
关联规则(Apriori算法、FP-树频集算法、Eclat算法)
关联规则最早是由R.Agrawal等人针对超市购物篮分析问题提出的,其目的是发现超市交易数据库中不同商品之间的关联关系。
关联规则体现了顾客购物的行为模式,这可以为经营决策、市场预测和策划等方面提供依据。关联规则挖掘系统已经被成功应用于市场营销、银行业、零售业、保险业、电信业和公司经营管理等各个方面。关联规则还可以应用于文本挖掘、商品广告有机分析和网络故障分析等领域。
经典的关联规则挖掘算法包括Apriori算法和FP-growth算法(J.Han等人提出)。前者多次扫描数据库,每次利用候选频繁集产生频繁集;后者则利用树形结构直接得到频繁集,减少了扫描数据库的次数,从而提高了算法的效率。但是前者的扩展性好,可用于并行计算等领域。
| |
咖啡
|
不喝
咖啡
|
|
|
茶
|
150
|
50
|
200
|
|
不喝茶
|
650
|
150
|
800
|
| |
800
|
200
|
1000
|
假定希望分析爱喝咖啡和爱喝茶的人之间的关系。收集一组人关于饮料偏爱的信息
评估关联规则:{茶} -> {咖啡}
支持度=15% 置信度=75%
Confidence= P(咖啡|茶) = 0.75
但是 P(咖啡) = 0.8
尽管规则 {茶} -> {咖啡}有很高的置信度,但是它却是一个误导。
支持度-置信度框架的局限性:
由于置信度度量忽略了规则后件中出现的项集的支持度,高置信度的规则有时可能出现误导。
解决这个问题的一种方法是使用提升度:
lift(A,B)= P(B/A)P(B)或conf(A→B)/sup(B)
如果提升度大于1,表明A和B是正相关的。如果小于1,表明A和B是负相关的。
关联规则 Eclat算法案例
library(arules) #加载arules程序包 data(Groceries) #调用数据文件
frequentsets=eclat(Groceries,parameter=list(support=0.05,maxlen=10)) #求频繁项集 inspect(frequentsets[1:10]) #察看求得的频繁项集 inspect(sort(frequentsets,by="support")[1:10]) #根据支持度对求得的频繁项集排序并察看 supp(A) = P(A)= 出现的频率 = count(A) / counts

关联规则 Apriori算法案例
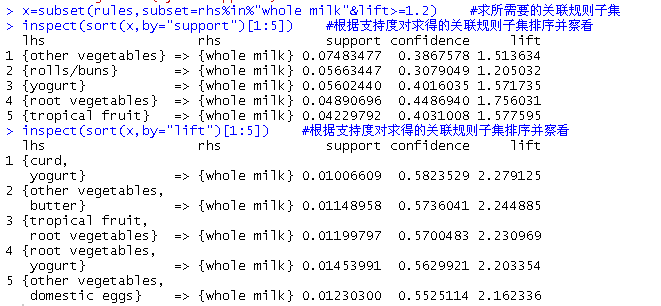
rules=apriori(Groceries,parameter=list(support=0.01,confidence=0.01)) #求关联规则 summary(rules) #察看求得的关联规则之摘要 x=subset(rules,subset=rhs%in%"whole milk"&lift>=1.2) #求所需要的关联规则子集 inspect(sort(x,by="support")[1:5]) #根据支持度对求得的关联规则子集排序并察看 supp(A) = P(A)= 出现的频率 = count(A) / counts
inspect(sort(x,by="confidence")[1:5]) #根据置信度(可信度)对求得的关联规则子集排序并察看 conf(A->B) = P(A ^ B)/ P(B)= P(B|A)
inspect(sort(x,by="lift")[1:5]) #根据提高率(兴趣度)对求得的关联规则子集排序并察看 lift(A->B) = lift(B->A) = conf(A->B)/ P(B)= conf(B->A) / P(A)
= P(A ^ B)/(P(A)* P(B))
# 保存内容 sink("apriori.txt") inspect(rules) sink()
关联规则 FP-树频繁集算法案例
外链:FP-Tree算法的实现
Java开发算法推荐:http://blog.csdn.net/yangliuy/article/details/7494983

 浙公网安备 33010602011771号
浙公网安备 33010602011771号