
OpenCV探索之路(二十二):制作一个类“全能扫描王”的简易扫描软件
相信很多人手机里都装了个“扫描全能王”APP,平时可以用它来可以扫描一些证件、文本,确实很好用,第一次用的时候确实感觉功能很强大啊算法很牛逼啊。但是仔细一想,其实这些实现起来也是很简单的,我想了下,实现的步骤应该就只有下面三个:
- 将证件轮廓找到
- 提取证件矩形轮廓四点进行透视变换
- 二值化
知道原理之后,我马上利用强大的opencv开发一个类似“全能扫描王”扫描工具。
整理一下我们要制作的这个扫描工具有哪些功能:
- 图像的信息区域的提取与矫正
- 图像的二值化
- 锐化和增强
第二第三点都非常简单,那么制作这个工具的难点完全落在了第一点“ 图像的信息区域的提取与矫正”上了。在编码实现的过程中,确实有很多坑需要踩一踩。
我们先展示一下效果,我们有这么一个用手机拍摄的图片

经过扫描工具一番处理后变成这样子。也就是说,我们将原图中的那个文件抠了了出来,并且完成矫正。

实现过程查阅了大量资料,也看了网上很多类似的博客,前辈们实现过相类似的透视变换的代码,但是他们的代码实现的都不理想,很多图片根本没法检测。不过还是可以从前人的经验中获取到很多好想法的,所以先列出一些有借鉴的博客:
http://www.pyimagesearch.com/2014/09/01/build-kick-ass-mobile-document-scanner-just-5-minutes/
http://www.pyimagesearch.com/2014/09/01/build-kick-ass-mobile-document-scanner-just-5-minutes/
正式实现
第一步,二值化+高斯滤波+膨胀+canny边缘提取
一开始我是没有采取形态学处理的,仅仅是二值化+高斯滤波+canny边缘提取的策略,但是实际运行下效果并不好,原因在于有一些图片的信息区域轮廓没法闭合,这就导致了信息区域轮廓没法提取。但是加入适当的膨胀后,效果就好多了。
Mat src = imread("1.png");
imshow("src img", src);
Mat source = src.clone();
Mat bkup = src.clone();
Mat img = src.clone();
cvtColor(img, img, CV_RGB2GRAY); //二值化
imshow("gray", img);
//equalizeHist(img, img);
//imshow("equal", img);
GaussianBlur(img, img, Size(5, 5), 0, 0); //高斯滤波
//获取自定义核
Mat element = getStructuringElement(MORPH_RECT, Size(3, 3)); //第一个参数MORPH_RECT表示矩形的卷积核,当然还可以选择椭圆形的、交叉型的
//膨胀操作
dilate(img, img, element); //实现过程中发现,适当的膨胀很重要
imshow("dilate", img);
Canny(img, img, 30, 120, 3); //边缘提取
imshow("get contour", img);
}
轮廓提取效果如下:

第二步,轮廓查找并筛选
一般情况下,我们提取到的轮廓不会像上图那样的干净,而是带有很多干扰项轮廓,如果我们不能很好的剔除这些轮廓,我们根本没法找出我们想要的信息区域。我筛选轮廓的方法很简单,就是找出一张图片中面积最大的那个轮廓作为我们的信息区域轮廓,这招真是屡试不爽,因为根据我们日常经验,我们对一张证件或者文件性扫描拍摄,证件区域占整张图片的面积肯定是最大的。
vector<vector<Point> > contours;
vector<vector<Point> > f_contours;
std::vector<cv::Point> approx2;
//注意第5个参数为CV_RETR_EXTERNAL,只检索外框
findContours(img, f_contours, CV_RETR_EXTERNAL, CV_CHAIN_APPROX_NONE); //找轮廓
//求出面积最大的轮廓
int max_area = 0;
int index;
for (int i = 0; i < f_contours.size(); i++)
{
double tmparea = fabs(contourArea(f_contours[i]));
if (tmparea > max_area)
{
index = i;
max_area = tmparea;
}
}
contours.push_back(f_contours[index]);
筛选出我们所需的轮廓

第三步,找出这个四边形轮廓的四个顶点
因为我们需要轮廓的四个顶点坐标来实现透视变换,现在的问题来了:我们怎么利用这个四边形轮廓的点集来找出初四边形的四个顶点?
这真是一个大难题!
一开始我的想法是这样子的:直接从四边形点集中筛选出四个定点(比如x坐标最大的那个坐标肯定是四边形右上角坐标或者右下角坐标,x坐标最小的那个坐标肯定是左上角或者下角的那个坐标,如此类推),但是这种想法实现起来是很有问题的而因为它很受限于四边形的姿态,所以一个思路一直没法进行下去。如果大家有仅依赖四边形点集就能找出四边形的四个顶点坐标的方法,请告诉我,我们一同探讨。
所以我切换了另外一个思路:基于直线交点的思路。我们首先使用霍夫变换找出四边形的边,然后求两两直线的交点不就是四边形的定点吗?的确是这样子的,但是实际操作起来也是问题多多啊。
最大的问题就是,我们怎么保证我们使用霍夫变换找到的直线刚好就是形成四边形的四条直线?
所以我们就必须不断地去改变霍夫变换的参数,不断迭代,来求出一个可以形成四边形的直线情况。
那什么情况的直线我们不能接受?
- 两两直线过于接近我们排除
- 两两直线没有交点我们排除
- 检测出来的直线数目不是4条我们排除
如果找到了满足条件的四条直线,我们就可以去计算他们的交点了。算法如下:
cv::Point2f computeIntersect(cv::Vec4i a, cv::Vec4i b)
{
int x1 = a[0], y1 = a[1], x2 = a[2], y2 = a[3];
int x3 = b[0], y3 = b[1], x4 = b[2], y4 = b[3];
if (float d = ((float)(x1 - x2) * (y3 - y4)) - ((y1 - y2) * (x3 - x4)))
{
cv::Point2f pt;
pt.x = ((x1*y2 - y1*x2) * (x3 - x4) - (x1 - x2) * (x3*y4 - y3*x4)) / d;
pt.y = ((x1*y2 - y1*x2) * (y3 - y4) - (y1 - y2) * (x3*y4 - y3*x4)) / d;
return pt;
}
else
return cv::Point2f(-1, -1);
}
计算出四个交点后,我们不能完全信任他们就是我们要找的四个顶点,所以继续筛选:
- 如果两两定点的距离过近,我们排除
bool IsGoodPoints = true;
//保证点与点的距离足够大以排除错误点
for (int i = 0; i < corners.size(); i++)
{
for (int j = i + 1; j < corners.size(); j++)
{
int distance = sqrt((corners[i].x - corners[j].x)*(corners[i].x - corners[j].x) + (corners[i].y - corners[j].y)*(corners[i].y - corners[j].y));
if (distance < 5)
{
IsGoodPoints = false;
}
}
}
if (!IsGoodPoints) continue;
- 如果这四个点构成不了四边形我们排除
cv::approxPolyDP(cv::Mat(corners), approx, cv::arcLength(cv::Mat(corners), true) * 0.02, true);
if (lines.size() == 4 && corners.size() == 4 && approx.size() == 4)
{
flag = 1;
break;
}
如果都通过以上筛选条件的,我们就可以认为他们就是我们找的那四个顶点,这时我们就可以停止迭代,进行顶点排序,即确定这四个顶点哪个是左上角点,哪个又是右下点。
算法如下:
bool x_sort(const Point2f & m1, const Point2f & m2)
{
return m1.x < m2.x;
}
//确定四个点的中心线
void sortCorners(std::vector<cv::Point2f>& corners,
cv::Point2f center)
{
std::vector<cv::Point2f> top, bot;
vector<Point2f> backup = corners;
sort(corners, x_sort); //注意先按x的大小给4个点排序
for (int i = 0; i < corners.size(); i++)
{
if (corners[i].y < center.y && top.size() < 2) //这里的小于2是为了避免三个顶点都在top的情况
top.push_back(corners[i]);
else
bot.push_back(corners[i]);
}
corners.clear();
if (top.size() == 2 && bot.size() == 2)
{
//cout << "log" << endl;
cv::Point2f tl = top[0].x > top[1].x ? top[1] : top[0];
cv::Point2f tr = top[0].x > top[1].x ? top[0] : top[1];
cv::Point2f bl = bot[0].x > bot[1].x ? bot[1] : bot[0];
cv::Point2f br = bot[0].x > bot[1].x ? bot[0] : bot[1];
corners.push_back(tl);
corners.push_back(tr);
corners.push_back(br);
corners.push_back(bl);
}
else
{
corners = backup;
}
}
第四步,四点法透射变换
我们拿到原图信息区域四边形的四个顶点,现在我们还需要变换后图像的四个顶点才可以实现投射变换。
求变换后四个顶点坐标前我们还需要做的一件事就是,确定变换后的图像尺寸。第一种方法就是人工指定,比如我直接规定好变换后的图片大小是bbb*aaa。第二种方法就是,通过计算确定信息区域的尺寸,也就是说,信息区域有多大,我们变换后的图像就有多大。
既然我们知道了四边形的四个顶点了,那么我们可以直接求两点的距离来确定四边形的长宽。变换后的图像高度宽度可以这么确定:
int g_dst_hight; //最终图像的高度
int g_dst_width; //最终图像的宽度
void CalcDstSize(const vector<cv::Point2f>& corners)
{
int h1 = sqrt((corners[0].x - corners[3].x)*(corners[0].x - corners[3].x) + (corners[0].y - corners[3].y)*(corners[0].y - corners[3].y));
int h2 = sqrt((corners[1].x - corners[2].x)*(corners[1].x - corners[2].x) + (corners[1].y - corners[2].y)*(corners[1].y - corners[2].y));
g_dst_hight = MAX(h1, h2);
int w1 = sqrt((corners[0].x - corners[1].x)*(corners[0].x - corners[1].x) + (corners[0].y - corners[1].y)*(corners[0].y - corners[1].y));
int w2 = sqrt((corners[2].x - corners[3].x)*(corners[2].x - corners[3].x) + (corners[2].y - corners[3].y)*(corners[2].y - corners[3].y));
g_dst_width = MAX(w1, w2);
}
透射变换:
cv::Mat quad = cv::Mat::zeros(g_dst_hight, g_dst_width, CV_8UC3);
std::vector<cv::Point2f> quad_pts;
quad_pts.push_back(cv::Point2f(0, 0));
quad_pts.push_back(cv::Point2f(quad.cols, 0));
quad_pts.push_back(cv::Point2f(quad.cols, quad.rows));
quad_pts.push_back(cv::Point2f(0, quad.rows));
cv::Mat transmtx = cv::getPerspectiveTransform(corners, quad_pts);
cv::warpPerspective(source, quad, transmtx, quad.size());
所有关键步骤都已经说明完毕,运行一下代码,看看效果。
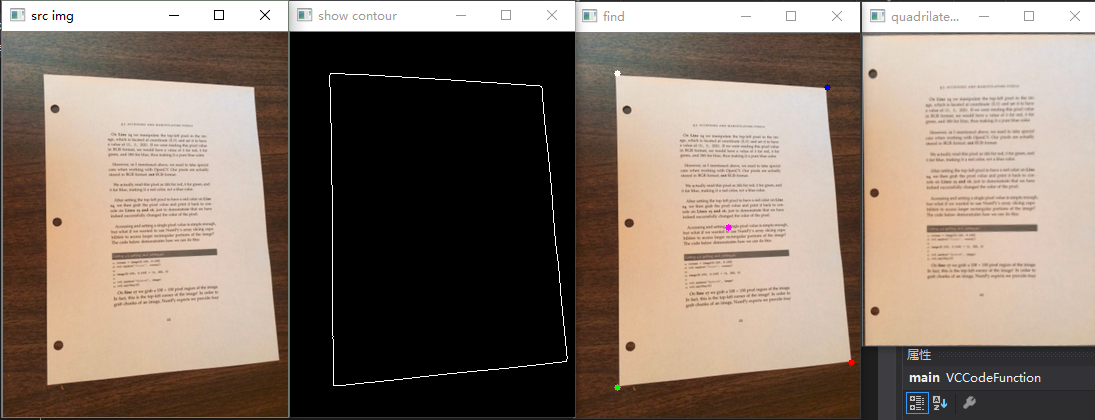
再拍一些其他图片,看看处理效果
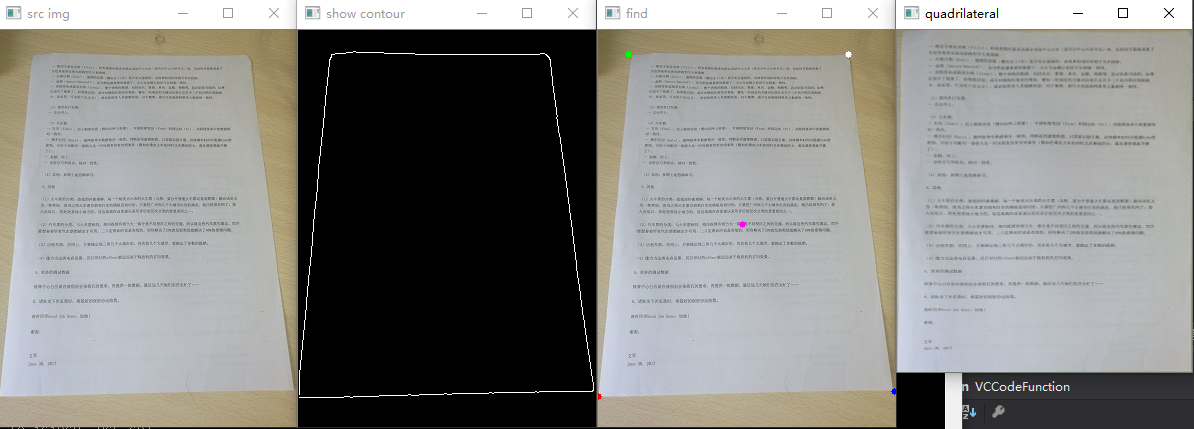

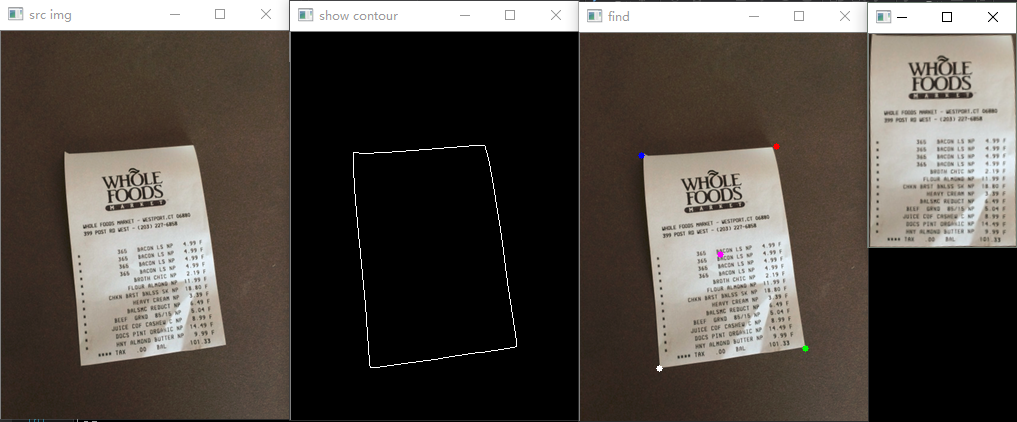

试一下带有干扰背景的图像,效果还是不错的
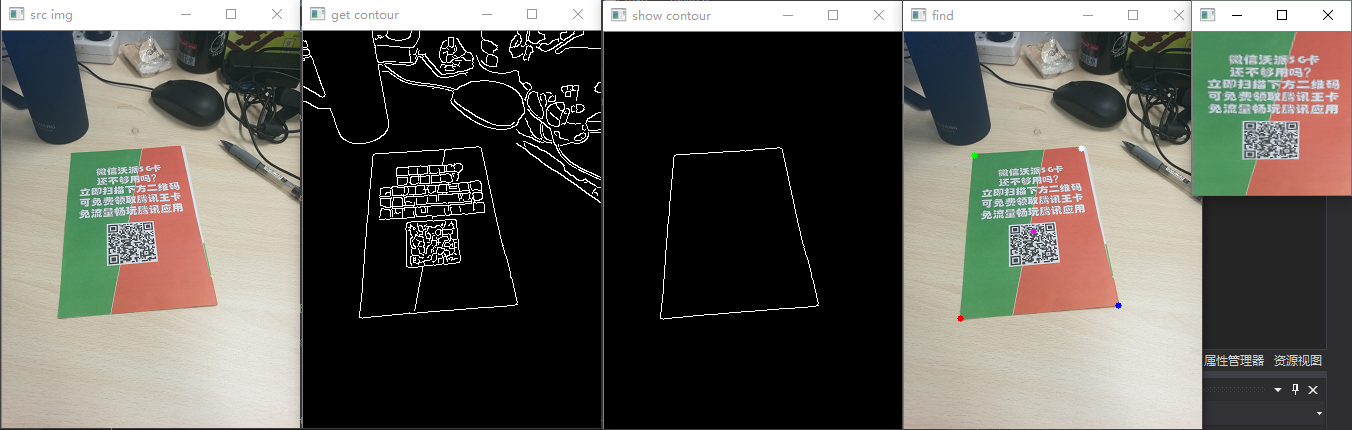
额外效果:二值化
有些时候还需要将一些文本或者证件弄成扫描模样,那我们就加入二值化实现该效果。
Mat local,gray;
cvtColor(quad, gray, CV_RGB2GRAY);
int blockSize = 25;
int constValue = 10;
adaptiveThreshold(gray, local, 255, CV_ADAPTIVE_THRESH_MEAN_C, CV_THRESH_BINARY, blockSize, constValue);
imshow("二值化", local);
二值化效果挺好的


完整代码以及测试图像可以在我的github上获取。欢迎大家一起探讨~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号