Mysql 练习题一
库操作:
1. 创建 数据库
create database db1;
2. 使用数据库
use db1
3. 查看表
show tables;
4. 删除
drop database db1
表操作:
创建一个表
create TABLE t1( name VARCHAR(50) not null , age int NULL, salary DOUBLE(5,2) );
删除表
drop table t1
查询:
SELECT * from t1
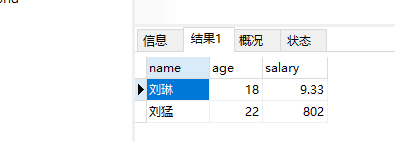
复制表
create table t2 select * from t1; # 复制表结构和数据,
create table t3 like t1; #复制表结构
插入数据:
insert into t2(name,age) VALUES("li", 19);

修改表字段:
update t2 set name ="小风" where name ="li"
删除操作:
delete from t2 where age =18
查询部门id为空的数据
SELECT * from person where dept_id IS NULL;
and 语法
SELECT * from person where salary >4000 and age<=30;
区间查询.
select * from person where salary between 5000 and 10000
集合查询
-- select * from person where age =20 or age =23 or age =40
select * from where not age in(23,20);
模糊查询
select * from person where name LIKE "%月"
select * from person where name LIKE "%月%" --包含的意思
select * from person where name LIKE "_l__" #_为占位符
排序:
select * from person ORDER BY salary desc
select * from person ORDER BY salary desc,age DESC
select * from person ORDER BY CONVERT(name USING gbk) #对中文进行排序.
聚合函数:
-- select MAX(salary) from person
--
-- select MIN(salary) from person
-- --
-- SELECT AVG(salary) FROM person
--
-- SELECT SUM(salary) from person
--
SELECT count(*) from person

分组:
SELECT count(id) ,avg(salary)from person group by dept_id having avg(salary)>= 5000;

正则匹配
SELECT * from person where name REGEXP "^a"
SELECT * from person where name REGEXP "[a,e,n]"
sql语句的执行顺序

多表查询
select * from person,dept where person.dept_id =dept.did
SELECT * from person LEFT JOIN dept on person.dept_id =dept.did; #以左表作为基准,
1.创建留言数据库: liuyandb;
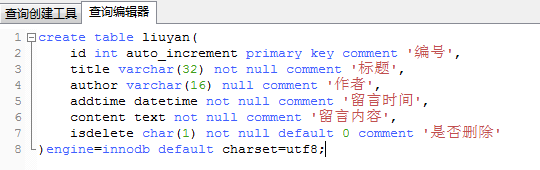
create table liuyan(
id int auto_increment primary key comment '编号',
title varchar(32) not null comment '标题',
author varchar(16) null comment '作者',
addtime datetime not null comment '留言时间',
content text not null comment '留言内容',
isdelete char(1) not null default 0 comment '是否删除'
)engine=innodb default charset=utf8;
2.在liuyandb数据库中创建留言表liuyan,结构如下:
|
表名 |
liuyan |
留言信息表 |
|||
|
序号 |
字段名称 |
字段说明 |
类型 |
属性 |
备注 |
|
1 |
id |
编号 |
int |
非空 |
主键,自增1 |
|
2 |
title |
标题 |
varchar(32) |
非空 |
|
|
3 |
author |
作者 |
varchar(16) |
可以空 |
|
|
4 |
addtime |
留言时间 |
datetime |
非空 |
|
|
5 |
content |
留言内容 |
text |
非空 |
|
|
6 |
isdelete |
是否删除 |
char(1) |
非空 |
默认值 0 |
3.在留言表最后添加一列状态(status char(1) 默认值为0)
alter table liuyan add status char(1) default 0 ;

4.修改留言表author的默认值为’youku’,设为非空
alter table liuyan modify author VARCHAR(16) not null default 'youkong'
5.删除liuyan表中的isdelete字段
alter table liuyan drop isdelete
6.为留言表添加>5条测试数据 (例如:
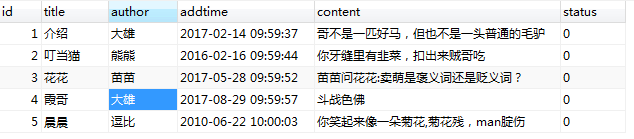
insert into liuyan values (null,'介绍','大雄','2017-02-14 09:59:37','哥不是一匹好马,但也不是一头普通的毛驴',null), (null,'叮当猫','熊熊','2016-02-16 09:59:44','你牙缝里有韭菜,扣出来贼哥吃',null), (null,'花花','苗苗','2017-05-28 09:59:52','苗苗问花花:卖萌是褒义词还是贬义词?',null), (null,'霞哥','大雄','2017-08-29 09:59:57','斗战色佛',null), (null,'晨晨','逗比','2010-06-22 10:00:03','你笑起来像一朵菊花,菊花残,man腚伤',null);
7. 要求将id值大于3的信息中author 字段值改为admin
update liuyan set author ='admin' where id >3
8. 删除id号为4的数据。
delete from liuyan where id =4
附加题:
- 为留言表添加>10条测试数据,要求分三个作者添加数据
- 查询某一个作者的留言信息。
select id,title,author,addtime,content,status from liuyan where author ='xxxx';
- 查询所有数据,按时间降序排序。
select * from liuyan order by addtime DESC
- 获取id在2到6之间的留言信息,并按时间降序排序
select * from liuyan where id BETWEEN 2 and 6 ORDER BY addtime desc
y
- 统计每个作者留了多少条留言,并对数量按从小到大排序。
select author,count(id) as'留言条数' from liuyan group by author order by count(id) desc
将id为8、9的两条数据的作者改为’doudou’.
update liuyan set author ='doudou' where id in (3,5);
- 取出最新的三条留言。
select * from (select id,title,author,addtime,content,status from liuyan ORDER BY addtime desc) haha LIMIT 3
- 查询留言者中包含”a”字母的留言信息,并按留言时间从小到大排序
select * from liuyan where author like '%a%' order by addtime asc
- 删除”作者”重复的数据,并保留id最大的一个作者
delete from liuyan where author in( select author from (select author from liuyan group by author having count(1)>1) a ) and id not in( select id from (select max(id) id from liuyan group by author having count(1)>1) b )

 浙公网安备 33010602011771号
浙公网安备 33010602011771号