Lucene5.5.2开发入门详解
一、 全文检索的概念
常见的全文检索
1) 在window系统中,可以指定磁盘中的某一个位置来搜索你想要得到的东西。这个功能是windows比较常用的功能。
2) 在eclipse中,帮助文档搜索:heltp 》help content,文件搜索ctrl+h,ctrl+shift+R.
其实eclipse的搜索功能就是用lucene写的
3) 在百度和google 中,可以搜索互联网中的信息,有:网页、pdf、word音频、视频等内容。
4) Taobao搜索商品。
全文检索的应用场景
1、站内搜索
l 通常用于在大量数据出现的系统中,找出你想要的资料。常见的有
l baidu贴吧
l 商品网站的搜索等
l 中关村在线 商品的名称、电脑硬件名称 (CPU)
l 文件管理系统
l 对文件的搜索功能。Window的文件搜索
2、垂直搜索
l 是针对 某个行业的搜索引擎
l 是搜索引擎的细分和延伸
l 是针对网页库中的专门信息的整合
l 其特点是专、深、精,并具有行业色彩
l 可以应用于购物搜索、房产搜索、人才搜索
说明
l 从大量的信息中快速、准确地查找出要的信息
l 搜索的内容是文本信息(不是多媒体)
l 全文检索只是一个概念,而具体实现有很多框架,lucene是其中的一种,常见的还有solr,es等。其实solr和es底层也是lucene,只是做了一些封装。
二、Lucene与sql性能比较
lsql:比如我要查找某个商品,根据商品名,比如select * from product where doctname like %keywords%,这样查询的话对于数据量少是可以的,可是一旦你的数据量巨大几万几十万的时候,你的性能将会极大的减弱。
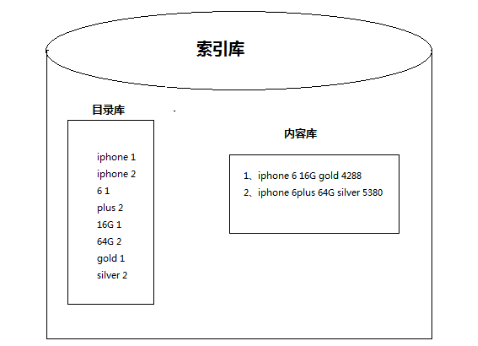
l lucene:在索引库里面会把所有的商品名根据分词器建立索引,就好比新华字典,索引对应document,比如输入衬衫,那么就会根据索引迅速的翻到衬衫对应的商品名,时间迅速,性能很好。
三、 第一个lucene程序
开发前的准备
1. 版本说明
由于lucene的版本非常多,目前从apach官网上能下载到完整jar包的版本目前只有5.5.2和6.2.0,因此这里选择5.5.2版本,5.5.2版本所需要的jdk需要1.7。
2. 下载地址
http://apache.fayea.com/lucene/java/5.5.2/
3. 本例使用到的jar包
1、 lucene-core-5.5.2.jar(核心包)
2、 lucene-analyzers-common-5.5.2.jar(分词器)
3、 lucene-backward-codecs-5.5.2.jar(兼容老版本)
4、 lucene-queryparser-5.5.2.jar(查询解析)
建立索引
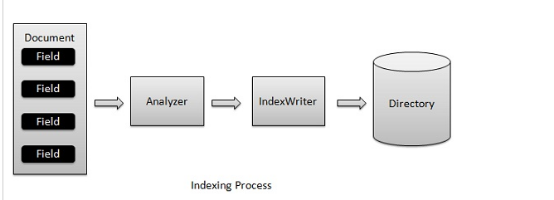
步骤:
1. 创建IndexWriter对象
a) 需要指定索引库的位置,索引库的位置可能是磁盘,也有可能是内存。
b) 需要指定用什么分词器,因为创建索引的时候,会按照一定的切分内容的方式去创建索引,这样才能通过关键字查找到对应的内容。
2. 把JavaBean转化为Document
a) Javabean的每一个字段就代表一个field,一个javabean就代表一个document。
3. 利用IndexWriter.addDocument方法增加索引
a) 说明:关于这个方法,实际上做了两件事情,先是创建好内容,再根据指定的分词器分词出关键字,创建索引目录。
4. 关闭IndexWriter
说明:使用完之后,要关闭掉资源,因为这里有io流资源相关的操作。另外一个原因关闭indexwriter,同时会提交操作,这样才能创建索引成功。
关键类说明:
IndexWriter:是增、删、改索引过程的核心组件。这个类负责创建新索引或者打开已有索引,以及向索引中添加、删除或者更新被索引文档的信息。
IndexWriterConfig:获取indexwriter所需要的对象,可以理解为获取indexwriter的一个设置对象,可以设定使用什么分词创建索引,也可以设定创建索引的方式,是追加还是覆盖。
Directory:在数据库中,数据库中的数据文件存储在磁盘上。索引库也是同样,索引库中的索引数据也在磁盘上存在,我们用Directory这个类来描述。
Analyzer:指定录入的内容按照切分成若干个关键词放入到目录库中。
Field:存放一个键值对。这么理解:类似于数据库的一个字段。Filed的实现有很多种,如:StringField、TextField、IntField。Field包含了三个属性:类型、name、value。不同的实现体现了不同的类型,name、value代表的是一对键值对的名称和值。
Document:这么理解:类似于数据库的一条记录。Document的结构为:Document(List<Field>)。
Store:一个枚举类,两个值yes和no,yes代表内容存放在索引库中,no代表内容不存放在索引库中,这里要注意是不存放内容,但是是否会作为索引关键词是另一回事。
编码实现:
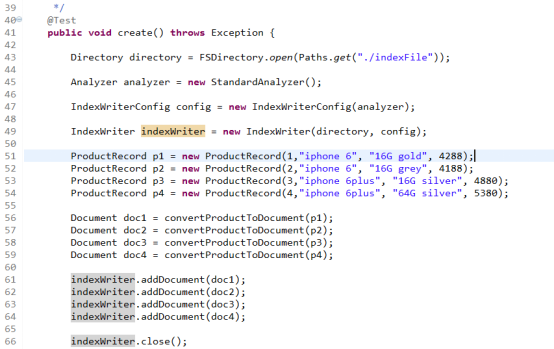
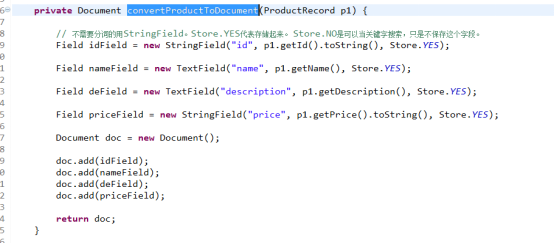
注:关于上面情况下使用IntField,StringField,TextField的问题。
IntField:主要在保存类似数量,例如库存数量,需要经常用到范围查询的时候。使用这个字段保存的数据,无法通过正常的关键字查找到。
StringField:不需要分词,需要精确匹配的这段,如数据库的id,地理名等。
TextField:需要分词的字段
索引查看工具luke
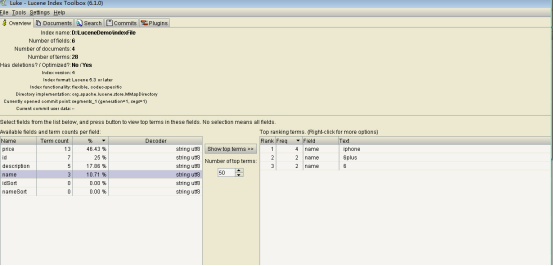
搜索

步骤:
1. 创建IndexSearch
a) 需要拿到indexReader对象
2. 创建Query对象
3. 进行搜索
4. 根据获取到的TopDocs,获得总结果数和前N行目录ScoreDoc。
5. 根据目录ID列表获取到document。indexSearcher.doc(int)。
关键类说明:
IndexSearch:是查索引过程的核心组件。
QueryParser 解析用户的查询字符串进行搜索,是一个解析用户输入的工具,可以通过扫描用户输入的字符串,生成Query对象。
Query:查询对象。封装要查询的相关信息。
TopDocs:索引库目录的一个引用。可以理解为搜索到的目录结果集的引用。主要包含了两个信息,总的记录数和目录结果集。
ScoreDoc:一条目录。包含了得分和索引下标。
编码:
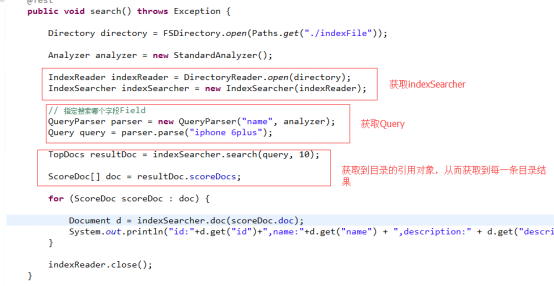
删除索引
编码:
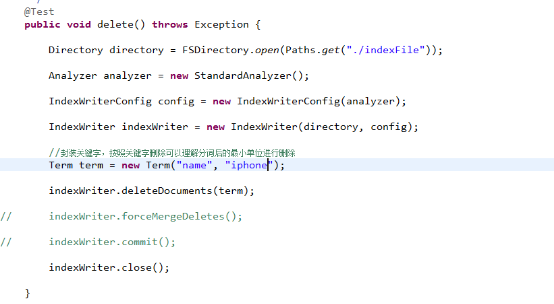
说明:获取到的indexwriter一定要关闭,原因和创建索引的原因一样。
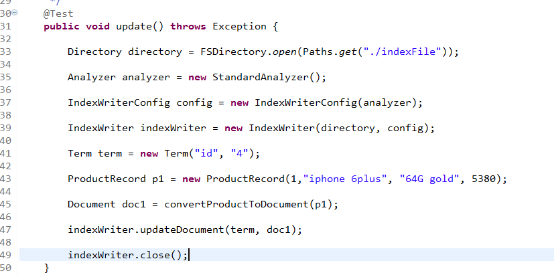
更新索引
lucene的更新操作与数据库的更新操作是不一样的。因为在更新的时候,有可能变换了关键字的位置,这样分词器对关键字还得重新查找,而且还得在目录和内容中替换,这样做的效率比较低,所以lucene的更新操作是删除和增加两步骤来完成的。
注:关于索引库优化。
旧版本:每执行一次就生成一个cfs文件。如果增加、删除反复操作很多次,就会造成文件大量增加,这样检索的速度也会下降,所以我们有必要去优化索引结构。使文件的结构发生改变从而提高效率。
新版本当达到一个数量后会自动优化。
优化lucene能过forceMerge方法来将当小文件达到多少个时,就自动合并多个小文件为一个大文件,因为它的使用代价较高不意见使用此方法,默认情况下lucene会自己合并。
编码:
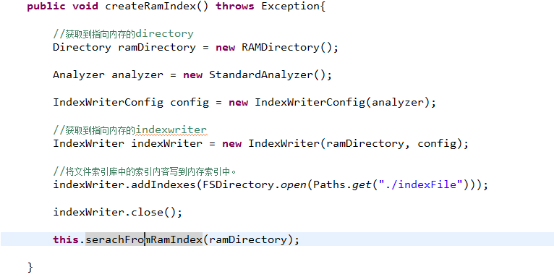
内存索引库
特点
在内存中开辟一块空间,专门为索引库存放。这样有以下几个特征:
1) 因为索引库在内存中,所以访问速度更快。
2) 在程序退出时,索引库中的文件也相应的消失了。
3) 如果索引库比较大,必须得保证足够多的内存空间。
根据Directory不同的子类获取到内存索引还是文件索引库。创建索引的操作基本类似。
编码:
分词器
英文分词器
步骤:切分关键词
去除停用词
转为小写(搜索时不区分大小写,因为分词器会帮你转化)
如:I am a programmer,live in shenzhen,what about you?
分词后的结果为:
i
am
programmer
live
shenzhen
what
about
you
分词代码(无需研究没有什么意义,看分词后的结果就好了):
/** * 英文分词器 */ @Test public void testEnAnalyzer() throws Exception{ Analyzer analyzer = new StandardAnalyzer(); String text = "I am a programmer,live in shenzhen,what about you?"; this.testAnalyzer(text, analyzer); } /** * 中文分词器ik */ @Test public void testIKAnalyzer() throws Exception{ Analyzer analyzer = new IKAnalyzer(); // String text = "我是一名程序猿,居住在深圳,你呢?"; String text = "立创商城"; this.testAnalyzer(text, analyzer); } private void testAnalyzer(String text , Analyzer analyzer) throws Exception { TokenStream ts = null; try { ts = analyzer.tokenStream("myfield", new StringReader(text)); // 获取词元文本属性 CharTermAttribute term = ts.addAttribute(CharTermAttribute.class); // 重置TokenStream(重置StringReader) ts.reset(); // 迭代获取分词结果 while (ts.incrementToken()) { System.out.println( term.toString()); } // 关闭TokenStream(关闭StringReader) ts.end(); } catch (IOException e) { e.printStackTrace(); } finally { // 释放TokenStream的所有资源 if (ts != null) { try { ts.close(); } catch (IOException e) { e.printStackTrace(); } } } }

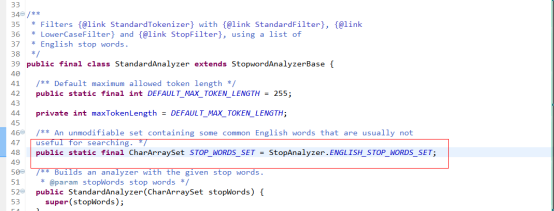
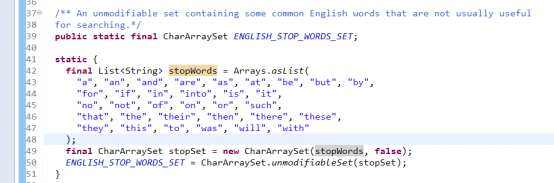
中文分词器
1) 常用的分词器有:IKAnalyzer、paoding、mmseg4j、imdict。 这里选用:IKAnalyzer
2) 如何自定义扩展词汇:将IKAnalyzer.cfg.xml拷贝到src下,然后新建一个自己的自定义词典,配置IKAnalyzer.cfg.xml即可。
源码分析入口:


初始化最主要的工作就是读入词典,并将这些词放入内存字典树
1.main2012.dic(关键词)2.quantifier.dic(量词)3.stopword.dic(停用词,可扩展)4.ext.dic(扩展词,可选)
注意:自定义的词汇文件要注意编码格式:UTF-8无BOM格式,否则分词会没有作用。
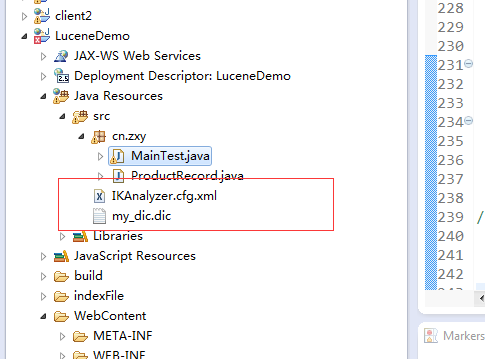

关于中文分词器,必定会有一个默认的词库文件。

IK Analyzer2012支持 细粒度切分 和 智能切分。
样例:
1)文本原文:
IKAnalyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包。从2006年12月推出1.0版本开始,IKAnalyzer已经推出了3个大版本。
智能分词结果:
ikanalyzer | 是 | 一个 | 开源 | 的 | 基于 | java | 语言 | 开发 | 的 | 轻量级 | 的 | 中文 | 分词 | 工具包 | 从 | 2006年 | 12月 | 推出 | 1.0版 | 开始 | ikanalyzer | 已经 | 推 | 出了 | 3个 | 大 | 版本
最细粒度分词结果:
ikanalyzer | 是 | 一个 | 一 | 个 | 开源 | 的 | 基于 | java | 语言 | 开发 | 的 | 轻量级| 量级 | 的 | 中文 | 分词 | 工具包 | 工具 | 包 | 从 | 2006 | 年 | 12 | 月 | 推出 | 1.0 | 版 | 开始 | ikanalyzer | 已经 | 推出 | 出了 | 3 | 个 | 大 | 版本
Lucene分页
Lucene的分页,总的来说有两种形式。
方式一:在ScoresDocs里进行分页
原理:在lucene里面,每一个索引内容都会对应一个不重复的docid,而这一点跟Oralce数据库的伪列rownum一样,恰恰正是由于这个docid的 存在,所以让lucene在海量数据检索时从而拥有更好的性能,我们都知道Oracle数据库在分页时,使用的就是伪列进行分页,那么我的lucene也是一样,既然有一个docid的存在,那么就可以把数据全部拿到内存中,根据docid进行分页。
编码实现:

方式二:利用SearchAfter,再次查询分页
原理:先拿到上一页最后一个ScoreDoc,利用lucene提供的SearchAfter和得到的ScoreDoc查询当前页的索引结果。
编码实现:
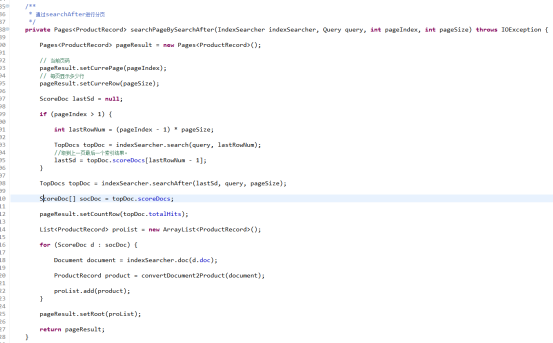
两种方式的优缺点对比:
|
编号 |
方式 |
优点 |
缺点 |
|
1 |
在ScoresDocs里进行分页 |
无需再次查询索引,速度很快 |
在海量数据时,会内存溢出 |
|
2 |
利用SearchAfter,再次查询分页 |
适合大批量数据的分页 |
再次查询,速度相对慢一点,但可以利用缓存弥补 |
搜索方式Query
1、TermQuery
关键字查询,不分词。
1 Query query = new TermQuery(new Term("id", "1"));
2、MatchAllDocsQuery
查询所有。
1 Query query = new MatchAllDocsQuery();
3、WildcardQuery
通配符查询。?:匹配任意一个字符,*匹配多个任意字符
Query query = new WildcardQuery(new Term("name","i?"));
4、PhraseQuery
同个字段多个关键字组合查询,并且的关系。不分词,关键字区分大小写
Query query = new PhraseQuery("name", "iphone","6plus");
5、BooleanQuery
多个字段关键字组合查询
BooleanQuery.Builder booleanQuery = new BooleanQuery.Builder(); booleanQuery.add(new TermQuery(new Term("name", "iphone")), Occur.MUST); booleanQuery.add(new TermQuery(new Term("description", "grey")), Occur.MUST); Query query = booleanQuery.build();
6、NumericRangeQuery
范围查询,只针对IntField、FloatField这些数字类型的Field才能进行范围查询。
Query query = NumericRangeQuery.newIntRange("id", 1, 2, true, true);
说明:第四个参数和第五个参数,代表是否大于等于的意思,true即为包含。
排序
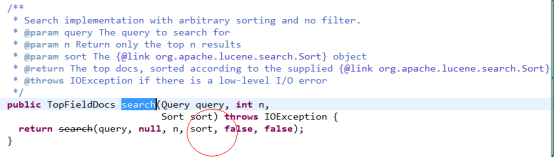
观察源码,关于IndexSearcher.search有很多重载的方法,其中有方法可以传递Sort对象进去实现排序,如下图:
构造Sort字段实现排序,其中,这里要注意Lucene5.x的排序相比lucene4.x之前改动较大。
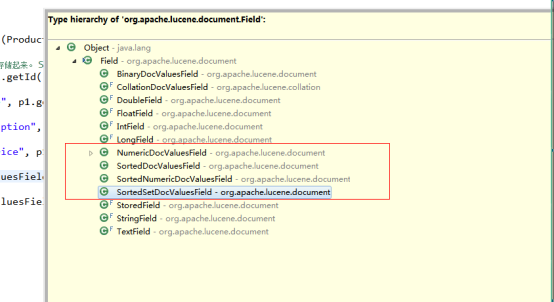
主要在排序字段需要在建立索引的时候单独指定,即不能根据索引的内容字段或者关键字字段去排序。如下图,如果某个字段需要支持排序,需要额外构建下面类型的Field字段,否则无法排序。
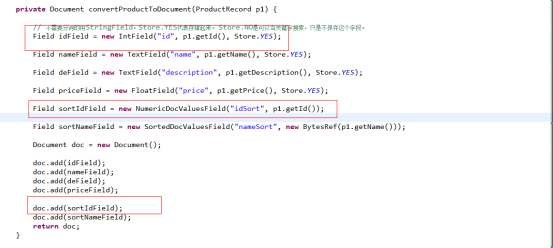
编码实现:

四、相关文件
IK分词器:http://pan.baidu.com/s/1dFMcxnb
luke:http://pan.baidu.com/s/1dE0N2d7
