


前言
之前写了一篇文章,总体介绍了EQueue。在看这篇文章之前如果还没看过那篇文章,可能会看不懂这篇文章。所以建议没看过的朋友务必先看一下那篇文章中所提到的各种概念,这样才能更好的理解本文所说的内容。说实话我当初写EQueue也是抱着一种玩的态度的,就是想尝试写一个分布式消息队列,用来为ENode提供分布式消息通信的能力。后来写着写着,发现越来越好玩,因为觉得这个队列以后应该会很实用,所以就花了更多的时间去设计它,完善它。希望它最终能被更多的人使用。到目前为止,我觉得目前基本实现了以下特性:轻量级、分布式、高性能、消息可持久化、支持大量堆积消息(不受限于内存大小)、支持消费者集群、消费者流控、消息的监控支持。本文我想再重点分析一下消息的持久化以及消息堆积方面的设计。首先说明一下,这里的设计都是我个人的设计,没有参考成熟的消息队列的做法,比如rabbitmq, rocketmq, kafka,等。我觉得能够按照自己的思路去实现一个作品,这种感觉真好!接下来我们开始分析吧。
EQueue核心架构简介
关于消息的持久化,我在第一篇文章中其实已经基本提到过,请看这个链接。为了后面方便说明问题,我在这里再贴一下EQueue的核心概念图:
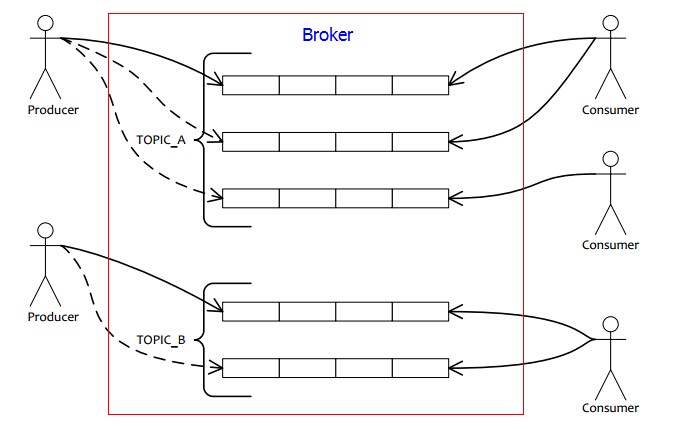
如上图所示,EQueue主要由三部分组成:1)Producer,即消息生产者;2)Broker,即存储消息的地方,上图中红框的部分;3)Consumer,即消息消费者。
消息的数据结构设计
上图中的Broker我们可以理解为一台服务器,该服务器就是用来存储消息的。Producer发送消息是发到这个服务器,Consumer消费消息也是从这个服务器拿消息。Broker上的每个消息都有Topic和Queue的概念。Topic与Queue的关系是,一个Topic下可以有多个Queue,QueueId用一个序号来区分。比如一个Topic下有4个Queue,那这几个Queue的QueueId分别为0,1,2,3。然后一个Producer发送消息时,它会按照某个路由方式(ENode中会按照聚合根ID或CommandId的hashcode取模来路由到某个特定的Queue)来把消息发送到Broker上当前Topic下的哪个Queue。所以,在发送一个消息时,Producer除了会传递消息的内容外,还会传递消息的Topic以及QueueId来告诉Broker,这个消息是要放在哪里的。然后Broker根据Topic以及QueueId得到对应的Queue,就可以开始做持久化消息的逻辑了。下面我们看一下一个持久化在Broker上的消息的数据结构:
[Serializable] public class QueueMessage { /// <summary>消息所属Topic /// </summary> public string Topic { get; set; } /// <summary>消息内容,一个二进制数组 /// </summary> public byte[] Body { get; set; } /// <summary>消息的全局序号 /// </summary> public long MessageOffset { get; set; } /// <summary>消息所属的队列ID /// </summary> public int QueueId { get; set; } /// <summary>消息在所属队列的序号 /// </summary> public long QueueOffset { get; set; } /// <summary>消息的存储时间 /// </summary> public DateTime StoredTime { get; set; } }
MessageOffset是消息的全局序号,就是Broker上的消息的唯一ID,QueueOffset是该消息在Queue中的序号,是在该Queue中唯一。其他的属性应该就不用多解释了。
从上面的数据结构可以看出,只要我们持久化了消息,那只要消息不丢,那我们一定可以根据这些消息重建出所有的Topic以及Queue,以及可以知道消息在Queue中的序号与其全局序号的映射关系,因为消息本身都已经包含了这个映射关系了。
消息的持久化和堆积的思考
为什么要持久化?因为我们的消息不能丢,我觉得这一个理由就够了!那么怎么持久化?我能想到的方案有三个:1)写文件;2)存key/value的nosql,比如leveldb;3)存储在关系型db,比如Sql Server;
关于前面两个方案的讨论,在前一篇文章中有比较详细的讨论,本文不想多讨论了。因为EQueue最终采用的是第三种方案,也就是用关系型db来持久化,目前实现的是Sql Server。
选择Sql Server作为消息存储的权衡考虑
如果是每个过来的消息,都直接持久化到Sql Server,那持久化会成为瓶颈。所以,在性能和可能丢消息之间,我选择了可能丢消息的方案。所以我设计为定时持久化消息(就像我们写入文件的内存,nosql或者操作系统都是有缓存的,并没有立即刷入磁盘一样!),现在是每隔500毫秒,使用SqlBulkCopy的方法批量持久化消息。大家知道Sql Server的SqlBulkCopy的性能是非常高的,据我个人的测试,每秒20W肯定不是问题。所以,我可以认为,SqlBulkCopy不会成为消息持久化的瓶颈。但是因为是定时持久化的。所以假如服务器断电了,那我们有可能会丢失最近500毫秒的消息。实际情况有可能丢失的还会更多。因为假如Sql Server有问题,导致消息都没办法持久化,那断电的时候,我们丢失的就不只是500ms的消息了。那有办法吗?就是监控,我觉得我们可以通过对消息队列的监控,如果发现当前已经持久化的消息的MessageOffset和当前最新的最大MessageOffset之间的差值大于一定的警界值,就报警。这样我们就能及时发现消息的持久化是否有大量延迟,提早做出措施解决。好,通过SqlBulkCopy的定时持久化,消息持久化的性能瓶颈解决了。同时我们也知道了潜在的风险以及如何预防这个风险了。另外一个保护措施是,我们可以给我们的Broker服务器配置UPS电源,保证服务器断电时,还能继续工作。
消费者拉取消息时,从内存直接拉取还是从db拉取的权衡
假如,我们的消息都在内存,那消费者拉取性能肯定很高,因为当消费者要获取并消费消息时,它总是在内存,所以不会有IO,所以性能好。但是问题是,内存有限,放不下很多的消息。假设一个消息200字节,那16G的内存,最多只能放下8500W多个消息。这个数量显然还是不够高,因为我们的目标是大量消息的堆积,所以我们必须要做出一些权衡。我觉得是否可以这样,我们可以配置一个阀值,比如1000W,只要当前Broker上目前存在的消息数不到1000W,那就放在内存;如果超过1000W,则不再存放在内存,而是仅存储在db。但是,好像如果通过阀值来判断的话,好像还需要开发者自己评估Broker服务器的内存大小以及平均每个消息的大小,从而才能计算出一个合理的阀值。能否让框架自动根据当前内存的使用量来评估是否后续的消息可以放在内存呢?之前我也是这个想法,但是后来还是采用了阀值的方案。因为后来实现的时候,发现效果不好,而且由于消息消费后还会被定时删除,且消息也在同时不断增加,且我们拿到的当前服务器的可用内存有可能不是那么准确。总之,算法比较复杂,且不太稳定。所以,最后还是采用了简单可靠的阀值方案。
那么这样的话,就是一部分消息在内存,一部分不在。那当我们拉取到不在内存的消息时,那不是要去访问db了?那消费者消费消息性能不是会急剧降低了吗?我也有这个顾虑,所以,想了个办法。就是当发现当前要消费的消息不在内存时,则一次性批量从db拉取N多消息,比如5000个(可配置)。拉取过来后,立马存储到内存。这样当消费者要消费这5000个消息时,我们能确保这些消息一定在内存了。也就是说,最差的情况,假如现在所有的消息都不在内存,那我们访问db的频率是,每5000个消息,去访问一次db。这样我们可以极大的降低拉取消息的频率,从而基本不会影响消费者消费消息的性能。另外你可能会担心一次性从db拉取5000个消息可能会比较耗时,这点我测试了下,性能还是很高的,肯定不会成为瓶颈。因为我们的消息的主键就是消息的全局序号,是一个long类型的值,在db的消息表中就是主键,根据主键用>=, <=的条件去查询,性能是非常快的。
另外,实际上由于这个阀值是基于当前内存中还没被消费的消息数来判断的,只要我们的消费者性能跟得上生产者发送消息的性能,那Broker上理论上不会有大量堆积的消息。因为我们的消息假如被及时消费了,那Broker上会有定时的线程,定时从Broker的内存移除已被所有消费者已消费的消息。这样Broker上目前还没被消费的消息数应该不会到达阀值。这样所有的消息都一定是在内存存在的。只有当消费者的性能长时间跟不上生产者的性能时,才会出现消息堆积,我们才会启动阀值保护措施,将超过阀值的消息不再放入内存,以防止内存爆满,使机器挂掉。所以,我们可以预见,监控系统是多么重要,我们应该及时关注监控数据,设置好报警规则,确保尽量让消息都在内存,这是一个好的实践。
通过上面的分析,我们知道了如何确保内存不会被没有消费的消息占满的一个措施,接下来我们来看看消息索引的问题。
假如消息的索引信息太多,内存放不下了呢?
上面有提到过,一个Topic下有多个Queue,每个Queue实际上就是一个逻辑队列,该队列里存放了消息当前在Queue中的位置(序号)以及该消息的全局位置(序号)之间的映射关系。简单的说,就是每个Queue中有一个ConcurrentDictionary<long, long>,key就是queueOffset,value就是messageOffset。我把这个映射关系字典叫做消息的索引信息。
通过前面我们对消息的数据结构的分析,我们知道这些Queue我们是无需持久化的,也就是说我们可以放在内存。那内存真的放的下吗?经过我的测试,我发现ConcurrentDictionary<long, long>还是很占用内存的。每100M的内存测试下来只能放100W个中等大小的消息索引(long类型的key/value键值对)。这样的话,1G内存只能放1000W个左右的索引了,10G内存也只能放1亿个左右的索引。太少了!那怎么办呢?思路是,既然放不下,那就内存也不放了。我思考后发现,其实我们无须把每个消息的索引都放在Queue里,我们其实只要知道当前Queue的当前最大的QueueOffset即可。
然后,任何一个消费者消费消息时,都是面向单个Queue的,EQueue采用的是拉模型(Pull Message),消费者每次过来拉消息都是拉一批去消费,现在默认值是32个。所以,假如当前Queue的最大QueueOffset是100,然后消费者发过来的拉取消息的请求中要拉取的起始消息的QueueOffset是50,然后假如现在Queue里的第50个开始到100个之间的所有消息所以都不在内存。那怎么办呢?很简单,我们可以在此时,用一条SQL到Sql Server中的消息表中批量拉取一定数量的消息索引(比如5000(可配置)个,实际可能只能拉取到50个,因为当前这个Queue最大的Offset只有100),然后将这些拉取到的索引设置到Queue上,这样这个Queue上就有50到100的这些消息的索引信息了。这样我们就能知道从50到81(共32个索引)之间的这些消息的全局序号了,从而就能拿到最终的消息了,然后就能返回给消费者了。由于这里我们也是批量拉取消息索引,所以和前面一样,也不会有什么性能问题。
这里,因为这里要根据Topic, QueueId, QueueOffset这几个条件从消息表中查询消息,所以如果不使用Sql Server这种关系型数据库,还真不好实现。因为假如用文件持久化消息或者用key/value的nosql,虽然持久化性能很高,都可以立即持久化(实际上也没那么好,呵呵,因为NoSQL也不是立即刷盘的哦!断电后也有丢数据的风险),但都不支持像这种需要用到二级索引的查询需求。所以,这也是我倾向于考虑使用关系型db的原因。另外,为了查询时性能达到最优,我对这三个字段建立了索引,确保不会全表扫描,提高查询性能。
实际上,我这里也给Queue可以在内存缓存多少个消息索引设计了一个阀值,默认是500W(大家可以根据实际情况和Queue的多少来配置,以后EQueue会考虑给不同Topic下的Queue支持配置不同的阀值)。也就是说,只要Queue中的消息索引不超过500W,那所有索引都在内存,只有超过了500W,才不会再把消息索引放在内存。同样,因为只要消息被消费及时的话,Queue中的消息索引都会被及时移除,这样Queue中的消息索引一般就不可能超过500W了。只有消费者消费消息的速度长时间低于产生消息的速度,才会出现Queue中的消息索引出现堆积最终超过500W的情况。同理,我们这里只要做好监控,那也能保证不会到达阀值。
好了,Broker上最占用内存的2个点我们都分析了如何控制内存的占用大小。总体思路是通过控制内存中缓存的消息数以及消息的索引数来达到内存不会因为消息和消息索引的不断增加而导致用完。然后在内存中消息或消息索引不存在时(监控做的话的话,这种情况一般不会发生),通过批量从db快速拉取(两种拉取都是可以走索引)再放入内存的方式,来实现消费者拉取消息时,依然能保持高性能。
消息的监控设计
通过上面的分析,我们知道,我们非常需要知道,当前Broker上的消息堆积情况。当出现有堆积时,我们要尽快做出处理。所以,我实现了最基本的监控数据的展示。主要实现了两个页面:
1)展示当前Broker上有哪些Queue,每个Queue的当前Offset,当前已被所有消费者消费的最大Offset,Queue中的当前消息数。如下如所示:

2)展示当前Broker上每个Queue被消费的情况,每个Queue正在被哪个消费者消费,已经被这个消费者消费到哪里了(也就是消费位置)。如下图所示:
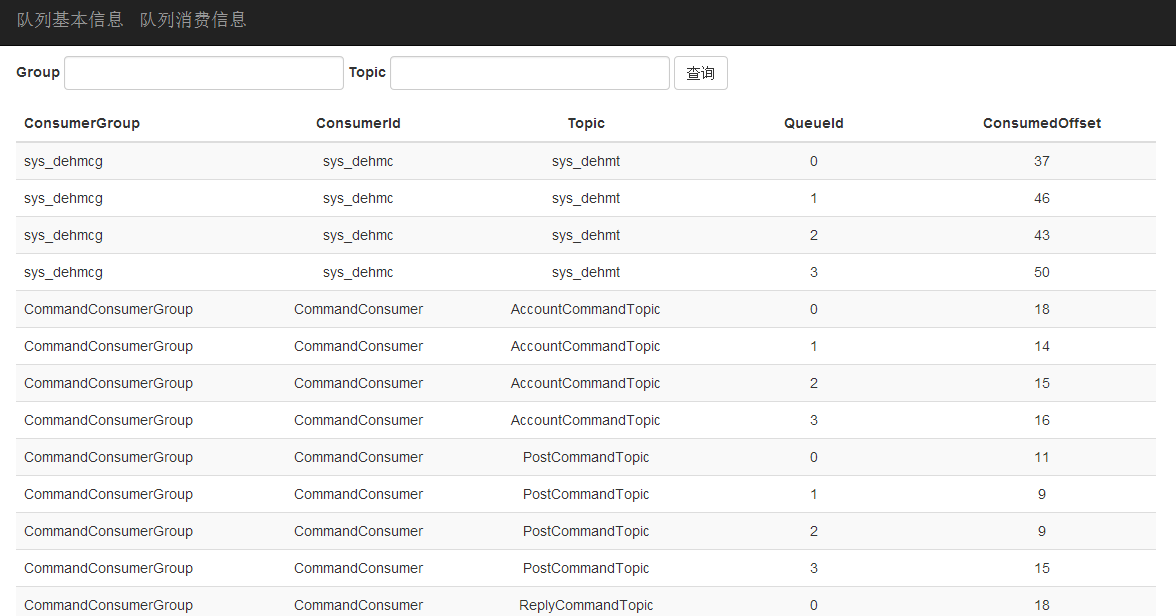
具体的数据,大家可以到http://www.enode.me/equeueadmin这个监控页面查看。上面的监控数据还只是最基础的,但也是最重要的数据。以后我会不断丰富监控数据以及添加报警功能。
ps: http://www.enode.me是用ENode实现的一个简单论坛,以上这个监控页面的地址则是对这个论坛的消息监控页面。
又快2点了,就到这吧!又收获一篇,开心,呵呵。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号