



Linux内核如何装载和启动一个可执行程序
实验七:Linux内核如何装载和启动一个可执行程序
姓名:李冬辉
学号:20133201
注: 原创作品转载请注明出处 + 《Linux内核分析》MOOC课程http://mooc.study.163.com/course/USTC-1000029000
云课堂笔记:
(1)可执行文件的创建
C代码(.c) - 经过编译器预处理,编译成汇编代码(.asm) - 汇编器,生成目标代码(.o) - 链接器,链接成可执行文件(.out) - OS将可执行文件加载到内存里执行。如图

1. 预处理
gcc -E -o hello.cpp hello.c -m32 预处理(文本文件)
预处理负责把include的文件包含进来及宏替换等工作
2. 编译
gcc -x cpp-output -S -o hello.s hello.cpp -m32 编译成汇编代码(文本文件)
3. 汇编
gcc -x assembler -c hello.s -o hello.o -m32 汇编成目标代码(ELF格式,二进制文件,有一些机器指令,只是还不能运行)
4. 链接
gcc -o hello hello.o -m32 链接成可执行文件(ELF格式,二进制文件)
在hello可执行文件里面使用了共享库,会调用printf,libc库里的函数
gcc -o hello.static hello.o -m32 -static 静态链接
把执行所需要依赖的东西都放在程序内部
(2)ELF三种主要的目标文件:
1.可重定位:保存代码和适当数据,用来和其他的object文件一起创建可执行/共享文件,主要是.o文件
2.可执行文件:指出了exec如何创建程序进程映像,怎么加载,从哪里开始执行
3.共享object文件:保存代码和适当数据,用来被下面的两个连接器链接。
(1)连接editor,连接可重定位、共享object文件。即装载时链接。
(2)动态链接器,联合可执行、其他共享object文件创建进程映像。即运行时链接。
(3)可执行程序的执行环境
-
命令行参数和shell环境,一般我们执行一个程序的Shell环境,我们的实验直接使用execve系统调用。
-
$ ls -l /usr/bin 列出/usr/bin下的目录信息
-
Shell本身不限制命令行参数的个数, 命令行参数的个数受限于命令自身
-
例如,int main(int argc, char *argv[])
-
又如, int main(int argc, char *argv[], char *envp[])
-
Shell会调用execve将命令行参数和环境参数传递给可执行程序的main函数
-
int execve(const char * filename,char * const argv[ ],char * const envp[ ]);
-
库函数exec*都是execve的封装例程
命令行参数和环境串都放在用户态堆栈中

(4)可执行程序的装载
-
命令行参数和shell环境,一般我们执行一个程序的Shell环境,我们的实验直接使用execve系统调用。
-
Shell本身不限制命令行参数的个数, 命令行参数的个数受限于命令自身
-
例如,int main(int argc, char *argv[])
-
又如, int main(int argc, char *argv[], char *envp[])
-
Shell会调用execve将命令行参数和环境参数传递给可执行程序的main函数
-
int execve(const char * filename,char * const argv[ ],char * const envp[ ]);
-
库函数exec*都是execve的封装例程
-
sys_execve内部会解析可执行文件格式
-
do_execve -> do_execve_common -> exec_binprm -
search_binary_handler符合寻找文件格式对应的解析模块,如下:

实验步骤:
1、先把menu删掉,在克隆一个,用test_exec.c覆盖掉test.c。
2、打开test.c。发现增加了一句MenuConfig。
3、打开Makefile,首先静态编译了hello.c,生成根文件系统时把init和hello都放入rootfs image里面,这样执行exec的时候就自动的帮我们加载hello这个文件。
4、执行结果hello world! 是新加载的一个可执行程序输出的。
5、-S -s单步调试,窗口被冻结。
6、设置三个断点:sys_execve,load_elf_binary,start_thread。
7、list列出来跟踪, 输入s可以进入do_execve的内部。按c继续执行,跑到load_elf_binary。list查看代码,输入n一句一句跟踪,nnnc,追踪到start_thread。
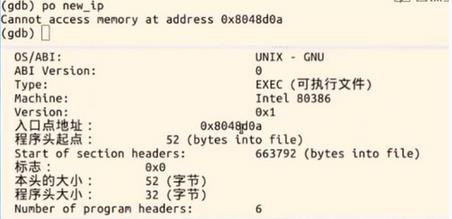
8、观察hello这个可执行程序的入口,发现也是0x8048d0a,和new_ip的位置一样。new_ip是返回到用户态第一条指令的地址。
9、将new_ip和new_sp赋值,并设了一个新堆栈。
实验截图:




Linux系统加载可执行程序所需处理过程的理解
1. 新的可执行程序是从哪里开始执行的?
当execve()系统调用终止且进程重新恢复它在用户态执行时,执行上下文被大幅度改变,要执行的新程序已被映射到进程空间,从elf头中的程序入口点开始执行新程序。
如果这个新程序是静态链接的,那么这个程序就可以独立运行,elf头中的这个入口地址就是本程序的入口地址。
如果这个新程序是动态链接的,那么此时还需要装载共享库,elf头中的这个入口地址是动态链接器ld的入口地址。
2 .为什么execve系统调用返回后新的可执行程序能顺利执行?
新的可执行程序执行,需要以下:
1. 它所需要的库函数。
2. 属于它的进程空间:代码段,数据段,内核栈,用户栈等。
3. 它所需要的运行参数。
4. 它所需要的系统资源。
如果满足以上4个条件,那么新的可执行程序就会处于可运行态,只要被调度到,就可以正常执行。我们一个一个看这几个条件能不能满足。
条件1:如果新进程是静态链接的,那么库函数已经在可执行程序文件中,条件满足。如果是动态链接的,新进程的入口地址是动态链接器ld的起始地址,可以完成对所需库函数的加载,也能满足条件。
条件2:execve系统调用通过大幅度修改执行上下文,将用户态堆栈清空,将老进程的进程空间替换为新进程的进程空间,新进程从老进程那里继承了所需要的进程空间,条件满足。
条件3:我们一般在shell中,输入可执行程序所需要的参数,shell程序把这些参数用函数参数传递的方式传给给execve系统调用,然后execve系统调用以系统调用参数传递的方式传给sys_execve,最后sys_execve在初始化新程序的用户态堆栈时,将这些参数放在main函数取参数的位置上。条件满足。
条件4:如果当前系统中没有所需要的资源,那么新进程会被挂起,直到资源有了,唤醒新进程,变为可运行态,条件可以满足。
综上所述,新的可执行程序可以顺利执行。
3. 对于静态链接的可执行程序和动态链接的可执行程序execve系统调用返回时会有什么不同?
execve系统调用会调用sys_execve,然后sys_execve调用do_execve,然后do_execve调用do_execve_common,然后do_execve_common调用exec_binprm,在exec_binprm中:

对于ELF文件格式,fmt函数指针实际会执行load_elf_binary,load_elf_binary会调用start_thread,在start_thread中通过修改内核堆栈中EIP的值,使其指向elf_entry,跳转到elf_entry执行。
对于静态链接的可执行程序,elf_entry是新程序的执行起点。对于动态链接的可执行程序,需要先加载链接器ld,
elf_entry = load_elf_interp(…)
将CPU控制权交给ld来加载依赖库,再由ld在完成加载工作后将CPU控制权还给新进程。
总结:
可执行文件是一个普通的文件,它描述了如何初始化一个新的执行上下文,也就是如何开始一个新的计算。可执行文件类别有很多,在内核中有一个链表,在init的时候会将支持的可执行程序解析程序注册添加到链表中,那么在对可执行文件进行解析时,就从链表头开始找,找到匹配的处理函数就可以对其进行解析。
在shell中启动一个可执行程序时,会创建一个新进程,它通过覆盖父进程(也就是shell进程)的进程环境,并将用户态堆栈清空,获得需要的执行上下文环境。
命令行参数和环境变量会通过shell传递给execve,excve通过系统调用参数传递,传递给sys_execve,最后sys_execve在初始化新进程堆栈的时候拷贝进去。
load_elf_binary->start_thread(…)通过修改内核堆栈中EIP的值作为新程序的起点。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号