
[JavaScript忍者系列] — CSS选择符引擎入门
本文的目标读者是入门级Web前端开发人员。
本文介绍了CSS选择符表达式引擎的基本原理。CSS选择符引擎几乎是前端开发人员每天在使用的工具。本文将逐一介绍实现该引擎的各种策略。首先,我们介绍基于W3C标准API的方法。
W3C标准的Slectors API
能够支持的平台: Safari 3+, Firefox 3.1+, Internet Explorer 8+, Chrome and Opera 10+
两个最常用的方法:
querySelector,该函数接受一个CSS选择符字符串,返回找到的第一个元素,如果没有找到则返回null。
querySelectorAll,该函数接受一个CSS选择符字符串,返回找到的所有元素的集合(NodeList)。
这两个方法存在于所有的DOM元素,DOM文档对象,以及DOM文档片段(fragment)对象上。
<div id="test"> <b>Hello</b>, I'm a ninja! </div> <div id="test2"></div>
<script> window.onload = function () { var divs = document.querySelectorAll("body > div"); assert(divs.length === 2, "Two divs found using a CSS selector."); var b = document.getElementById("test") .querySelector("b:only-child"); assert(b, "The bold element was found relative to another element."); }; </script>
上述例子的一个缺点是它依赖于浏览器对CSS选择符的支持(老版本IE就歇菜了),因此可以考虑使用以某元素作为根节点对子节点的查询。代码如下。
<script> window.onload = function () { var b = document.getElementById("test").querySelector("div b"); assert(b, "Only the last part of the selector matters."); }; </script>
上述代码有个问题,当以某元素作为根节点对子节点的查询时,query函数只检查最右边的部分是不是包含在父节点里。注意到#test下面压根就没有div标签,可是query函数忽略了查询字符串的前面部分。
这个现象确实有悖于我们期望的CSS选择符引擎的运行效果,所以我们需要做一些修补工作。最常见的技巧是:临时增加一个新id给那个根节点元素从而强行地包含它里面的内容。代码如下。
<script> (function () { var count = 1; this.rootedQuerySelectorAll = function (elem, query) { var oldID = elem.id; elem.id = "rooted" + (count++); try { return elem.querySelectorAll("#" + elem.id + " " + query); } catch (e) { throw e; } finally { elem.id = oldID; } }; })(); window.onload = function () { var b = rootedQuerySelectorAll( document.getElementById("test"), "div b"); assert(b.length === 0, "The selector is now rooted properly."); }; </script>
在上述代码中我们需要注意到以下几点:
首先,要给父元素一个全局唯一的id,因此需要保存父元素原始的id。然后把这个全局唯一的id添加到查询字符串中。
接着的收尾部分就是去除新增加的那个id和返回查询结果,这个过程中可能会有一个API异常抛出(多数情况是因为选择符语法错误或者是浏览器不支持的选择符)。因此,我们要在外层用try/catch语句块包住API调用语句,还要在finnally的子句中还原父元素的原始id。你可能会发现,这里隐藏着JavaScript语言神奇的一个地方,就是虽然我们在try语句里已经return了,可是finnally子句还是要被执行的(在结果值被真正return给调用函数前)。
选择器API绝对可以算作W3C标准里最具前途的新API了。一旦主流浏览器支持CSS3(或至少绝大部分CSS3选择符)以后,它可以节省编程人员使用大量的JavaScript代码。
使用 XPath 寻找元素
XPath是一种可以在DOM文档中查询节点的语言。它甚至比CSS选择符更加强大。许多流行的浏览器 (Firefox,Safari 3+, Opera 9+, Chrome)都提供了对XPath的部分函数实现,可以在HTML文档中查找元素。 Internet Explorer 6及之前的版本只能使用XPath查找XML文档(而不是HTML文档)。
Xpath表达式比复杂的CSS选择符执行快。但是,当我们实现一个纯DOM操作方式的CSS选择符引擎时,我们要考虑浏览器支持性的风险。在对于简单的CSS选择符,Xpath就失去优越性了。
因此我们考虑使用一个阈值,当使用Xpath更有利的情况下我们就是用Xpath。决定阈值依赖于开发人员的经验,比如:当查找id或者标签时,使用纯DOM操作代码永远是更快的方式。
如果用户浏览器支持Xpath表达式,我们可以使用下述代码(依赖于prototype库)。
if (typeof document.evaluate === "function") { function getElementsByXPath(expression, parentElement) { var results = []; var query = document.evaluate(expression, parentElement || document, null, XPathResult.ORDERED_NODE_SNAPSHOT_TYPE, null); for (var i = 0, length = query.snapshotLength; i < length; i++) results.push(query.snapshotItem(i)); return results; } }
虽然使用Xpath可以解决任何选择符问题,但它不是一个可行的方案。对于一个的CSS选择符表达式,对应的Xpath的表达式却是令人生畏的复杂。 下面这个表格展示了如何把CSS选择符转换到Xpath表达式。
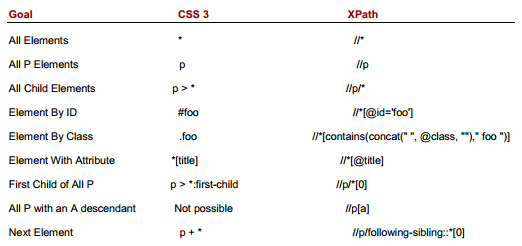
当建造一个基于正则表达式的CSS选择符引擎时,我们可以包含Xpath的方式作为一个子模块,它把用户查询的CSS选择符表达式部分转换成Xpath的表达式,然后使用Xpath的办法查找DOM。
实现XPath的部分的代码可能与正则表达式方式的代码一样多。很多开发人员选择抛弃XPath的部分来减少CSS选择符引擎的复杂程度。所以,你需要衡量Xpath带来的的性能提升以及它的代码实现复杂程度。
纯DOM实现方式
CSS选择符引擎的核心是以纯DOM操作方式实现的。它解析用户给出的CSS选择符,然后使用已有的DOM方法(例如getElementById, getElementsByTagName)来查找对应的DOM元素。使用纯DOM方式实现有以下理由:
第一,Internet Explorer 6 and 7。尽管IE8以上的版本支持querySelectorAll()方法,但是在IE6、7中对Xpath和选择符API的支持使得使用纯DOM实现很有必要。
第二,向下兼容,如果你希望你的代码能够“降级”支持老版本的浏览器(比如Safari 2),那么你应该使用纯DOM实现。
第三,为了速度。对于某些CSS选择符表达式,使用纯DOM核心能够处理得更快(比如根据id找元素)。
知道了使用纯DOM核心的重要性,接下来我们要看以两种方式实现选择符引擎:从上往下解析,和从下往上解析。
一个从上往下的引擎是这样解析CSS选择符表达式的:从左往右的匹配元素,在前部分的基础上再接着找下部分匹配的元素。 这种方式是目前主流JavaScript库的实现方式,更通用地,也是寻找页面元素的最佳方式。 让我们来看一段标记
<body> <div></div> <div class="ninja"> <span>Please </span> <a href="/ninja"><span>Click me!</span> </a> </div> </body>
如果我们想选"Click me!"那个元素,我们可以这样写 选择符表达式 : div.ninja a span 。
使用从上往下的方法是这样解析这个选择符表达式的:
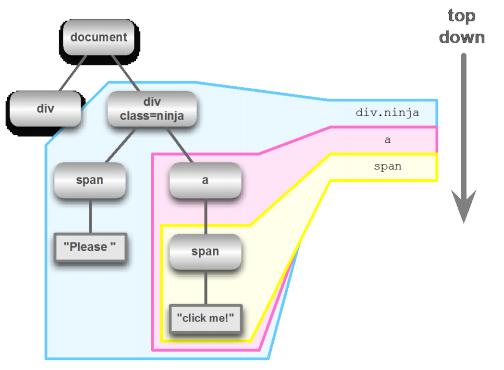
表达式中的第一项,div.ninja 指明了文档中的一颗子树。在那颗子树中,接着找表达式中下一项对应的子树。最后,span的目标节点被找到。
注意,这只是最简单的情况。在任何层的推进过程中,完全有可能有多颗子树同时匹配表达式。在实现选择符引擎的时候,有两个原则需要考虑:
返回的结果中元素的顺序应该按照在文档中原本的顺序出现
返回的结果中的元素不应该有重复的(比如不能一个元素在结果中出现两次)
为了避免这些陷阱,具体的代码实现可能会有一点小技巧。下面是一个简化的top-down方式引擎,它只能够支持按照tag标签名字查找元素。
<div>
<div> <span>Span</span>
</div>
</div>
<script>
window.onload = function () {
function find(selector, root) {
root = root || document;
var parts = selector.split(" "),
query = parts[0],
rest = parts.slice(1).join(" "),
elems = root.getElementsByTagName(query),
results = [];
for (var i = 0; i < elems.length; i++) {
if (rest) {
results = results.concat(find(rest, elems[i]));
} else {
results.push(elems[i]);
}
}
return results;
}
var divs = find("div");
assert(divs.length === 2, "Correct number of divs found.");
var divs = find("div", document.body);
assert(divs.length === 2,
"Correct number of divs found in body.");
var divs = find("body div");
assert(divs.length === 2,
"Correct number of divs found in body.");
var spans = find("div span");
assert(spans.length === 2, "A duplicate span was found.");
};
</script>
在上面的例子中,我们实现了一个简单的支持按照tag标签名字查找元素的从上往下解析方式的选择符引擎。 这个引擎可以分解为几个子部分:解析选择符表达式,在文档中查找元素,过滤元素,递归/合并每一层里的结果。
解析选择符表达式
在上面的例子中,解析过程就是把CSS选择符(例如"div span")分解成字符串数组(["div", "span"])。实际上,在CSS2和CSS3的标准中,使用属性值查找元素是被支持的。因此在选择符中完全有可能有额外的空格,使得上面简单的方法不可行了。但是,这种简单的方法对于处理大部分的情况已经足够了。
要完全实现解析,我们需要一系列的解析规则来处理用户给出的任何表达式。 下面的代码就是使用正则表达式把表达式分解成各个小块(如果需要,则分开逗号)
<script type="text/javascript">
var selector = "div.class > span:not(:first-child) a[href]"
var chunker = /((?:\([^\)]+\)|\[[^\]]+\]|[^ ,\(\[]+)+)(\s*,\s*)?/g;
var parts = [];
// Reset the position of the chunker regexp (start from beginning)
chunker.lastIndex = 0;
// Collect the pieces
while ((m = chunker.exec(selector)) !== null) {
parts.push(m[1]);
// Stop if we've countered a comma
if (m[2]) {
extra = RegExp.rightContext;
break;
}
}
assert(parts.length == 4,
"Our selector is broken into 4 unique parts.");
assert(parts[0] === "div.class", "div selector");
assert(parts[1] === ">", "child selector");
assert(parts[2] === "span:not(:first-child)", "span selector");
assert(parts[3] === "a[href]", "a selector");
</script>
显然,这段代码支持的选择符只是一张大拼图中的一小部分。我们需要定义更多的解析规则来支持用户输入的各种表达式组合。绝大多数CSS选择符引擎使用了map结构,来将正则表达式对应到目标处理函数。这样当一个正则表达式匹配用户表达式的一部分时,对应的函数就去处理那一部分表达式的选择符。
寻找元素
在页面中寻找正确的DOM元素有许多种解决方案。使用哪种方案取决于浏览器支持什么样的选择符。
首先是 getElementById() 方法。它只在HTML文档的根节点上存在。它的作用是找到第一个匹配指定id值的元素,因此他可以用来解决 "#id" 这样的表达式。注意,在Internet Explorer 和 Opera,它同样也会查找第一个具有同名 name值的元素。 因此,如果需要值按照 id 值查找,我们需要额外的一步验证工作来排除掉 name值同名的元素。
如果需要支持寻找所有具有给定 id值的元素(这在CSS选择符表达式中是习惯性用法,尽管HTML文法规定一个id只能对应一个元素),有两种方法可以采用:第一种方法,遍历所有的元素,找出所有匹配给定 id值的元素;第二种方法,使用 document.all["id"] ,它将返回一个包含匹配id值元素的数组。
接下来是 getElementsByTagName() 方法,它的作用就如同它的名字所述:找出所有匹配给定标签名的元素。 注意,它还有另一种用法:如果使用 星号* 作为参数标签名,那么它会返回文档中或者一个节点下所有的元素。 这一招对于 处理基于属性值的选择符 很有用,比如 ".class" 或者 "[attr]"。 因为 ".class" 并没有指定标签名,所以我们需要列出某节点下的所有子元素,然后依次判断class名称。
另外,在Internet Explorer中使用 星号* 查找有一个缺点,它同样会返回 注释语句 节点(因为在IE中,注释语句节点有一个 "!" 的标签名,所以它也会被返回)。 这样,我们需要额外的一步过滤工作来排除注释语句节点。
接下来是 getElementsByName() 方法,它的作用只有一个: 找出所有匹配给定 name值的节点(例如,<input> 元素都具有name值 )。因此这个方法可以用来解决 "[name=name]" 这样的表达式。
最后是 getElementsByClassName() 方法。这个方法相对比较新,正在被各主流浏览器实现(Firefox 3+, Safari 3+ 和 Chrome)。它的作用是基于 元素的class名称 进行查找。 这种浏览器原生的方法极大地加快了 按class名称查找 的代码实现。
尽管还有一些其他技巧用来解决元素查找,以上那些方法依然是我们主要使用的工具。一旦找出了所有匹配的备选元素后,接下来就进行元素过滤了。
过滤元素
一个CSS表达式通常是由几个独立的小部分组成的。例如,这样一个表达式 "div.class[id]" 就由三个部分组成: 1. div元素 2. 具有给定的class名称 3. 具有一个名叫id的属性值。
首先我们需要找出选择符的第一部分。例如,在上述表达式中,我们看到第一部分是找div元素,所以我们立刻想到用 getElementsByTagName() 方法找出页面上所有的 <div> 元素。 接下来,我们必须过滤元素,使得剩下的元素具有给定的class名称和id属性值。
过滤元素是选择符引擎的实现中普遍存在的一部分。过滤原则主要依靠元素属性值或者元素在DOM树中与其他节点的关系。
按照属性过滤:访问元素的DOM属性(通常使用 getAttribute() 方法),并且验证它的值是否等于给定值。按照class类名过滤是本类别中的一个子集(访问 className 属性并且验证它的值)。
按照位置关系过滤: 这种情况出现在对于在某父元素上使用 ":nth-child(even)" 或者 ":last-child" 组合的表达式。 如果浏览器支持这样的CSS选择符,那么会返回一个子元素的集合。另外,所有的浏览器都支持 childNodes,它返回一个子元素的集合,其中也包含所有的纯文本节点和注释语句节点。 使用以上两种方法,可以按照元素在DOM树中的位置关系进行过滤。
实现元素过滤功能具有两个目的:第一,可以把这个功能提供给用户让他们测试任意元素是否符合某值;第二,在内部计算时,可以检查元素是否符合用户给出的选择符表达式。
合并元素
在本文的第一段代码中,我们可以看见选择符引擎需要能够递归的找元素(找出后代元素)以及合并所有符合要求的元素,最终返回结果集。
但是,在本小节中,我们初步的代码实现太简单了。注意到,我们最终在文档中找到了两个 <span> 元素。因此,我们需要做额外的一步检查,来确保最终结果的数组中不能包含重复的元素。 大多数top-down方式的选择符引擎中都使用了若干确保元素唯一性的方法。
<div id="test"> <b>Hello</b>, I'm a ninja!</div> <div id="test2"></div> <script> (function () { var run = 0; this.unique = function (array) { var ret = []; run++; for (var i = 0, length = array.length; i < length; i++) { var elem = array[i]; if (elem.uniqueID !== run) { elem.uniqueID = run; ret.push(array[i]); } } return ret; }; })(); window.onload = function () { var divs = unique(document.getElementsByTagName("div")); assert(divs.length === 2, "No duplicates removed."); var body = unique([document.body, document.body]); assert(body.length === 1, "body duplicate removed."); }; </script>
其中的 unique() 方法给数组中的所有元素增加了一个额外的属性,标记它们是否被访问过。因此,当所有元素都处理后,最终只剩下了不重复的元素。类似本方法的其他算法可以在大多数CSS选择符引擎中见到。
到目前为止,我们大致就构造了一个 从上到下方式(top-down)的 CSS选择符引擎。 现在,我们来看另外的一种方案。
从下到上的方式实现
如果你不用考虑唯一地确定元素,那么你可以以从下到上的方式(bottom-up)实现选择符解析过程。它的流程跟从上到下的方式相反(复习那张解析过程的图示)。例如,对于这样的表达式 "div span",你需要首先找出所有 <span> 元素,然后对于每个候选元素,看看它们是否有一个 <div> 的祖先元素。
这样的方式并没有 从上到下的方式 流行。尽管它能够良好地处理简单的CSS选择符表达式,但是在每个候选元素上对于祖先的遍历就显得太耗费时间和资源了。
构造从下到上方式的引擎很简单。首先找到CSS选择符表达式中的最后一个部分,然后找出匹配的元素,接着按照一系列的过滤规则过滤掉不符合的元素。下面的代码阐述了这一过程。
<div>
<div>
<span>Span</span>
</div>
</div>
<script>
window.onload = function () {
function find(selector, root) {
root = root || document;
var parts = selector.split(" "),
query = parts[parts.length - 1],
rest = parts.slice(0, -1).join("").toUpperCase(),
elems = root.getElementsByTagName(query),
results = [];
for (var i = 0; i < elems.length; i++) {
if (rest) {
var parent = elems[i].parentNode;
while (parent && parent.nodeName != rest) {
parent = parent.parentNode;
}
if (parent) {
results.push(elems[i]);
}
} else {
results.push(elems[i]);
}
}
return results;
}
var divs = find("div");
assert(divs.length === 2, "Correct number of divs found.");
var divs = find("div", document.body);
assert(divs.length === 2,
"Correct number of divs found in body.");
var divs = find("body div");
assert(divs.length === 2,
"Correct number of divs found in body.");
var spans = find("div span");
assert(spans.length === 1, "No duplicate span was found.");
};
</script>
注意,上述代码只能处理一层祖先关系。如果需要处理多层祖先关系,那么当前层的状态则需要被记录。考虑使用两个数组:第一个数组记录将要被返回的元素(其中的某些元素被设置成undefined,如果它们不能匹配表达式);第二个数组记录当前需要被测试的祖先节点。
就如之前所述,这一步额外的祖先关系验证会带来更多的性能开销。但是按照从下到上的方式实现就不需要在结果集中取出重复元素的一步,因此它也算有一些优势。(因为按照从下到上的方式在最开始的时候每个元素就已经是各自独立不重复的了;而如果按照从上到下的方式,由于在递归时子树可能相互重叠,所以那会包含重复的元素)
小结
JavaScript实现的CSS选择符引擎是一个强大的工具。它能让我们轻松地使用若干选择符语法在页面上寻找DOM元素。尽管在完全实现一个选择符引擎时有非常多的细节需要考虑,这种情况正在大大的改善(得益于浏览器原生的方法)。
回顾一下本文讨论的几点:
- 现代浏览器已经开始实现对于 W3C标准选择符API的支持,但是依然有很长一段路要走.
- 考虑到性能问题,我们仍然有必要实现自己的选择符引擎。
- 要创建一个选择符引擎,我们可以:
- 利用 W3C标准的选择符API
- 利用 XPath
- 为了最好的性能,使用纯DOM操作方式
- 从上到下的方式非常流行,但是它需要一些清理工作:比如确保返回元素不重复。
- 从下到上的方式避免了那个清理工作,但是它会带来更多的性能开销。
随着浏览器逐渐支持W3C标准选择符,顾虑引擎实现的细节或许会成为过去式了。但是对于许多开发人员来说,那一天或许不能很快的到来。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号