|
 How to pass an array to a stored procedure How to pass an array to a stored procedure
Author of this Tip: Thomas Kyte
You want to declare an array EMPARRY like the following ...
(emp_no number,
emp_dept varchar2
emp_salary number
emp_title varchar2)
.... and use it as a parameter in a stored proc like:
procedure emp_report(emp_arr EMPARRY)
To accomplish this, you just need to declare new types. You can have types that are tables of a RECORD or types that are tables of SCALARS. PL/SQL use collection types such as arrays, bags, lists, nested tables, sets, and trees. To support these techniques in database applications, PL/SQL provides the datatypes TABLE and VARRAY, which allow you to declare index-by tables, nested tables and variable-size arrays.
To create collections, you define a collection type, then declare variables of that type. You can define TABLE and VARRAY types in the declarative part of any PL/SQL block, subprogram, or package.
For nested tables, use the syntax:
TYPE type_name IS TABLE OF element_type [NOT NULL];
- type_name - is a type specifier used later to declare collections. For nested tables declared within PL/SQL, element_type is any PL/SQL datatype except:
REF CURSOR
- element type - nested tables declared globally in SQL have additional restrictions on the element type. They cannot use the following element types:
BINARY_INTEGER, PLS_INTEGERBOOLEANLONG, LONG RAWNATURAL, NATURALNPOSITIVE, POSITIVENREF CURSORSIGNTYPESTRING
Create a Package demo_pkg with the overloaded procedure emp_report. One uses EMPARRY as argument,
the other CHARARRY.
CREATE OR REPLACE PACKAGE demo_pkg
AS
-- Emparry keeps Rows of the Table EMP
TYPE emparray IS TABLE OF emp%rowtype INDEX BY BINARY_INTEGER;
-- Chararray keeps just VARCHARs
TYPE chararray IS TABLE OF VARCHAR2(255) INDEX BY BINARY_INTEGER;
-- Declare emp_report to use emparry as Argument
PROCEDURE emp_report(emp_arr IN emparray);
-- Overloaded emp_report to use chararray as Argument
PROCEDURE emp_report(p_empno IN chararray,
p_deptno IN chararray,
p_sal IN chararray,
p_job IN chararray);
END;
/
CREATE OR REPLACE PACKAGE BODY demo_pkg
AS
-- Define emp_report to use emparry as Argument
PROCEDURE emp_report(emp_arr IN emparray)
IS
BEGIN
DBMS_OUTPUT.PUT_LINE('output from: emp_report(emp_arr in emparray)');
-- Loop through emparry
FOR I IN 1 .. emp_arr.COUNT LOOP
DBMS_OUTPUT.PUT_LINE( 'EMPNO = ' ||
emp_arr(i).empno || ' DEPTNO = ' ||
emp_arr(i).deptno);
END LOOP;
END;
-- Overloaded emp_report to use chararray as Argument
PROCEDURE emp_report(p_empno IN chararray,
p_deptno IN chararray,
p_sal IN chararray,
p_job IN chararray)
IS
BEGIN
DBMS_OUTPUT.PUT_LINE('output from: emp_report(p_empno in chararray, ...)');
-- Loop through chararray
FOR I IN 1 .. P_EMPNO.COUNT LOOP
DBMS_OUTPUT.PUT_LINE( 'EMPNO = ' || P_EMPNO(I) || ' DEPTNO = ' || P_DEPTNO(I) );
END LOOP;
END;
END;
/
Initializing and Referencing Collections
Until you initialize it, a nested table or varray is atomically null: the collection itself is null, not its elements.
SET SERVEROUTPUT ON
DECLARE my_data demo_pkg.emparray;
BEGIN
-- Row 1 in emparray
my_data(1).empno := 1234;
my_data(1).deptno := 10;
-- Row 2 in emparray
my_data(2).empno := 4567;
my_data(2).deptno := 20;
demo_pkg.emp_report(my_data);
END;
/
output from: emp_report(emp_arr in emparray)
EMPNO = 1234 DEPTNO = 10
EMPNO = 4567 DEPTNO = 20
DECLARE
my_empnos demo_pkg.chararray;
my_deptno demo_pkg.chararray;
empty demo_pkg.chararray;
BEGIN
my_empnos(1) := 1234;
my_deptno(1) := 10;
my_empnos(2) := 4567;
my_deptno(2) := 20;
demo_pkg.emp_report(my_empnos,my_deptno,empty,empty);
END;
/
output from: emp_report(p_empno in chararray, ...)
EMPNO = 1234 DEPTNO = 10
EMPNO = 4567 DEPTNO = 20
The following collection methods help generalize code, make collections easier to use, and make your applications easier to maintain:
- EXISTS
- COUNT
- LIMIT
- FIRST and LAST
- PRIOR and NEXT
- EXTEND
- TRIM
- DELETE
A collection method is a built-in function or procedure that operates on collections and is called using dot notation. The syntax follows:
collection_name.method_name[(parameters)]
Collection methods cannot be called from SQL statements. Also, EXTEND and TRIM cannot be used with associative arrays. EXISTS, COUNT, LIMIT, FIRST, LAST, PRIOR, and NEXT are functions; EXTEND, TRIM, and DELETE are procedures. EXISTS, PRIOR, NEXT, TRIM, EXTEND, and DELETE take parameters corresponding to collection subscripts, which are usually integers but can also be strings for associative arrays.
Only EXISTS can be applied to atomically null collections. If you apply another method to such collections, PL/SQL raises COLLECTION_IS_NULL.
For more Information see: PL/SQL User's Guide and Reference
Understanding Associative Arrays (Index-By Tables) in Oracle 9.2
Associative arrays are new in Oracle 9.2, they help you represent data sets of arbitrary size, with fast lookup for an individual element without knowing its position within the array and without having to loop through all the array elements. It is like a simple version of a SQL table where you can retrieve values based on the primary key. For simple temporary storage of lookup data, associative arrays let you avoid using the disk space and network operations required for SQL tables.
Because associative arrays are intended for temporary data rather than storing persistent data, youcannot use them with SQL statements such as INSERT and SELECT INTO. You can make them persistent for the life of a database session by declaring the type in a package and assigning the values in a package body.
For example, here is the declaration of an associative array type, and one array of that type, using keys that are strings:
SET SERVEROUTPUT ON
DECLARE
TYPE TyCity IS TABLE OF NUMBER INDEX BY VARCHAR2(64);
l_city TyCity;
l_pop NUMBER;
l_first VARCHAR2(64);
l_last VARCHAR2(64);
BEGIN
-- Initialize Associative Array
l_city('Bern') := 20000;
l_city('Olten') := 750000;
-- Get Population for Olten
l_pop := l_city('Olten');
DBMS_OUTPUT.PUT_LINE('Olten has: ' || l_pop || ' habitants');
-- Insert more Value Pairs in Associative Array
l_city('Thun') := 15000;
l_city('Zürich') := 2000000;
-- Get first City Name
l_first := l_city.FIRST;
DBMS_OUTPUT.PUT_LINE('First City is: ' || l_first);
-- Get last City Name
l_last := l_city.LAST;
DBMS_OUTPUT.PUT_LINE('Last City is: ' || l_last);
-- Get Population for last City
l_pop := l_city(l_city.LAST);
DBMS_OUTPUT.PUT_LINE('Last City has: ' || l_pop || ' habitants');
END;
/
Olten has: 750000 habitants
First City is: Bern
Last City is: Zürich
Last City has: 2000000 habitants
PL/SQL procedure successfully completed.
This example shows how to load a lookup table from the database into an Associative Array which is fully kept in the memory for fast random access. First we create the following table:
SQL> desc city
Name Null? Type
-----------------------------------
PLZ VARCHAR2(12)
NAME_D NOT NULL VARCHAR2(80)
We create the Package AssArrDemo with the Procedure load_data to initialize the Associative Array. The Function check_plz checks if there is a zip code (PLZ) for a given city name. Note that the index in the Associative Array TyCity is of type city.name_d%TYPE which is a VARCHAR(80). Here is the Package:
CREATE OR REPLACE PACKAGE AssArrDemo
AS
-- Declare Associative Array using CITY.NAME_D as the index
-- Note that city.name_d%TYPE is a VARCHAR2 !!!!
TYPE TyCity IS TABLE OF city.name_d%TYPE INDEX BY city.name_d%TYPE;
-- Variable of type Associative Array
AsCity TyCity;
-- Procedure and Function Declaration
PROCEDURE load_data;
FUNCTION check_plz (pCityName city.name_d%TYPE) RETURN city.plz%TYPE;
END;
/
CREATE OR REPLACE PACKAGE BODY AssArrDemo
AS
-- Procedure to load Database Data into the Associative Array
PROCEDURE load_data IS
CURSOR cLoad IS
SELECT plz, name_d FROM city;
BEGIN
FOR rLoad IN cLoad LOOP
AsCity(rLoad.name_d) := rLoad.plz;
END LOOP;
END load_data;
-- Function to lookup PLZ for given city name
FUNCTION check_plz (pCityName city.name_d%TYPE) RETURN city.plz%TYPE IS
BEGIN
RETURN AsCity(pCityName);
EXCEPTION
WHEN no_data_found THEN
RETURN ('PLZ not found for City: <' || pCityName || '>');
END check_plz;
END;
/
SET SERVEROUTPUT ON
DECLARE
BEGIN
AssArrDemo.load_data;
dbms_output.put_line('PLZ for Seftigen is: ' || AssArrDemo.check_plz('Seftigen'));
END;
/
PLZ for Seftigen is: 3136
PL/SQL procedure successfully completed.
How to use an OUTER join to replace slow IN condition
A membership condition (IN, NOT IN) tests for membership in a list or subquery. It's easy to implement, but usually the execution plan chosen by the query optimizer is not as optimal as it can be if you replace the query by an OUTER join.
An outer join extends the result of a simple join. An outer join returns all rows that satisfy the join condition and also returns some or all of those rows from one table for which no rows from the other satisfy the join condition.
The following example shows, how you can replace an IN condition by an OUTER join. First create the following table and insert some values;
DROP TABLE stock;
--
CREATE TABLE stock (
stock_id NUMBER(5) NOT NULL,
selled_year NUMBER(4),
customer_id NUMBER(5));
STOCK_ID SELLED_YEAR CUSTOMER_ID
---------- ----------- -----------
1 1995 1
1 1995 2
1 1995 1
1 1995 2
3 1995 3
3 1995 3
4 1965 1
4 1965 1
5 2000 2
6 2000 1
7 2001 4
8 1995 1
Apply the following conditions to the above result set:
Show only those records with SELLED_YEAR >= 1993 and CUST_ID's 1,2,3.
SELECT *
FROM stock st
WHERE (selled_year >= 1993)
AND(customer_id IN (1,2,3));
STOCK_ID SELLED_YEAR CUSTOMER_ID
---------- ----------- -----------
1 1995 1
1 1995 2
3 1995 3
1 1995 1
1 1995 2
3 1995 3
5 2000 2
6 2000 1
8 1995 1
From this result set, do not show any records for CUST_ID = 1 and
SELLED_YEAR = 1995.
SELECT *
FROM stock
WHERE selled_year = 1995
AND customer_id = 1;
STOCK_ID SELLED_YEAR CUSTOMER_ID
---------- ----------- -----------
1 1995 1
1 1995 1
8 1995 1
If you subtract the result set in Condition 2 from the result set in Condition 1 you will get the following final result set. The question is now, how to get this result set in one single Step.
STOCK_ID SELLED_YEAR CUSTOMER_ID
---------- ----------- -----------
3 1995 3
5 2000 2
6 2000 1
SQL> set autotrace on explain
SELECT DISTINCT *
FROM stock st
WHERE (selled_year >= 1993)
AND (customer_id IN (1,2,3))
AND stock_id NOT IN
(SELECT stock_id
FROM stock
WHERE selled_year = 1995
AND customer_id = 1);
Oracle 9.2
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=CHOOSE
1 0 SORT (UNIQUE)
2 1 FILTER
3 2 TABLE ACCESS (FULL) OF 'STOCK'
4 2 TABLE ACCESS (FULL) OF 'STOCK'
SQL Server 2000
Execution Plan
----------------------------------------------------------
|--Sort(DISTINCT ORDER BY)
|--Nested Loops
|--Table Scan(stock)
|--Table Scan(stock)
SELECT DISTINCT st.*
FROM stock st
LEFT OUTER JOIN (SELECT stock_id
FROM stock
WHERE selled_year = 1995
AND customer_id = 1
)su
ON su.stock_id = st.stock_id
WHERE selled_year >= 1993
AND customer_id IN (1,2,3)
AND su.stock_id IS NULL;
Oracle 9.2
Execution Plan
------------------------------------------------
0 SELECT STATEMENT Optimizer=CHOOSE
1 0 SORT (UNIQUE)
2 1 FILTER
3 2 HASH JOIN (OUTER)
4 3 TABLE ACCESS (FULL) OF 'STOCK'
5 3 TABLE ACCESS (FULL) OF 'STOCK'
SQL Server 2000
set showplan_all on
Execution Plan
------------------------------------------------
|--Sort(DISTINCT ORDER BY)
|--Filter
|--Nested Loops
|--Table Scan(stock)
|--Table Scan(stock)
Both Databases Oracle and SQL-Server 2000 do not generate the same execution plan for the two SQL-Statements which have of course the same result set. Usually the IN and NOT IN solutions are slower - but this must be verified with real data, not only with a few records as shown in this example. However it is worth to spend the time to verify an measure the execution time.
How to randomly selecting rows ?
If you need to randomly select one or more rows from one of your tables, then you can use the following query.
As an example we want to show an employee, randomly selected from the EMP table:
SELECT *
FROM (SELECT empno, ename
FROM emp
WHERE ename like '%'
ORDER BY DBMS_RANDOM.VALUE)
WHERE rownum <= 1;
EMPNO ENAME
---------- ----------
7566 JONES
If you need two employees, use:
SELECT *
FROM (SELECT empno, ename
FROM emp
WHERE ename like '%'
ORDER BY DBMS_RANDOM.VALUE)
WHERE rownum <= 2;
EMPNO ENAME
---------- ----------
7499 ALLEN
7844 TURNER
Displaying the maximum value for every record
You want to display the maximum value for every row for some columns in a table.
GREATEST returns the greatest of the list of exprs. All exprs after the first are implicitly converted to the datatype of the first expr before the comparison. Oracle compares the exprs using nonpadded comparison semantics. Character comparison is based on the value of the character in the database character set. One character is greater than another if it has a higher character set value. If the value returned by this function is character data, then its datatype is always VARCHAR2.
Create the following table with some values:
DROP TABLE tcol;
CREATE TABLE tcol (
recno NUMBER(2),
col1 NUMBER(2),
col2 NUMBER(2),
col3 NUMBER(2)
);
INSERT INTO tcol (recno,col1,col2,col3) VALUES (1,20,40,22);
INSERT INTO tcol (recno,col1,col2,col3) VALUES (2,50,10,25);
INSERT INTO tcol (recno,col1,col2,col3) VALUES (3,10,44,12);
INSERT INTO tcol (recno,col1,col2,col3) VALUES (4,22,90,65);
COMMIT;
Now you can create the following view:
DROP VIEW vcol;
CREATE VIEW vcol AS
SELECT recno, GREATEST(col1,col2,col3) max_val FROM tcol;
SELECT * FROM vcol;
RECNO MAX_VAL
---------- ----------
1 40
2 50
3 44
4 90
Or, you can use an Inline View:
SELECT * FROM (
SELECT recno, GREATEST(col1,col2,col3) max_val FROM tcol
);
RECNO MAX_VAL
---------- ----------
1 40
2 50
3 44
4 90
Create your own Password «Encryption» Function
For applications dealing with highly sensitive data, Oracle provides the DBMS_OBFUSCATION_TOOLKIT PL/SQL package to encrypt and decrypt data, including string inputs and raw inputs. The function is limited to selected algorithms, such as the Data Encryption Standard (DES). Developers may not plug in their own encryption algorithms, and the key length is also fixed.
Another solution is to hash or digest the data using the GET_HASH_VALUE Function of the DBMS_UTILITY package.
This function computes a hash value for the given string.
Syntax
DBMS_UTILITY.GET_HASH_VALUE (
name VARCHAR2,
base NUMBER,
hash_size NUMBER)
RETURN NUMBER;
Parameters
| name |
String to be hashed. |
| base |
Base value for the returned hash value to start at. |
| hash_size |
Desired size of the hash table. |
Returns
A hash value based on the input string. For example, to get a hash value on a string where the hash value should be between 1000 and 3047, use 1000 as the base value and 2048 as the hash_size value. Using a power of 2 for the hash_size parameter works best.
select DBMS_UTILITY.GET_HASH_VALUE (
'zahn', 1000, POWER(2,11)
) "Hash Val" FROM dual;
Hash Val
----------
1154
To validate a username/password we take them, and hash it. This results in a fixed length string of some bytes of data. We compare that to the stored hash and if they match -- you are in, if not -- you are not.
So, for our password check function, we would simply glue the USERNAME together with the supplied PASSWORD.
CREATE OR REPLACE FUNCTION hashit
(p_username IN VARCHAR2, p_password IN VARCHAR2)
RETURN VARCHAR2
IS
BEGIN
RETURN
LTRIM (
TO_CHAR (
DBMS_UTILITY.GET_HASH_VALUE (
UPPER(p_username)||'/'||
UPPER(p_password),
1000000000,
POWER(2,30)
),
RPAD('X',29,'X')||'X'
)
);
END hashit;
/
So, we have a function digest that takes a username and password, hashes it into 1 of 1073741824 different numeric values, adds 1000000000 to it (to make it big) and turns it into HEX. This is what we would store in the database -- not the password. Now when the user presents a username/password, we digest it and compare -- if they match, you get in, if not you do not.
SELECT hashit ('zahn','martin') FROM dual;
HASHIT('ZAHN','MARTIN')
------------------------
3C5525AA
Getting Rows N through M of a Result Set
Author of this Tip: Thomas Kyte
You would like to fetch data and sort it based on some field. As this query results into approx 100 records, you would like to cut the result set into 4, each of 25 records and you would like to give sequence number to each record.
SELECT *
FROM (SELECT A.*, ROWNUM rnum
FROM (your query including the order by) A
WHERE ROWNUM <= MAX_ROWS )
WHERE rnum >= MIN_ROWS
/
Example
SELECT *
FROM (SELECT A.*, ROWNUM rnum
FROM (SELECT ename,dname
FROM emp e, dept d
WHERE e.deptno = d.deptno
ORDER BY E.ENAME) A
WHERE ROWNUM <= 5)
WHERE rnum >= 2
/
ENAME DNAME RNUM
---------- -------------- ----------
ALLEN SALES 2
BLAKE SALES 3
CLARK ACCOUNTING 4
FORD RESEARCH 5
Configuring OS Authentication on W2K to connect to Oracle
OS authentication is a very useful feature of Oracle. If you are unfamiliar with it, basically what it does is allow the users to connect to the database by authenticating their W2K username in the database. No password is associated with an OPS$ account since it is assumed that OS authentication is sufficient. There are many benifits to taking advantage of this:
- The user does not have to keep track of multiple ID’s and passwords.
|
- The user can be forced to change his W2K password periodically
|
- The Oracle DBA does not have to keep track of password changes.
|
- You can run scripts locally on your workstation, or on the server through SQL*PLUS that do not contain ID and password.
|
Of course there must be disadvantages of this method. If the password for an NT account becomes known, oracle access is then granted without another level of security. The other disadvantage is that your configuration may not be set up correctly to support this.
The Windows native authentication adapter works with Windows authentication protocols to enable access to your Oracle9i database. Kerberos is the default authentication protocol for Windows 2000.
If the user is logged on as a Windows 2000 domain user from a Windows 2000 computer, then Kerberos is the authentication mechanism used by the NTS adapter.
If authentication is set to NTS on a standalone Windows 2000 or Windows NT 4.0 computer, ensure that Windows Service NT LM Security Support Provider is started. If this service is not started on a standalone Windows 2000 or Windows NT 4.0 computer, then NTS authentication fails. This issue is applicable only if you are running Windows 2000 or Windows NT 4.0 in standalone mode.
Client computers do not need to specify an authentication protocol when attempting a connection to an Oracle9i database. Instead, Oracle9i database determines the protocol to use, completely transparent to the user. The only Oracle requirement is to ensure that parameterSQLNET.AUTHENTICATION_SERVICES contains nts in the SQLNET.ORA file located inORACLE_HOME\network\admin on both the client and database server:
SQLNET.AUTHENTICATION_SERVICES = (nts)
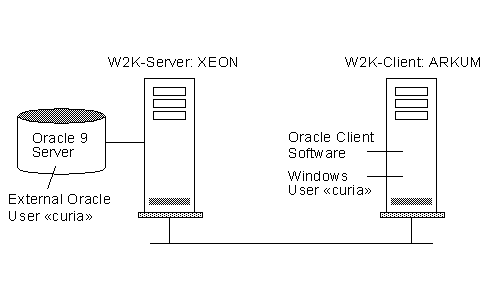
The W2K User «curia» on the Windows Client Computer ARKUM wants to connect to Oracle 9i Database located on the W2K Server XEON using Operating System Authentication handled by ARKUM. Users need not enter a login-ID and password when using this type of login.
The user account on the client ARKUM must match the user account on the server XEON. The OPS$ account in the database must be in the format OPS$username.
| 1. |
Create a user account «curia» on the Windows NT Client ARKUM . |
| 2. |
Create an OPS$ account in the Oracle Database on XEON.
create user OPS$curia identified externally;
grant connect, resource to OPS$curia;
alter user OPS$curia default tablespace tab;
alter user OPS$curia temporary tablespace temp;
|
| 3. |
By default you cannot connect through SQL NET, to establish this feature you must set the INIT.ORA file parameter REMOTE_OS_AUTHENT=TRUE on XEON which will allow authentication of remote clients with the value of OS_AUTHENT_PREFIX.
os_authent_prefix = "OPS$"
remote_os_authent = true
You might want to caution that "only people who do not care about their data" would use this. The reason is that with REMOTE_OS_AUTHENT=TRUE, all I need to do is plop a machine down on the network, create a named account on this machine and I'm in.
We use REMOTE_OS_AUTHENT=TRUE in Oracle but the way we set it up is:
- Only low level user accounts use it.
- Use the protcol.ora file to restrict inbound IP connects to the database to come only from specified data center machines.
For information on protocol.ora read Understanding SQL*Net Release 2.3 Part No. A424841. In appendix A they describe the protcol.ora file and tell how to set up Validnode Verification. This allows you to specify from which hosts a listener will accept inbound connections from.
|
| 4. |
Setup the TNSNAMES.ORA configuration file on ARKUM that contains service names to connect descriptors. This file is used for the local naming method. The tnsnames.ora file typically resides in $ORACLE_HOME/network/admin on UNIX platforms and ORACLE_HOME\network\admin on Windows.
XEO2.WORLD =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(Host = xeon)(Port = 1522))
(CONNECT_DATA =
(SERVICE_NAME = XEO2)
(SERVER = DEDICATED)
)
)
|
Now run SQLPLUS on the client and login to the database as follows:
How to kill Oracle Process on Win NT/2000
Win NT/2000 is a thread based Operating System and not process based Operating System like Unix. Oracle user and background processes are not multiple processes but, threads with in oracle.exe process. 'orakill' is oracle provided utility to kill a particular resource intensive thread under oracle.exe process.
For help type in at the DOS prompt
C:\>orakill /?
The following query can be used to get the sid, thread id of a particular resource intensive thread.
select sid, spid as thread, osuser, s.program
from sys.v_$process p, sys.v_$session s
where p.addr = s.paddr;
SID THREAD OSUSER PROGRAM
---------- ------------ -------- ------------
1 1264 SYSTEM ORACLE.EXE
2 1268 SYSTEM ORACLE.EXE
3 1272 SYSTEM ORACLE.EXE
4 1276 SYSTEM ORACLE.EXE
5 1296 SYSTEM ORACLE.EXE
6 1324 SYSTEM ORACLE.EXE
7 1396 SYSTEM ORACLE.EXE
8 1408 SYSTEM ORACLE.EXE
9 1484 SYSTEM ORACLE.EXE
10 1504 SYSTEM ORACLE.EXE
16 2160 zahn sqlplusw.exe
11 1400 zahn sqlplusw.exe
Say the query from user zahn is consuming lot resources and it can be killed by running orakill utility as follows.
C:\>orakill 11 1400
Primary Keys and Unique Columns in Oracle and SQL-Server
Overview
The SQL-92 standard requires that all values in a primary key be unique and that the column not allow null values. Both Oracle and Microsoft SQL Server enforce uniqueness by automatically creating unique indexes whenever a PRIMARY KEY or UNIQUE constraint is defined. Additionally, primary key columns are automatically defined as NOT NULL. Only one primary key is allowed per table.
A SQL Server clustered index is created by default for a primary key, though a nonclustered index can be requested. The Oracle index on primary keys can be removed by either dropping or disabling the constraint, whereas the SQL Server index can be removed only by dropping the constraint.
In either RDBMS, alternate keys can be defined with a UNIQUE constraint. Multiple UNIQUE constraints can be defined on any table. UNIQUE constraint columns are nullable. In SQL Server, a nonclustered index is created by default, unless otherwise specified.
UNIQUE Indexes and NULL's
When migrating your application, it is important to note that SQL Server allows only one row to contain the value NULL for the complete unique key (single or multiple column index), and Oracle allows any number of rows to contain the value NULL for the complete unique key.
Example
Let's make a small example to verify this situation.
DROP TABLE departement
GO
CREATE TABLE departement (
dept INTEGER NOT NULL,
dname VARCHAR(30) NULL,
CONSTRAINT departement_pk
PRIMARY KEY CLUSTERED (dept),
CONSTRAINT dname_unique
UNIQUE NONCLUSTERED (dname)
)
GO
INSERT INTO departement (dept,dname) VALUES (1,'Sales')
INSERT INTO departement (dept,dname) VALUES (2,'Informatik')
INSERT INTO departement (dept,dname) VALUES (3,'Support')
INSERT INTO departement (dept,dname) VALUES (4,NULL)
INSERT INTO departement (dept,dname) VALUES (5,NULL)
GO
(1 row(s) affected)
(1 row(s) affected)
(1 row(s) affected)
(1 row(s) affected)
Server: Msg 2627, Level 14, State 2, Line 1
Violation of UNIQUE KEY constraint 'dname_unique'.
Cannot insert duplicate key in object 'departement'.
The statement has been terminated.
DROP TABLE departement;
CREATE TABLE departement (
dept INTEGER NOT NULL,
dname VARCHAR2(30) NULL,
CONSTRAINT departement_pk
PRIMARY KEY (dept)
USING INDEX TABLESPACE tab
PCTFREE 0 STORAGE (
INITIAL 10K NEXT 10K
MINEXTENTS 1 MAXEXTENTS UNLIMITED),
CONSTRAINT dname_unique
UNIQUE (dname)
USING INDEX TABLESPACE tab
PCTFREE 0 STORAGE (
INITIAL 10K NEXT 10K
MINEXTENTS 1 MAXEXTENTS UNLIMITED)
);
INSERT INTO departement (dept,dname) VALUES (1,'Sales');
INSERT INTO departement (dept,dname) VALUES (2,'Informatik');
INSERT INTO departement (dept,dname) VALUES (3,'Support');
INSERT INTO departement (dept,dname) VALUES (4,NULL);
INSERT INTO departement (dept,dname) VALUES (5,NULL);
COMMIT;
1 row created.
1 row created.
1 row created.
1 row created.
1 row created.
Commit complete.
Conclusion
Oracle is NOT SQL-Server .... SQL-Server is NOT Oracle.
Display Exact Match First
Overview
In an application, someone may ask to display an exact match first. For example, suppose that the following SQL:
SELECT * FROM tubes
WHERE prod LIKE '%Tube%' ORDER BY prod;
Returns the following Results:
ID PROD
---------- -------------------------------------------------
1 51H Tube Joint Compound
2 5X12 Flex Tube
3 725-4B / Hose-Male Tube
4 90 Deg Male Elbow Tube OD 3/8, Tube Thread 1/4
7 Tail Tube
8 Tail Tube Strap
5 Tube
6 Tube Cutter Hose / Plastic
9 Wrench 12in Tube
But you want the exact match first:
ID PPROD
---------- ------------------------------------------------
5 Tube
1 51H Tube Joint Compound
2 5X12 Flex Tube
3 725-4B / Hose-Male Tube
4 90 Deg Male Elbow Tube OD 3/8, Tube Thread 1/4
7 Tail Tube
8 Tail Tube Strap
6 Tube Cutter Hose / Plastic
9 Wrench 12in Tube
Here is a (nearly perfect) solution
SELECT id, DECODE(prod,'Tube', ' '||prod, prod) pprod
FROM tubes
WHERE prod LIKE '%Tube%' ORDER BY pprod;
We get a space in front of 'Tube' with this solution, but in many applications this can be filtered with TRIM later.
Reorganize very large tables with the NOLOGGING Option
Overview
The Oracle NOLOGGING clause is a wonderful tool since it often halves run times, but you need to remember the danger. For example, a common practice is to reorganize very large tables is to use CREATE TABLE AS SELECT (CTAS) commands:
SQL> CREATE TABLE
2 new_emp
3 TABLESPACE
4 tab
5 NOLOGGING
6 AS
7 SELECT * FROM emp;
Table created.
SQL> DROP TABLE emp;
Table dropped.
SQL> RENAME new_emp TO emp;
Table renamed.
However, you must be aware that a roll-forward through this operation is not possible, since there are no images in the archived redo logs for this operation. Hence, you MUST take a full backup after performing any NOLOGGING operation.
Watch out for the UNRECOVERABLE and NOLOGGING clause
Be very careful using UNRECOVERABLE clause (Oracle7) and the NOLOGGING clause (Oracle8) when performing CREATE INDEX or CREATE TABLE AS SELECT (CTAS) commands.
The CTAS with NOLOGGING or UNRECOVERABLE will send the actual create statement to the redo logs (this information is needed in the data dictionary), but all rows loaded into the table during the operation are NOT sent to the redo logs.
With NOLOGGING in Oracle8, although you can set the NOLOGGING attribute for a table, partition, index, or tablespace, NOLOGGING mode does not apply to every operation performed on the schema object for which you set the NOLOGGING attribute.
Only the following operations can make use of the NOLOGGING option:
- alter table...move partition
- alter table...split partition
- alter index...split partition
- alter index...rebuild
- alter index...rebuild partition
- create table...as select
- create index
- direct load with SQL*Loader
- direct load INSERT
Many Oracle professionals use NOLOGGING because the actions runs fast because the Oracle redo logs are bypassed. However, this can be quite dangerous if you need to roll-forward through this time period during a database recovery.
It is not possible to roll forward through a point in time when an NOLOGGING operation has taken place. This can be a CREATE INDEX NOLOGGING, CREATE TABLE AS SELECT NOLOGGING, or an NOLOGGING table load.
Oracle 10g new features
Overview
With all of the hoopla surrounding the impending release of Oracle10g, it is sometimes difficult to differentiate between the truly valuable features and the marginal new features.
On one hand, Oracle10g is more complex and robust than previous database versions with  its wealth of new tuning options, sophisticated tuning tools and enhanced tuning parameters. On the other hand, it issimpler than any Oracle database before it. At your option, you can disable much of the flexibility (and complexity) of Oracle and create an easy to maintain system that requires little experienced human intervention. its wealth of new tuning options, sophisticated tuning tools and enhanced tuning parameters. On the other hand, it issimpler than any Oracle database before it. At your option, you can disable much of the flexibility (and complexity) of Oracle and create an easy to maintain system that requires little experienced human intervention.
This dichotomy is an amazing new feature and allows Oracle10g to be either robust or simple. Much of the new 10g features address this issue.
10g provides a wealth of features that can be used to automate almost every aspect of its database administration. It is important to note that these automation features are optional, and they are not intended to replace standard DBA activities. Rather, the Oracle10g automation features are aimed at shops that do not have the manpower or expertise to manually perform the tasks.
So, if your 10g database does not require detailed, expert tuning, then the automated features might be a good choice. They are targeted at these market segments:
Small shops: Small installations that can't afford a trained Oracle DBA. Shops with over-worked DBAs: Large shops with hundreds of instances where the DBA does not have time to properly tune each system.
Let's take a closer look at the 10g automation features.
Automation Features
Automatic Workload Repository defaults to a collection interval every 30 minutes and collects data that is the foundation for all of the other self-tuning features. AWR is very much like STATSPACK, especially the level-5 STATSPACK collection mechanism where top SQL is collected every hour, based on your rolling thresholds for high-use SQL. In addition to the SQL, AWR collects detailed run-time statistics on the top SQL (disk reads, executions, consistent gets) and uses this information to adjust the rolling collection threshold. This technique ensures that AWR always collects the most resource-intensive SQL.
The Automatic Maintenance Tasks automate the routine tasks of refreshing statistics when they become stale, and rebuilding indexes when they become sub-optimal. The AMTs are scheduled for execution inside the new Oracle10g Unified Scheduler (US), providing a primitive DBA functionality.
The Automatic Database Diagnostic Monitor analyzes the AWR data, much the same as a human DBA would analyze a STATSPACK report. ADDM searches for lock-and-latch contention, file I/O bottlenecks and SGA shortages just like a human DBA. The ADDM then triggers automatic reconfiguration using the Automatic Storage Management (ASM) and Automatic Memory Management (AMM) components.
The Automated Memory Management component manages the RAM inside the System Global Area, much the same way as the automatic PGA management feature in Oracle9i (pga_aggregate_target) automates the sort and hash areas with PGA RAM. The ASM uses real-time workload data from AWR and changes the sizes of the shared pool and data buffers according to the current workload.
The Automatic Storage Management feature allows for the automatic stripe-and-mirror everywhere approach to be used to automatically load balance the disk I/O subsystem and remove the need for the DBA to specify physical file locations when allocating a tablespace.
Other Features
The SQL Tuning Advisor works with the Automatic Tuning Optimizer (ATO) to analyze historical SQL workload (using data from the AWR), and generates recommendations for new indexes and materialized views that will reduce the disk I/O associated with troublesome SQL statements.
Server Generated Alerts (SGA) interfaces with the US to send e-mail messages when an external problem is impeding Oracle performance. External problems might include a UNIX mount point that is full, causing a failure of ASM files to extend or a RAM shortage with the System Global Area.
Benefits to .NET
Oracle Database 10g is an enterprise-class, cluster-capable, grid-ready database that supports all new features equally across all platforms, including Windows server environments. In addition to the server side of the database itself, Oracle has worked over the years to facilitate application-development integration for Microsoft developers, especially those working in the .NET world. To this end, Oracle provided Oracle Data Provider for .NET (ODP.NET), which provides connectivity between the Oracle database and .NET applications. Many enhancements in the latest release of ODP.NET further extend that support by providing significant integration and performance improvements between .NET and Oracle Database 10g. This "grid-aware" version of ODP.NET means .NET developers can take advantage of Oracle Database 10g's grid capabilities.
ODP.NET now has enhanced support for Oracle XML DB. "That's important," he says, "because many .NET developers use XML heavily in their applications. Developers who are using .NET will be able to work with XML data much more easily, because of our integration with XML DB through the new APIs and a new XMLType datatype in ODP.NET."
ODP.NET now lets you manipulate XML data more easily within .NET, using the XMLType that's been native to the Oracle database since Oracle Database 9i. It also lets you access relational or object-relational data as XML data in an Oracle database instance from the Microsoft .NET environment—using Visual Studio .NET development tools, such as Visual Basic, Visual C++, or Visual C#, for example—and process the XML by using the facilities of the Microsoft .NET framework and saving any changes back into the Oracle database as XML data.
ODP.NET includes many other new capabilities, including support for nested cursors and PL/SQL associative arrays, allowing .NET developers to gain the benefits of working in Oracle's own programming constructs without losing the ability to use any part of .NET's functionality. For example, PL/SQL associative arrays (formerly known as PL/SQL Index-By Tables), comparable to hash tables in some other programming languages, are sets of key-value pairs that can represent data sets of arbitrary size; associative arrays can provide fast lookup of individual elements in an array without knowing their positions within the array or having to loop through all the array elements.
Another improvement in Oracle Database 10g available to ODP.NET developers is the new IEEE-compliant datatypes FLOAT and DOUBLE. Supported in ODP.NET, they take up less storage space, are faster than the other number datatypes available in Oracle, and facilitate more-direct handling of FLOAT and DOUBLE datatypes between host variables and stored data.
Finally, there are numerous other performance improvements, in terms of both performance and data retrieval—particularly in retrieving number data and LOBs. For example, in prior releases, developers had limited control over retrieving LOB data, "but with this release, there's a new property in ODP.NET,InitialLOBfetchSize, that allows you to optimize LOB retrieval to suit your needs. For example, a European government agency's geographic information system (GIS) application that accesses tens of thousands of rows of LOB data gained a 17-fold improvement in its application speed, simply by replacing the ODP.NET driver with the newer version.
Oracle running on Gentoo Linux
Overview
We have tested Gentoo Linux / Oracle 9.2 at work. Gentoo is a pretty nice distribution, and provides a useful mechanism called "portage" for compiling software from source and keeping things up to date. In general, the linux machine seems a lot faster now compared to the previous Redhat binary image. You have a lot of control over what's installed by default, so it's also using far less disk space. at work. Gentoo is a pretty nice distribution, and provides a useful mechanism called "portage" for compiling software from source and keeping things up to date. In general, the linux machine seems a lot faster now compared to the previous Redhat binary image. You have a lot of control over what's installed by default, so it's also using far less disk space.
Although Gentoo is not an officially supported Linux distro for Oracle, it works without problems. We did run into a few issues during installation.
Installation
Install libcompat. You can emerge this like so (as user root):
emerge sys-libs/lib-compat
gcc 2.95 has to be the default gcc version in order to install successfully. Using a later version resulted in the following error: Error in invoking target ioracle of makefile
/opt/product/oracle/9.2.0/ctx/lib/in_rdbms.mk.
Verify the version you're using with:
gcc --version
We got returned
gcc (GCC) 3.2.3 20030422 (Gentoo Linux
1.4.3.2.3-r2, propolice)
To get the Oracle installation to complete, we installed gcc 2.95
cd /usr/portage/sys-devel/gcc
Check for the exact emerge name of gcc 2.95
emerge /usr/portage/sys-devel/gcc/gcc-2.95.3-r8.ebuild
Then temporarily changed /usr/bin/gcc into a symbolic link
mv /usr/bin/gcc /usr/bin/gcc-backup
ln -s /usr/i686-pc-linux-gnu/gcc-bin/2.95/gcc \
/usr/bin/gcc
After installation was complete, restore the original version:
rm /usr/bin/gcc
mv /usr/bin/gcc-backup /usr/bin/gcc
During installation, we got the following error: Error in invoking target install of makefile /opt/oracle/product/9.2.0/ctx/lib/ins_ctx.mk. It's documented on Metalink as Note 191587.1, and you can work around it like this:
Modify the file $ORACLE_HOME/ctx/lib/ins_ctx.mk changing
ctxhx: $(CTXHXOBJ)
$(LINK) $(CTXHXOBJ) $(INSO_LINK)
to
ctxhx: $(CTXHXOBJ)
$(LINK) -ldl $(CTXHXOBJ) $(INSO_LINK)
After fixing the above, installation was still failing with an error in ins_ctx.mk. It turns out this is caused by bug 2037255 in Oracle Text. If you don't need Oracle Text, just click Ignore on the error dialog.
The whole rest of the installation is exactly the same as on any other Linux Distribution. A short installation guide can be found here.
Hiding the Oracle Password
Author of this Tip: Thomas Kyte
Overview
If you write shell scripts that invoke SQL*Plus and other tools from the command line, you put the username and password on the command line. We don't like the fact that the "ps" command can display the command line of the process to other users, since it will reveal the username and password for this account! How canwe mask this information from "ps"?
OS Authentication
The favorite solution to this is to use an "identified externally" account.
For example, we have set:
NAME TYPE VALUE
------------------------------ ------- --------------------
os_authent_prefix string ops$
in the INIT.ORA, we then:
create user ops$zahn identified externally;
This lets us:
$ id
uid=400(zahn) gid=400(dba)
$ sqlplus /
SQL> show user
USER is "OPS$ZAHN"
We do not need a username password anymore (we can still use them but we can always use / to log in). This is perfect for cron jobs, at jobs and sysadmin accounts, but not for client application connections.
Environment Variables
This is useful for Scripts, look at the following example:
#!/bin/bash
# Let this be you env variables.
export APP_USER=scott
export APP_PASS=tiger
export APP_SID=GEN1
# Here is the script with a execute permission.
sqlplus << END_OF_SQL
${APP_USER}/${APP_PASS}@${APP_SID}
select * from user_tables;
END_OF_SQL
exit $?
If you are on solaris, fire up your script and then go:
/usr/ucb/ps -auxwwee | grep APP_PASS
and see what you see ... ps can dump the ENVIRONMENT as well. (very handy trick to know, can be useful to see a processes environment -- but for you -- it exposes the password.
How to Acquire a Lock without Handling Exceptions
Overview
Normally we use FOR UPDATE NOWAIT to acquire a lock on rows. This statement either locks all the selected rows or the control is returned without acquiring any lock (i.e. even on rows which are available for locking) after throwing an exception.
For Update SKIP LOCKED
But there is an feature in Oracle Database, the clause FOR UPDATE SKIP LOCKED, which can be used to lock rows that are available for locking and skip the rows that have been locked by other sessions. This statement returns the control back without throwing an exception, even if all the rows are locked by another session.
To illustrate, we open two sessions. In the first session, we lock the row with deptno as 10 using FOR UPDATE NOWAIT.
SELECT * FROM dept
WHERE deptno = 10
FOR UPDATE NOWAIT;
DEPTNO DNAME LOC
---------- -------------- -------------
10 ACCOUNTING NEW YORK
In the second session, we try to lock two rows (deptno 10 and 20) from the table dept using FOR UPDATE NOWAIT. An exception is thrown after executing the following statement because one of the row (i.e. deptno 10) out of the selected list is already locked by session 1.
SELECT * FROM dept
WHERE deptno IN (10,20)
FOR UPDATE NOWAIT;
SELECT * FROM dept WHERE deptno IN (10,20)
FOR UPDATE NOWAIT
ERROR at line 1:
ORA-00054: resource busy and acquire with NOWAIT specified
Now we again try to lock two rows (deptno(s) 10 and 20) from the table dept but using the clause FOR UPDATE SKIP LOCKED instead of FOR UPDATE NOWAIT. As you can see the following statement has
1. returned the control without throwing an exception
2. acquired lock on the row (i.e. deptno 20) which is available for locking
3. skipped the row (i.e. deptno 10) that has been locked already by session 1
SELECT * FROM dept
WHERE deptno IN (10,20)
FOR UPDATE SKIP LOCKED;
DEPTNO DNAME LOC
---------- -------------- -------------
20 RESEARCH DALLAS
Updating a Row Using a Record
Overview
Although you can enumerate each field of a PL/SQL record when inserting or updating rows in a table, the resulting code is not especially readable or maintainable. Instead, you can use PL/SQL records directly in these statements. The most convenient technique is to declare the record using a %ROWTYPE attribute, so that it has exactly the same fields as the SQL table.
Example
DECLARE
emp_rec emp%ROWTYPE;
BEGIN
emp_rec.eno := 1500;
emp_rec.ename := 'Steven Hill';
emp_rec.sal := '40000';
--
-- A %ROWTYPE value can fill
-- in all the row fields.
--
INSERT INTO emp VALUES emp_rec;
--
-- The fields of a %ROWTYPE can
-- completely replace the table columns.
--
UPDATE emp SET ROW = emp_rec WHERE eno = 100;
END;
/
Referencing the Same Subquery Multiple Times
Overview
In complex queries that process the same subquery multiple times, you might be tempted to store the subquery results in a temporary table and perform additional queries against the temporary table. TheWITH clause lets you factor out the subquery, give it a name, then reference that name multiple times within the original complex query.
This technique lets the optimizer choose how to deal with the subquery results -- whether to create a temporary table or inline it as a view.
For example, the following query joins two tables and computes the aggregate SUM(SAL) more than once. The bold text represents the parts of the query that are repeated.
The WITH clause
SELECT dname, SUM(sal) AS dept_total
FROM emp, dept
WHERE emp.deptno = dept.deptno
GROUP BY dname HAVING
SUM(sal) >
(
SELECT SUM(sal) * 1/3
FROM emp, dept
WHERE emp.deptno = dept.deptno
)
ORDER BY SUM(sal) DESC;
DNAME DEPT_TOTAL
-------------- ----------
RESEARCH 10875
SALES 9400
Execution Plan
------------------------------------------------------
0 SELECT STATEMENT Optimizer=CHOOSE
1 0 SORT (ORDER BY)
2 1 FILTER
3 2 SORT (GROUP BY)
4 3 MERGE JOIN
5 4 SORT (JOIN)
6 5 TABLE ACCESS (FULL) OF 'DEPT'
7 4 SORT (JOIN)
8 7 TABLE ACCESS (FULL) OF 'EMP'
9 2 SORT (AGGREGATE)
10 9 MERGE JOIN
11 10 SORT (JOIN)
12 11 TABLE ACCESS (FULL) OF 'DEPT'
13 10 SORT (JOIN)
14 13 TABLE ACCESS (FULL) OF 'EMP'
You can improve the query by doing the subquery once, and referencing it at the appropriate points in the main query. The bold text represents the common parts of the subquery, and the places where the subquery is referenced.
WITH
summary AS
(
SELECT dname, SUM(sal) AS dept_total
FROM emp, dept
WHERE emp.deptno = dept.deptno
GROUP BY dname
)
SELECT dname, dept_total
FROM summary
WHERE dept_total >
(
SELECT SUM(dept_total) * 1/3
FROM summary
)
ORDER BY dept_total DESC;
DNAME DEPT_TOTAL
-------------- ----------
RESEARCH 10875
SALES 9400
Execution Plan
---------------------------------------------------
0 SELECT STATEMENT Optimizer=CHOOSE
1 2 RECURSIVE EXECUTION OF 'SYS_LE_2_0'
2 0 TEMP TABLE TRANSFORMATION
3 2 SORT (ORDER BY)
4 3 FILTER
5 4 VIEW
6 5 TABLE ACCESS (FULL) OF 'SYS_TEMP'
7 4 SORT (AGGREGATE)
8 7 VIEW
9 8 TABLE ACCESS (FULL) OF 'SYS_TEMP'
UPDATE joined Tables (Key Preserve Concept)
Overview
When you update a column in joined tables, the value of some records are changed into the value NULL, even if some records should not be updated. To demonstrate this behaviour with Oracle9i, look at the following example:
DROP TABLE t1;
CREATE TABLE t1 (
key INT,
col1 VARCHAR2(25)
);
DROP TABLE t2;
CREATE TABLE t2 (
key INT,
value VARCHAR2(25),
col2 INT
);
INSERT INTO t1 VALUES (100, 'Original Data');
INSERT INTO t1 VALUES (200, 'Original Data');
INSERT INTO t2 VALUES (100, 'New Data', 1 );
COMMIT;
SELECT * FROM t1;
KEY COL1
---------- -------------------------
100 Original Data
200 Original Data
VARIABLE other_value NUMBER
EXEC :other_value := 1
UPDATE t1 B
SET col1 = (SELECT value
FROM t2 O
WHERE B.key = O.key
AND O.col2 = :other_value);
2 rows updated. <==== !
SELECT * FROM t1;
KEY COL1
---------- -------------------------
100 New Data
200
The first row (KEY = 100) was updated as desired, but the second row (KEY = 200) was updated with NULL, not as expected, why?
Key Preserved Concept in Oracle
In the example above we update a join. We can only modify the columns in one of the tables ( T1 ) and the other tables ( T2 ) we are NOT modifying must be "key preserved".
That is - we must be able to verify that at most one record will be returned when we join T1 to this other table T2. In order to do that, key in T2 must either be a primary key or have a unique constraint applied to it.
DROP TABLE t2;
CREATE TABLE t2 (
key INT PRIMARY KEY,
value VARCHAR2(25),
col2 INT
);
Drop and recreate the tables T1 and T2 and insert the same values, then apply the following UPDATE using an inline view:
UPDATE
(SELECT col1, value
FROM t1, t2
WHERE t1.key = t2.key
AND t2.col2 = :other_value)
SET col1 = value
/
1 row updated. <==== !
SELECT * FROM t1;
KEY COL1
---------- -------------------------
100 New Data
200 Original Data
Row 2 (KEY = 200) is now untouched and only the rows we wanted are updated.
Another solution will work with no constraints on anything -- you do not need the primary key/unique constraint on T2 (but you better be sure the subquery returns 0 or 1 records!). It is very much like our update, just has a where clause so that only rows that we find matches for are actually updated.
DROP TABLE t1;
CREATE TABLE t1 (
key INT,
col1 VARCHAR2(25)
);
DROP TABLE t2;
CREATE TABLE t2 (
key INT,
value VARCHAR2(25),
col2 INT
);
INSERT INTO t1 VALUES (100, 'Original Data');
INSERT INTO t1 VALUES (200, 'Original Data');
INSERT INTO t2 VALUES (100, 'New Data', 1 );
COMMIT;
UPDATE t1
SET col1 = (SELECT value
FROM t2
WHERE t1.key = t2.key
AND col2 = :other_value)
WHERE EXISTS (SELECT value
FROM t2
WHERE t1.key = t2.key
AND col2 = :other_value)
/
1 row updated.
SELECT * FROM t1;
KEY COL1
---------- -------------------------
100 New Data
200 Original Data
Conclusion
The concept of a key-preserved table is fundamental to understanding the restrictions on modifying joins (join views). A table is key preserved if every key of the table can also be a key of the result of the join. So, a key-preserved table has its keys preserved through a join.
More Information about this concept can be found in the Oracle Database Administrator's Guide.
Hierarchical Query Enhancements in Oracle 10g
Overview
Some applications make extensive use of hierarchical data such as an organization chart, a bill of material in a manufacturing and assembly plant, or a family tree. These types of information are most conveniently represented in a tree structure. However, such data can be easily fit into a relational table by using a self-referential relationship.
Oracle provides some useful extensions to ANSI SQL to manipulate hierarchical data represented in a relational table. Up to Oracle9i, Oracle’s hierarchical extensions include the START WITH … CONNECT BY clause, the PRIOR operator, and the LEVEL pseudo-column. The following example lists the employees in a hierarchical order and indents the subordinates under an employee:
column EmpName format a30
SELECT RPAD(' ',2*LEVEL,' ')||ename EmpName, empno, mgr
FROM emp
START WITH mgr IS NULL
CONNECT BY PRIOR empno = mgr
/
EMPNAME EMPNO MGR
------------------------------ ---------- ----------
KING 7839
JONES 7566 7839
SCOTT 7788 7566
ADAMS 7876 7788
FORD 7902 7566
SMITH 7369 7902
BLAKE 7698 7839
ALLEN 7499 7698
WARD 7521 7698
MARTIN 7654 7698
TURNER 7844 7698
JAMES 7900 7698
CLARK 7782 7839
MILLER 7934 7782
New Features
The new hierarchical query features in Oracle Database 10g are:
New Operator
CONNECT_BY_ROOT
New Pseudocolumns
CONNECT_BY_ISCYCLE
CONNECT_BY_ISLEAF
New Function
SYS_CONNECT_BY_PATH (Oracle9i)
New Keywords
NOCYCLE
SIBLINGS (Oracle9i)
CONNECT_BY_ROOT
The CONNECT_BY_ROOT operator, when applied to a column, returns the value for that column for the root row. The following example illustrates how the CONNECT_BY_ROOT operator is used:
SELECT ename, CONNECT_BY_ROOT ename "Top Manager"
FROM emp
START WITH mgr = 7839
CONNECT BY PRIOR empno = mgr
/
ENAME Top Manager
---------- -----------
JONES JONES
SCOTT JONES
ADAMS JONES
FORD JONES
SMITH JONES
BLAKE BLAKE
ALLEN BLAKE
WARD BLAKE
MARTIN BLAKE
TURNER BLAKE
JAMES BLAKE
CLARK CLARK
MILLER CLARK
In this example, the organization tree is built by starting with the rows that have MGR = 7839. This means that anyone whose manager is 7839 will be considered a root for this query. Now, all the employees who come under the organizations under these roots will be displayed in the result set of this query along with the name of their top-most manager in the tree. The CONNECT_BY_ROOT operator determines the top-most node in the tree for a given row.
NOCYCLE
Cycles are not allowed in a true tree structure. But some hierarchical data may contain cycles. In a hierarchical structure, if a descendant is also an ancestor, it is called a cycle. It is sometimes difficult to identify cycles in hierarchical data. The hierarchical construct “START WITH … CONNECT BY … PRIOR” will report an error if there is a cycle in the data.
To allow the “START WITH … CONNECT BY … PRIOR” construct to work properly even if cycles are present in the data, Oracle Database 10g provides a new keyword, NOCYCLE. If there are cycles in the data, you can use the NOCYCLE keyword in the CONNECT BY clause, and you will not get the error mentioned earlier.
The test data we have in the EMP table doesn’t have a cycle. To test the NOCYCLE feature, let’s introduce a cycle into the existing EMP data, by updating the MGR column of the top-most employee (KING with EMPNO=7839) with the EMPNO of one of the lowest level employees (MARTIN with EMPNO = 7654).
UPDATE emp
SET mgr = 7654
WHERE mgr IS NULL;
COMMIT;
column EmpName format a30
SELECT RPAD(' ',2*LEVEL,' ')||ename EmpName, empno, mgr
FROM emp
START WITH empno = 7839
CONNECT BY PRIOR empno = mgr
/
EMPNAME EMPNO MGR
------------------------------ ---------- ----------
KING 7839 7654
JONES 7566 7839
SCOTT 7788 7566
ADAMS 7876 7788
FORD 7902 7566
SMITH 7369 7902
BLAKE 7698 7839
ALLEN 7499 7698
WARD 7521 7698
MARTIN 7654 7698
KING 7839 7654
JONES 7566 7839
SCOTT 7788 7566
ADAMS 7876 7788
FORD 7902 7566
ERROR:
ORA-01436: CONNECT BY loop in user data
Besides the error, note that the whole tree starting with KING starts repeting under MARTIN. This is erroneous and confusing. The NOCYCLE keyword can be used in the CONNECT BY clause to get rid of this error:
SELECT RPAD(' ',2*LEVEL,' ')||ename EmpName, empno, mgr
FROM emp
START WITH empno = 7839
CONNECT BY NOCYCLE PRIOR empno = mgr
/
EMPNAME EMPNO MGR
------------------------------ ---------- ----------
KING 7839 7654
JONES 7566 7839
SCOTT 7788 7566
ADAMS 7876 7788
FORD 7902 7566
SMITH 7369 7902
BLAKE 7698 7839
ALLEN 7499 7698
WARD 7521 7698
MARTIN 7654 7698
TURNER 7844 7698
JAMES 7900 7698
CLARK 7782 7839
MILLER 7934 7782
The above query recognizes that there is a cycle and ignore the cycle (as an impact of the NOCYCLE keyword), and returns the rows as if there were no cycle.
CONNECT_BY_ISCYCLE
It is sometimes difficult to identify cycles in hierarchical data. Oracle 10g’s new pseudocolumn CONNECT_BY_ISCYCLE can help you identify the cycles in the data easily. The CONNECT_BY_ISCYCLE can be used only in conjunction with the NOCYCLE keyword in a hierarchical query. The CONNECT_BY_ISCYCLE pseudocolumn returns 1 if the current row has a child which is also its ancestor; otherwise it returns 0.
column EmpName format a15
SELECT RPAD(' ',2*LEVEL,' ')||ename EmpName, empno, mgr,
CONNECT_BY_ISCYCLE
FROM emp
START WITH empno = 7839
CONNECT BY NOCYCLE PRIOR empno = mgr
/
EMPNAME EMPNO MGR CONNECT_BY_ISCYCLE
--------------- ---------- ---------- ------------------
KING 7839 7654 0
JONES 7566 7839 0
SCOTT 7788 7566 0
ADAMS 7876 7788 0
FORD 7902 7566 0
SMITH 7369 7902 0
BLAKE 7698 7839 0
ALLEN 7499 7698 0
WARD 7521 7698 0
MARTIN 7654 7698 1
TURNER 7844 7698 0
JAMES 7900 7698 0
CLARK 7782 7839 0
MILLER 7934 7782 0
CONNECT_BY_ISLEAF
For correct results in the subsequent queries, we should revert the data back to its original state by rolling back (if you have not committed) the earlier change we did to force a cycle in the data. If you have already committed the change, then update the MGR for KING to NULL.
In a tree structure, the nodes at the lowest level of the tree are referred to as leaf nodes. Leaf nodes have no children. CONNECT_BY_ISLEAF is a pseudocolumn that returns 1 if the current row is a leaf, and returns 0 if the current row is not a leaf.
UPDATE emp
SET mgr = NULL
WHERE empno = 7839;
COMMIT;
column EmpName format a15
SELECT RPAD(' ',2*LEVEL,' ')||ename EmpName, empno, mgr, CONNECT_BY_ISLEAF
FROM emp
START WITH empno = 7839
CONNECT BY PRIOR empno = mgr
/
EMPNAME EMPNO MGR CONNECT_BY_ISLEAF
--------------- ---------- ---------- -----------------
KING 7839 0
JONES 7566 7839 0
SCOTT 7788 7566 0
ADAMS 7876 7788 1
FORD 7902 7566 0
SMITH 7369 7902 1
BLAKE 7698 7839 0
ALLEN 7499 7698 1
WARD 7521 7698 1
MARTIN 7654 7698 1
TURNER 7844 7698 1
JAMES 7900 7698 1
CLARK 7782 7839 0
MILLER 7934 7782 1
SYS_CONNECT_BY_PATH
The SYS_CONNECT_BY_PATH function was introduced in Oracle9i. However, it makes sense to discuss it along with the enhancements in Oracle Database 10g. The SYS_CONNECT_BY_PATH is function takes two arguments — a column name, and a character string — and returns the value of the column from the root node to each node, separated by the character string.
SELECT SYS_CONNECT_BY_PATH(ename, '/') "Path"
FROM emp
START WITH empno = 7839
CONNECT BY PRIOR empno = mgr
/
Path
-----------------------------
KING
/KING/JONES
/KING/JONES/SCOTT
/KING/JONES/SCOTT/ADAMS
/KING/JONES/FORD
/KING/JONES/FORD/SMITH
/KING/BLAKE
/KING/BLAKE/ALLEN
/KING/BLAKE/WARD
/KING/BLAKE/MARTIN
/KING/BLAKE/TURNER
/KING/BLAKE/JAMES
/KING/CLARK
/KING/CLARK/MILLER
ORDER SIBLINGS BY
The SIBLINGS keyword was introduced in Oracle9i. However, it makes sense to discuss it along with the enhancements in Oracle Database 10g. A hierarchical query with a “START WITH … CONNECT BY … PRIOR … “ construct displays the results in an arbitrary order, as shown in the following example:
column EmpName format a30
SELECT RPAD(' ',2*LEVEL,' ')||ename EmpName, empno, mgr
FROM emp
START WITH mgr IS NULL
CONNECT BY PRIOR empno = mgr
/
EMPNAME EMPNO MGR
------------------------------ ---------- ----------
KING 7839
JONES 7566 7839
SCOTT 7788 7566
ADAMS 7876 7788
FORD 7902 7566
SMITH 7369 7902
BLAKE 7698 7839
ALLEN 7499 7698
WARD 7521 7698
MARTIN 7654 7698
TURNER 7844 7698
JAMES 7900 7698
CLARK 7782 7839
MILLER 7934 7782
As always, you can use an ORDER BY clause to order the result rows in the way you want. However, in this case, an ORDER BY clause can destroy the hierarchical layers of the displayed data, as shown in the following example:
SELECT RPAD(' ',2*LEVEL,' ')||ename EmpName, empno, mgr
FROM emp
START WITH mgr IS NULL
CONNECT BY PRIOR empno = mgr
ORDER BY ename
/
EMPNAME EMPNO MGR
--------------- ---------- ----------
ADAMS 7876 7788
ALLEN 7499 7698
BLAKE 7698 7839
CLARK 7782 7839
FORD 7902 7566
JAMES 7900 7698
JONES 7566 7839
KING 7839
MARTIN 7654 7698
MILLER 7934 7782
SCOTT 7788 7566
SMITH 7369 7902
TURNER 7844 7698
WARD 7521 7698
As you can see from the above output, it is impossible to identify the hierarchical relationship between the rows. To resolve this problem, Oracle Database 10g has introduced a new keyword SIBLINGS, that you can use in an ORDER BY clause, and order the result set properly.
SELECT RPAD(' ',2*LEVEL,' ')||ename EmpName, empno, mgr
FROM emp
START WITH mgr IS NULL
CONNECT BY PRIOR empno = mgr
ORDER SIBLINGS BY ename
/
EMPNAME EMPNO MGR
--------------- ---------- ----------
KING 7839
BLAKE 7698 7839
ALLEN 7499 7698
JAMES 7900 7698
MARTIN 7654 7698
TURNER 7844 7698
WARD 7521 7698
CLARK 7782 7839
MILLER 7934 7782
JONES 7566 7839
FORD 7902 7566
SMITH 7369 7902
SCOTT 7788 7566
ADAMS 7876 7788
In the above output, BLAKE, CLARK and JONES are siblings, and they are displayed in the ascending order. So are BLAKE’s children – ALLEN, JAMES, MARTIN, TURNER and WARD.
Conclusion
Oracle Database 10g enhances the already powerful hierarchical query features of the Oracle database. Among the new features are the easy ways to identify leafs and cycles in the data. The ordering of siblings provides a great way to improve the readability of the result sets. Developers who are familiar with Oracle’s hierarchical query constructs will find these features very useful.
The Secrets of ROWNUM in Oracle
Overview
The pseudocolumn ROWNUM is available since Oracle versions 7 and it often leads to wrong results in combination with ORDER BY. For each row returned by a query, the ROWNUM pseudocolumn returns a number indicating the order in which Oracle selects the row from a table or set of joined rows. The first row selected has a ROWNUM of 1, the second has 2, and so on.
You can use the ROWNUM pseudocolumn to limit the number of rows returned by a query to 5:
SELECT Empno, Ename, Job, Mgr, Hiredate, Sal
FROM Emp
WHERE ROWNUM < 6;
EMPNO ENAME JOB MGR HIREDATE SAL
---------- -------- --------- ------- --------- ----------
7369 SMITH CLERK 7902 17-DEC-80 800
7499 ALLEN SALESMAN 7698 20-FEB-81 1600
7521 WARD SALESMAN 7698 22-FEB-81 1250
7566 JONES MANAGER 7839 02-APR-81 2975
7654 MARTIN SALESMAN 7698 28-SEP-81 1250
ORDER BY and ROWNUM - Wrong Result!
If an ORDER BY clause follows ROWNUM in the same query, the rows will be reordered by the ORDER BY clause.
SELECT Empno, Ename, Job, Mgr, Hiredate, Sal
FROM Emp
WHERE ROWNUM < 6
ORDER BY Sal;
EMPNO ENAME JOB MGR HIREDATE SAL
---------- -------- --------- ------- --------- ----------
7369 SMITH CLERK 7902 17-DEC-80 800
7521 WARD SALESMAN 7698 22-FEB-81 1250
7654 MARTIN SALESMAN 7698 28-SEP-81 1250
7499 ALLEN SALESMAN 7698 20-FEB-81 1600
7566 JONES MANAGER 7839 02-APR-81 2975
Use Inline Views - Correct Result!
Hups - Because the ROWNUM is assigned upon retrieval, it is assigned prior to any sorting! This is opposite to the result you would get in SQL Server using the TOP clause. In order to select employees with the highest five salaries, you have to force sorting and then apply ROWNUM condition. Here is the syntax for a top-N query where N = 5.
SELECT Empno, Ename, Job, Mgr, Hiredate, Sal
FROM
(SELECT Empno, Ename, Job, Mgr, Hiredate, Sal
FROM Emp
ORDER BY NVL(Sal, 0) DESC)
WHERE ROWNUM < 6;
EMPNO ENAME JOB MGR HIREDATE SAL
---------- -------- --------- ------- --------- ----------
7839 KING PRESIDENT 17-NOV-81 5000
7788 SCOTT ANALYST 7566 09-DEC-82 3000
7902 FORD ANALYST 7566 03-DEC-81 3000
7566 JONES MANAGER 7839 02-APR-81 2975
7698 BLAKE MANAGER 7839 01-MAY-81 2850
We used the NVL() function to sort the expression because sorting just by Emp_Salary would have put all records with NULL salary before those with the highest salaries, and that's not what we wanted to achieve.
ROWNUM instead of Subquery
Sometimes it is worth to rewrite a query to get a better performance - one such example shows the power of ROWNUM, to eliminate a subquery. Create the following table and fill it with some random data.
CREATE TABLE bigtable (
id NUMBER,
weight NUMBER,
adate DATE
);
INSERT INTO bigtable (id, weight, adate)
SELECT MOD(ROWNUM,1000),
DBMS_RANDOM.RANDOM,
SYSDATE-1000+DBMS_RANDOM.VALUE(0,1000)
FROM all_objects
/
Now look at the following query, which uses a subquery
SELECT MAX (weight) weight
FROM bigtable
WHERE id = 345
AND adate = (SELECT MAX (adate)
FROM bigtable
WHERE id = 345);
WEIGHT
----------
1650589959
The same result can be accomplish using ROWNUM and an inline view.
SELECT weight FROM (SELECT weight
FROM bigtable
WHERE id = 345
ORDER BY id DESC,
adate DESC,
weight DESC)
WHERE ROWNUM = 1;
WEIGHT
----------
1650589959
Conclusion
The inline view is a construct in Oracle SQL where you can place a query in the SQL FROM, clause, just as if the query was a table name. A common use for in-line views in Oracle SQL is to simplify complex queries by removing join operations and condensing several separate queries into a single query.
The ROWNUM pseudocolumn returns a number indicating the order in which Oracle selects the row from a table or set of joined rows.
The combination of ROWNUM and inline views is often a solution for an alternative way to perform a query.
The Secrets of Inline Views in Oracle
Overview
The inline view is a construct in Oracle SQL where you can place a query in the SQL FROM clause, just as if the query was a table name.
A common use for in-line views in Oracle SQL is to simplify complex queries by removing join operations and condensing several separate queries into a single query.
In ANSI standard SQL, it is quite difficult to compare two result sets that are summed together in a single query, and this is a common problem with Oracle SQL where specific values must be compared to a summary. Without the use of an in-line view, several separate SQL queries would need to be written, one to compute the sums from each view and another to compare the intermediate result sets.
Inline Views
As an example of an in-line view look at the following SELECT statement to show the amount of free space and used space within all Oracle tablespaces. Let’s take a close look at this SQL to see how it works. Carefully note that the FROM clause in this SQL query specifies two sub-queries that perform summations and grouping from two standard views, DBA_DATA_FILES, and DBA_FREE_SPACE.
COLUMN dummy NOPRINT
COLUMN pct_used FORMAT 999.9 HEADING "%|Used"
COLUMN name FORMAT a16 HEADING "Tablespace Name"
COLUMN total FORMAT 999,999,999 HEADING "Total"
COLUMN used FORMAT 999,999,999 HEADING "Used"
COLUMN free FORMAT 999,999,999 HEADING "Free"
COLUMN largest FORMAT 999,999,999 HEADING "Largest"
BREAK ON report
COMPUTE sum OF total ON REPORT
COMPUTE sum OF free ON REPORT
COMPUTE sum OF used ON REPORT
SELECT
NVL(b.tablespace_name,nvl(a.tablespace_name,'UNKOWN')) name,
kbytes_alloc total,
kbytes_alloc-NVL(kbytes_free,0) used,
NVL(kbytes_free,0) free,
((kbytes_alloc-NVL(kbytes_free,0))/kbytes_alloc)*100 pct_used
FROM ( SELECT SUM(bytes)/1024 Kbytes_free,
tablespace_name
FROM sys.dba_free_space
GROUP BY tablespace_name
) a,
( SELECT SUM(bytes)/1024 Kbytes_alloc,
tablespace_name
FROM sys.dba_data_files
GROUP BY tablespace_name
) b
WHERE a.tablespace_name (+) = b.tablespace_name
/
%
Tablespace Name Total Used Free Used
---------------- ------------ ------------ ------------ ------
IDX 819,264 1,600 817,664 .2
SYSAUX 819,200 243,648 575,552 29.7
SYSTEM 819,200 191,808 627,392 23.4
TAB 819,264 14,400 804,864 1.8
UNDO 204,800 8,896 195,904 4.3
USERS 10,304 3,136 7,168 30.4
------------ ------------ ------------
sum 3,492,032 463,488 3,028,544
The statement compares the sum of the total space within each tablespace to the sum of the free space within each tablespace. Note, that the summation is done in the Inline View.
Remote Administration with SYSDBA Privileges
Overview
If you're in an environment where you want to manage all of your Oracle databases from one place and not have to log on to each host, you must do it via a network connection. For example to remotely administer RMAN through a network connection, you need such an environment.
Enable remote Administration
You have to to two things
-
Create a password file on each target database.
-
Enable remote logins for password file users.
To create the password file, as the Oracle software owner or as a member of the DBA group:
$ orapwd file=sidname password=password entries=n
There are three user-provided variables in this example:
-
sidname: The SID of the target instance
-
password: The password to be used when you connect a user SYS with SYSDBA privilege.
-
n: The maximum number of schemas allowed in the password files.
For example, say that you have an instance named AKI1, that you want the password to be goofi, and that you want at the most 30 entries in the password file. Logon to the remote database machine an enter:
$ cd $ORACLE_HOME/dbs
$ orapwd file=orapwAKI1 password=goofi entries=30
The resulting password file is named orapwAKI1 and is in the $ORACLE_HOME/dbs directory.
After you create a password file, you need to enable remote logins. To do this, set the instance's REMOTE_LOGIN_PASSWORDFILE initialization parameter in INIT.ORA to exclusive, as shown:
remote_login_passwordfile = exclusive
Setting this parameter to exclusive signifies that only one database can use the password file and that users other than sys and internal can reside in it. You can now use a network connection to connect to your target database as SYSDBA.
Test the connection, try to connect from a PC to the remote database as SYS with SYSDBA privileges:
$ sqlplus "sys/goofi@AKI1 as sysdba"
Date/Time from Substraction of Two Date Values
Overview
If you substract two Date Values in Oracle, then the returning the result is in Days (such as 2.23456). However you would the Result in Days, Hours, Minutes and Seconds. Why not ask the Oracle Database to do that with Oracle Precision and speed.
Example
We will use a leap year date, 01/01/2000 for example, for temporary purposes. This date will provide accurate calculation for most cases.
First, substract the two Dates:
SELECT TO_DATE('10/29/04-23:28:30','MM/DD/YY-HH24:MI:SS') -
TO_DATE('10/29/04-20:52:04','MM/DD/YY-HH24:MI:SS')
DateDiff
FROM dual;
DATEDIFF
----------
.108634259
Now convert it to Years, Months, Days, Hours, Minutes and Seconds using the following Statement:
DEFINE DateDay = .108634259
SELECT
TO_NUMBER(SUBSTR(A,1,4)) - 2000 years,
TO_NUMBER(SUBSTR(A,6,2)) - 01 months,
TO_NUMBER(SUBSTR(A,9,2)) - 01 days,
SUBSTR(A,12,2) hours,
SUBSTR(A,15,2) minutes,
SUBSTR(A,18,2) seconds
FROM (SELECT TO_CHAR(TO_DATE('20000101','YYYYMMDD')
+ &DateDay,'YYYY MM DD HH24:MI:SS') A
FROM DUAL);
YEARS MONTHS DAYS HO MI SE
---------- ---------- ---------- -- -- --
0 0 0 02 36 26
The Result of .108634259 Days is: 2 Hours, 36 Minutes and 26 Seconds.
Encrypting a Column in a Table
Overview
For applications dealing with highly sensitive data, Oracle provides the DBMS_OBFUSCATION_TOOLKIT PL/SQL package to encrypt and decrypt data, including string inputs and raw inputs. The function is limited to selected algorithms, such as the Data Encryption Standard (DES). Developers may not plug in their own encryption algorithms, and the key length is also fixed. The function prohibits making multiple passes of encryption; that is, you cannot nest encryption calls, thereby encrypting an encrypted value. These restrictions are required by U.S. laws governing the export of cryptographic products.
Another solution to encrypt strings, for example passwords you can store them HASHED or DIGESTED. For example, in Oracle, the password is not encrypted (that would imply there is a decrypt but there is not). For example, to validate a username/password we take them, plus some magic "salt" and hash it. This results in a fixed length string of some bytes of data. We compare that to the stored hash and if they match -- you are in, if not -- you are not.
Computes a Hash Value for the given String
So, to write a password check function, one would simply glue the USERNAME together with the supplied PASSWORD. You would call DBMS_UTILITY.GET_HASH_VALUE to generate some hashes.
This function computes a hash value for the given string.
DBMS_UTILITY.GET_HASH_VALUE (
name VARCHAR2,
base NUMBER,
hash_size NUMBER)
RETURN NUMBER;
Parameters:
| name |
String to be hashed |
| base |
Base value for the returned hash value to start at |
| hash_size |
Desired size of the hash table |
Returns:
A hash value based on the input string. For example, to get a hash value on a string where the hash value should be between 1000 and 3047, use 1000 as the base value and 2048 as the hash_size value. Using a power of 2 for the hash_size parameter works best.
Here is the digest Function
CREATE OR REPLACE FUNCTION digest (p_username IN VARCHAR2,
p_password IN VARCHAR2)
RETURN VARCHAR2 IS
BEGIN
RETURN
LTRIM (
TO_CHAR (
DBMS_UTILITY.GET_HASH_VALUE (
UPPER(p_username)||'/'||UPPER(p_password),
1000000000,
POWER(2,30)
),
RPAD('X',29,'X')||'X'
)
);
END digest;
/
SQL> EXECUTE DBMS_OUTPUT.PUT_LINE(digest('SCOTT','TIGER'));
4307767C
The function digest takes a username and password, hashes it into 1 of 1073741824 different numeric values, adds 1000000000 to it (to make it big) and turns it into HEX. This is what we would store in the database -- not the password (which we really don't ever need to know). Now when the user presents a username/password, we digest it and compare -- if they match, you get in, if not you do not.
Customize the SQL*Plus Environment
Author of this Tip: Thomas Kyte
Overview
The setup for SQL*Plus is amazingly easy. In fact, it should already be done. Every client softwareinstallation has it, and every server installation has it too. On windows, there are two versions of SQL*Plus: a GUI one (the sqlplusw.exe program) and a character based one (the sqlplus.exeprogram). The character-mode SQL*Plus is 100% compatible with SQL*Plus on every other platform on which Oracle is delivered. The GUI SQL*Plus, which offers no real functional benefit over the character mode - after all, it is a character-mode tool running in a window - is different enough to be confusing and isn't flexible as the command-line version. Additionally, it is already officially deprecated in the next release of Oracle, so it won't be around for long.
Store Settings for SQL*PLUS (login.sql and glogin.sql)
Whenever SQL*PLUS starts up, it looks for a file named glogin.sql under the directory$ORACLE_HOME/sqlplus/admin. If such a file is found, it is read and the containing statements executed. This allows to store settings (such as linesize) accross SQL*PLUS sessions. New in Oracle 10g: Oracle also reads glogin.sql and login.sql at a connect in sql*plus.
Additionally, after reading glogin.sql, sql*plus also looks for a file named login.sql in the directory from where SQL*PLUS was started and in the directory that the environment variable SQLPATH points to and reads it and executes it. Settings from the login.sql take precedence over settings fromglogin.sql.
A common login.sql file
REM turn off the terminal output - make it so SQLPlus does not
REM print out anything when we log in
set termout off
REM default your editor here. SQLPlus has many
REM individual settings.
REM This is one of the most important ones
define _editor=vi
REM serveroutput controls whether your DBMS_OUTPUT.PUT_LINE calls
REM go into the bit bucket (serveroutput off) or get displayed
REM on screen. I always want serveroutput set on and as big
REM as possible - this does that. The format wrapped elements
REM causes SQLPlus to preserve leading whitespace - very useful
set serveroutput on size 1000000 format wrapped
REM Here I set some default column widths for commonly queried
REM columns - columns I find myself setting frequently,
REM day after day
column object_name format a30
column segment_name format a30
column file_name format a40
column name format a30
column file_name format a30
column what format a30 word_wrapped
column plan_plus_exp format a100
REM by default, a spool file is a fixed width file with lots of
REM trailing blanks. Trimspool removes these trailing blanks
REM making the spool file significantly smaller
set trimspool on
REM LONG controls how much of a LONG or CLOB sqlplus displays
REM by default. It defaults to 80 characters which in general
REM is far too small. I use the first 5000 characters by default
set long 5000
REM This sets the default width at which sqlplus wraps output.
REM I use a telnet client that can go upto 135 characters wide -
REM hence this is my preferred setting.
set linesize 135
REM SQLplus will print column headings every N lines of output
REM this defaults to 14 lines. I find that they just clutter my
REM screen so this setting effectively disables them for all
REM intents and purposes - except for the first page of course
set pagesize 9999
REM here is how I set my signature prompt in sqlplus to
REM username@database> I use the NEW_VALUE concept to format
REM a nice prompt string that defaults to IDLE (useful for those
REM of you that use sqlplus to startup their databases - the
REM prompt will default to idle> if your database isn't started)
define gname=idle
column global_name new_value gname
select lower(user) || '@' ||
substr( global_name, 1, decode( dot,
0, length(global_name),
dot-1) ) global_name
from (select global_name, instr(global_name,'.') dot
from global_name );
set sqlprompt '&gname> '
REM and lastly, we'll put termout back on so sqlplus prints
REM to the screen
set termout on
Converting Columns to Rows
Overview
Suppose you want to convert an Oracle table:
(id, sum1, sum2, sum3)
into another table:
(id, '1', sum1)
(id, '2', sum2)
(id, '3', sum3)
That means converting 1 row from the first table into 3 rows in the other table. Of course, this can be done by scanning the source table 3 times, one for each «sum» column, but if the first table is pretty large (~50 million rows), we need another, faster approach.
Solution
Using an Inline View with the UNION ALL operator, all can be done in one single step.
CREATE TABLE t1 (
id NUMBER PRIMARY KEY,
sum1 NUMBER,
sum2 NUMBER,
sum3 NUMBER
);
INSERT INTO t1 VALUES (1,20,40,50);
INSERT INTO t1 VALUES (2,30,20,25);
INSERT INTO t1 VALUES (3,15,60,55);
COMMIT;
select * from t1;
ID SUM1 SUM2 SUM3
---------- ---------- ---------- ----------
1 20 40 50
2 30 20 25
3 15 60 55
CREATE TABLE t2 AS
SELECT id, num, DECODE(num,'1',sum1,'2',sum2,'3',sum3) data
from t1, (SELECT '1' num FROM dual UNION ALL
SELECT '2' num FROM dual UNION ALL
SELECT '3' num FROM dual)
/
select * from t2 order by id;
ID N DATA
---------- - ----------
1 1 20
1 2 40
1 3 50
2 1 30
2 3 25
2 2 20
3 1 15
3 3 55
3 2 60
Counting negative and postive numbers
Overview
You have a result set with positive, negative and neutral values like this:
select * from result;
KEY VAL
---------- ----------
first -1.222
second -.03
third -.02
fourth 0
fifth 1.2
sixth .03
Now, you want to count how many negative, postitive and neutral values you have.
- 3 negative
- 1 no change
- 2 positive
Solution
Use the Oracle SIGN ( n ) function which returns -1 if n < 0. If n = 0, then the function returns 0. If n > 0, then SIGN returns 1.
create table result (
key varchar2(10),
val number
);
insert into result (key,val) values ('first',-1.222);
insert into result (key,val) values ('second',-.03);
insert into result (key,val) values ('third',-.02);
insert into result (key,val) values ('fourth',0);
insert into result (key,val) values ('fifth',1.2);
insert into result (key,val) values ('sixth',.03);
select count(decode(sign(val),-1,-1)) neg,
count(decode(sign(val),0,0)) zero,
count(decode(sign(val),1,1)) pos
from result;
NEG ZERO POS
---------- ---------- ----------
3 1 2
How to fix invalid Objects in Oracle Data Dictionary
You may notice, that you cannot install an additional Option (Spatial, InterMedia, etc) or you are not able to create the Enterprise Manager Repository. For example you get the following errors if you create the Repository with:
emca - config dbcontrol db -repos create
No errors.
No errors.
Warning: Package Body created with compilation errors.
No errors.
No errors.
.....
and later:
Recompile invalid objects...
ERROR:
ORA-24344: success with compilation error
ORA-06512: at line 38
Potential Solution
1. Clean up the failed respository creation
a. SQL> drop user sysman cascade;
b. SQL> drop role MGMT_USER;
c. SQL> drop user MGMT_VIEW cascade;
d. SQL> drop public synonym MGMT_TARGET_BLACKOUTS;
e. SQL> drop public synonym SETEMVIEWUSERCONTEXT;
2. Ensure that the execute permission has been granted
on the following packages:
SQL> grant execute on utl_smtp to public;
SQL> grant execute on utl_tcp to public;
SQL> grant execute on utl_file to public;
3. Run the catproc.sql script from ORACLE_HOME/rdbms/admin
SQL> @catproc.sql
3. Retry the emca utility or create the desired Option
emca -config dbcontrol db -repos create
Automated Checkpoint Tuning (MTTR)
Check-Pointing
Check-pointing is an important Oracle activity which records the highest system change number (SCN,) so that all data blocks less than or equal to the SCN are known to be written out to the data files. If there is a failure and then subsequent cache recovery, only the redo records containing changes at SCN(s) higher than the checkpoint need to be applied during recovery.
As we are aware, instance and crash recovery occur in two steps - cache recovery followed by transaction recovery. During the cache recovery phase, also known as the rolling forward stage, Oracle applies all committed and uncommitted changes in the redo log files to the affected data blocks. The work required for cache recovery processing is proportional to the rate of change to the database and the time between checkpoints.
Mean time to recover (MTTR)
Fast-start recovery can greatly reduce the mean time to recover (MTTR), with minimal effects on online application performance. Oracle continuously estimates the recovery time and automatically adjusts the check-pointing rate to meet the target recovery time.
With 10g, the Oracle database can now self-tune check-pointing to achieve good recovery times with low impact on normal throughput. You no longer have to set any checkpoint-related parameters.
This method reduces the time required for cache recovery and makes the recovery bounded and predictable by limiting the number of dirty buffers and the number of redo records generated between the most recent redo record and the last checkpoint. Administrators specify a target (bounded) time to complete the cache recovery phase of recovery with the FAST_START_MTTR_TARGET initialization parameter, and Oracle automatically varies the incremental checkpoint writes to meet that target.
The TARGET_MTTR field of V$INSTANCE_RECOVERY contains the MTTR target in effect. The ESTIMATED_MTTR field of V$INSTANCE_RECOVERY contains the estimated MTTR should a crash happen right away.
Example
SELECT TARGET_MTTR,
ESTIMATED_MTTR,
CKPT_BLOCK_WRITES
FROM V$INSTANCE_RECOVERY;
TARGET_MTTR ESTIMATED_MTTR CKPT_BLOCK_WRITES
----------- -------------- -----------------
214 12 269880
Whenever you set FAST_START_MTTR_TARGET to a nonzero value, then set the following parametersto 0.
LOG_CHECKPOINT_TIMEOUT = 0
LOG_CHECKPOINT_INTERVAL = 0
FAST_START_IO_TARGET = 0
Because these initialization parameters either override FAST_START_MTTR_TARGET or potentially drive checkpoints more aggressively than FAST_START_MTTR_TARGET does, they can interfere with the simulation.
Oracle Char Semantics and Globalization
Overview
Historically database columns which hold alphanumeric data have been defined using the number of bytes they store. This approach was fine as the number of bytes equated to the number of characters when using single-byte character sets. With the increasing use of multibyte character sets to support globalized databases comes the problem of bytes no longer equating to characters.
The VARCHAR2 datatype specifies a variable-length character string. When you create a VARCHAR2 column, you supply the maximum number of bytes or characters of data that it can hold.
Oracle subsequently stores each value in the column exactly as you specify it, provided the value does not exceed the column's maximum length of the column. If you try to insert a value that exceeds the specified length, then Oracle returns an ORA-12899 error.
A character is technically a code point of the database character set. CHAR and BYTE qualifiers override the setting of the NLS_LENGTH_SEMANTICS parameter, which has a default of bytes. The maximum length of VARCHAR2 data is 4000 bytes.
Current Setting of NLS_LENGTH_SEMANTICS
select * from nls_database_parameters;
NLS_LANGUAGE AMERICAN
NLS_TERRITORY AMERICA
NLS_CURRENCY $
NLS_ISO_CURRENCY AMERICA
NLS_NUMERIC_CHARACTERS .,
NLS_CHARACTERSET AL32UTF8
NLS_CALENDAR GREGORIAN
NLS_DATE_FORMAT DD-MON-RR
NLS_DATE_LANGUAGE AMERICAN
NLS_SORT BINARY
NLS_TIME_FORMAT HH.MI.SSXFF AM
NLS_TIMESTAMP_FORMAT DD-MON-RR HH.MI.SSXFF AM
NLS_TIME_TZ_FORMAT HH.MI.SSXFF AM TZR
NLS_TIMESTAMP_TZ_FORMAT DD-MON-RR HH.MI.SSXFF AM TZR
NLS_DUAL_CURRENCY $
NLS_COMP BINARY
NLS_LENGTH_SEMANTICS BYTE
NLS_NCHAR_CONV_EXCP FALSE
NLS_NCHAR_CHARACTERSET AL16UTF16
NLS_RDBMS_VERSION 10.2.0.3.0
Example
CREATE TABLE test (
t1 VARCHAR2(10 BYTE),
t2 VARCHAR2(10 CHAR),
t3 VARCHAR2(10)
);
DESC test;
Name Null? Type
---------------------------------------------------
T1 VARCHAR2(10)
T2 VARCHAR2(10 CHAR)
T3 VARCHAR2(10)
OK, we can see how the table was created.
INSERT INTO TEST (t1, t2) VALUES ('1234567890','äöüߧèáàâö');
INSERT INTO TEST (t1, t2) VALUES ('äää','ääääääääää');
COMMIT;
1 row created.
1 row created.
Commit complete.
INSERT INTO VARCHAR_TEST (t1) VALUES ('ääääää');
ERROR at line 1:
ORA-12899: value too large for column "TEST"."T1" (actual: 12, maximum: 10)
The default character semantics of the database or session can be altered using the NLS_LENGTH_SEMANTICS parameter.
alter system set nls_length_semantics=char;
alter session set nls_length_semantics=char;
The INSTR, LENGTH and SUBSTR functions always deal with characters, regardless of column definitions and the character sets. For times when you specifically need to deal in bytes Oracle provides the INSTRB, LENGTHB and SUBSTRB functions.
|