
四则运算题目生成器项目笔记
本次作业是实现一个面向小学教师的四则运算题目生成程序,它的功能包括生成题目,以及根据题目计算结果并自动给同学的作业打分。
预估时间及实际花费时间表格
从表格中可以看出,用于设计和测试的时间较多。
| PSP2.1 | Personal Software Process Stages | Time |
|---|---|---|
| Planning | 计划 | |
| · Estimate | · 估计这个任务需要多少时间 | 20h |
| Development | 开发 | |
| · Analysis | · 需求分析 (包括学习新技术) | 1h |
| · Design Spec | · 生成设计文档 | 1h |
| · Design Review | · 设计复审 (和同事审核设计文档) | 1h |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 0.5h |
| · Design | · 具体设计 | 2h |
| · Coding | · 具体编码 | 3h |
| · Code Review | · 代码复审 | 1h |
| · Test | · 测试(自我测试,修改代码,提交修改) | 2h |
| Reporting | 报告 | |
| · Test Report | · 测试报告 | 3h |
| · Size Measurement | · 计算工作量 | 0.5h |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 1h |
| 合计 | 16h |
需求分析
根据老师的要求,所写程序功能大体分为两部分:
- 根据参数生成满足要求的四则运算题目并同时生成答案
- 对同学的答案进行评测
其中,第二个功能较为简单,就是一个经典的中缀表达式求值的问题,我们可以用两个栈来随便维护一下就好。
第一个功能中要求较多:
- 根据命令行参数决定生成题目的数量和题目中数值的大小
- 生成的所有题目都要保证在计算过程中不能出现负数
- 每一个题目中所含的运算符数不超过三个
- 生成的题目中的数字及结果如果为分数,则必须为真分数。
- 如果生成了多个题目,那么这些题目应该是
不同的。
不同定义为:
任何两道题目不能通过有限次交换+和×左右的算术表达式变换为同一道题目
具体设计
首先分析第一个功能。
第一个要求很容易满足,通过控制一些参数即可实现。
第二个要求则需要对表达式进行运算,如果出现了负数,则交换减号两边的表达式。(或采取其他方式避免)
第三个要求相当于对题目的简化。仅用考虑不超过三个运算符的表达式
第四个要求则需要我们同时处理分数和整数。我们考虑使用一个统一的Factor类来实现。
第五个要求是这些要求中较难的一个。它要求我们生成的表达式不能有相同的计算顺序。结合表达式的性质,我们很容易就想到了树的最小表示法。
即用二叉树的形式存放表达式,那么只要两棵树的最小表示不同,则这两个表达式一定是不同的。
并且由于表达式中的运算符数量较少,将树最小表示的过程可以暴力的来做。
ps:刚开始没有限制表达式的数量,那么如果要对表达式树进行最小表示,则需要树的每一个节点均为子表达式,并且需要对表达式类重载小于运算符,实现起来较为繁琐。后来老师加上了对运算符的限制,则大大降低了编程复杂度。
类定义:
class Factor {
int fraction;
long long numerator, denominator;
}
class Expression {
int opNum;
Factor fac[FACTOR_SIZE];
char op[FACTOR_SIZE];
}
上述代码描述了本程序中关键的两个类:factor和Expression。
Factor类实现了分数和整数的统一处理(包括四则运算、输出等),其numerator属性为分子,denomination属性为分母,fraction属性标记了其是否为分数。
Expression类实现了表达式的处理,包括表达式的最小表示,处理出现负数和除数为零的情况等不合法情况以及输出。
有了上述基础,表达式的生成就变得非常简单了。
- 随机一个1~3的变量,表示表达式中所含运算符的个数
- 随机生成相应个数的运算符和数值。并初步构建表达式。
- 对表达式的减法和除法中可能出现的问题进行检测,如果有问题则对表达式进行修改。
- 将表达式树转化为最小表示,并判断是否重复。
- 按照表达式树的计算顺序(即后序遍历顺序)生成带括号的表达式字符串。
- 输出该字符串。
至此,第一个功能就初步设计完毕了。
第二个功能则没什么好说的,就是读入两个文件,将两个文件中保存的答案记录下来并进行计算和比较,从而得出结果。需要注意的就是一些文件读取的问题和文件内容不合法的判断。
代码实现中出现的问题
对于Factor和Expression类,我最初在每个类中都定义了一个print()方法,用于输出该类型的变量。然而之后发现由于需要生成多个表达式,且每个表达式生成后都要向两个文件中写入数据,那么采用输出重定向的方式就较为不便。于是我将print()方法改为了与Java中类似的toString()方法,该方法会返回要输出的字符串。这样就可以方便的使用文件流的方式来存取数据了。
对于将表达式进行最小表示后的判重问题,我刚开始的思路是开一个很多维的map来存表达式的所有运算符和数值。大概类似这个样子:
map<Factor, map<Factor, map<Factor ,map<char, map <char, int> > > > > mp;
写完之后发现编译器给出了警告:
warning C4503: 'std::_Tree<std::_Tmap_traits<_Kty,_Ty,_Pr,_Alloc,false>>::erase' : decorated name length exceeded, name was truncated
查阅资料后发现,这是由于模板展开后的标识符长度超过了编译器限制。
那如何消除这个警告呢?后来我才想到,既然要求表达式唯一,那么直接将最小表示后的表达式字符串作为key就好了嘛……
所以仅需要一个set<string>来存放不同的表达式即可。
对于输入的参数中要求生成较多数量的表达式但是给出的表达式中数值得限制较小,就可能会出现凑不出要求的表达式数量的情况。对于这种情况,目前还没有想到完美的方法来保证所有可能的表达式均被生成。仅限定了一个阈值,如果在循环了这么多次后仍然没有找到一个以前没有出现的表达式,那么就近似地认为没有更多的表达式了。
不过在实际应用中,应该不会出现这种极限的情况。
代码复审及测试
在代码写完后,我进行了Code Review和debug。
Code Review中,发现了两处写错的地方,debug中,发现了三个细节问题(判断除0错误时的逻辑问题、生成数值的时候fraction取值的问题以及文件读写的问题),并进行了改正。
在后续的测试中,发现了即使数值限制为100,中间结果也有可能会超过int的范围,因此必须采用long long类型的变量来存储数值。
测试用例如下:
- 生成题目TestCase1:
ExpressionGeneration.exe -r 10000 -n 1
pause
# generate Exercises.txt including a expression which values are less than 10000
# Answers.txt including the expression's answer
- 生成题目TestCase2:
ExpressionGeneration.exe -n 5
pause
# input error,display the help message`
- 生成题目TestCase3:
ExpressionGeneration.exe -n 5
pause
# input error,display the help message`
- 生成题目TestCase3:
ExpressionGeneration.exe -n 5.1 -r 4
pause
# input invalid, display the help message
- 生成题目TestCase4:
ExpressionGeneration.exe -n -r 4 5
pause
# input invalid, display the help message
- 生成题目TestCase5:
ExpressionGeneration.exe -n 10000 -r 3
pause
# generate Exercises.txt including 10000 expressions which values are less than 3
# Answers.txt including the answers of all the expressions
- 生成题目TestCase6:
ExpressionGeneration.exe -n 10000 -r 2
pause
# It doesn't have so many expressions
测试答案的测试用例由于文件较大,在此不再展示,围绕文件读取合法性、题目格式的正确性、答案格式的正确性、题目文件和答案文件是否匹配、答案正确的题目数量等方面设计测试用例即可。
性能测试
- 生成10000道数值限制为100的题目
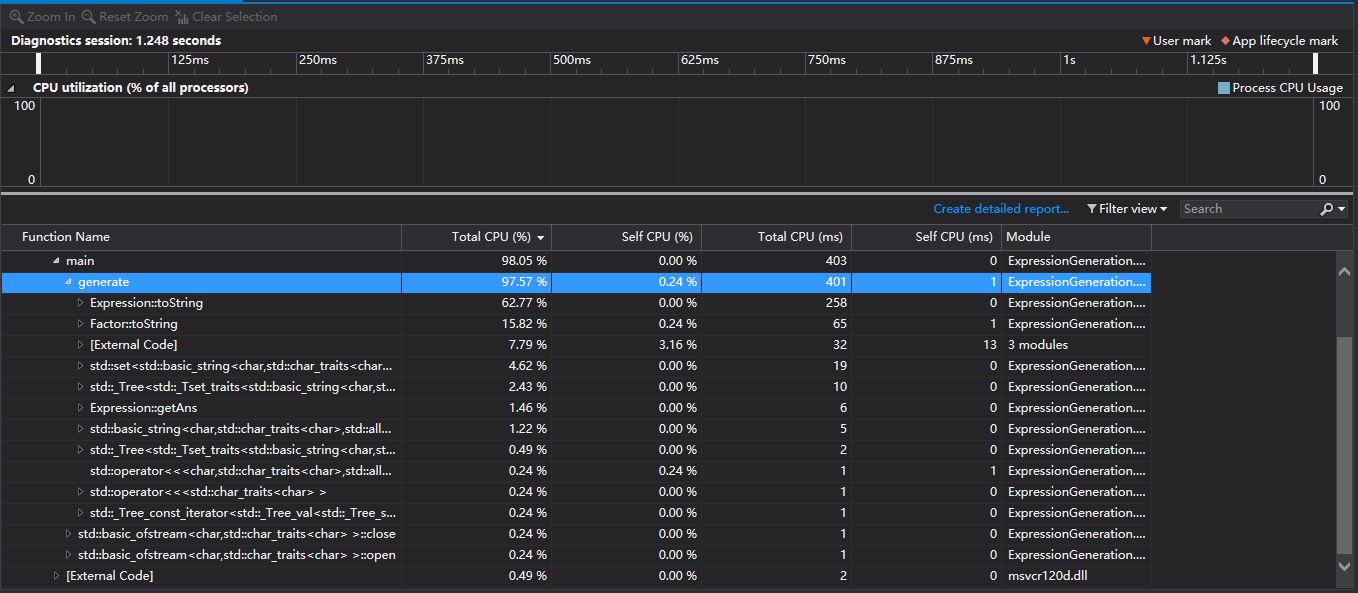
-
- 从上图中,我们可以看出,限制程序效率的的关键在于表达式的toString()方法。其次为Factor(分数类)的toString()方法。由于我没有采用标准的树结构来存储表达式,而是采用了数组的形式,所以在转化为字符串的时候分类较多。此外,是用其中调用到的用于将数字转化为string的intToStr()方法中,多次用到了对long long类型的数进行取模运算。
-
生成10000道数值限制为3的题目
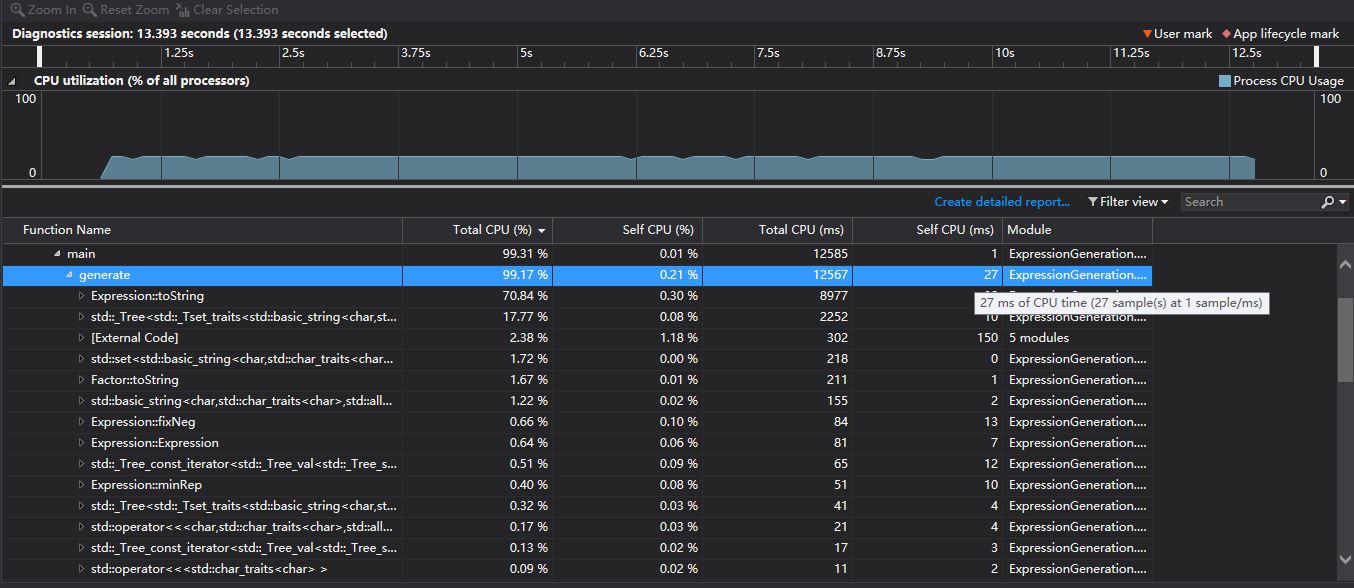
-
- 从上图中,我们发现,排名第一的仍然是表达式类的toSting()方法,但是排名第二的是则是STL中set的相关方法。这是由于数值限制非常小,从而使得出现重复表达式的概率较高,因此更多的表达式在set判重时被咔嚓掉了,从而导致set相关函数的运行时间较高。
-
对10000道数值限制为100的题目进行检验
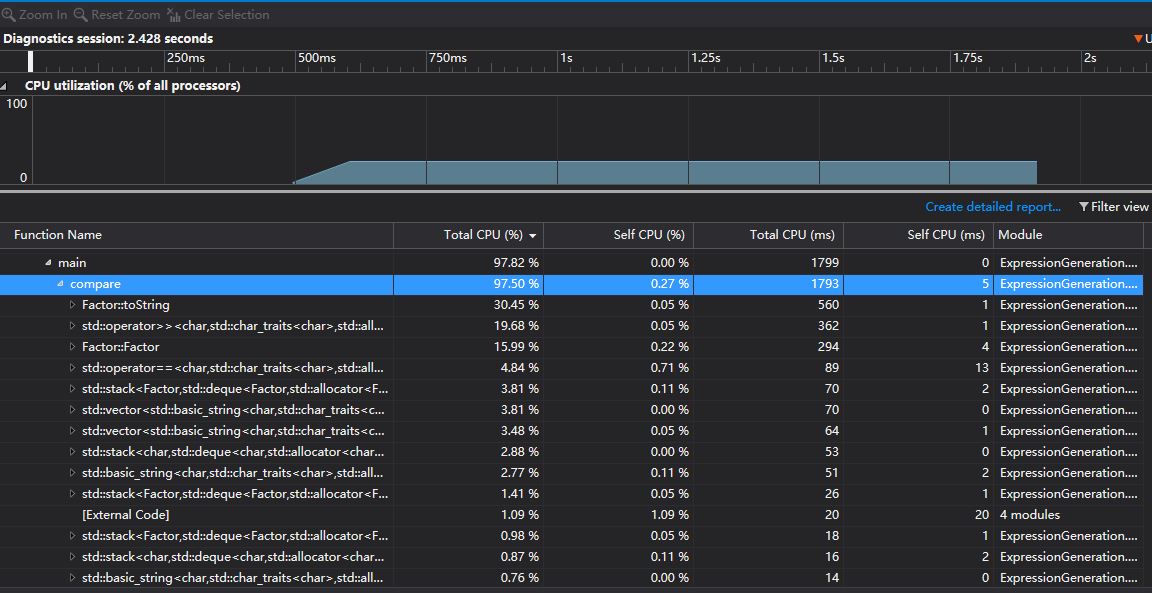
-
- 检验题目时并没有用到表达式类,而是直接读取数据后使用两个栈来维护,因此耗时排名第一的函数从expression的toString()方法变为了Factor类的toString()方法。之后的就是一些STL库函数了,这是用于我使用了STL中的栈。
不过总的来说,运行效率可以接受。toString()方法也没有太大的改进空间了。
总结与收获
完成这次个人项目的过程中,我进一步体会到做工程与解决数学问题的区别。
在实际项目中,需求往往不是能够仅从题目要求中读出来的,更多的还是要结合实际情况进行分析。同时,做项目的目的是为了服务生活,有时,我们可以根据生活中的实际情况来对问题进行简化。(比如这次项目中对运算符个数的限制),而不是一味地构想难解的问题。
此外,我也发现了数据结构和算法基础在项目实现中的重要性。在本次项目中,如果能够想到平时经常用到的判断树同构问题的最小表示法的话,那么这就是一个非常熟悉且优美的问题了。(不过我的代码实现还是不够优美……)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号