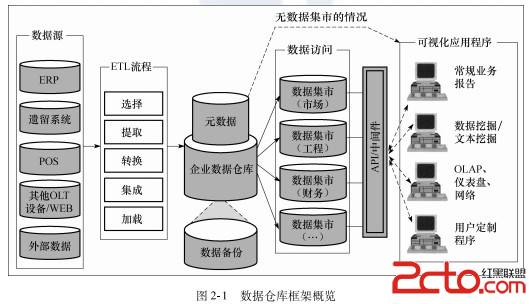
数据集市层——论为什么随着技术分析的深入,决策数据报表问题越来越多
一、前言
当前大数据概念特别流行,其中根据数据做决策,根据数据做分析已经成为每个公司必备的能力。
二、数据抽取
随之组建数据技术团队也顺理成章的事情,数据团队从业务数据库抽取数据到自己的分析数据库,这个过程称之为:数据抽取,原因如下:
- 能将数据从业务数据库中转移出来,所以在需要总体分析数据时就与业务处理性能不发生冲突。
- 当用抽取程序将数据从业务处理范围内移出时,数据的控制方式就发生了转变,处理数据更方便
三、自然演化体系结构
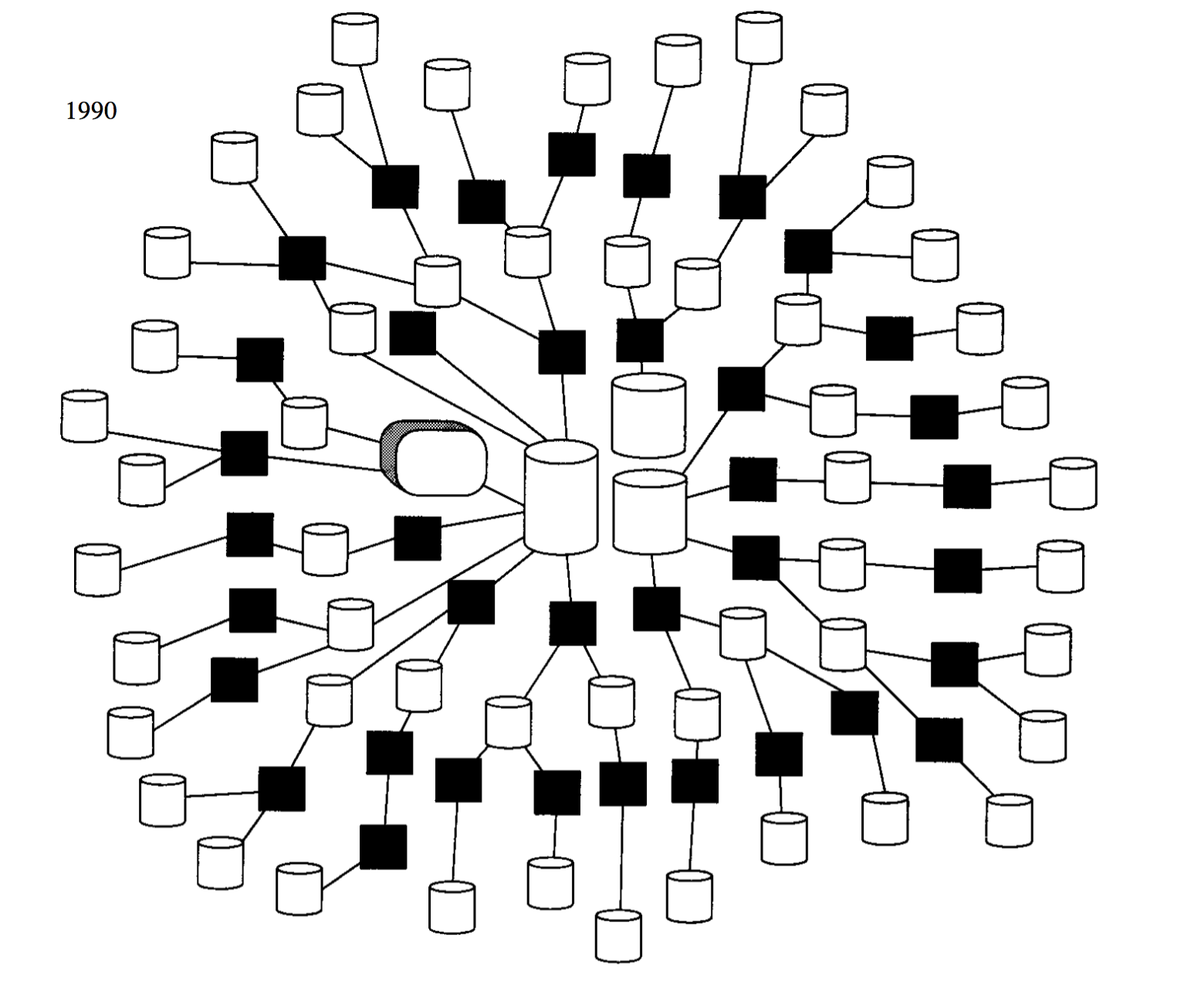
随着需求的不断增加,对抽取的要求越来越多,甚至逐步失控,这个过程叫:自然演化体系结构,俗称蜘蛛网,如图:
四、数据问题
如果按照类似的情况发展,逐渐产生如下弊端:
- 数据可信性差
- 生产率逐步下降
4.1 数据可信性差
问题之首便是数据可信性差。比如两个人像管理者呈送报表,一个人说业绩下降了5%,另一个人说业绩上升了2%,两个人的结论不吻合,工作很难协调。试想管理者看见两份报表的心情,只能根据政策和个人想法做决定,具体的原因是如下四点:
- 数据处理时间不一样:这个非常容易理解,有的数据是早晨3点抽取的,有的数据是9点抽取的,做出的报表必然有差异。有人可能说如果是离线的昨天的数据,在报表添加时间限制就可以了,但是实际情况是有些数据没有时间,我就经历过几次,比如抓取的竟对数据。
- 算法有差异:也称之为口径不一致。比如算新老用户,有人使用cookie做为区分,有人使用账号做为区分,甚至有人使用手机设备号码作为区分,结果自然不一致
- 抽取的层次不同:这个是前两个理由的扩展,每次的抽取盒算法上的差异,结果可能出现差异。对于一个总和结果来说,经过十几层抽取不是罕见的
- 外部数据问题:现在原始数据有多个来源不足为奇,比如获取手机推广渠道效果的数据,有人从公司技术部门获取数据,而另外一个人从数据库或者无线技术部门获取数据,结果必然有差异,本人曾经深受其扰
4.2 效率逐步下降
数据可信性差还是其中的一个问题,在自然演化体系结构中,生产率可能是逐步下降的,注意是逐步下降,不是开始就下降,这个一个痛苦的过程。设想一个数据系统已经运行了一段时间,这个时候管理者希望使用数年积累的数据产出一张综合决策报表,那么咱们首先要定位需要的数据,再分析分析数据。比如管理者需要最近几年本公司和竟对公司的产品对比数据,本公司有N个产品结果表,各取一部分,竟对数据更是如此,这就需要逐步筛选数据,是非常乏味的过程。筛选之后又要分析,由于结果表的可信性本来就有问题,分析结果校验的时候往往是层层出错,如察贪污受贿一样,一揭一串,相关人员都不得安宁,造成整个数据团队工作效率下降的现象。
五、问题
既然发现了这些问题,如何解决哪?其实这并不复杂,建立面向主题的数据集市层。当然就是要建立数据仓库,那么咱们更深入的理解这个过程与传统的分析过程的区别:(sdlc:系统生命周期,系统生存周期,是软件的产生直到报废的生命周期)

可见传统的生产过程是需求驱动的,来一个需求做一个报表;而数据仓库的生产过程正好相反,一旦数据到手,先集成数据,然后校验(校验的目的是为了在以后的开发过程中提升效率),理解需求之后,建立面向不同需求的数据,称之为面向主题的数据集市层。
六、数据集市层
数据集市(Data Mart) ,也叫数据市场,可以理解为字段非常多的宽表,比如销售表,出了包含订单和金额等必需的字段,还包含可能使用的产品信息集合、用户信息集合、甚至销售人员的信息,是数据仓库的核心组成部分。搭建好了面向主题的数据集市仓库之后,能非常有效的解决上面提出的若干问题:
1、提升数据准确性:因为建立面向主题的数据表之后,不用再根据需求的不同,建立不同的结果表,自然发生错误的几率会大大降低
2、提升效率:由于是面向主题的,所以需要的任何数据都可以从数据集市表直接简单产出
对比图如下: