


Hive 学习笔记(启动方式,内置服务)
一、Hive介绍
Hive是基于Hadoop的一个数据仓库,Hive能够将SQL语句转化为MapReduce任务进行运行。
Hive架构图分为以下四部分。
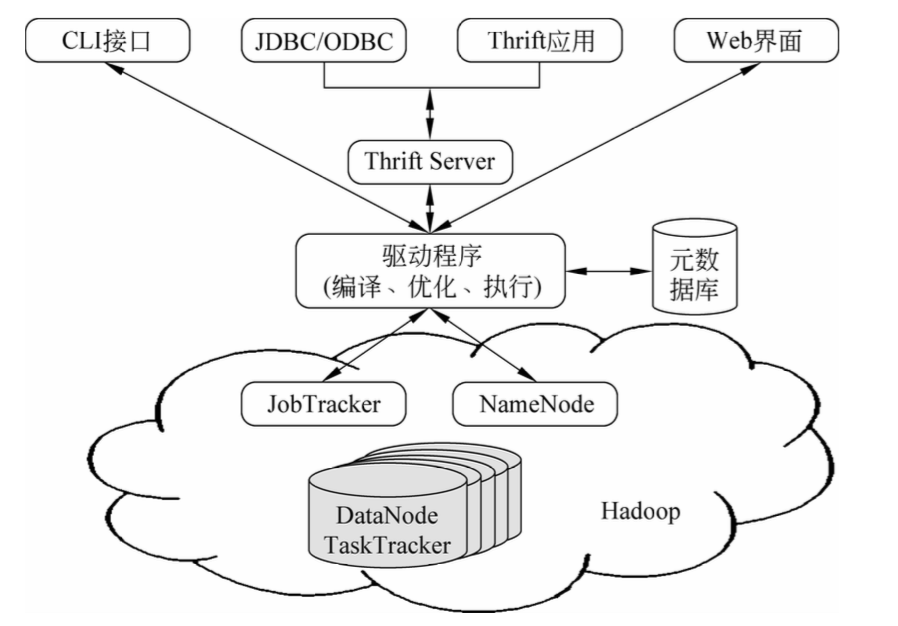
1、用户接口
Hive有三个用户接口:
-
- 命令行接口(CLI):以命令行的形式输入SQL语句进行数据数据操作
- Web界面:通过Web方式进行访问。
- Hive的远程服务方式:通过JDBC等方式进行访问。
2、元数据存储
将元数据存储在关系数据库中(MySql、Derby),元数据包括表的属性、表的名称、表的列、分区及其属性以及表数据所在的目录等。
3、解释器、编译器、优化器
分别完成SQL查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在HDFS中,并在随后由MapReduce调用执行。
4、数据存储
Hive没有专门的数据存储格式,也没有为数据建立索引,Hive中所有数据都存储在HDFS中。
Hive包含以下数据模型:表、外部表、分区和桶
二、Metadata,Metastore 的作用
Metadata即元数据: 元数据包含用Hive创建的database、tabel等的元信息。元数据存储在关系型数据库中。如Derby、MySQL等。
Metastore的作用是: 客户端连接metastore服务,metastore再去连接MySQL数据库来存取元数据。
有了metastore服务,就可以有多个客户端同时连接,而且这些客户端不需要知道MySQL数据库的用户名和密码,只需要连接metastore 服务即可。
三、Hive的元数据存储(Metastore三种配置方式)
由于元数据不断地修改、更新,所以Hive元数据不适合存储在HDFS中,一般存在RDBMS中。
1、内嵌模式(Embedded)
hive服务和metastore服务运行在同一个进程中,derby服务也运行在该进程中.
内嵌模式使用的是内嵌的Derby数据库来存储元数据,也不需要额外起Metastore服务。
这个是默认的,配置简单,但是一次只能一个客户端连接,适用于用来实验,不适用于生产环境。
2、本地模式(Local):本地安装mysql 替代derby存储元数据
这种安装方式和嵌入式的区别在于,不再使用内嵌的Derby作为元数据的存储介质,而是使用其他数据库比如MySQL来存储元数据。
hive服务和metastore服务运行在同一个进程中,mysql是单独的进程,可以同一台机器,也可以在远程机器上。
这种方式是一个多用户的模式,运行多个用户client连接到一个数据库中。这种方式一般作为公司内部同时使用Hive。
每一个用户必须要有对MySQL的访问权利,即每一个客户端使用者需要知道MySQL的用户名和密码才行。
<property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://127.0.0.1:3306/hive? createDatabaseIfNotExit=true</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>root</value> </property> <property> <name>hive.metastore.uris</name> <value></value> <description>指向的是运行metastore服务的主机,这是hive客户端配置,metastore服务不需要配置</description> </property> <property> <name>hive.metastore.warehouse.dir</name> <value>/user/hive/warehouse</value> <description>hive表的默认存储路径,为HDFS的路径location of default database for the warehouse</description> </property>
3、远程模式(Remote): 远程安装mysql 替代derby存储元数据
Hive服务和metastore在不同的进程内,可能是不同的机器,该模式需要将hive.metastore.local设置为false,将hive.metastore.uris设置为metastore服务器URL,
如果有多个metastore服务器,将URL之间用逗号分隔,metastore服务器URL的格式为thrift://127.0.0.1:9083。
远程元存储需要单独起metastore服务,然后每个客户端都在配置文件里配置连接到该metastore服务。
将metadata作为一个单独的服务进行启动。各种客户端通过beeline来连接,连接之前无需知道数据库的密码。
仅连接远程的mysql并不能称之为“远程模式”,是否远程指的是metastore和hive服务是否在同一进程内.
hive metastore 服务端启动命令: hive --service metastore -p <port_num>
如果不加端口默认启动:hive --service metastore,则默认监听端口是:9083 。
注意客户端中的端口配置需要和启动监听的端口一致。服务端启动正常后,客户端就可以执行hive操作了。
客户端连接metastore服务配置如下:
<property> <name>hive.metastore.uris</name> <value>thrift://127.0.0.1:9083,thrift://127.0.0.1:9084</value> <description>指向的是运行metastore服务的主机</description> </property>
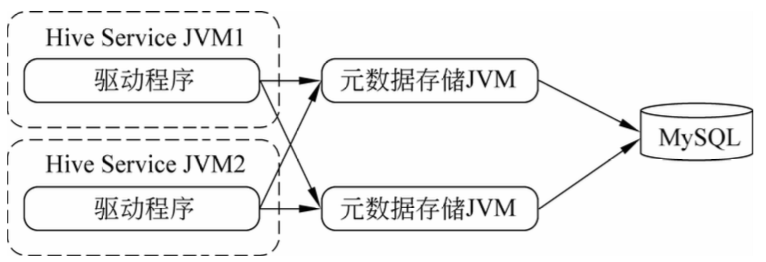
在服务器端启动一个MetaStoreServer,客户端利用Thrift协议通过MetaStoreServer访问元数据库。如下图:
四、Thrift 服务
通过hiveServer/hiveServer2启动Thrift服务,客户端连接Thrift服务访问Hive数据库(JDBC,JAVA等连接Thrift服务访问Hive)。
<property> <name>hive.server2.thrift.port</name> <value></value> <description>Port number of HiveServer2 Thrift interface when hive.server2.transport.mode is 'binary'.</description> </property> <property> <name>hive.server2.thrift.bind.host</name> <value>127.0.0.1</value> <description>Bind host on which to run the HiveServer2 Thrift service.</description> </property> <property> <name>hive.server2.enable.doAs</name> <value>false</value> <description> Setting this property to true will have HiveServer2 execute Hive operations as the user making the calls to it.
如果为True:Hive Server会以提交用户的身份去执行语句
如果为False:会以hive server daemon的admin user来执行语句
</description> </property>
启动Thrift服务:hive --service hiveserver2
测试Thrift服务:
新开一个命令行窗口,执行beeline命令:
shuwendeMBP:~ shuwen$ beeline
Beeline version 1.2.1.spark2 by Apache Hive
beeline> !connect jdbc:hive2://127.0.0.1:10000
Connecting to jdbc:hive2://127.0.0.1:10000
Enter username for jdbc:hive2://127.0.0.1:10000: shuwen
Enter password for jdbc:hive2://127.0.0.1:10000: ******
log4j:WARN No appenders could be found for logger (org.apache.hive.jdbc.Utils).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
Connected to: Apache Hive (version 1.2.2)
Driver: Hive JDBC (version 1.2.1.spark2)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://127.0.0.1:10000> show databases;
+----------------+--+
| database_name |
+----------------+--+
| db_2_1 |
| default |
| netuml |
+----------------+--+
3 rows selected (1.941 seconds)
五、Hive的三种启动方式
1、hive 命令行模式
进入hive安装目录,输入bin/hive的执行程序,或者输入 hive –service cli,用于linux平台命令行查询,查询语句基本跟mysql查询语句类似
2、hive web界面的启动方式
Hive 2.0 以后才支持Web UI的
bin/hive –service hwi (& 表示后台运行)
用于通过浏览器来访问hive,感觉没多大用途,浏览器访问地址是:127.0.0.1:9999/hwi
3、hive 远程服务 (端口号10000) 启动方式 (Thrift服务)
bin/hive –service hiveserver2 &(&表示后台运行)
用java,python等程序实现通过jdbc等驱动的访问hive就用这种起动方式了,这个是程序员最需要的方式了
六、Hive几种内置服务
执行bin/hive --service help 如下:
shuwendeMBP:~ shuwen$ hive --service help Usage ./hive <parameters> --service serviceName <service parameters> Service List: beeline cli help hiveburninclient hiveserver hiveserver2 hwi jar lineage metastore metatool orcfiledump rcfilecat schemaTool version Parameters parsed: --auxpath : Auxillary jars --config : Hive configuration directory --service : Starts specific service/component. cli is default Parameters used: HADOOP_HOME or HADOOP_PREFIX : Hadoop install directory HIVE_OPT : Hive options For help on a particular service: ./hive --service serviceName --help Debug help: ./hive --debug --help
我们可以看到上边输出项Server List,里边显示出Hive支持的服务列表,beeline cli help hiveserver2 hiveserver hwi jar lineage metastore metatool orcfiledump rcfilecat。
下面介绍最有用的一些服务
1、cli:是Command Line Interface 的缩写,是Hive的命令行界面,用的比较多,是默认服务,直接可以在命令行里使用。
3、hwi:其实就是hive web interface的缩写它是hive的web借口,是hive cli的一个web替代方案。
2、hiveserver:这个可以让Hive以提供Thrift服务的服务器形式来运行,可以允许许多个不同语言编写的客户端进行通信,使用需要启动HiveServer服务以和客户端联系,
我们可以通过设置HIVE_PORT环境变量来设置服务器所监听的端口,在默认情况下,端口号为10000,这个可以通过以下方式来启动Hiverserver:
bin/hive --service hiveserver -p 10002
其中-p参数也是用来指定监听端口的
4、jar:与hadoop jar等价的Hive接口,这是运行类路径中同时包含Hadoop 和Hive类的Java应用程序的简便方式
5、metastore:在默认的情况下,metastore和hive服务运行在同一个进程中,使用这个服务,可以让metastore作为一个单独的进程运行。
我们可以通过METASTOE——PORT来指定监听的端口号
七、问题总结
Could not create ServerSocket on address 0.0.0.0/0.0.0.0:9083
遇到这种情况大家都找不到头绪,是因为你开始运行了hive的metastore,可以输入jps
查看有没有RunJar
然后再输入
hive --service metastore启动
Hive在spark2.0.0启动时无法访问spark-assembly-*.jar的解决办法
ls: /usr/local/share/spark-2.0.0-bin-hadoop2.7/lib/spark-assembly-*.jar: No such file or directory
发现主要原因是:在/<PathToHive>/bin/hive文件中,有这样的命令:加载spark中相关的JAR包if [[ -n "$SPARK_HOME" ]] then sparkAssemblyPath=`ls ${SPARK_HOME}/lib/spark-assembly-*.jar` CLASSPATH="${CLASSPATH}:${sparkAssemblyPath}" fi但是spark升级到spark2以后,原有lib目录下的大JAR包被分散成多个小JAR包,原来的spark-assembly-*.jar已经不存在,所以hive没有办法找到这个JAR包。
解决方法:修改/<PathToHive>/bin/hive文件,将加载原来的lib/spark-assembly-*.jar`替换成jars/*.jar,就不会出现这样的问题。
1.hive.metastore.uris指向的是运行metastore服务的主机,并不是指向运行hiveserver的主机,那台主机不用启动hiveserver也ok;
2.直接使用hive命令启动shell环境时,其实已经顺带启动了hiveserver,所以远程模式下其实只需要单独启动metastore,然后就可以进入shell环境正常使用
3.hiveserver和metastore进程名都叫RunJar。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号