


全文搜索资料
全文搜索资料
http://msdn.microsoft.com/zh-cn/library/ms142571.aspx
SQL Server 中的全文搜索为用户和应用程序提供了对 SQL Server 表中基于字符的数据运行全文查询的功能。
在可以对某一表运行全文查询之前,数据库管理员必须对该表创建全文索引。
全文索引包括表中一个或多个基于字符的列。
这些列可以具有下列任何一种数据类型:char、varchar、nchar、nvarchar、
text、ntext、image、xml 或 varbinary(max) 和 FILESTREAM。
每个全文索引都对表中的一个或多个列创建索引,并且每个列都可以使用特定语言。
全文查询根据特定语言(例如,英语或日语)的规则对词和短语进行操作,从而对全文索引中的文本数据执行语言搜索。
全文查询可以包括简单的词和短语,或者词或短语的多种形式。
全文查询返回包含至少一个匹配项(也称为“命中”)的所有文档。
当目标文档包含在全文查询中指定的所有字词,并符合任何其他搜索条件(如匹配的字词之间的距离)时,即发生匹配。
注意
全文搜索是 SQL Server 数据库引擎的一个可选组件
使用全文搜索可以干什么?
全文搜索适用于多种商业应用场景:例如,电子商务(在网站上搜索项目)、律师事务所(在法律数据库中搜索案件记录)或人力资源部门(从所存储的个人简历中找到符合职位描述的简历)。 不管是什么样的商业应用场景,全文搜索的基本管理任务和开发任务是相同的。 然而,在给定的商业应用场景中,可以对全文索引和查询进行优化以使其满足业务目标。 例如,对于电子商务来说,最大限度地提高性能可能比对结果进行排序、检索的准确性(实际上有多少个现有匹配项是由全文查询返回的)或支持多种语言更重要。 对于律师事务所来说,首先需要考虑的可能是返回所有可能存在的匹配项(“返回全部”信息)。
全文搜索查询
在将列添加到全文索引之后,用户和应用程序即可对列中的文本运行全文查询。 这些查询可以搜索以下项中的任一项:
一个或多个特定的词或短语(“简单词”)
以指定文本开头的词或短语(“前缀词”)
特定词的变形(“派生词”)
与另一个词或短语邻近的词或短语(“邻近词”)
特定词的同义词形式(“同义词库”)
使用加权值的词或短语(“加权词”)
全文查询不区分大小写。 例如对于 "Aluminum" 或 "aluminum",搜索将返回相同的结果。
全文查询使用一小组 Transact-SQL 谓词(CONTAINS 和 FREETEXT)和函数(CONTAINSTABLE 和 FREETEXTTABLE)。 然而,给定商业应用场景的搜索目标会对全文查询的结构产生影响。 例如:
电子商务(在网站上搜索产品):
1 SELECT product_id FROM products WHERE CONTAINS(product_description, 2 ”Snap Happy 100EZ” OR 3 FORMSOF(THESAURUS,’Snap Happy’) OR 4 ‘100EZ’) AND product_cost<200
招聘员工(搜索具有 SQL Server 使用经验的职位候选人):
1 SELECT candidate_name,SSN FROM candidates WHERE CONTAINS(candidate_resume,”SQL Server”) AND 2 candidate_division =DBA
全文搜索的组件和体系结构
全文搜索体系结构包括以下进程:
SQL Server 进程 (sqlservr.exe)。
筛选器后台程序宿主进程 (fdhost.exe)。
为了安全起见,筛选器由称为筛选器后台程序宿主的单独进程加载。 fdhost.exe 进程是由 FDHOST 启动器服务 (MSSQLFDLauncher) 创建的,这些进程使用 FDHOST 启动器服务帐户的安全凭据运行。 因此,必须运行 FDHOST 启动器服务才能正常进行全文索引和全文查询。 有关设置此服务的服务帐户的信息,请参阅设置用于全文筛选器后台程序启动器的服务帐户。
这两个进程包含全文搜索体系结构的各组件。 下图概括了这些组件及其关系。 该图后面的内容介绍了这些组件。
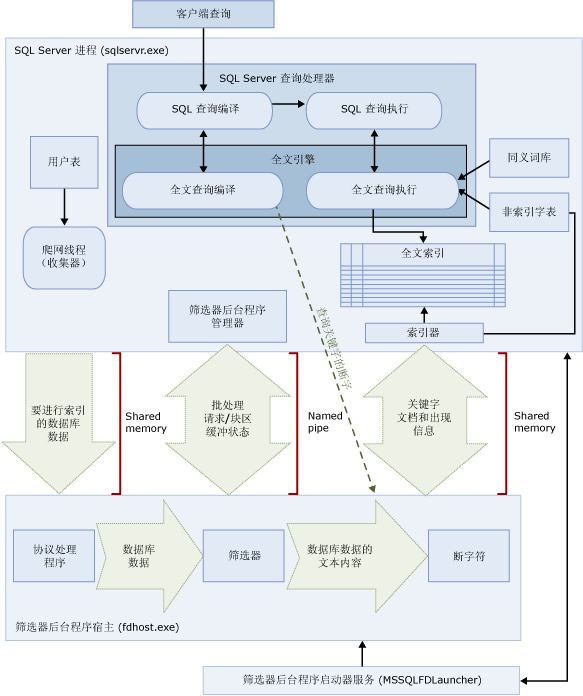
SQL Server 进程
SQL Server 进程使用全文搜索的以下组件:
用户表。这些表包含要进行全文索引的数据。
全文收集器。全文收集器使用全文爬网线程。 它负责计划和驱动对全文索引的填充,并负责监视全文目录。
同义词库文件。这些文件包含搜索项的同义词。 有关详细信息,请参阅为全文搜索配置和管理同义词库文件。
非索引字表对象。非索引字表对象包含对搜索无用的常见词列表。 有关详细信息,请参阅为全文搜索配置和管理非索引字和非索引字表。
SQL Server 查询处理器。查询处理器编译并执行 SQL 查询。 如果 SQL 查询包含全文搜索查询,则在编译和执行期间该查询都会发送到全文引擎。 查询结果将与全文索引相匹配。
全文引擎。SQL Server 中的全文引擎与查询处理器完全集成。全文引擎编译并执行全文查询。 作为查询执行的一部分,全文引擎可能会接收来自同义词库和非索引字表的输入。
索引编写器(索引器)。索引编写器生成用于存储索引标记的结构。
筛选器后台程序管理器。筛选器后台程序管理器负责监视全文引擎筛选器后台程序宿主的状态。
筛选器后台程序宿主进程
筛选器后台程序宿主是一个由全文引擎启动的进程。 它运行下列全文搜索组件,这些组件负责对表中的数据进行访问、筛选和断字,
同时还负责对查询输入进行断字和提取词干。
筛选器后台程序宿主的组件如下:
协议处理程序。此组件从内存中取出数据,以进行进一步的处理,并访问指定数据库的用户表中的数据。
其职责之一是从全文索引列中收集数据,并将所收集的数据传递给筛选器后台程序宿主,从而由该宿主根据需要应用筛选和断字符。
筛选器。某些数据类型需要筛选,然后才能为文档中的数据(包括 varbinary、varbinary(max)、image 或 xml 列中的数据)创建全文索引。 给定文档采用何种筛选器取决于文档类型。 例如,Microsoft Word (.doc) 文档、Microsoft Excel (.xls) 文档和 XML (.xml)
文档分别使用不同的筛选器。 然后,筛选器从文档中提取文本块区,删除嵌入的格式并保留文本,
如有可能的话也会保留有关文本位置的信息。 结果将以文本化信息流的形式出现。 有关详细信息,请参阅配置和管理搜索筛选器。
断字符和词干分析器。断字符是特定于语言的组件,它根据给定语言的词汇规则查找词边界(“断字”)。
每个断字符都与用于组合动词及执行变形扩展的特定于语言的词干分析器组件相关联。 在创建索引时,
筛选器后台程序宿主使用断字符和词干分析器来对给定表列中的文本数据执行语言分析。
与全文索引中的表列相关的语言将决定为列创建索引时要使用的断字符和词干分析器。
有关详细信息,请参阅配置和管理断字符和词干分析器以便搜索。
全文搜索处理
全文搜索由全文引擎提供支持。
全文引擎有两个角色:索引支持和查询支持。
全文索引过程 全文填充(也称为爬网)开始后,全文引擎会将大批数据存入内存并通知筛选器后台程序宿主。
宿主对数据进行筛选和断字,并将转换的数据转换为倒排词列表。 然后,全文搜索从词列表中提取转换的数据, 对其进行处理以删除非索引字,
然后将某一批次的词列表永久保存到一个或多个倒排索引中。 对存储在 varbinary(max) 或 image 列中的数据编制索引时,
筛选器(实现 IFilter 接口)将基于为该数据指定的文件格式 (例如,Microsoft Word)来提取文本。 在某些情况下,
筛选器组件要求将 varbinary(max) 或 image 数据写入 filterdata 文件夹中 ,而不是将其存入内存。
在处理过程中,通过断字符将收集到的文本数据分隔成各个单独的标记或关键字。 用于词汇切分的语言将在列级指定,
或者也可以通过筛选器组件在 varbinary(max)、image 或 xml 数据内标识。 还可能会进行其他处理以删除非索引字,
并在将标记存储到全文索引或索引片断之前对其进行规范化。 填充完成后,将触发最终的合并过程,以便将索引片断合并为一个主全文索引。
由于只需要查询主索引而不需要查询大量索引碎片,因此这将提高查询性能,并且可以使用更好的计分统计信息来得出相关性排名。
全文查询过程
查询处理器将查询的全文部分传递到全文引擎以进行处理。 全文引擎执行断字,
此外, 它还可以执行同义词库扩展、词干分析以及非索引字(干扰词)处理。
然后,查询的全文部分以 SQL 运算符的形式表示, 主要作为流式表值函数 (STVF)。
在查询执行过程中,这些 STVF 访问倒排索引以检索正确结果。 此时会将结果返回给客户端,或者先将它们进一步处理,再将它们返回给客户端。
全文搜索中的语言组件和语言支持
全文搜索支持大约 50 种不同语言,例如英语、西班牙语、中文、日语、阿拉伯语、孟加拉语和印地语。
有关支持的全文语言的完整列表,请参阅 sys.fulltext_languages (Transact-SQL)。
全文索引中包含的每一列与一个 Microsoft Windows 区域设置标识符 (LCID) 相关联,
每个区域设置标识符等同于全文搜索支持的一种语言。 例如,LCID 1033 等于美国英语,
LCID 2057 等于英国英语。 对于每种支持的全文语言,SQL Server 提供语言组件以支持对以该语言存储的全文数据进行索引和查询。
语言特有组件包括:
断字符和词干分析器。断字符根据给定语言的词汇规则查找词边界(“断字”)。
每个断字符与一个词干分析器相关联,该词干分析器组合了同一种语言的动词。
有关详细信息,请参阅配置和管理断字符和词干分析器以便搜索。
非索引字表。提供系统非索引字表,该非索引字表包含一组基本非索引字(也称为干扰词)。
“非索引字”是对搜索没有任何帮助并且被全文查询忽略的词。 例如,在英语区域设置中,
诸如“a”、“and”、“is”和“the”之类的词都被视为非索引字。 通常情况下
,需要配置一个或多个同义词库文件和非索引字表。 有关详细信息,请参阅为全文搜索配置和管理非索引字和非索引字表。
同义词库文件。SQL Server 还会安装一个全局同义词库文件,并且还为每种全文语言安装一个同义词库文件。
安装的同义词库文件实际上是空的,不过可以编辑它们以便为特定语言或商业应用场景定义同义词。
通过开发针对全文数据定制的同义词库,您可以有效地扩大对这些数据的全文查询的范围。
有关详细信息,请参阅为全文搜索配置和管理同义词库文件。
筛选器 (iFilter。对 varbinary(max)、image 或 xml 数据类型列中的文档进行索引时,
需要使用筛选器来执行额外的处理工作。 此筛选器必须特定于文档类型(.doc、.pdf、.xls、.xml 等)。
断字符(和词干分析器)以及筛选器在筛选器后台程序宿主进程 (fdhost.exe) 中运行。
------------------------------------------------------------------------------------------------------------
全文搜索入门
http://msdn.microsoft.com/zh-cn/library/ms142497.aspx
SQL Server 中的数据库在默认情况下支持全文索引。
不过,若要对表使用全文索引,必须对要使用全文引擎访问的表列设置全文索引功能。
配置数据库以进行全文搜索。 对于任何应用场景,
数据库管理员都要执行以下基本步骤来将数据库中的表列配置为可以进行全文搜索: 创建全文目录。 在要搜索的每个表中,
按以下方法创建全文索引: 标识要包含在全文索引中的各个文本列。
如果给定列包含存储为二进制数据(varbinary(max) 或 image 数据)的文档, 您必须指定一个表列(“类型列”)以标识被索引的列中各文档的类型。
指定对列中文档进行全文搜索时所使用的语言。 选择全文索引中要使用的更改跟踪机制,以跟踪基表及其列中的更改。
全文搜索通过使用以下“语言组件”支持多种语言:断字符和词干分析器、 包含非索引字(也称为“干扰词”)的非索引字表及同义词库文件。
在某些情况下,同义词库文件和非索引字表需要由数据库管理员配置。
给定同义词库文件支持使用相应语言的所有全文索引,给定非索引字表可以根据您的需要与尽可能多的全文索引相关联。
设置全文目录和索引
这涉及以下基本步骤:
1、创建全文目录来存储全文索引。
每个全文索引必须属于一个全文目录。 您可以为每个全文索引创建一个单独的文本目录,也可以将多个全文索引与给定目录关联起来。
全文目录是虚拟对象,不属于任何文件组。 该目录是表示一组全文索引的逻辑概念。
2、对表或索引视图创建全文索引。
全文索引是一种特殊类型的基于标记的功能性索引,由全文引擎生成和维护。 若要对表或视图创建全文搜索,
则该表或视图必须具有唯一的、不可为 Null 的单列索引。 全文引擎需要使用此唯一索引将表中的每一行映射到一个唯一的可压缩键。
全文索引可以包括 char、varchar、nchar、nvarchar、text、ntext、image、xml、varbinary 和 varbinary(max) 列。
有关详细信息,请参阅创建和管理全文索引。
在了解如何创建全文索引之前,请务必考虑它们与普通 SQL Server 索引的不同之处。 下表列出了这些差异。
|
全文索引 |
普通 SQL Server 索引 |
|---|---|
|
每个表只允许有一个全文索引。 |
每个表允许有多个普通索引。 |
|
将数据添加到全文索引的操作称为“填充”,可以通过计划或特定请求来请求填充,也可以在添加新数据时自动填充。 |
当插入、更新或删除作为其基础的数据时自动更新。 |
|
在同一个数据库内分组为一个或多个全文目录。 |
不分组。 |
选择全文索引的选项
选择列语言 有关在选择列语言时要注意的事项的信息,请参阅创建全文索引时选择语言。
选择全文索引的文件组 生成全文索引是一个需要大量占用 I/O 的过程(它需要频繁地从 SQL Server 读取数据,然后将筛选后的数据传播到全文索引)。
最佳做法是将全文索引置于最适于最大程度地提高 I/O 性能的数据库文件组中,或者将全文索引置于另一个卷的其他文件组中。
如果您非常注重管理的方便性,建议您将表数据和所有关联的全文目录存储在同一文件组中。
出于性能的考虑,有时您可能需要将表数据和全文索引置于存储在不同卷上的不同文件组中,以便最大化 I/O 并行度。
将全文索引分配到全文目录
计划表的全文索引在全文目录中的位置非常重要。
建议将具有相同更新特征的表(如更改次数少的与更改次数多的,或者在一天中某个特定时段内频繁更改的表)关联在一起,并置于同一全文目录下。
通过设置全文目录填充计划,会使全文索引与表保持同步,且在数据库活动较多时不会对数据库服务器的资源使用产生负面影响。
将表分配到全文目录时,应考虑下列准则:
始终选择可用于全文唯一键的最小唯一索引。 (最好是 4 个字节、基于整数的索引。)这将显著减少文件系统中 Microsoft Search 服务所需要的资源。
如果主键较大(超过 100 个字节),可以考虑选择表中的另一个唯一索引(或创建另一个唯一索引)来作为全文唯一键。
否则,如果全文唯一键的大小超过所允许的最大值(900 个字节),全文填充将无法继续进行。
如果创建索引的表有数百万行,请将该表分配到其自身的全文目录。
考虑要进行全文索引的表中发生的更改量以及总行数。
如果要更改的总行数与上次全文填充期间表中出现的行数合起来达到了数百万行,请将该表分配到其自身的全文目录。
将非索引字表与全文索引关联
SQL Server 2008 引入了非索引字表。
“非索引字表”是非索引字(也称为“干扰词”)的列表。
非索引字表与每个全文索引相关联,因而该非索引字表中的词会应用于对该索引的全文查询。
默认情况下,系统非索引字表与新的全文索引相关联。
不过,您也可以创建和使用您自己的非索引字表。
有关详细信息,请参阅为全文搜索配置和管理非索引字和非索引字表。
例如,下面的 CREATE FULLTEXT STOPLIST Transact-SQL 语句可通过从系统非索引字表进行复制来创建名为 myStoplist3 的新全文非索引字表:
1 CREATE FULLTEXT STOPLIST myStoplist FROM SYSTEM STOPLIST; 2 GO
下面的 ALTER FULLTEXT STOPLIST Transact-SQL 语句可更改名为 myStoplist 的非索引字表,
首先为西班牙语添加词“en”,再为法语添加词“en”:
1 ALTER FULLTEXT STOPLIST MyStoplist ADD 'en' LANGUAGE 'Spanish'; 2 ALTER FULLTEXT STOPLIST MyStoplist ADD 'en' LANGUAGE 'French'; 3 GO
更新全文索引
与普通 SQL Server 索引一样,全文索引可以在相关表中的数据修改时自动更新。
这是默认行为。 另外,还可以手动或在预定的间隔更新全文索引。
由于填充全文索引可能极为耗费时间和资源,因此索引更新通常作为异步进程执行,该进程在后台运行,
在基表中进行修改后使全文索引保持最新。 在基表中进行每次更改后立即更新全文索引可能会占用大量的资源。
因此,如果更新/插入/删除操作非常频繁,您可能会发现查询性能有所降低。
如果出现这种情况,可以考虑制定一个手动的更改跟踪更新计划,以便按一定的间隔更新大量的更改,从而避免与查询争用资源。
若要监视填充状态,请使用 FULLTEXTCATALOGPROPERTY 或 OBJECTPROPERTYEX 函数。
若要获得目录填充状态,请运行以下语句:
1 SELECT FULLTEXTCATALOGPROPERTY('AdvWksDocFTCat', 'Populatestatus');
通常,如果正在进行完全填充,则返回的结果为 1。
示例:设置全文搜索
下面的示例由两部分组成, 首先对 AdventureWorks 数据库创建名为 AdvWksDocFTCat 的全文目录,
然后对 AdventureWorks2012 中的 Document 表创建全文索引。 此语句将在安装过程中指定的默认位置创建全文目录。
将在默认目录下创建名为 AdvWksDocFTCat 的文件夹。 为了创建名为 AdvWksDocFTCat 的全文目录,
此示例使用了 CREATE FULLTEXT CATALOG 语句:
1 USE AdventureWorks; 2 GO 3 CREATE FULLTEXT CATALOG AdvWksDocFTCat;
在对 Document 表创建全文索引之前,请确保该表具有唯一的、不可为 Null 的单列索引。
下面的 CREATE INDEX 语句可对 Document 表的 DocumentID 列创建唯一索引 ui_ukDoc:
1 CREATE UNIQUE INDEX ui_ukDoc ON Production.Document(DocumentID);
具有唯一键后,即可使用下面的 CREATE FULLTEXT INDEX 语句对 Document 表创建全文索引。
1 CREATE FULLTEXT INDEX ON Production.Document 2 ( 3 Document --Full-text index column name 4 TYPE COLUMN FileExtension --Name of column that contains file type information 5 Language 2057 --2057 is the LCID for British English 6 ) 7 KEY INDEX ui_ukDoc ON AdvWksDocFTCat --Unique index 8 WITH CHANGE_TRACKING AUTO --Population type; 9 GO
此示例中定义的 TYPE COLUMN 指定表中的类型列,该列包含“Document”列(为二进制类型)的每一行中文档的类型。
此类型列存储给定行中文档的、由用户提供的文件扩展名 —“.doc”、“.xls”等等。
全文引擎使用给定行中的文件扩展名调用正确的筛选器,以用于分析该行中的数据。
在该筛选器对该行的二进制数据进行分析后,指定的断字符将分析其内容(在此示例中,使用的是英国英语的断字符)。
请注意,仅在进行索引时,或者在对全文索引启用了自动更改跟踪的情况下用户在基表中插入或更新列时,
才会执行筛选过程。 有关详细信息,请参阅配置和管理搜索筛选器。
查看有关全文索引的信息
|
目录视图或动态管理视图 |
说明 |
|---|---|
|
对于全文索引引用的每个全文目录,返回与其对应的一行。 |
|
|
构成全文索引的每列都对应一行。 |
|
|
全文索引使用内部表(称为“全文索引片断”)来存储倒排索引数据。 可以使用此视图来查询有关这些片断的元数据。 在此视图中,每个全文索引片断在每个包含全文索引的表中各占一行。 |
|
|
表对象的每个全文索引对应一行。 |
|
|
返回有关指定表的全文索引内容的信息。 |
|
|
返回有关指定表的文档级全文索引内容的信息。 给定关键字可以出现在几个文档中。 |
|
|
返回有关当前正在进行的全文索引填充的信息。 |
1 USE [pratice] --使用了全文搜索的数据库 2 GO 3 4 5 --对于全文索引引用的每个全文目录,返回与其对应的一行。使用了多少个全文目录就会有多少行 6 SELECT * FROM sys.[fulltext_index_catalog_usages] 7 8 9 --构成全文索引的每列都对应一行。有哪些列应用了全文索引就会有多少行 10 SELECT * FROM sys.[fulltext_index_columns] 11 12 --全文索引使用内部表(称为“全文索引片断”)来存储倒排索引数据。 可以使用此视图来查询有关这些片断的元数据。 在此视图中,每个全文索引片断在每个包含全文索引的表中各占一行。 13 SELECT * FROM sys.fulltext_index_fragments 14 15 --表对象的每个全文索引对应一行。 16 SELECT * FROM sys.[fulltext_indexes] 17 18 --返回有关当前正在进行的全文索引填充的信息。 19 SELECT * FROM sys.[dm_fts_index_population] 20 21 --返回当前数据库支持的全文分词的语言 22 SELECT * FROM sys.[fulltext_languages]
-----------------------------------------------------------------------------------------
http://msdn.microsoft.com/zh-cn/library/ms142575.aspx
填充全文索引
创建和维护全文索引涉及使用称为“填充”(也称为“爬网”)的过程填充索引。
填充类型 SQL Server 支持以下填充类型:完全填充、基于更改跟踪的自动或手动填充和基于时间戳的增量式填充。
完全填充 在完全填充期间,为表或索引视图的所有行生成索引条目。 全文索引的完全填充为基表或索引视图的所有行生成索引条目。
默认情况下,一旦创建新的全文索引,SQL Server 便会对其进行完全填充。 但是,完全填充会占用相当多的资源。
因此,当在高峰期创建全文索引时,最佳做法通常是将完全填充推迟到非高峰时段, 当全文索引的基表非常大时更应如此。
不过,索引所属的全文目录在填充其所有全文索引之后才可使用。 若要创建全文索引而不立即填充它,
请在 CREATE FULLTEXT INDEX 语句中指定 CHANGE_TRACKING OFF, NO POPULATION 子句。
如果您指定 CHANGE_TRACKING MANUAL,全文引擎将使用语句。 SQL Server 将不填充新的全文索引,
直到您使用 START FULL POPULATION 或 START INCREMENTAL POPULATION 子句执行 ALTER FULLTEXT INDEX 语句。
有关详细信息,请参阅本主题后面的示例“A. 创建全文索引而不运行完全填充”和“B. 对表运行完全填充”。
基于更改跟踪的填充
或者,您可以在对全文索引进行初始完全填充之后使用更改跟踪对其进行维护。 将出现与更改跟踪关联的较小开销,因为 SQL Server 维护它用来跟踪自上次填充后对基表所做更改的表。 当使用更改跟踪时,SQL Server 维护基表或索引视图中已通过更新、删除或插入进行过修改的行的记录。 通过 WRITETEXT 和 UPDATETEXT 所做的数据更改不会反映到全文索引中,也不能使用更改跟踪方法拾取。
注意
对于包含 timestamp 列的表,可以使用增量填充。
如果在创建索引期间启用更改跟踪,则 SQL Server 将在新全文索引创建之后立即对其进行完全填充。 其后,将跟踪更改并将更改传播到全文索引。 有两类更改跟踪:自动(CHANGE_TRACKING AUTO 选项)和手动(CHANGE_TRACKING MANUAL 选项)。 自动更改跟踪为默认行为。
更改跟踪的类型确定全文索引的填充方式,如下所示:
自动填充
默认情况下,或者如果您指定 CHANGE_TRACKING AUTO,全文引擎将对全文索引使用自动填充。 完成首次完全填充之后,当修改基表中的数据时将跟踪更改并自动传播跟踪的更改。 不过,由于全文索引是在后台更新的,因此传播的更改可能不会立即反映到索引中。
设置使用自动填充的跟踪更改
1 --创建的时候 2 CREATE FULLTEXT INDEX ON Production.Document 3 ( 4 Document --Full-text index column name 5 TYPE COLUMN FileExtension --Name of column that contains file type information 6 Language 2057 --2057 is the LCID for British English 7 ) 8 KEY INDEX ui_ukDoc ON AdvWksDocFTCat --Unique index 9 WITH CHANGE_TRACKING AUTO --Population type; 10 GO 11 ----------------------------------------------------- 12 --更改的时候 13 USE [pratice] 14 GO 15 ALTER FULLTEXT INDEX ON [dbo].[fulltext_test] SET CHANGE_TRACKING AUTO
有关详细信息,请参阅本主题后面的示例“E. 更改全文索引以使用自动更改跟踪”。
-----------------------------------------------------------------------
手动填充
如果您指定 CHANGE_TRACKING MANUAL,全文引擎将对全文索引使用手动填充。 完成首次完全填充之后,当修改基表中的数据时将跟踪更改。 但是,这些更改不会传播到全文索引,直至您执行 ALTER FULLTEXT INDEX … START UPDATE POPULATION 语句。 您可以使用 SQL Server 代理来定期调用此 Transact-SQL 语句。
启动使用手动填充的跟踪更改
1 --创建的时候 2 CREATE FULLTEXT INDEX ON Production.Document 3 ( 4 Document --Full-text index column name 5 TYPE COLUMN FileExtension --Name of column that contains file type information 6 Language 2057 --2057 is the LCID for British English 7 ) 8 KEY INDEX ui_ukDoc ON AdvWksDocFTCat --Unique index 9 WITH CHANGE_TRACKING MANUAL --Population type; 10 GO 11 ----------------------------------------------------- 12 --更改的时候 13 USE [pratice] 14 GO 15 ALTER FULLTEXT INDEX ON [dbo].[fulltext_test] SET CHANGE_TRACKING MANUAL
有关详细信息,请参阅本主题后面的示例“C. 使用手动更改跟踪创建全文索引”和“D. 运行手动填充”。
关闭更改跟踪
1 --创建的时候 2 CREATE FULLTEXT INDEX ON Production.Document 3 ( 4 Document --Full-text index column name 5 TYPE COLUMN FileExtension --Name of column that contains file type information 6 Language 2057 --2057 is the LCID for British English 7 ) 8 KEY INDEX ui_ukDoc ON AdvWksDocFTCat --Unique index 9 WITH CHANGE_TRACKING OFF --Population type; 10 GO 11 ----------------------------------------------------- 12 --更改的时候 13 USE [pratice] 14 GO 15 ALTER FULLTEXT INDEX ON [dbo].[fulltext_test] SET CHANGE_TRACKING OFF
基于时间戳的增量填充
增量填充是手动填充全文索引的一种替代机制。
您可以对 CHANGE_TRACKING 设置为 MANUAL 或 OFF 的全文索引运行增量填充。
如果全文索引的第一个填充是增量填充,它将对所有行编制索引并使其等效于完全填充。
增量填充要求索引表必须具有 timestamp 数据类型的列。 如果 timestamp 列不存在,则无法执行增量填充。
对不含 timestamp 列的表请求增量填充会导致完全填充操作。
另外,如果影响表全文索引的任意元数据自上次填充以来发生了变化,则增量填充请求将作为完全填充来执行。
这包括更改任何列、索引或全文索引定义所引起的元数据更改。
SQL Server 使用 timestamp 列标识自上次填充后发生更改的行。
然后,增量填充在全文索引中更新上次填充的当时或之后添加、删除或修改的行。
如果对表进行大量插入操作,则使用增量填充会较使用手动填充有效。
在填充结束时,全文引擎将记录新的 timestamp 值。 该值是 SQL 收集器遇到的最大 timestamp 值。
以后再启动增量填充时,将会使用此值。
若要运行增量填充,请执行使用 START INCREMENTAL POPULATION 子句的 ALTER FULLTEXT INDEX 语句。
1 USE [pratice] 2 GO 3 ALTER FULLTEXT INDEX ON [dbo].[fulltext_test] START INCREMENTAL POPULATION
填充全文索引的示例
注意: 本节中的示例使用 AdventureWorks 示例数据库的 Production.Document 或 HumanResources.JobCandidate 表。
A.创建全文索引而不运行完全填充 以下示例对 AdventureWorks 示例数据库的 Production.Document 表创建全文索引。
该示例使用 WITH CHANGE_TRACKING OFF, NO POPULATION 来延迟初次完全填充。
1 USE [AdventureWorks] 2 GO 3 CREATE UNIQUE INDEX ui_ukDoc ON Production.Document(DocumentID); 4 GO 5 CREATE FULLTEXT CATALOG AW_Production_FTCat; 6 GO 7 CREATE FULLTEXT INDEX ON Production.Document 8 ( 9 Document --Full-text index column name 10 TYPE COLUMN FileExtension --Name of column that contains file type information 11 Language 1033 --1033 is LCID for the English language 12 ) 13 KEY INDEX ui_ukDoc 14 ON AW_Production_FTCat 15 WITH CHANGE_TRACKING OFF, NO POPULATION; 16 GO
B.对表运行完全填充
以下示例对 AdventureWorks 示例数据库的 Production.Document 表运行完全填充。
1 ALTER FULLTEXT INDEX ON Production.Document START FULL POPULATION;
C.使用手动更改跟踪创建全文索引
以下示例对 AdventureWorks 示例数据库的 HumanResources.JobCandidate 表创建全文索引,该全文索引将使用具有手动填充的更改跟踪。
1 USE AdventureWorks; 2 GO 3 CREATE UNIQUE INDEX ui_ukJobCand ON HumanResources.JobCandidate(JobCandidateID); 4 GO 5 CREATE FULLTEXT CATALOG ft AS DEFAULT; 6 GO 7 CREATE FULLTEXT INDEX ON HumanResources.JobCandidate(Resume) 8 KEY INDEX ui_ukJobCand 9 WITH CHANGE_TRACKING=MANUAL; 10 GO
D.运行手动填充
以下示例对 AdventureWorks 示例数据库的 HumanResources.JobCandidate 表的更改跟踪全文索引运行手动填充。
1 USE AdventureWorks; 2 GO 3 ALTER FULLTEXT INDEX ON HumanResources.JobCandidate START UPDATE POPULATION; 4 GO
E.更改全文索引以使用自动更改跟踪
以下示例更改 AdventureWorks 示例数据库的 HumanResources.JobCandidate 表的全文索引以使用自动填充的更改跟踪。
1 USE AdventureWorks; 2 GO 3 ALTER FULLTEXT INDEX ON HumanResources.JobCandidate SET CHANGE_TRACKING AUTO; 4 GO
创建或更改增量填充计划
在 SSMS 中创建或更改增量填充计划
在对象资源管理器中,展开服务器。
展开“数据库”,然后展开包含全文索引的数据库。
展开“表”。
右键单击对其定义了全文索引的表,选择“全文索引”,然后在“全文索引”上下文菜单中单击“属性”。 此时将打开“全文索引属性”对话框。
在“选择页”窗格中,选择“计划”。
使用此页可以创建或管理 SQL Server 代理作业的计划,该作业用于启动对全文索引基表或索引视图的表增量填充。
重要提示
如果基表或视图不包含 timestamp 数据类型的列,则执行完全填充。
选项如下所示:
若要创建新计划,请单击“新建”。
此时将打开“新建全文索引表计划”对话框,您可以在此对话框中创建计划。 若要保存计划,请单击“确定”。
重要提示
在退出“全文索引属性”对话框后,SQL Server 代理作业(对 database_name.table_name 启动增量填充)将与新计划相关联。 如果您针对该全文索引创建多个计划,则这些计划都将使用同一作业。
若要更改某个计划,请选择该计划并单击“编辑”。
此时将打开“新建全文索引表计划”对话框,您可以在此对话框中修改计划。
注意
有关修改作业的信息,请参阅修改作业。
若要删除某个计划,请选择该计划并单击“删除”。
单击“确定”。
排除全文填充(爬网)中的错误
如果在爬网期间发生了错误,全文搜索的爬网日志功能会创建并维护一个爬网日志,该日志是一个纯文本文件。
每个爬网日志都对应于某一个全文目录。
默认情况下,给定实例(此处为第一个实例)的爬网日志位于 %ProgramFiles%\Microsoft SQL Server\MSSQL11.MSSQLSERVER\MSSQL\LOG 文件夹中。
爬网日志文件遵循以下命名方案:
SQLFT<DatabaseID><FullTextCatalogID>.LOG[<n>]
<DatabaseID>
数据库的 ID。 <dbid> 是一个带有前导零的五位数。
<FullTextCatalogID>
全文目录 ID。 <catid> 是一个带有前导零的五位数。
<n>
是一个整数,指示同一全文目录现有的一个或多个爬网日志。
例如,SQLFT0000500008.2 是一个数据库 ID 为 5、全文目录 ID 为 8 的数据库爬网日志文件。
文件名结尾的 2 指示此数据库/目录对具有两个爬网日志文件。

1 2013-08-08 19:14:36.92 spid14s The full-text catalog monitor reported catalog "fulltext_test" (5) in database "pratice" (5) in REINITIALIZE state. This is an informational message only. No user action is required. 2 2013-08-08 19:14:36.92 spid16s Informational: Full-text Auto population initialized for table or indexed view '[pratice].[dbo].[fulltext_test]' (table or indexed view ID '622625261', database ID '5'). Population sub-tasks: 1.
-------------------------------------------------------------------------------
http://msdn.microsoft.com/zh-cn/library/ms142560.aspx
改进全文索引的性能
硬件资源(例如内存、磁盘速度、CPU 速度和计算机体系结构)会影响全文索引和全文查询的性能。
性能问题的常见原因 导致全文索引性能降低的主要原因是硬件资源的限制:
如果筛选器后台程序宿主进程 (fdhost.exe) 或 SQL Server 进程 (sqlservr.exe) 的 CPU 使用率接近 100%,
则 CPU 会成为瓶颈。 如果平均磁盘等待队列长度是磁盘头数量的两倍以上,则磁盘将成为瓶颈。
主要的解决方法是创建独立于 SQL Server 数据库文件和日志的全文目录。 将日志、数据库文件和全文目录分别放在不同的磁盘上。
购买运行速度更快的磁盘和使用 RAID 也能帮助改善索引性能。
如果物理内存不足(3GB 限制),则内存可能是瓶颈。
物理内存限制可能存在于所有系统上,而在 32 位系统上,虚拟内存压力可导致全文索引速度降低。
注意
从 SQL Server 2008 开始,全文引擎可以使用 AWE 内存,因为全文引擎是 sqlservr.exe 的一部分。
----------------------------------------------------------------
如果系统没有硬件瓶颈,则全文搜索的索引性能主要取决于以下因素:
(1)SQL Server 创建全文批次花费的时间。
(2)筛选器后台程序能以多快的速度处理这些批次。
注意
与完全填充不同,增量、手动和自动更改跟踪填充的设计目的并不是为了最大程度地利用硬件资源以获得更高速度。
因此,这些优化建议可能不会增强全文索引的性能。
填充完成后,将触发最终的合并过程,以便将索引碎片合并为一个主全文索引。 由于只需要查询主索引而不需要查询大量索引碎片,
因此这将提高查询性能,并且可以使用更好的计分统计信息来得出相关性排名。 请注意,由于合并索引碎片时必须读取和写入大量数据
,所以主合并可能会耗费大量 I/O,但它不会阻塞传入的查询。
重要提示
对大量数据进行主合并会创建一个长时间运行的事务,在检查点期间延迟事务日志的截断。 在这种情况下,事务日志可能会在完整恢复模式下显著增长。
作为最佳做法,在使用完整恢复模式的数据库中重新组织较大的全文索引之前,应确保事务日志中包含足够的空间用于长时间运行的事务。
有关详细信息,请参阅管理事务日志文件的大小。
优化全文索引的性能
若要最大限度地提高全文索引的性能,请实施下列最佳做法:
若要最大程度地使用所有处理器或内核,请将 sp_configure ‘max full-text crawl ranges’ 设置为系统的 CPU 数。
1 EXEC [sys].[sp_configure] 'show advanced options', 1; 2 GO 3 RECONFIGURE; 4 GO 5 6 EXEC [sys].[sp_configure] 'max full-text crawl range', 4 7 GO 8 RECONFIGURE; 9 GO
有关该配置选项的信息,请参阅 max full-text crawl range 服务器配置选项。
请确保基表具有聚集索引。 对聚集索引的第一列使用整数数据类型。 避免在聚集索引的第一列使用 GUID。
对聚集索引执行多范围填充可以产生最高的填充速度。 我们建议充当全文键的列采用整数数据类型。
使用 UPDATE STATISTICS 语句更新基表的统计信息。 更重要的是,更新聚集索引或全文键的统计信息以进行完全填充。
这有助于多范围填充在表上生成良好的分区。
如果要提高增量填充的性能,请对 timestamp 列生成辅助索引。
在大型多 CPU 计算机上执行完全填充之前,建议您通过设置 max server memory 值来暂时限制缓冲池的大小,从而留出足够的内存供 fdhost.exe 进程及操作系统使用。 有关详细信息,请参阅本主题后面的“估计筛选器后台程序宿主进程 (fdhost.exe) 的内存需求量”。
解决完全填充性能问题
若要诊断性能问题,请查看全文爬网日志。 有关爬网日志的信息,请参阅填充全文索引。
如果对完全填充的性能不满意,则建议按顺序执行以下故障排除步骤。
物理内存使用量
在全文填充期间,fdhost.exe 或 sqlservr.exe 的内存有可能不足。
如果全文爬网日志显示 fdhost.exe 正在反复重新启动,或系统返回错误代码 8007008,则意味着这些进程中的某一个进程内存不足。
如果 fdhost.exe 在生成转储(特别是在大型多 CPU 计算机上),则该进程的内存可能不足。
注意
若要获得有关全文爬网所用的内存缓冲区的信息,请参阅 sys.dm_fts_memory_buffers (Transact-SQL)。
1 SELECT * FROM sys.dm_fts_memory_buffers
可能的原因如下:
如果在完全填充期间可用的物理内存数量是零,则 SQL Server 缓冲池可能正占用系统的大部分物理内存。
sqlservr.exe 进程试图侵占缓冲池的所有可用内存(最大为配置的最大服务器内存)。 如果分配的 max server memory 过大,
fdhost.exe 进程可能会面临内存不足的状况及共享内存分配失败。
注意
在多 CPU 计算机上进行全文填充期间,fdhost.exe 或 sqlservr.exe 之间可能出现缓冲池内存争用。 由此造成的共享内存不足会导致批次重试、内存抖动并让
fdhost.exe 进程进行转储。
可以通过适当设置 SQL Server 缓冲池的 max server memory 值来解决此问题。
有关详细信息,请参阅本主题后面的“估计筛选器后台程序宿主进程 (fdhost.exe) 的内存需求量”。减小用于全文索引的批次大小可能也会有用。
分页问题
页文件大小不足也会导致 fdhost.exe 或 sqlservr.exe 的内存不足,例如在具有增长受限的较小页文件的系统上。
如果爬网日志未指示存在任何与内存相关的故障,则很可能是因为过度分页导致性能下降。
估计筛选器后台程序宿主进程 (fdhost.exe) 的内存需求量
进行填充时 fdhost.exe 进程需要的内存量主要取决于它使用的全文爬网范围数、入站共享内存 (ISM) 的大小以及最大 ISM 实例数。
可以使用下面的公式粗略估算筛选器后台程序宿主占用的内存量(以字节为单位):
number_of_crawl_ranges * ism_size * max_outstanding_isms * 2
上面公式中的变量的默认值如下所示:
|
变量 |
默认值 |
|---|---|
|
number_of_crawl_ranges |
CPU 的数目 |
|
ism_size |
x86 计算机为 1 MB x64 计算机为 4 MB、8 MB 或 16MB,具体取决于物理内存总量 |
|
max_outstanding_isms |
x86 计算机为 25 x64 计算机为 5 |
下表列出了有关如何估算 fdhost.exe 的内存需求量的准则。 此表中的公式使用以下值:
F,它是 fdhost.exe 所需内存的估计值 (MB)。
T,它是系统中可用物理内存的总量 (MB)。
M,这是最佳 max server memory 设置。
|
平台 |
估计 fdhost.exe 的内存需求量 (MB) - F1 |
用于计算最大服务器内存的公式 - M2 |
|---|---|---|
|
x86 |
F = Number of crawl ranges * 50 |
M = minimum ( T , 2000)–F– 500 |
|
x64 |
F = Number of crawl ranges * 10 * 8 |
M = T – F – 500 |
1 如果正在进行多个完全填充,则分别计算每个完全填充的 fdhost.exe 内存需求量,如 F1、F2 等等。 然后按照 T– sigma(Fi) 计算得到 M。
2 500 MB 是系统中其他进程所需内存的估计值。 如果系统正在执行其他工作,请相应地增加此值。
3 .ism_size 对于 x64 平台假定为 8 MB。
示例:估计 fdhost.exe 的内存需求量
此示例针对具有 8GM RAM 和 4 个双核处理器的 AMD64 计算机。 首先计算出 fdhost.exe 所需内存的估计值 F。 爬网范围数是 8。
F = 8*10*8=640
然后计算出 max server memory 的最佳值 M。 该系统的可用物理内存总量 (MB) T 是 8192。
M = 8192-640-500=7052
示例:设置最大服务器内存
此示例使用 sp_configure 和 RECONFIGURE Transact-SQL 语句将 max server memory 设置为上一个示例中计算得到的 M 值,即 7052。
1 USE master; 2 GO 3 EXEC sp_configure 'max server memory', 32767; 4 GO 5 RECONFIGURE; 6 GO
设置最大服务器内存配置选项
可以降低 CPU 占用率的因素
我们希望当平均 CPU 占用率低于大约 30% 时完全填充的性能不是最佳的。
本节讨论影响 CPU 占用率的一些因素。
长时间等待页面
若要了解等待页面的时间是否太长,请执行下面的 Transact-SQL 语句:
1 SELECT TOP 10 * FROM sys.dm_os_wait_stats ORDER BY wait_time_ms DESC;
下表描述了这里需要了解的等待类型。
|
等待类型 |
说明 |
可能的解决方法 |
|---|---|---|
|
PAGEIO_LATCH_SH(_EX 或 _UP) |
这可能表明存在 IO 瓶颈,在此情况下通常还会发现平均磁盘队列长度很高。 |
将全文索引移动到其他磁盘上的其他文件组可能有助于减少 IO 瓶颈。 |
|
PAGELATCH_EX(或 _UP) |
这可能表明多个正在试图写入相同数据库文件的线程之间存在大量争用现象。 |
将文件添加到全文索引所在的文件组可能有助于减轻此类争用。 |
扫描基表的效率很低
完全填充将扫描基表,以生成批次。 在下列情况下,这样的表扫描可能很低效:
如果基表有很高百分比的行外列正在建立全文索引,则扫描基表以生成批次可能成为瓶颈。
在这种情况下,使用 varchar(max) 或 nvarchar(max) 对较小的数据进行行内移动可能有用。
如果基表非常零碎,扫描可能很低效。
有关计算行外数据和索引碎片的信息,请参阅
sys.dm_db_partition_stats (Transact-SQL) 和 sys.dm_db_index_physical_stats (Transact-SQL)。
若要减少碎片,可以重新组织或重新生成聚集索引。 有关详细信息,请参阅重新组织和重新生成索引。
解决索引性能由于筛选器而变慢的问题
在填充全文索引时,全文引擎使用以下两种类型的筛选器:多线程筛选器和单线程筛选器。
有些文档(如 Microsoft Word 文档)使用多线程筛选器进行筛选。 另外一些文档使用单线程筛选器进行筛选,
如 Adobe Acrobat 可移植文档格式 (PDF) 文档。
为了安全起见,筛选器是由筛选器后台程序主机进程加载的。 服务器实例对所有多线程筛选器使用多线程进程,并对所有单线程筛选器使用单线程进程。
如果使用多线程筛选器的文档包含使用单线程筛选器的嵌入文档,全文引擎将启动单线程进程以处理嵌入文档。
例如,在遇到包含 PDF 文档的 Word 文档时,全文引擎使用多线程进程来处理 Word 内容,并启动单线程进程以处理 PDF 内容。
但是,单线程筛选器可能无法在此环境中正常工作,并且可能会破坏筛选进程的稳定性。 在某些频繁出现此类嵌入的环境中,它可能会导致筛选进程崩溃。
如果发生这种情况,全文引擎会将任何失败的文档(如包含嵌入 PDF 内容的 Word 文档)重新传送到单线程筛选进程。
如果频繁进行重新传送,将会导致全文索引进程性能下降。
若要解决该问题,必须将容器文档(此处为 Word 文档)的筛选器标记为单线程筛选器。 可以更改筛选器注册表值,以便将给定筛选器标记为单线程筛选器。
若要将筛选器标记为单线程筛选器,您需要将筛选器的 ThreadingModel 注册表值设置为 Apartment Threaded。
有关单线程单元的信息,请参阅白皮书了解和使用 COM 线程模型。
-----------------------------------------------------------------------------------------------------------------------
http://msdn.microsoft.com/zh-cn/library/cc879261(v=SQL.105).aspx
全文索引属性(“列”页)
查看或更改全文索引的属性
唯一索引 从下拉列表中选择索引。索引必须是唯一且不为 Null 的单键列索引。 选择将进行全文索引的合格列 此网格显示可用于此全文索引的表列。
已选中当前是全文索引的列。或者,可以选中要成为全文索引的其他列。
|
在单击“确定”之前,请确保至少选中一列。 |
|
可用列 |
列名称。 |
|
断字符语言 |
其断字符和词干分析器对所有全文索引数据执行语言分析的语言。 有关详细信息,请参阅断字符和词干分析器和创建全文索引时选择语言的最佳实践。 |
|
类型列 |
保留所选列的文档类型的表列的名称。此为只读属性。 |
------------------------------------------------------------------------------------------------------------------------------------------
http://msdn.microsoft.com/zh-cn/library/ms142505(v=SQL.105).aspx
全文索引的结构
对全文索引的结构的良好了解将帮助您了解全文引擎如何工作。 本主题使用 Adventure Works 中的 Document 表的以下摘录部分作为示例表。此摘录部分仅显示该表的两个列(DocumentID 列和 Title 列)和三行。 在下例中,我们假设已对 Title 列创建了全文索引。
|
DocumentID |
Title |
|---|---|
|
1 |
Crank Arm and Tire Maintenance |
|
2 |
Front Reflector Bracket and Reflector Assembly 3 |
|
3 |
Front Reflector Bracket Installation |
例如,下表(显示 Fragment 1)描述对 Document 表的 Title 列创建的全文索引的内容。
与该表呈现的信息相比,全文索引包含更多信息。该表是全文索引的逻辑表示形式,并且仅为演示目的提供。
行以压缩格式存储,以优化磁盘的使用。
注意,数据已从原始文档倒排。发生数据倒排是因为关键字映射到文档 ID。因此,全文索引通常称为倒排索引。
还要注意,已从全文索引中删除关键字“and”。这样做是因为“and”是非索引字,从全文索引中删除非索引字可以大幅节省磁盘空间,并因此提高查询性能。
SQL2008开始引入非索引字
将非索引字表与全文索引关联
SQL Server 2008 引入了非索引字表。 “非索引字表”是非索引字(也称为“干扰词”)的列表。 非索引字表与每个全文索引相关联,因而该非索引字表中的词会应用于对该索引的全文查询。
有关非索引字的详细信息,请参阅非索引字和非索引字表。
Fragment 1
|
Keyword |
ColId |
DocId |
Occurrence |
|---|---|---|---|
|
Crank |
1 |
1 |
1 |
|
Arm |
1 |
1 |
2 |
|
Tire |
1 |
1 |
4 |
|
Maintenance |
1 |
1 |
5 |
|
Front |
1 |
2 |
1 |
|
Front |
1 |
3 |
1 |
|
Reflector |
1 |
2 |
2 |
|
Reflector |
1 |
2 |
5 |
|
Reflector |
1 |
3 |
2 |
|
Bracket |
1 |
2 |
3 |
|
Bracket |
1 |
3 |
3 |
|
Assembly |
1 |
2 |
6 |
|
3 |
1 |
2 |
7 |
|
Installation |
1 |
3 |
4 |
Keyword 列包含在创建索引时提取的单个标记的表示形式。断字符可确定组成标记的词。
ColId 列包含的值对应于已建立全文索引的特定列。
DocId 列包含八字节整数的值,该值映射到全文索引表中特定的全文键值。如果全文键不是整数数据类型,则需要此映射。
在这样的情况下,全文键值与 DocId 值之间的映射将保留在一个称为 DocId Mapping 表的单独表中。若要查询这些映射,
请使用 sp_fulltext_keymappings 系统存储过程。若要满足搜索条件,则上述表中的 DocId 值需要与 DocId Mapping 表联接,
以便从所查询的基表中检索行。如果基表的全文键值是整数类型,则该值直接充当 DocId,而不需要映射。
因此,使用整数全文键值有助于优化全文查询。
Occurrence 列包含整数值。对于每个 DocId 值,均有一个 Occurrence 值的列表对应于该 DocId 值中特定关键字的相对字偏移量。
位置值用于确定短语或邻近匹配项,例如具有相邻位置值的短语。它们还用于计算相关性分数,例如记分时可能会用某个关键字在 DocId 中的出现次数。
全文索引碎片
逻辑全文索引通常拆分到多个内部表中。每个内部表称为一个全文索引碎片。
这些碎片中的某一些可能包含比其他碎片更新的数据。例如,如果用户更新其 DocId 是 3 的以下行,并且该表可自动跟踪更改,
则会创建新的碎片。
|
DocumentID |
Title |
|---|---|
|
3 |
Rear Reflector |
在下面的示例(显示 Fragment 2)中,碎片中包含比 Fragment 1 中更新的关于 DocId 3 的数据。
因此,当用户查询“Rear Reflector”时,会将 Fragment 2 中的数据用于 DocId 3。
每个碎片都用一个创建时间戳来标记,可以使用 sys.fulltext_index_fragments 目录视图查询该时间戳。
Fragment 2
|
Keyword |
ColId |
DocId |
Occ |
|---|---|---|---|
|
Rear |
1 |
3 |
1 |
|
Reflector |
1 |
3 |
2 |
从 Fragment 2 可以看到,全文查询需要在内部查询每个碎片,并放弃更旧的条目。因此,全文索引中太多的全文索引碎片会导致查询性能大幅下降。
若要减少碎片数,请使用 ALTER FULLTEXT CATALOGTransact-SQL 语句的 REORGANIZE 选项来重新组织全文目录。
此语句将执行一次“主合并”,主合并将碎片合并成一个更大的碎片,并从全文索引中删除所有过时的条目。
1 ALTER FULLTEXT CATALOG fulltext_test REORGANIZE 2 GO
经过重新组织后,示例索引会包含以下行:
|
Keyword |
ColId |
DocId |
Occ |
|---|---|---|---|
|
Crank |
1 |
1 |
1 |
|
Arm |
1 |
1 |
2 |
|
Tire |
1 |
1 |
4 |
|
Maintenance |
1 |
1 |
5 |
|
Front |
1 |
2 |
1 |
|
Rear |
1 |
3 |
1 |
|
Reflector |
1 |
2 |
2 |
|
Reflector |
1 |
2 |
5 |
|
Reflector |
1 |
3 |
2 |
|
Bracket |
1 |
2 |
3 |
|
Assembly |
1 |
2 |
6 |
|
3 |
1 |
2 |
7 |
跟MySQL一样,删除了某些分词信息之后,需要重新组织,以免索引文件越来越大
mysql>SET GLOBAL innodb_optimize_fulltext_only=1;
mysql>OPTIMIZE TABLE test.fts_a;
mysql>select * from INNODB_FT_DELETED;
mysql>select * from INNODB_FT_BEING_DELETED;
《mysql技术内幕innodb存储引擎》P239
innodb1.2.x版本
每张表只能有一个全文索引
多列组合的全文索引,每个列要有相同字符集和排序规则
不支持中文,日语,韩语
--下列 T-SQL 指令碼示範查詢全文檢索索引狀態以及其內容。
SELECT * FROM sys.dm_fts_index_population
SELECT * FROM sys.dm_fts_index_keywords( DB_ID('tde'), OBJECT_ID('SalesLT.Product'))

http://blogs.technet.com/b/technet_taiwan/archive/2015/06/02/sql-database-new-features-tde-and-full-text-search.aspx
全文索引限制:
(1)全文索引可对char、varchar、nchar、nvarchar、text、ntext、image、xml、varbinary 或 varbinary(max) 类型字段进行检索
(2)一个表只能建立一个全文索引(但可以对多个字段)
(3)全文索引的列必须是not null和唯一的
全文索引使用内部表(称为“全文索引片断”)来存储倒排索引数据。 可以使用此视图来查询有关这些片断的元数据。 在此视图中,每个全文索引片断在每个包含全文索引的表中各占一行。.
填充的方式有3种:1、完全填充,2、增量填充,3、自动跟踪更改
f


f

f

f

f

sql2008 的全文索引现在是存储在数据库中
全文索引基于CHAR/VARCHAR/NVARCHAR/XML/VARBINARY
提供了50个筛选器
全文索引使用语言特有的断字符word breaker 和词干分析器stemmer
指定具体语言,单词之间的breaker
被排除在常用单词(字)外面的单词(字)称为干扰词stop word,通过指定干扰词避免大量根本算不上关键字的单词(字)所干扰
一个表/索引视图只能有一个全文索引
stemmer
n. 抽梗机,除梗器;抽梗工人
f

f

f

f

f
全文索引填充不是即时完成的,因为数据必须提交给索引引擎,再由索引引擎应用断字符,词干分析器,语言文件,干扰词列表stop lists,最后才将更改合并到索引 merge到索引
语言规范决定了由全文索引引擎需要加载的断字符和词干分析器
SQL2008有第三方断字符和词干分析器
断字符还能识别数据中的单词之间的距离,这种接近性(proximity)添加到全文数据中,mysql的全文也有近似性,这是全文索引的独有功能,like%%是做不到的
sqlserver使用词干分析器来识别关键词的各种形式变化
f
f

f

f

f

f

f

f

全文谓词(全文搜索关键词)提交给全文索引引擎,全文索引引擎利用断字符word breaker标记搜索关键词,加token,将数据返回给优化器
where后面的谓词,如果不是全文,就叫谓词,如果是全文就是全文谓词
language参数指定是,是哪一个国家语言
优化器不能通过参数嗅探来计算全文索引上的分别统计数据,为了获得最佳性能必须给全文搜索的所有关键字都是Unicode类型
同义词文件
f
f

f

f

f

f

f

f

f

f

f

f
创建同义词XML文件
添加干扰词列表
重建全文索引
干扰词列表stop list或noise word file
如果你在一个全文谓词中提交的参数是干扰词,查询不会返回任何结果(而且他根本不需要访问底层数据)
sql2005和更早版本在FTDATA文件夹下配置干扰词文件,sql2008的干扰词列表存放在sqlserver的一个数据库中
增量填充全文索引必须要有一个时间戳
同义词和干扰词存放路径
C:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\FTData
C:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\FTData文件夹下只有两种文件:同义词和干扰词存
干扰词列表stop list或noise word file或stop word
全文关键术语

f

f

f
f

 浙公网安备 33010602011771号
浙公网安备 33010602011771号