档执行的查询,必须先调用 sp_xml_preparedocument。它将分析 XML 文档并向准备使用的已分析文档返回一个句柄。已分析文档以文档对象模型 (DOM) 树的形式说明 XML 文档中的各种节点。该文档句柄传递给 OPENXML。然后 OPENXML 根据传递给它的参数提供一个该文档的行集视图。
必须通过调用 sp_xml_removedocument 系统存储过程从内存中删除以内部形式表示的 XML 文档来释放内存。
下图说明了该过程。
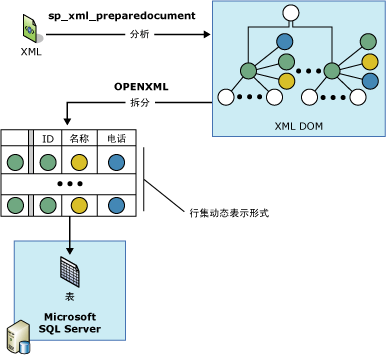
请注意,要理解 OPENXML,需要熟悉 XPath 查询并理解 XML。有关 SQL Server 中 XPath 支持的详细信息,请参阅Using XPath Queries in SQLXML 4.0。
OPENXML 允许将行和列的 XPath 模式参数化为变量。如果程序员向外部用户公开参数化(例如通过外部调用的存储过程提供参数),这种参数化可能会导致引入 XPath 表达式。为了避免这种潜在的安全问题,建议切勿向外部调用方公开 XPath 参数。
OPENXML 的参数包括:
- XML 文档句柄 (idoc)
- 标识要映射到行的节点的 XPath 表达式 (rowpattern)
- 对要生成的行集的说明
- 行集列和 XML 节点之间的映射
XML 文档句柄 (idoc)
sp_xml_preparedocument 存储过程返回该文档句柄。
标识要处理的节点的 XPath 表达式 (rowpattern)
指定为 rowpattern 的 XPath 表达式标识 XML 文档中的一组节点。rowpattern 标识的每个节点对应于 OPENXML 所生成的行集中的一行。
XPath 表达式标识的节点可以是 XML 文档中的任何 XML 节点。如果 rowpattern 标识 XML 文档中的一组元素,则所标识的每个元素节点在行集中都占一行。例如,如果 rowpattern 以属性结束,则将为 rowpattern 选择的每个属性节点创建一行。
对要生成的行集的说明
OPENXML 使用行集架构来生成结果行集。指定行集架构时,可以使用下列选项。
使用边缘表格式
应使用边缘表格式来指定行集架构。请勿使用 WITH 子句。
否则,OPENXML 将以边缘表格式返回行集。边缘表这种称谓源于已分析的 XML 文档树中的每个边缘都映射到行集中的一行。
边缘表在单个表中表示 XML 文档的细密结构。此结构包括元素名称和属性名称、文档层次结构、命名空间和处理指令。通过边缘表格式可以获得无法通过元属性表现的其他信息。有关元属性的详细信息,请参阅“在 OPENXML 中指定元属性”(29bfd1c6-3f9a-43c4-924a-53d438e442f4)。
通过边缘表提供的其他信息可以存储和查询元素和属性的数据类型以及节点类型,另外还可以存储和查询有关 XML 文档结构的信息。有了这些其他信息,还可以创建您自己的 XML 文档管理系统。
通过使用边缘表,可以编写这样一些存储过程:将 XML 文档作为二进制大型对象 (BLOB) 输入,生成边缘表,然后以更为详细的级别提取和分析文档。此详细级别可以包括查找文档层次结构、元素名称和属性名称、命名空间和处理指令。
当映射到其他关系格式不合逻辑且 ntext 字段没有提供足够的结构信息时,边缘表还可以用作 XML 文档的存储格式。
在可以使用 XML 分析器检查 XML 文档的情况下,使用边缘表也可以获得相同的信息。
下表介绍了边缘表的结构。
| 列名 | 数据类型 | 说明 |
|---|---|---|
|
id |
bigint |
是文档节点的唯一 ID。 根元素的 ID 值为 0。保留负 ID 值。 |
|
parentid |
bigint |
标识节点的父节点。此 ID 标识的父节点不一定是父元素。具体情况取决于此 ID 所标识节点的子节点的节点类型。例如,如果节点为文本节点,则其父节点可能是一个属性节点。 如果节点位于 XML 文档的顶层,则其 ParentID 为 NULL。 |
|
节点类型 |
int |
标识节点类型,是对应于 XML 对象模型 (DOM) 节点类型编号的一个整数。 下列值是可以显示在此列中以指明节点类型的值: 1 = 元素节点 2 = 属性节点 3 = 文本节点 4 = CDATA 部分节点 5 = 实体引用节点 6 = 实体节点 7 = 处理指令节点 8 = 注释节点 9 = 文档节点 10 = 文档类型节点 11 = 文档片段节点 12 = 表示法节点 有关详细信息,请参阅 Microsoft XML (MSXML) SDK 中的“节点类型属性”主题。 |
|
localname |
nvarchar(max) |
提供元素或属性的本地名称。如果 DOM 对象没有名称则为 NULL。 |
|
prefix |
nvarchar(max) |
是节点名称的命名空间前缀。 |
|
namespaceuri |
nvarchar(max) |
是节点的命名空间 URI。如果值是 NULL,则命名空间不存在。 |
|
datatype |
nvarchar(max) |
是元素或属性行的实际数据类型,否则是 NULL。数据类型是从内联 DTD 中或从内联架构中推断得出。 |
|
prev |
bigint |
是前一个同级元素的 XML ID。如果前面没有同级元素则为 NULL。 |
|
text |
ntext |
包含文本形式的属性值或元素内容。如果边缘表项不需要值则为 NULL。 |
使用 WITH 子句指定现有表
可以使用 WITH 字句指定现有表的名称。若要执行此操作,只需指定现有的表名称,OPENXML 可以使用该表的架构生成行集。
使用 WITH 子句指定架构
可以使用 WITH 子句指定完整架构。在指定行集架构时,可指定列名、它们的数据类型,以及它们到 XML 文档的映射。
可以使用 SchemaDeclaration 中的 ColPattern 参数来指定列模式。指定的列模式用于将行集列映射到 rowpattern 标识的 XML 节点并确定映射类型。
如果没有为列指定 ColPattern,则行集列根据 flags 参数指定的映射来映射到具有相同名称的 XML 节点。但是,如果在 WITH 子句中将 ColPattern 指定为架构描述的一部分,则它将覆盖在 flags 参数中指定的映射。
行集列和 XML 节点之间的映射
在 OPENXML 语句中,可以选择指定行集列和 rowpattern 标识的 XML 节点之间的映射类型(如以属性为中心或以元素为中心)。此信息用于 XML 节点和行集列之间的转换。
可以采用下列两种方式之一来指定映射,也可以同时采用来指定映射:
- 通过使用 flags 参数
由 flags 参数指定的映射采用名称对应,即 XML 节点映射到具有相同名称的对应行集列。 - 通过使用 ColPattern 参数
ColPattern 是 XPath 表达式,被指定为 WITH 子句中的 SchemaDeclaration 的一部分。在 ColPattern 中指定的映射覆盖 flags 参数指定的映射。
ColPattern 可以用于指定映射类型(如以属性为中心或以元素为中心),以覆盖或增强 flags 指定的默认映射。
在下列情况下指定 ColPattern:
- 行集中的列名不同于它映射到的元素名称或属性名称。在这种情况下,ColPattern 用于标识行集列映射到的 XML 元素名称和属性名称。
- 希望将元属性特性映射到列。在这种情况下,ColPattern 用于标识行集列映射到的元属性。有关如何使用元属性的详细信息,请参阅在 OPENXML 中指定元属性。
- 行集中的列名不同于它映射到的元素名称或属性名称。在这种情况下,ColPattern 用于标识行集列映射到的 XML 元素名称和属性名称。
flags 和 ColPattern 参数都是可选的。如果未指定映射,则采用以属性为中心的映射。以属性为中心的映射是 flags 参数的默认值。
以属性为中心的映射
将 OPENXML 中的 flags 参数设置为 1 (XML_ATTRIBUTES) 将指定“以属性为中心”的映射。如果 flags 包含 XML_ATTRIBUTES,则显示的行集提供或使用其中每个 XML 元素都表示为一行的那些行。XML 属性根据名称对应映射到 SchemaDeclaration 中定义的属性,或 WITH 子句的 Tablename 提供的属性。名称对应表示具有特定名称的 XML 属性都以相同名称存储在行集中的列内。
如果列名不同于它映射到的属性名称,则必须指定 ColPattern。
如果 XML 属性具有命名空间限定符,则行集中的列名也必须有该限定符。
以元素为中心的映射
将 OPENXML 中的 flags 参数设置为 2 (XML_ELEMENTS) 将指定“以元素为中心”的映射。除了下列差异外,它与“以属性为中心”的映射相似:
- 除非指定列级模式,否则映射的名称对应(例如,映射到具有相同名称的 XML 元素的列)选择不复杂的子元素。在检索过程中,如果子元素复杂(因为它包含其他子元素),则将列设置为 NULL。然后忽略子元素的属性值。
- 对于具有相同名称的多个子元素,将返回第一个节点。
说说它的优点吧
* Xml可以帮助我们实现结构化或是非结构化的数据都能统一处理,
* 在关系模式中可以可变化内容
* 可以选择最合适的数据模型来处理数据
* 基于Xquery的数据查询和数据修改
参考资料:http://msdn.microsoft.com/zh-cn/library/ms178107(SQL.90).aspx

 浙公网安备 33010602011771号
浙公网安备 33010602011771号