
递归函数的设计--以二叉树查找为例
工作后发现,大学计算机课程里面的树结构相当有用,很多现实中的东西把它看成树就容易理解多了。
----大学舍友
最近和二叉树有关的代码频繁地打交道。由于函数的递归实现占用巨大的计算机运行时间(尤其是深层递归调用,存储函数参数的程序栈会占据很大的运行时间,参见图1),我的目的是将递归实现改为非递归的循环实现(以前的编程经验表明,两者的运行速度相差悬殊)。本文以二叉树查找为例,对递归函数的设计进行分析说明,最后给出查找的非递归实现思路。
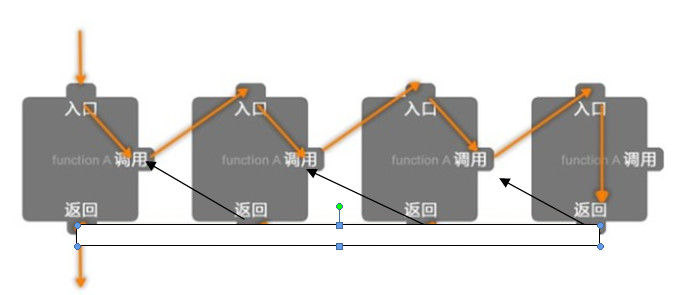
图1. 递归调用示意图
递归,就是函数调用自身的一种方式[1]。定义就是上面这个样子的,实际函数的调用过程如图 1 所示[2]。在程序的具体实现过程中,还是有两个问题需要格外注意:一,函数调用自身,那么调用前和调用后的区别在哪里?点解,两者函数的参数不一样,进而导致程序处理的问题域不一样。二,递归调用什么时候结束?点解,要在程序中针对每一种模式(下文将介绍)进行设计,避免程序陷入到死循环中。
具体到二叉树的查找实现上来。由于二叉树的查找基于遍历的方式来实现,教科书上关于遍历的方式大抵分为前序,中序和后序这三种方式进行讲解,并给出了伪代码。这里仅以前序方式为例进行说明(选择前序方式是基于两方面的原因:一,这种实现方式便于对递归函数的设计和理解;二,根据我的了解,后两种方式在编程实践中的使用貌似不多,只是提供理论上的一种实现方式)。基于前序的二叉树查找的伪代码如下:
Search() {
if(当前节点非空) {
1. 遍历当前节点。相应的退出条件为:验证其是否符合查找要求,如果符合,则退出
2. 遍历其左子树,调用Search()函数
3. 遍历其右子树,调用Search()函数
}
}
如前所述,遍历其左右子树分别需要将左子树和右子树作为Search()的函数参数传递进去,程序从根节点开始一层一层向下查找。另外,构造出来的二叉树有的时候常常不是完全二叉树,因此需要判断当前节点的左右子树是否为空,如果其中一个为空,那么就直接在另外一个子树中进行查找,如果两个都为空而当前节点又不符合查找要求,则退出。如下图所示,它给出了当前节点的五种模式[3],参见图2,它们分别是空树,当前节点没有左右子树,当前节点有左子树没有右子树,当前节点有右子树没有左子树,当前节点既有左子树又有右子树,在程序设计中要对这些方式都要考虑到。
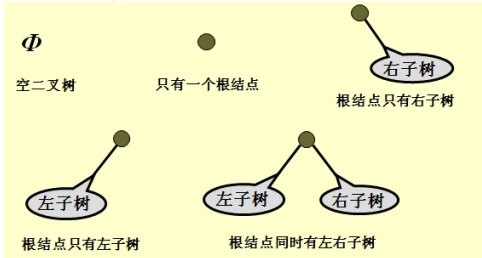
图2. 二叉树节点的五种模式
其实,在设计基于二叉树算法的时候,只要将一个节点的五种模式考虑清楚基本就可以大功告成了。原因是递归调用是不断地向下一层调用的方式,即考虑某个节点后,紧接着考虑它的左右子树,而左右子树又属于五种情形之一,当然可以用相同的函数来执行了。
回到开头的问题,如何将递归调用改为非递归实现?可以根据二叉树的层次来用for循环表示,或者直接使用while循环判断节点是否为空来实现,这样就可以避免递归调用了。不过,相应的函数需要进行修改,伪代码如下(以for循环为例):
for(int i=1; i<total_level+1;++i) {
if(treeNode == NULL) {
return;
}
if(i == 1) {
if(data not in treeNode)
return;
}
successful = Search(data, treeNode);
if(successful ) {
break;
}
if (left_child !=NULL && data in left_child) {
treeNode = treeNode->left_child;
continue;
}
if (right_child !=NULL && data in right_child) {
treeNode = treeNode->right_child;
continue;
}
}
需要注意的是,上述代码建立在这样的假设之上,即在搜索的过程中,当判断出 data 在某个节点所在的子树下时,要保证 data 在这个子树下能够被 Search 到。否则,程序很可能不能正确地 Search 到相应的节点。
参考资料:
[1] http://baike.baidu.com/link?url=iJRpWUn-ez1s08MrNWyGoUPhVs21ijt0ynHRHUkEFN1hc67kXm5RkmA9SExU7i6TmtjbWaqhHt5DOEp8vTcD5gs5IJ9rnkKyeMwU8Pm4a1m
[2] https://www.zhihu.com/question/20507130
[3] http://www.tuicool.com/articles/ERni22
作者:caicailiu 出处:http://www.cnblogs.com/liuyc/ 欢迎转载或分享,但请务必声明文章出处。
posted on 2016-12-18 22:51 caicailiu 阅读(1097) 评论(0) 编辑 收藏 举报

