删除重复项,保留最大值
昨天对商城添加快递费,由于忘记获取快递费的feeid了。用replace into table 语句,导致更新快递费,无论表中有没有记录都添加。
今天通过数据库已查询,里面上千条记录。
里面有expressid和areaid相同的项。
如图:
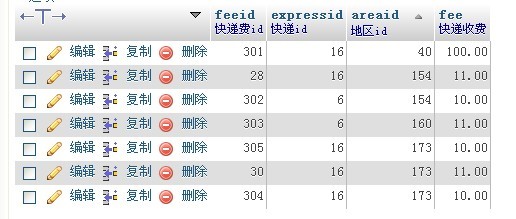
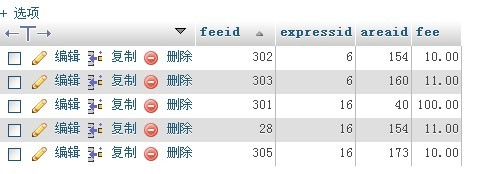
现在需要删除掉expressid 和areaid两个重复的,只保留一个feeid最大的。即最后一次更改。
需要的结果如图:
思路是什么样的?
1、直接查出重复的,删除
2、查出需要保留的,删除不在这个范围内的。
用第二种比较容易
- 第一步查出需要保留的。
SELECT *
FROM expressfee as ef
GROUP BY expressid, areaid
这样写虽然也得到了结果,但是并不能确保查询出来的是feeid最大的。
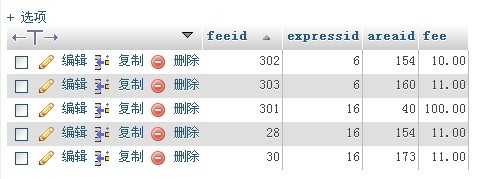
用下面的语句可以做到:
SELECT *
FROM (select * from expressfee order by feeid desc) as ef
GROUP BY expressid, areaid
如果对这点有怀疑,你可以把排序方式更改。
SELECT *
FROM (select * from expressfee order by feeid asc) as ef
GROUP BY expressid, areaid
结果:
- 第二步
- 开始删除
delete from expressfee where feeid not in(
SELECT feeid
FROM (select * from expressfee order by feeid desc) as ef
GROUP BY expressid, areaid)
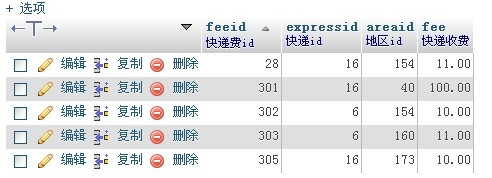
完成。
顺便批评下一篇文章 "用distinct在MySQL中查询多条不重复记录值" 按照他写的是不行的。
如果感觉不错,请
赞
一个!
by simpman
by simpman
