



[Python爬虫] 之十二:Selenium +phantomjs抓取中的url编码问题
最近在抓取活动树网站 (http://www.huodongshu.com/html/find.html) 上数据时发现,在用搜索框输入中文后,点击搜索,phantomjs抓取数据怎么也抓取不到,但是用IE驱动就可以找到,后来才发现了原因。
例如URL: http://www.huodongshu.com/html/find_search.html?search_keyword=数字, phantomjs抓取的内存中url变成了http://www.huodongshu.com/html/find_search.html?search_keyword=??,导致搜索的结果为0,就是没有搜索到。
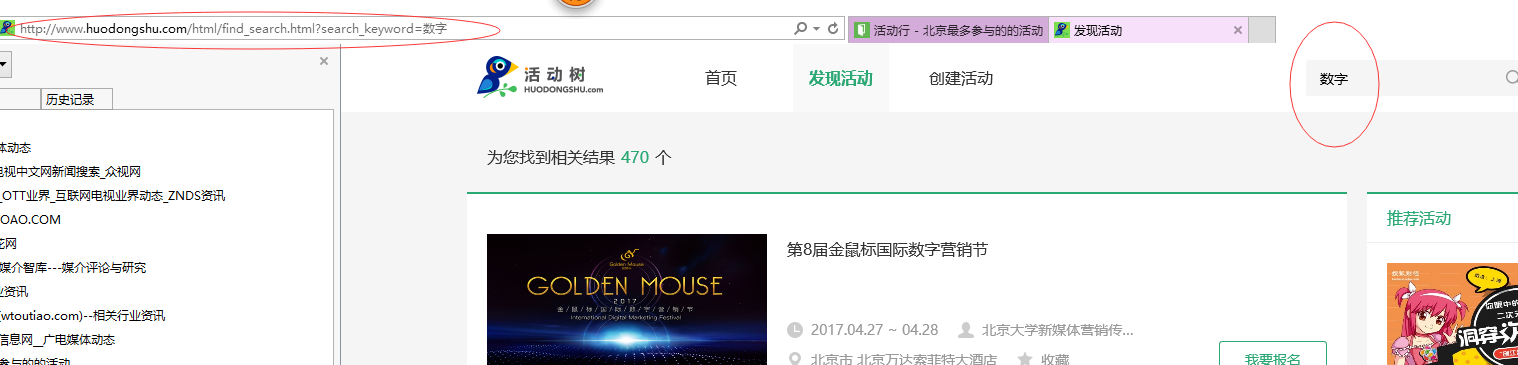
在搜索框输入英文是没有问题,奇怪输入中文就就变成了??,后来在活动行(http://www.huodongxing.com/)网站上直接输入数字后,变成了%E6%95%B0%E5%AD%97
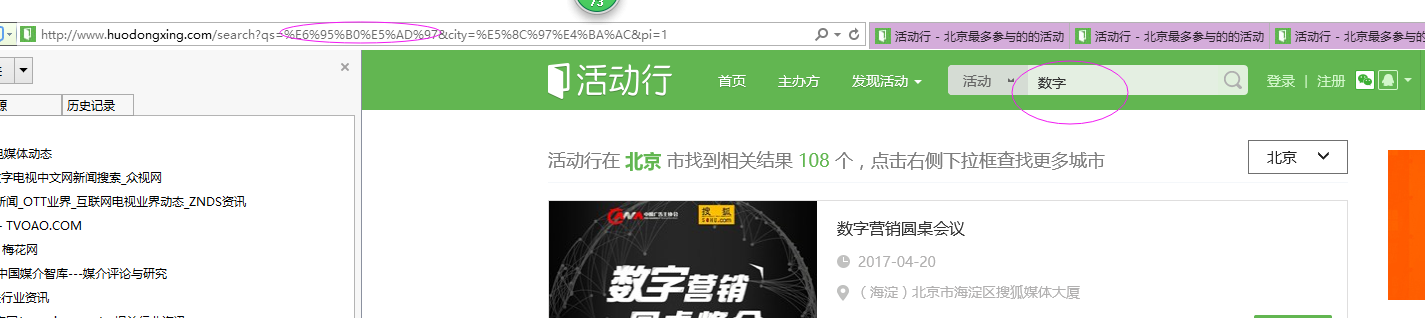
后来就想如果把对应的中文转换成%E6%95%B0%E5%AD%97 这样的编码,phantomjs能不能找到呢,比如:
Url='http://www.huodongshu.com/html/find_search.html?search_keyword=%E6%95%B0%E5%AD%97',结果一测试果然可以找到,因此在用phantomjs抓取数据是,先把搜索中文关键字转换成url编码就解决问题了。
具体有两个方法,具体如下:
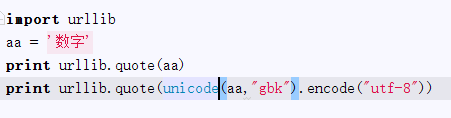
结果:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号