



记一次线上由nginx upstream keepalive与http协议"协作"引起的接口报错率飙高事件
年前接到个任务,说要解决线上一些手机客户端接口报错率很高的问题.拿到了监控邮件,粗略一看,各种50%+的错误率,简直触目惊心.这种疑难杂症解决起来还是挺好玩的,于是撸起袖子action.
最终的结果虽然报错问题得到了解决,但是感觉并不是最根本的解决方案.
下面把解决的过程和目前的问题放出来一起探讨下.
第一步,针对错误进行跟踪,初步定位问题
由于之前客户端同学在请求中添加了唯一标示request_id. 所以选择了一些报错的记录进行跟踪. 打开了jetty的request_log请求日志,经查发现出错请求会出现两种情况:
1,未在request_log中出现,既请求都未能从nginx发送至后端服务
2,在request_log中出现,并返回成功(状态码200,并且响应时间很快)
由此暂时排除后端服务问题,推测问题出现在nginx与服务之间的链接.
第二步,查看nginx日志,初步优化
经由第一步得出结果,进一步观察出错时候的nginx日志.
发现出错时nginx日志中会出现”no live upstreams while connecting to upstream”错误.并伴随大量”upstream prematurely closed connection while reading response header from upstream”错误.
经查阅资料得出nginx负载与健康检查机制的简陋可能造成某些请求无法发送到活动的后端服务上. 遂添加nginx负载机制配置以期解决问题.
参考资料:
http://www.tuicool.com/articles/AfeuUje
https://segmentfault.com/a/1190000002446630
在线上backends中添加了以下配置:
备注: 因涉及服务器机密,IP及端口均经过修改
upstream mobile {
server 192.168.0.10:6001 max_fails=10 fail_timeout=10s;
server 192.168.0.10:6002 max_fails=10 fail_timeout=10s;
server 192.168.0.10:6003 max_fails=10 fail_timeout=10s;
server 192.168.0.10:6004 max_fails=10 fail_timeout=10s;
keepalive 64;
}
经过一段时间观察后,发现"no live upstreams while connecting to upstream"错误大幅度减少,但502错误率依旧,依然存在大量"upstream prematurely closed connection while reading response header from upstream"
第三步,upstream prematurely closed connection while reading response header from upstream
添加第二步的配置后观察与思考,推测问题可能出现在以下两个方面:
1,后端jetty服务压力过大导致无法完成响应.
2,网络原因导致请求出问题.
那么一项一项的排查吧.
排除jetty服务压力
先排查jetty服务压力是否造成报错.遂添加了对jetty线程及请求队列的监控. 也引发了之前一篇关于jetty线程监控的文章.需要的朋友自行取用.
http://www.cnblogs.com/succour/p/6266283.html
观察后发现即使高峰时期jetty中的线程数依然没有过大压力,没有出现队列拥堵现象.所以将重心放于网络原因.
释放招式:tcpdump抓包.网络问题浮出水面.
进行tcp链接抓包并解析,分析出错原因.
使用tcpdump抓包并解析后发现:
出错请求都会在此tcp流中前一个请求未收到响应时就关闭链接
既一个tcp连接中的http请求与响应不能一一对应且请求数永远比响应数多1.
而追踪未出错请求时则发现tcp流中请求与响应都可一一对应.
由于我们线上在nginx中都配置了nginx upstream中的keepalive,既nginx与后端服务链接的复用,推测可能是前一个请求结束后或keepalive时间到后nginx关闭了链接,而新的请求还在发送中就被中断了.
第四步,去除keepalive配置,解决问题
在线上的upstream中去除了keepalive配置,配置变为了:
备注: 因涉及服务器机密,IP及端口均经过修改
upstream mobile {
server 192.168.0.10:6001 max_fails=10 fail_timeout=10s;
server 192.168.0.10:6002 max_fails=10 fail_timeout=10s;
server 192.168.0.10:6003 max_fails=10 fail_timeout=10s;
server 192.168.0.10:6004 max_fails=10 fail_timeout=10s;
}
修改生效当时那茫茫多的"upstream prematurely closed connection while reading response header from upstream"瞬间消失. 观察了一天之后,502错误率明显下降,现已下降到0.00x%的级别.
说明推测是正确的,nginx upstream的keeplive导致了此次问题的出现.
第五步,后续
虽然去除keepalive解决了问题,但是keepalive对于链接的复用确实是可以提高通信效率的.粗暴的删除也只能是暂时的解决方案.而且也并没有查阅到相关keepalive会引起此问题的文章.
所以问题的根源依旧没有水落石出.
继续推测可能是由于线上tcp链接的配置问题导致的.
于是将线上的tcp配置拷贝到测试环境,添加上keepalive对测试环境进行压测,奇异的一幕出现了...问题并没有被复现...
tcp配置参考资料:
http://www.cnblogs.com/zengkefu/p/5749009.html
一脸懵逼的我继续观察tcp抓到的包以及nginx中的错误日志...
终于是有所发现...
原来在nginx错误日志中以HTTP/1.1协议发送的请求,到了tcp抓包中竟然被悄悄改为了HTTP/1.0协议...并且Connection请求头为close! nginx中所有报错为"upstream prematurely closed connection while reading response header from upstream"的请求所抓到的包全部都是这种情况...

注意ip地址以及时间,确定与下图为同一请求.
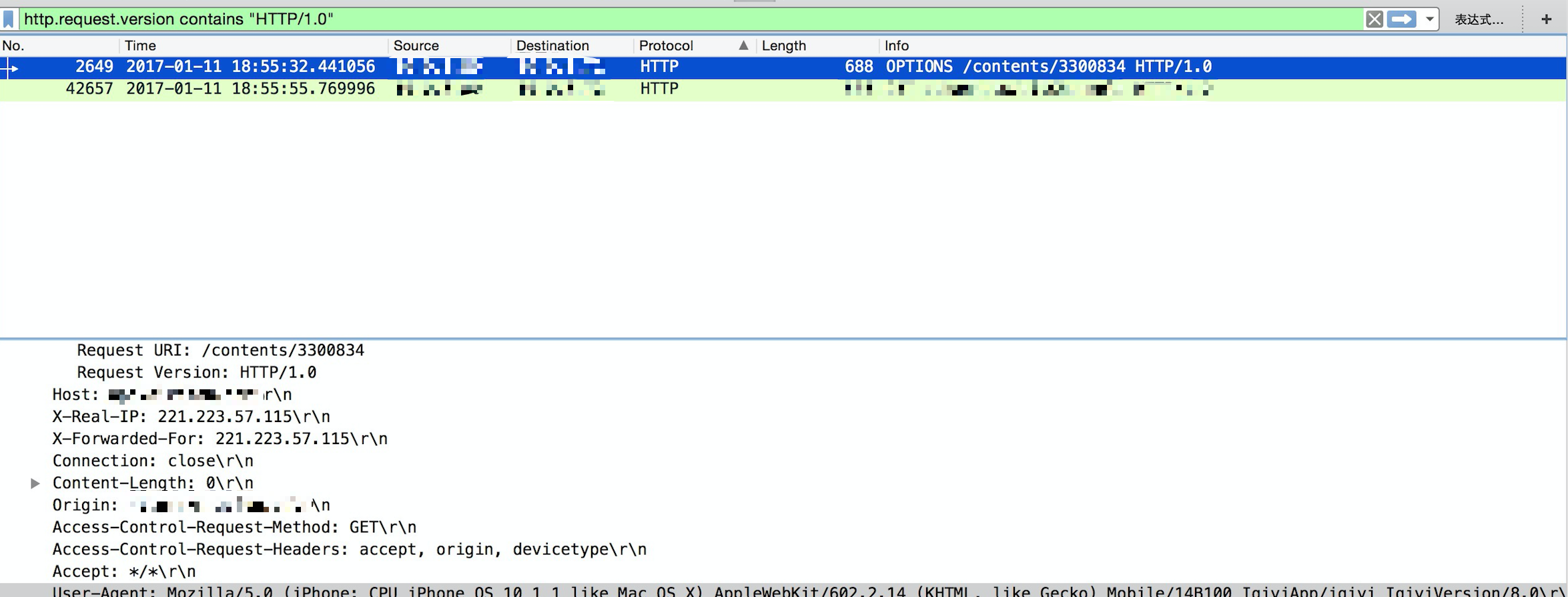
继续观察发现在这个被改变了http协议的请求前,都会有一个HTTP/1.0的请求.
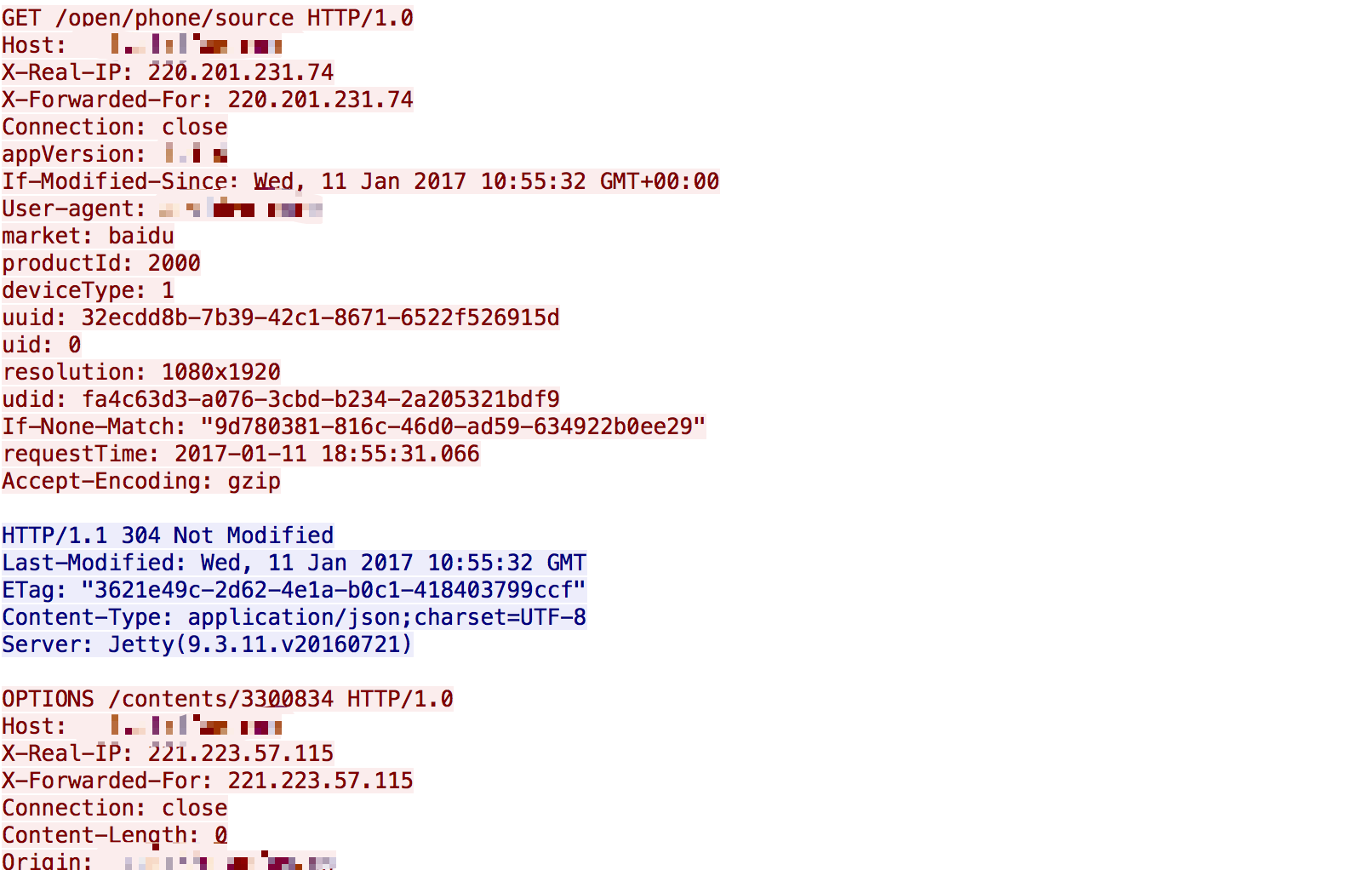
然后对这个TCP流抓包,发现了下面的情况:
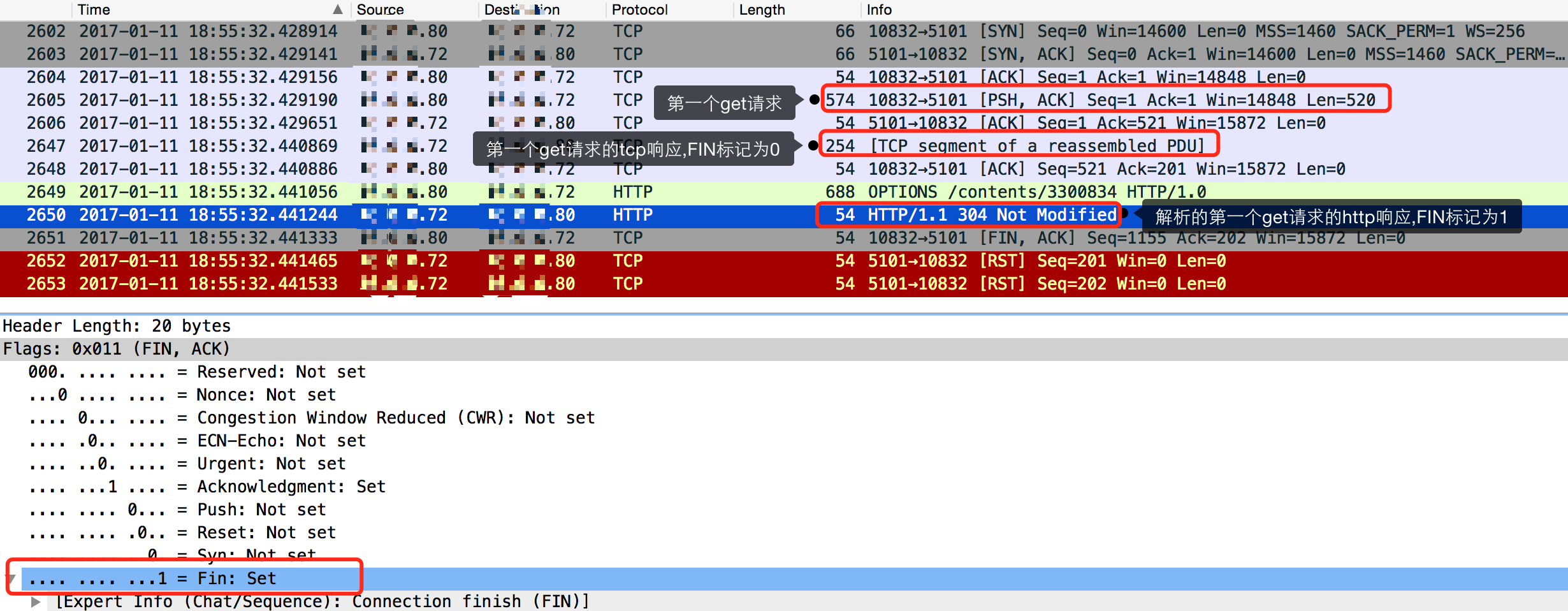
如图,80为nginx服务器,72为后端jetty服务.
在80向72以tcp发送第一个get请求后,72以tcp回发了一个响应.这个响应中FIN标记是为0的,也就是不关闭连接.
80在接收到72的响应后,继续以http发送了第二个get请求,也就是我们出错的请求.而且此请求被改为了HTTP/1.0!
然后80解析了72回发的第一个get请求的响应,而这个响应的FIN标记被http协议标记为了1,也就是需要关闭连接了.
然后80就没有等待第二个get请求的响应,发送了关闭连接的tcp报文.
此时第二个get请求也就没有办法发送响应了.因为tcp连接已经不存在了.
那么可以理解为HTTP/1.0协议发送的请求在请求结束后链接就被关闭,而在关闭前nginx依然复用了这个链接发送了请求...然后nginx关闭了连接,导致了后面这个请求报错!
还有第一个get请求的响应中tcp到http这个"解析"过程是怎么回事,还有待查询资料.问题就是在这个"解析"的时间内发送了另一个请求导致的...
至于第一个HTTP/1.0的请求是不是客户端发送过来的1.0还是被nginx修改的1.0,今天我去查看日志的时候,发现日志被删了...运维大哥今天又没在...只能等他回来再验证了...
未完待续...
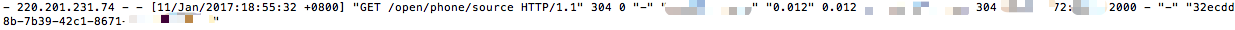
有了结论:
据运维说不知道谁把nginx转换http1.1的配置删掉了...就是下面两行:
proxy_http_version 1.1;
proxy_set_header Connection "";
虽然结论显得有点中二...但是感觉排查问题的过程还是值得记录的.


 浙公网安备 33010602011771号
浙公网安备 33010602011771号