
Skip-Gram模型
Stanford CS224n的课程资料关于word2vec的推荐阅读里包含Word2Vec Tutorial - The Skip-Gram Model 这篇文章。这里针对此文章作一个整理。
word2vec做了什么事情
从字面意思上来说就是将单词word转为向量vector,通过词向量来表征语义信息。
word2vec模型
这篇文章主要介绍的是Skip-Gram模型,除此之外word2vec还有CBOW模型。
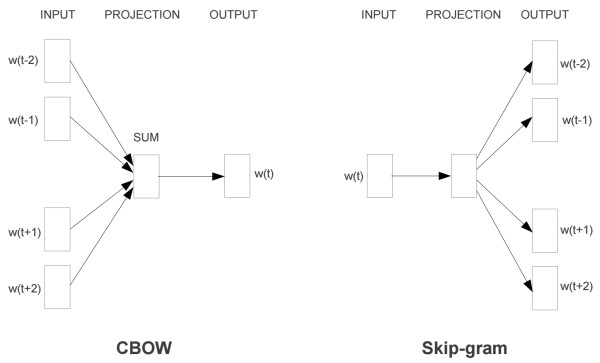
如上图所示,这两种模型的区别就是
- Skip-Gram是给定输入词来预测上下文
- 而CBOW则是给定上下文来预测输入词
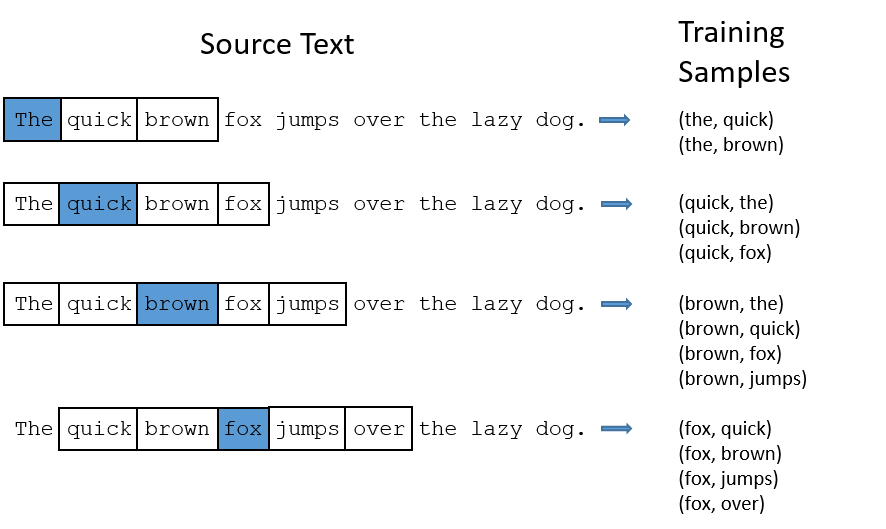
那么如何来训练Skip-Gram模型呢?上面这张图使用的句子是:"The quick brown fox jumps over the lazy dog.",通过逐一选定句子中的单词作为输入词,将与之相邻的词提取出来,进行学习。图中的窗口大小为2,也即每次向前和向后各看2个词(如果存在的话)。
一些细节
输入参数:通常会将文本中的词进行编码表示,如常见的有将文本库中的单词转换为词汇表,这样可以将每个单词通过one-hot编码表示。比如总共有10000个词,则每个单词最终都可以通过一个10000维向量表示。
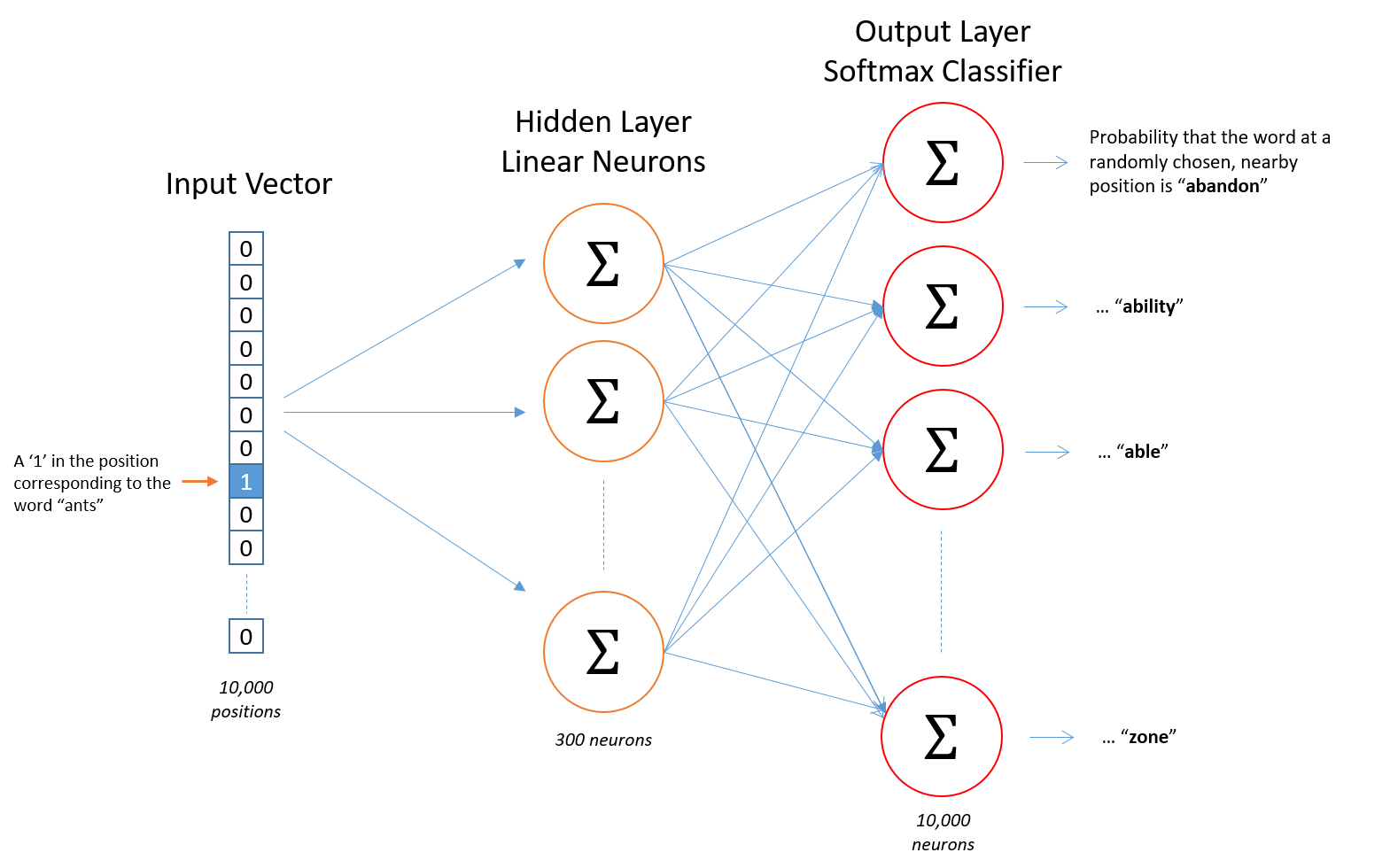
如上图所示,网络的输入是一个单词,10000维的one-hot向量,最终输出的结果也是一个10000维的向量,其中的值表示对应的词作为输入词的上下文的概率,也就是说最后输出的是输入词的邻近词的概率分布。
隐藏层
从上面的图也可以看出隐藏层中有300个神经元,也就是说输入词被表示为300维的一个向量。
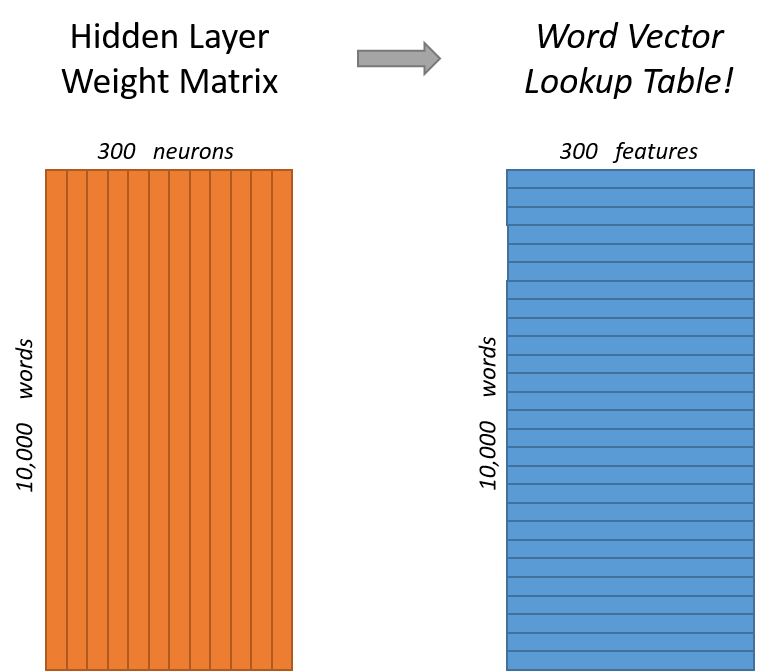
隐藏层中的权重矩阵大小为10000*300,一个10000维的one-hot输入词通过权重矩阵映射到了一个300维的向量,而这个向量正是所谓的word vector,对应于上图中右边的每一行。
另外值得提的是,如果将110000的输入向量与10000300的权重矩阵作乘积的话,其实效率挺低的。因为one-hot向量中只有1个元素是1,所以不难发现其实结果就是权重矩阵中的某一行。
输出层
在隐藏层中计算得到的300维的向量最终会再经过输出层变为10000维的向量,这里使用的是softmax回归,最终输出的结果所有概率之和为1。
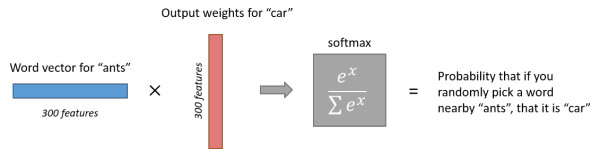
上图展示了输入词为ants,计算输出词为car的概率。
