
![]()
我们现在已经习惯把互联网作为资料库了,通过各种在线收藏服务组织我们的技术资料。
然而互联网存在着诸多不确定性,我们收藏的资料有时会不翼而飞,比如目标服务器瘫痪、迁移,或是原作者删除了该文章,更为常见的情况就是文章配图、附件链接失效,这些情况经常困扰我们。
将资料保存在本地无疑是最为安全的办法,但将网页一一“另存为”绝对是个麻烦事,也不便于管理;我以前是使用网文快捕来收集和管理技术资料,但近来感觉它有些臃肿、繁琐,所以就没有再使用了。而近来发现了这个优秀的Firefox扩展——ScrapBook
ScrapBook可以将网址链接或是网页内容收集起来,通过侧边栏管理及显示:

内容采集
在网页内容采集方面,ScrapBook做得非常周全:
- 可以仅保存网页中鼠标选中的部分;
- 可以将网页中的文字、样式、图片全部保存到本地;
- 可以同时获取网页内链接所指向的任意附件,如放大的图片、音乐、视频、压缩包、PDF/DOC文档等;
- 可以添加注释。
其选项对话框如下:

值得关注的一点是其中的“深层获取”功能,它可以把文章中所引用的其他文章资料一并获取,而当你遇到一个文章目录或系列文章索引的时候,它将变得尤为有用,它可以根据网页中的链接继续探索,并获取N层的内容,将之全部保存到本地。
以我的WPF相关文章索引为例,我们只选择其中几篇文章的链接部分,并设置获取1层链接,不获取图片及附件,启动获取后,可以看到ScrapBook正在获取多个页面的内容:

获取结束后,可以看到侧边栏的目录中仅仅多了一项:

打开此项,可以看到这里仅获取了我此前选中部分的内容:

点击其中的一个链接,就可以看到文章的内容,而此内容也是被完整保存在本地的(我设置了不保存图片):

便笺
有时你也许想把自己的经验心得一并纳入资料库,那么便笺功能将非常适合用到这里,你可以在侧栏中随意添加便笺:
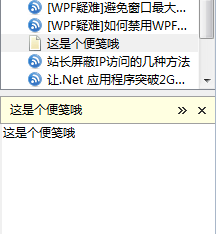
批注
除了上述的诱人的采集功能之外,ScrapBook还提供了不错的批注功能:

自定义附件
有时文章提供的附件链接是动态转接网址或下载页引用,这时附件获取功能将不起作用,我们可以通过手工下载附件,然后将其附加到获取后的文档中,你只需选中文中一段文字,比如“附件”,然后点击下面的菜单添加即可:
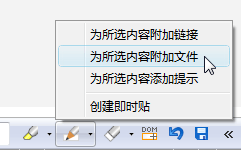
擦除
可以利用橡皮擦或DOM橡皮擦删除不需要的内容:
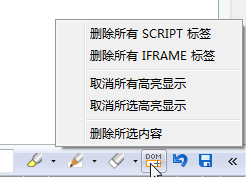
原始链接
在有些时候,我们只想收藏一个网址,并随时关注它的内容变化,比如我在问答社区发布了一个提问,我想时刻关注别人的回答,这可以在ScrapBook中办到吗?没问题的,ScrapBook可以选择只保存Url链接,而且保存在本地的文档,也有“打开原始链接”选项,真是相当方便的。
总结
ScrapBook仅200多k,但完全可以充当收藏夹、资料管理器、离线阅读器,是程序员们绝好的辅助工具,当然,前提是你要用Firefox。
下载
ScrapBook下载地址:http://addons.sociz.com/firefox/15/
提示
在获取博客园文章时,最好将代码块一一展开后再进行获取,或者选择获取JS代码,否则可能出现获取到的代码块无法展开的问题。
下载本文的PDF版本:http://uushare.com/user/icesee/file/1284711
转载请遵循此协议:署名 - 非商业用途 - 保持一致
并保留此链接:http://skyd.cnblogs.com/

