ELK系列~对fluentd参数的理解
这段时候一直在研究ELK框架,主要集成在对fluentd和nxlog的研究上,国内文章不多,主要看了一下官方的API,配合自己的理解,总结了一下,希望可以帮到刚入行的朋友们!
Fluentd(日志收集与过滤,server)
<source> @type tcp tag pilipa format none port 24224 bind 0.0.0.0 </source> <filter docker.**> type parser format json time_format %Y-%m-%dT%H:%M:%S.%L%Z key_name log reserve_data true </filter> <match **> @type stdout </match> </ROOT>
Source节点
source主要是配置一个TCP,格式为所有,端口为默认的24224,绑定主机为自己IP的服务,它对应的客户端就要是TCP的,我们的nxlog就是这种协议的,架构上说就是一个c/s结构,由nxlog负责把数据发到fluentd上面。
filter节点
filter就是过滤规则,当source.tag复合filter的规则时,就执行这个filter进行过滤行为
match是fluentd收到数据后的处理, @type stdout是指在控制台输出,而我们生产环境把它输出到了elasticsearch上面( @type elasticsearch),处理的格式是json,如果在进行parser.json失败后,数据就不会正常的写入指定的数据表了,当然你可以把异常的数据存储到elasticsearch的其它表里。
自己在实践中总结的地方:
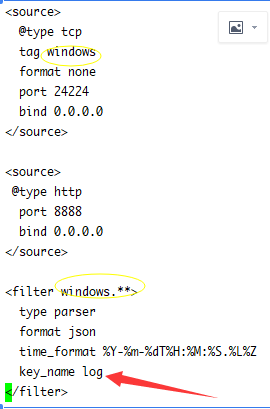
source里类型为@tcp类型时,它的tag是很重要的,我们的程序需要提供这个tag,当然如果你指定了端口,那这个tag就是当前端口的,而filter要根据这个tag去匹配自己,比如windows的tag,它会找以windows开头的fitler。
filter里的key_name,对应客户端发送消息时的主属性名称,有的是log,有的是message,有的是msg,像nxlog这种客户端它在使用tcp时key)name是message,下面说几种情况:
1 匹配了filter但没有找到key_name会有下面提示

2 没有任务key_name,会在结尾出现\r符号,我们需要去自己在output里过滤它,否则json转换失败

3 找到了对应的key_name

感谢各位的阅读!
希望本文章可以帮您快速的解决问题!
作者:仓储大叔,张占岭,
荣誉:微软MVP
QQ:853066980
支付宝扫一扫,为大叔打赏!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号