


IR(information retrieval) introduction
- 定义及相关概念
学术界:
" Information retrieval is finding material(usually documents) of an unstructured nature(usually text)
that satisfies an information need form within large collections(usually stored on computers)"
通俗的说,信息检索就是指从大量的无规则的数据集中,需找那些能够满足用户需求的数据。 在计算机发展的早期,
信息检索仅仅只是少数人参与活动,这些人包括:图书管理员、学者和研究员等。但是随着计算机技术的飞速发展和普及,
现在每天都有成千上万的人参与信息检索的过程中来(比如,当他们利用web搜索引擎查询资料或者是查找自己的email).
信息检索技术已经成了信息获取的主要的形式。
"unstructure data" ,通常是指那些没有清晰、语法明确,计算机容易读懂或处理的结构。它通常是与结构化数据的
相对立的。结构化数据的典型代表就是关系数据库。
信息搜索系统按照其覆盖的范围,通常分为Web检索,个人信息检索,企业、结构和特殊研究领域的检索。信息检索中
设计的两个基本概念就是:term-document matrix 和中心倒序检索数据结构。因此,接下来,我们将简要的介绍一下
布尔检索模型和其检索的处理过程。
布尔检索模型(Boolean retrieval model): 这个模型可以处理任何布尔表达是形式的查询,所谓的布尔表达式的形式
就是用操作符AND、OR、NOT将要查询的(term)词组连接起来的形式。
term-document matrix:这是一个二元组的矩阵,每个元素的表达形式(t,d),其中t是检索的基本单位,d是一个文档。
只有当一个文档d包含了检索术语t时,(t,d)=1.
例如,如下所示是一个数据集(由大量documents组成)的term-document matrix:
Antony Julius The Hamlet Othello Macbeth
and Caesar Tempest
Cleopatra
Antony 1 1 0 0 0 1
Brutus 1 1 0 1 0 0
Caesar 1 1 0 1 1 1
Calpurnia 0 1 0 0 0 0
Cleopatra 1 0 0 0 0 0
mercy 1 0 1 1 1 1
worser 1 0 1 1 1 0
利用这个term-document矩阵,我们来演示一下查询 Brutus AND Caesar NOT Calpurnia
110100 AND 110111 AND 101111=100100
因此,查询结果为 Antony and Cleopatra 和 Hamlet文档满足查询的内容。
现在让我们来试想一下,如果这个矩阵达到500K X 100K 大小时,term-document矩阵是否还适合于用于检索?当然
不可以。于此同时,我们还发现这个矩阵数据相对稀疏。有时几乎可以达到98%的数据都为0.因此,一种更好的表达就是仅仅
记录位置为1的位置。这个概念就映射到了信息检索中的第一个主要的概念--倒序索引的概念。这个名字挺起来有点多余的:一
个索引通常从一个查询词组(term)映射到包含该词组的文档列表中。
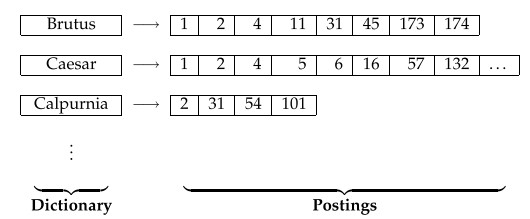
如下图所示,在倒序索引中,通常将terms(检索的基本单位)存放到一个Dictionary中,而将记录每个term所在docume-
-nts的信息放到链表中,这样每个链表中的每个项记录了一个term出现在documents的id号,正式的,我们将这样的链表为p-
-osting.所有的这些链表合起来成为postings.
接下来的几篇文章将继续这样倒序索引的建立过程以及使用过程。
posted on 2010-04-08 20:46 Creative Common 阅读(256) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号