
作业一 统计软件简介与数据操作
spss软件
所属类别 :
软件
SPSS(Statistical Product and Service Solutions),"统计产品与服务解决方案"软件。最初软件全称为"社会科学"(SolutionsStatistical Package for the Social Sciences),但是随着SPSS产品服务领域的扩大和服务深度的增加,SPSS公司已于2000年正式将英文全称更改为"统计产品与服务解决方案",标志着SPSS的战略方向正在做出重大调整。为IBM公司推出的一系列用于统计学分析运算、数据挖掘、预测分析和决策支持任务的软件产品及相关服务的总称SPSS,有Windows和Mac OS X等版本。
1984年SPSS总部首先推出了世界上第一个统计分析软件微机版本SPSS/PC+,开创了SPSS微机系列产品的开发方向,极大地扩充了它的应用范围,并使其能很快地应用于自然科学、技术科学、社会科学的各个领域。世界上许多有影响的报刊杂志纷纷就SPSS的自动统计绘图、数据的深入分析、使用方便、功能齐全等方面给予了高度的评价。
- 中文名称
统计产品与服务解决方案
- 外文名称
Statistical Product and Service Solutions
- 特 点
操作简单,编程简单,功能强大等
- 相关书籍
《SPSS其实很简单》《统计分析》
- 类 别
统计分析软件
- 语 言
英语
- 开发者
IBM公司
- 创始人
美国斯坦福大学的三位研究生
- 同类软件
Epi Info、SAS、Minitab
- 研发成功时间
1968年
- 平 台
ava
|
目录 |
1发展进程 2软件功能 3发展历史 4版本历史 |
5功能介绍 6产品特点 |
9软件平台 10相关图书 11其他相关 12同类软件 |
SPSS(Statistical Product and Service Solutions),"统计产品与服务解决方案"软件。最初软件全称为"社会科学统计软件包"(SolutionsStatistical Package for the Social Sciences),但是随着SPSS产品服务领域的扩大和服务深度的增加,SPSS公司已于2000年正式将英文全称更改为"统计产品与服务解决方案",标志着SPSS的战略方向正在做出重大调整。为IBM公司推出的一系列用于统计学分析运算、数据挖掘、预测分析和决策支持任务的软件产品及相关服务的总称SPSS,有Windows和Mac OS X等版本。
1984年SPSS总部首先推出了世界上第一个统计分析软件微机版本SPSS/PC+,开创了SPSS微机系列产品的开发方向,极大地扩充了它的应用范围,并使其能很快地应用于自然科学、技术科学、社会科学的各个领域。世界上许多有影响的报刊杂志纷纷就SPSS的自动统计绘图、数据的深入分析、使用方便、功能齐全等方面给予了高度的评价。
发展进程
SPSS是世界上最早的统计分析软件,由美国斯坦福大学的三位研究生Norman H. Nie、C. Hadlai (Tex) Hull 和 Dale H. Bent于1968年研究开发成功,同时成立了SPSS公司,并于1975年成立法人组织、在芝加哥组建了SPSS总部。
2009年7月28日,IBM公司宣布将用12亿美元现金收购统计分析软件提供商SPSS公司。如今SPSS已出至版本22.0,而且更名为IBM SPSS。迄今,SPSS公司已有40余年的成长历史。
折叠软件功能
SPSS是世界上最早采用图形菜单驱动界面的统计软件,它最突出的特点就是操作界面极为友好,输出结果美观漂亮。它将几乎所有的功能都以统一、规范的界面展现出来,使用Windows的窗口方式展示各种管理和分析数据方法的功能,对话框展示出各种功能选择项。用户只要掌握一定的Windows操作技能,精通统计分析原理,就可以使用该软件为特定的科研工作服务。SPSS采用类似EXCEL表格的方式输入与管理数据,数据接口较为通用,能方便的从其他数据库中读入数据。其统计过程包括了常用的、较为成熟的统计过程,完全可以满足非统计专业人士的工作需要。输出结果十分美观,存储时则是专用的SPO格式,可以转存为HTML格式和文本格式。对于熟悉老版本编程运行方式的用户,SPSS还特别设计了语法生成窗口,用户只需在菜单中选好各个选项,然后按"粘贴"按钮就可以自动生成标准的SPSS程序。极大的方便了中、高级用户。
SPSS图表制作SPSS for Windows是一个组合式软件包,它集数据录入、整理、分析功能于一身。用户可以根据实际需要和计算机的功能选择模块,以降低对系统硬盘容量的要求,有利于该软件的推广应用。SPSS的基本功能包括数据管理、统计分析、图表分析、输出管理等等。SPSS统计分析过程包括描述性统计、均值比较、一般线性模型、相关分析、回归分析、对数线性模型、聚类分析、数据简化、生存分析、时间序列分析、多重响应等几大类,每类中又分好几个统计过程,比如回归分析中又分线性回归分析、曲线估计、Logistic回归、Probit回归、加权估计、两阶段最小二乘法、非线性回归等多个统计过程,而且每个过程中又允许用户选择不同的方法及参数。SPSS也有专门的绘图系统,可以根据数据绘制各种图形。
SPSS for Windows的分析结果清晰、直观、易学易用,而且可以直接读取EXCEL及DBF数据文件,现已推广到多种各种操作系统的计算机上,它和SAS、BMDP并称为国际上最有影响的三大统计软件。在国际学术界有条不成文的规定,即在国际学术交流中,凡是用SPSS软件完成的计算和统计分析,可以不必说明算法,由此可见其影响之大和信誉之高。最新的21.0版采用DAA(Distributed Analysis Architecture,分布式分析系统),全面适应互联网,支持动态收集、分析数据和HTML格式报告。SPSS操作界面
SPSS输出结果虽然漂亮,但是很难与一般办公软件如Office或是WPS2000直接兼容,如不能用Excel等常用表格处理软件直接打开,只能采用拷贝、粘贴的方式加以交互。在撰写调查报告时往往要用电子表格软件及专业制图软件来重新绘制相关图表,这已经遭到诸多统计学人士的批评;而且SPSS作为三大综合性统计软件之一,其统计分析功能与另外两个软件即SAS和BMDP相比仍有一定欠缺。
虽然如此,SPSS for Windows由于其操作简单,已经在我国的社会科学、自然科学的各个领域发挥了巨大作用。该软件还可以应用于经济学、数学、统计学、物流管理、生物学、心理学、地理学、医疗卫生、体育、农业、林业、商业等各个领域。
折叠发展历史
1968年:斯坦福大学三位学生创建了SPSS
1968年:诞生第一个用于大型机的统计软件
1975年:在芝加哥成立SPSS总部
1984年:推出用于个人电脑的SPSS/PC+
1992年:推出Windows版本,同时全球自SPSS 11.0起,SPSS全称为"Statistical Product and Service Solutions",即"统计产品和服务解决方案"
2009年:SPSS公司宣布重新包装旗下的SPSS产品线,定位为预测统计分析软件(Predictive Analytics Software)PASW,包括四部分:
PASW Statistics (formerly SPSS Statistics):统计分析
PASW Modeler (formerly Clementine) :数据挖掘
Data Collection family (formerly Dimensions):数据收集
PASW Collaboration and Deployment Services (formerly Predictive Enterprise Services):企业应用服务
2010年:随着SPSS公司被IBM公司并购,各子产品家族名称前面不再以PASW为名,修改为统一加上IBM SPSS字样
折叠版本历史
- SPSS 15.0.1 - 2006年11月
- SPSS 16.0.2 - 2008年4月
- SPSS Statistics 17.0.1 - 2008年12月
- PASW Statistics 17.0.2 - 2009年3月
- PASW Statistics 17.0.3 - 2009年11月
- PASW Statistics 18.0.0 - 2009年8月
- PASW Statistics 18.0.1 - 2009年12月
- PASW Statistics 18.0.2 - 2010年4月
- PASW Statistics 18.0.3 - 2010年9月
- IBM SPSS Statistics 19.0 - 2010年8月
- IBM SPSS Statistics 20.0 - 2011年8月
- IBM SPSS Statistics 21.0 - 2012年8月
- IBM SPSS Statistics 22.0 - 2013年8月从被IBM收购之后,SPSS的更新都是一年一个版本,每年的8月中旬,总能见到。
折叠数据管理
在10版以后,SPSS的每个新增版本都会对数据管理功能作一些改进,以使用户的使用更为方便。13版中的改进可能主要有以下几个方面:
1)超长变量名:在12版中,变量名已经最多可以为64个字符长度,13版中可能还要大大放宽这一限制,以达到对当今各种复杂数据仓库更好的兼容性。
2)改进的Autorecode过程:该过程将可以使用自动编码模版,从而用户可以按自定义的顺序,而不是默认的ASCII码顺序进行变量值的重编码。另外,Autorecode过程将可以同时对多个变量进行重编码,以提高分析效率。
3)改进的日期/时间函数:本次的改进将集中在使得两个日期/时间差值的计算,以及对日期变量值的增减更为容易上。
折叠结果报告
从10版起,对数据和结果的图表呈现功能一直是SPSS改进的重点。在16版中,SPSS推出了全新的常规图功能,报表功能也达到了比较完善的地步。13版将针对使用中出现的一些问题,以及用户的需求对图表功能作进一步的改善。
1)统计图:在经过一年的使用后,新的常规图操作界面已基本完善,本次的改进除使得操作更为便捷外,还突出了两个重点。首先在常规图中引入更多的交互图功能,如图组(Paneled charts),带误差线的分类图形如误差线条图和线图,三维效果的简单、堆积和分段饼图等。其次是引入几种新的图形,已知的有人口金字塔和点密度图两种。
2)统计表:几乎全部过程的输出都将会弃用文本,改为更美观的枢轴表。而且枢轴表的表现和易用性会得到进一步的提高,并加入了一些新的功能,如可以对统计量进行排序、在表格中合并/省略若干小类的输出等。此外,枢轴表将可以被直接导出到PowerPoint中,这些无疑都方便了用户的使用。
折叠统计建模
Complex Samples是12版中新增的模块,用于实现复杂抽样的设计方案,以及对相应的数据进行描述。但当时并未提供统计建模功能。在13版中,这将会有很大的改观。一般线形模型将会被完整地引入复杂抽样模块中,以实现对复杂抽样研究中各种连续性变量的建模预测功能,例如对市场调研中的客户满意度数据进行建模。对于分类数据,Logistic回归则将会被系统的引入。这样,对于一个任意复杂的抽样研究,如多阶段分层整群抽样,或者更复杂的PPS抽样,研究者都可以在该模块中轻松的实现从抽样设计、统计描述到复杂统计建模以发现影响因素的整个分析过程,方差分析模型、线形回归模型、Logistic回归模型等复杂的统计模型都可以加以使用,而操作方式将会和完全随机抽样数据的分析操作没有什么差别。可以预见,该模块的推出将会大大促进国内对复杂抽样时统计推断模型的正确应用。
折叠模块
这个模块实际上就是将以前单独发行的SPSS AnswerTree软件整合进了SPSS平台。笔者几年前在自己的网站上介绍SPSS 11的新功能时,曾经很尖锐地指出SPSS的产品线过于分散,应当把各种功能较单一的小软件,如AnswerTree、Sample Power等整合到SPSS等几个平台上去。看来SPSS公司也意识到了这一点,而AnswerTree就是在此背景下第一个被彻底整合的产品。
Classification Tree模块基于数据挖掘中发展起来的树结构模型对分类变量或连续变量进行预测,可以方便、快速的对样本进行细分,而不需要用户有太多的统计专业知识。在市场细分和数据挖掘中有较广泛的应用。已知该模块提供了CHAID、Exhaustive CHAID和C&RT三种算法,在AnswerTree中提供的QUEST算法尚不能肯定是否会被纳入。
为了方便新老用户的使用,Tree模块在操作方式上不再使用AnswerTree中的向导方式,而是SPSS近两年开始采用的交互式选项卡对话框。但是,整个选项卡界面的内容实际上是和原先的向导基本一致的,另外,模型的结果输出仍然是AnswerTree中标准的树形图,这使得AnswerTree的老用户基本上不需要专门的学习就能够懂得如何使用该模块。
由于树结构模型的方法体系和传统的统计方法完全不同,贸然引入可能会引起读者统计方法体系的混乱。为此,本次编写的高级教程并未介绍该模块,而将在高级教程的下一个版本,以及关于市场细分问题的教材中对其加以详细介绍。
折叠兼容性
随着自身产品线的不断完善,SPSS公司的产品体系已经日益完整,而不同产品间的互补和兼容性也在不断加以改进。在13版中,SPSS软件已经可以和其他一些最新的产品很好的整合在一起,形成更为完整的解决方案。例如,SPSS、SPSS Data Entry和新发布的SPSS Text Analysis for Surveys一起就形成了对调查研究的完整解决方案。而新增的SPSS Classification Trees模块将使得SPSS软件本身就能够针对市场细分工作提供更为完整的方法体系。
折叠产品特点
折叠操作简便
界面非常友好,除了数据录入及部分命令程序等少数输入工作需要键盘键入外,大多数操作可通过鼠标拖曳、点击"菜单"、"按钮"和"对话框"来完成。
折叠编程方便
具有第四代语言的特点,告诉系统要做什么,无需告诉怎样做。只要了解统计分析的原理,无需通晓统计方法的各种算法,即可得到需要的统计分析结果。对于常见的统计方法,SPSS的命令语句、子命令及选择项的选择绝大部分由"对话框"的操作完成。因此,用户无需花大量时间记忆大量的命令、过程、选择项。
折叠功能强大
具有完整的数据输入、编辑、统计分析、报表、图形制作等功能。自带11种类型136个函数。SPSS提供了从简单的统计描述到复杂的多因素统计分析方法,比如数据的探索性分析、统计描述、列联表分析、二维相关、秩相关、偏相关、方差分析、非参数检验、多元回归、生存分析、协方差分析、判别分析、因子分析、聚类分析、非线性回归、Logistic回归等。
折叠数据接口
能够读取及输出多种格式的文件。比如由dBASE、FoxBASE、FoxPRO产生的*.dbf文件,文本编辑器软件生成的ASCⅡ数据文件,Excel的*.xls文件等均可转换成可供分析的SPSS数据文件。能够把SPSS的图形转换为7种图形文件。结果可保存为*.txt及html格式的文件。
折叠模块组合
SPSS for Windows软件分为若干功能模块。用户可以根据自己的分析需要和计算机的实际配置情况灵活选择。
折叠针对性强
SPSS针对初学者、熟练者及精通者都比较适用。并且很多群体只需要掌握简单的操作分析,大多青睐于SPSS,像薛薇的《基于SPSS的数据分析》一书也较适用于初学者。而那些熟练或精通者也较喜欢SPSS,因为他们可以通过编程来实现更强大的功能。
折叠spss主成分分析作用
主成分分析的主要原理是寻找一个适当的线性变换:spss
•将彼此相关的变量转变为彼此独立的新变量。
•方差较大的几个新变量就能综合反应原多个变量所包含的主要信息。
•新变量各自带有独特的专业含义。
主成分分析的作用是:
•减少指标变量的个数
•解决多重相关性问题
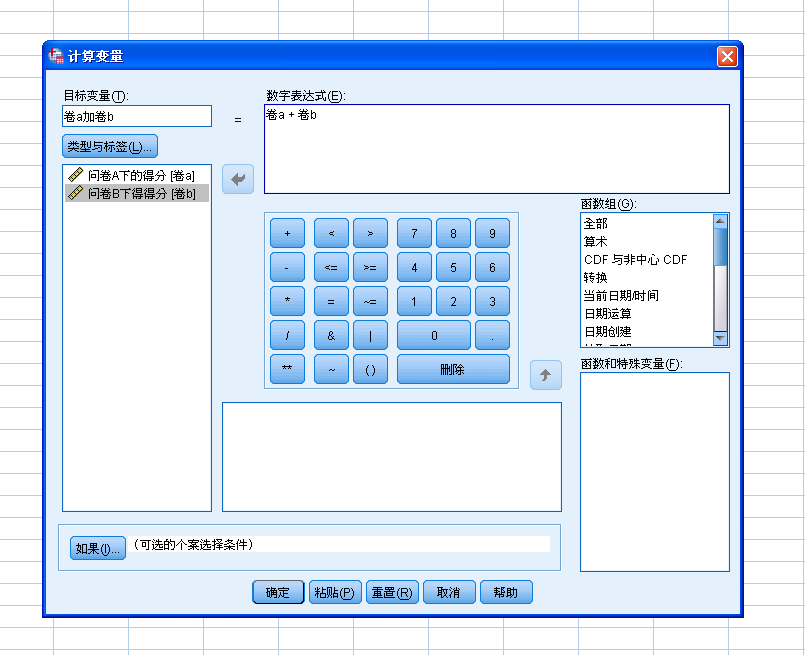
1、先在spss中准备好要处理的数据,然后在菜单栏上执行:analyse--dimension reduction--factor analyse。打开因素分析对话框。
2、我们看到下图就是因素分析的对话框,将要分析的变量都放入variables窗口中。
3、点击descriptives按钮,进入次级对话框,这个对话框可以输出我们想要看到的描述统计量。
4、因为做主成分分析需要我们看一下各个变量之间的相关,对变量间的关系有一个了解,所以需要输出相关,勾选coefficience,点击continue,返回主对话框。
5、回到主对话框,点击ok,开始输出数据处理结果。
6、你看到的这第一个表格就是相关矩阵,现实的是各个变量之间的相关系数,通过相关系数,你可以看到各个变量之间的相关,进而了解各个变量之间的关系。
7、第二个表格显示的主成分分析的过程,我们看到eigenvalues下面的total栏,他的意思就是特征根,他的意义是主成分影响力度的指标,一般以1为标准,如果特征根小于1,说明这个主因素的影响力度还不如一个基本的变量。所以我们只提取特征根大于1的主成分。如图所示,前三个主成分就是大于1的,所以我们只能说有三个主成分。另外,我们看到第一个主成分方差占所有主成分方差的46.9%,第二个占27.5%,第三个占15.0%。这三个累计达到了89.5%。[1]
折叠SPSS18.0
2010年,业界领先的预测分析软件提供商 SPSS 公司推出其旗舰统计分析软件 SPSS 的新版本 SPSS 18.0 for Windows。该版本继承了原有产品的特点之外还增加了许多显著的新特性。公司从大量的客户反馈信息中提取有益的建议,并加入到该新版本中。
SPSS 18 在数据管理、统计分析和可编程性方面增加了许多新的特性。除此之外,SPSS 18 还提供了新的图形选项以及 PDF 格式输出功能-这些都是用户强烈要求的新特性。如果用户使用了 Dimensions 软件用于调查研究,SPSS 同样能够直接导入和导出各种 Dimensions 数据模型。对于企业用户来说,SPSS 服务器不仅性能得到加强,其中用于 SPSS 预测企业服务萡 SPSS 适配器能够让企业内部的各个部门能够更有效地使用一致性的数据。
SPSS 18.0由17个功能模组组成:
- Base System 基础程式
- Advanced Models 高等统计模组(GEE/GLM/存活分析)
- Regression Models 进阶回归模组
- Custom Tables 多变量表格
- Forecasting 时间序列分析
- Categories 类别资料分析/多元尺度方法
- Conjoint 联合分析
- Exact Tests 精确检定
- Missing Value Analysis 遗漏值分析
- Neural Networks 类神经网络
- Decision Trees 决策树
- Data Preparation 资料准备
- Complex Samples 抽样计划
- Direct Marketing 直销行销模组
- Bootstrapping 拔靴法
- Data collection Data Entry 资料收集
- Programmability Extension 扩充程式码能力
SPSS广泛应用于各个领域,但是每个行业都存在着自己与众不同的行业特点和行业需求,因此SPSS根据各个行业数据分析和数据挖掘的特点,设计了更具有针对性的解决方案。
图形和输出
在SPSS 以往版本中已经使用的一种高度可视化的构造图表交互界面-图形构建器在 SPSS 新版中得到了进一步的加强。新式的图表能够让用户将复杂的信息清晰地表现出来。而 PDF 格式的输出功能够让用户更好地同其它人员进行信息共享。
数据和访问管理
SPSS Base 18 提供了更强大的数据管理功能帮助用户通过 SPSS 使用其它的应用程序和数据库。用户还可以定制 SPSS 内部信息显示的方式,这样在管理数据的时候能够节省时间,也具备一定的灵活性。
分析功能
SPSS Base 18 还包括了 ordinal regression(次序回归)分析算法,该算法在以前的版本中包含在 SPSS Advanced Models 附属模块中。在 18.0 中用户可以直接在 Base 模块中直接使用这种新的算法来对两种以上的变量的次序输出进行预测。例如,预测客户忠诚度及其与客户满意度的相关性。
可编程性
SPSS 18.0 中包括了 SPSS Programmability Extension 功能,在 SPSS 命令语法语言的基础上提供与其它编程语言的结合功能。用其它语言编写的程序代码,如 Python®,可以管理使用 SPSS 语法所编写的任务流。使用 SPSS 18.0 提供的扩展编程功能和特性,让 SPSS for Windows 成为了最强大的统计开发平台之一。
折叠软件平台
SPSS自SPSS16.0起推出Linux版本。SPSS最新版本为SPSS 22.0,已支持Windows 8、Mac OS X、Linux及UNIX/2012年,提供Mac、Windows、Linux及UNIX四种平台产品版本下载。
折叠相关图书
SPSS其实很简单
作者:罗纳德·D·约克奇 美国加利福尼亚大学教授。SPSS
译者:刘超,吴铮
出 版 社:中国人民大学出版社
出版时间: 2010-6-1
开本: 16开
定价: 39.00元
统计分析
(第3版) (附光盘一张)
作 者:卢纹岱主编
出 版 社:电子工业出版社
出版时间: 2006-6-1
字 数: 1039000
版 次: 1
页 数: 700
印刷时间: 2006/06/01
纸 张: 胶版纸
包 装: 平装
SPSS宝典
作者:张红兵
页数: 603
定价: 59
出版社: 电子工业出版社
装帧: 平装
出版年: 2007-02-01
统计学(第三版)
作者:贾俊平
页数:331
定价:32
出版社:中国人民大学出版社
出版年:2008年11月
SPSS数据统计与分析
作者:骆方 刘红云 黄昆
页数:270
定价:35.00
出版社:清华大学出版社
出版年:2011年07月
折叠其他相关
折叠Clementine
SPSS Clementine是ISL(Integral Solutions Limited)公司开发的数据挖掘工具平台。1999年SPSS公司收购了ISL公司,对Clementine产品进行重新整合和开发,Clementine已经成为SPSS公司的又一亮点。
作为一个数据挖掘平台, Clementine结合商业技术可以快速建立预测性模型,进而应用到商业活动中,帮助人们改进决策过程。 强大的数据挖掘功能和显著的投资回报率使得Clementine在业界久负盛誉。 同那些仅仅着重于模型的外在表现而忽略了数据挖掘在整个业务流程中的应用价值的其它数据挖掘工具相比, Clementine其功能强大的数据挖掘算法,使数据挖掘贯穿业务流程的始终,在缩短投资回报周期的同时极大提高了投资回报率。
广泛分析带来最优结果
为了解决各种商务问题,企业需要以不同的方式来处理各种类型迥异的数据, 相异的任务类型和数据类型就要求有不同的分析技术。 Clementine为您提供最出色、最广泛的数据挖掘技术,确保您可用最恰当的分析技术来处理相应的问题, 从而得到最优的结果以应对随时出现的商业问题。即便改进业务的机会被庞杂的数据表格所掩盖, Clementine也能最大限度地执行标准的数据挖掘流程,为您找到解决商业问题的最佳答案。
CRISP-DM 使数据挖掘成为标准的商业流程
为了推广数据挖掘技术,以解决越来越多的商业问题,SPSS和一个从事数据挖掘研究的全球性企业联盟制定了关于数据挖掘技术的行业标准--CRISP-DM(Cross-Industry Standard Process for Data Mining)。与以往仅仅局限在技术层面上的数据挖掘方法论不同,CRISP-DM把数据挖掘看作一个商业过程,并将其具体的商业目标映射为数据挖掘目标。一次调查显示,50%以上的数据挖掘工具采用的都是CRISP-DM的数据挖掘流程,它已经成为事实上的行业标准。
Clementine完全支持CRISP-DM标准,这不但规避了许多常规错误,而且其显著的智能预测模型有助于快速解决出现的问题。
应用模板的结果
在数据挖掘项目中使用Clementine应用模板(CATs)可以获得更优化的结果。 应用模板完全遵循CRISP-DM标准,借鉴了大量真实的数据挖掘实践经验,是经过理论和实践证明的有效技术,为项目的正确实施提供了强有力的支撑。Clementine中的应用模板包括:
CRM CAT--针对客户的获取和增长,提高反馈率并减少客户流失;
Web CAT--点击顺序分析和访问行为分析;
Telco CAT--客户保持和增加交叉销售;
Crime CAT--犯罪分析及其特征描述,确定事故高发区,联合研究相关犯罪行为;
Fraud CAT--发现金融交易和索赔中的欺诈和异常行为;
Microarray CAT--研究和疾病相关的基因序列并找到治愈手段。
折叠结构方程模型
确定复杂的关系
在社会科学以及经济、市场、管理等研究领域,有时需要处理多个原因多个结果间的复杂关系,或者会碰到不可直接观测的变量(即潜变量),这些都是传统的统计方法不好解决的问题。二十世纪八十年代以来,结构方程分析迅速发展,弥补了传统统计方法的不足,成为多元数据分析的重要工具。
简单而言,与传统的回归分析不同,结构方程分析能同时处理多个因变量,并可以比较评价不同因果关系的理论模型。与传统的探索性因子分析不同,在结构方程模型中,我们可提出一个特定的因子结构,并检验它是否吻合数据。通过结构方程多组分析,我们可了解不同组别 (如不同性别) 内各变量的关系是否保持不变,各因子的均值是否有显着差异。
国际上关于教育与心理统计的研究取得了快速的发展,结构方程模型可以说是其中发展较快,应用广泛的多元统计分析技术;在商业领域的品牌研究、顾客满意度研究等方向上也得到了广泛的应用。在我国,SEM研究方法还在管理学、经济学、医学及社会学研究等领域的应用也得到了快速的发展。
结构方程模型(SEM)是国际管理研究和其他社会科学研究中日益广泛采用的建模技术,每年的美国管理学会年会上都有专题教学和研讨。SEM越来越成为各类高层次学术刊物、高层次管理研究以及社会学和经济学等学科研究领域的必备方法。
AMOS软件简介
AMOS 是SPSS Statistics软件包中的独立产品,是功能强大的结构方程(SEM) 建模工具,通过对包括回归、因子分析、相关性分析和方差分析等传统多元分析方法的扩展,为您的理论研究提供更多的支持。
在AMOS 环境下,您可以在直观的路径图下指定、估计、评估以及设定模型,以展示假定的各变量之间的关系,来方便地地建立能真实反应复杂关系的行为态度模型。在AMOS 中,任何数值变量,不管是可观测的还是潜在的,都可以用来建模,预测其它数值变量。 AMOS快速创建模型以检验变量之间的相互影响及其原因,由于结构方程模型是一次性地验证复杂的因果关系,用标准方法以及在此基础上扩展的方法进行多元分析,因此比普通最小二乘回归和探索性因子分析更进一步,能获得更精确、丰富的综合分析结果。
AMOS界面使用AMOS直观的拖放式绘图工具,您可以快速地以路径图定制模型而无需编程。在有缺失值的情况下,AMOS使用Full Information Maximum Likelihood方法仍然可以自动计算正确的标准误及适当的统计量,降低估算值偏差。新版本的AMOS 还增加了探索性结果方程模型、辅助多组分析、高级文本输出、扩展的AMOS编程环境等功能。AMOS被广泛地应用于顾客满意度分析等领域。
折叠同类软件
- Epi Info
- SAS
- RapidMiner-开源预测性软件
- Minitab
- MathCAD
- Mathematica
- Maple
- R语言 - 开放源代码统计学软件
- PSPP - 开放源代码软件
- PLUTO-基于云计算技术架
R语言

?
所属类别 :
其他语言相关
R是用于统计分析、绘图的语言和操作环境。R是属于GNU系统的一个自由、免费、源代码开放的软件,它是一个用于统计计算和统计制图的优秀工具。
词条
百科
精彩信息一览无遗
基本信息
- 中文名称
R语言
- 外文名称
TheR Programming Language
- 功能
统计分析、绘图
|
目录 |
1发展历史 2功能 |
4CRAN 5安装 6语言环境 |
7教程参考 |
朗讯科技公司贝尔实验室总裁威廉·欧榭R是统计领域广泛使用的诞生于1980年左右的S语言的一个分支。可以认为R是S语言的一种实现。而S语言是由AT&T贝尔实验室开发的一种用来进行数据探索、统计分析和作图的解释型语言。最初S语言的实现版本主要是S-PLUS。S-PLUS是一个商业软件,它基于S语言,并由MathSoft公司的统计科学部进一步完善。后来Auckland大学的Robert Gentleman和Ross Ihaka及其他志愿人员开发了一个R系统。由"R开发核心团队"负责开发。 R是基于S语言的一个GNU项目,所以也可以当作S语言的一种实现,通常用S语言编写的代码都可以不作修改的在R环境下运行。 R的语法是来自Scheme。R的使用与S-PLUS有很多类似之处,这两种语言有一定的兼容性。S-PLUS的使用手册,只要稍加修改就可作为R的使用手册。所以有人说:R,是S-PLUS的一个"克隆"。
但是请不要忘了:R是免费的。(R is free)
R语言源代码托管在github,具体地址可以看参考资料。
R语言的下载可以通过cran的镜像来查找,具体地址可以看参考资料。
R语言有域名为.cn的下载地址,其中一个由Datagurn,另一个由中国科学技术大学提供的。
R语言Windows版,其中由两个下载地点是Datagurn和USTC提供的。具体地址可以看参考资料。
R是一套完整的数据处理、计算和制图软件系统。其功能包括:数据存储和处理系统;数组运算工具(其向量、矩阵运算方面功能尤其强大);完整连贯的统计分析工具;优秀的统计制图功能;简便而强大的编程语言:可操纵数据的输入和输出,可实现分支、循环,用户可自定义功能贝尔实验室。
与其说R是一种统计软件,还不如说R是一种数学计算的环境,因为R并不是仅仅提供若干统计程序、使用者只需指定数据库和若干参数便可进行一个统计分析。R的思想是:它可以提供一些集成的统计工具,但更大量的是它提供各种数学计算、统计计算的函数,从而使使用者能灵活机动的进行数据分析,甚至创造出符合需要的新的统计计算方法。
该语言的语法表面上类似 C,但在语义上是函数设计语言(functional programming language)的变种并且和Lisp以及APL有很强的兼容性。特别的是,它允许在"语言上计算"(computing on the language)。这使得它可以把表达式作为函数的输入参数,而这种做法对统计模拟和绘图非常有用。
R是一个免费的自由软件,它有UNIX、LINUX、MacOS和WINDOWS版本,都是可以免费下载和使用的。在那儿可以下载到R的安装程序、各种外挂程序和文档。在R的安装程序中只包含了8个基础模块,其他外在模块可以通过CRAN获得。
R的原代码可自由下载使用,亦有已编译的执行档版本可以下载,可在多种平台下运行,包括UNIX(也包括FreeBSD和Linux)、Windows和MacOS。 R主要是以命令行操作,同时有人开发了几种图形用户界面。
R内含多种统计学及数字分析功能。因为S的血缘,R比其他统计学或数学专用的编程语言有更强的物件导向(面向对象程序设计)功能。
R的另一强项是绘图功能,制图具有印刷的素质,也可加入数学符号。
虽然R主要用于统计分析或者开发统计相关的软体,但也有人用作矩阵计算。其分析速度可媲美GNU Octave甚至商业软件MATLAB。
R的功能能够通过由用户撰写的套件增强。增加的功能有特殊的统计技术、绘图功能,以及编程界面和数据输出/输入功能。这些软件包是由R语言、LaTeX、Java及最常用C语言和Fortran撰写。下载的执行档版本会连同一批核心功能的软件包,而根据CRAN纪录有过千种不同的软件包。其中有几款较为常用,例如用于经济计量、财经分析、人文科学研究以及人工智能。

折叠R包介绍
R语言的使用,很大程度上是借助各种各样的R包的辅助,从某种程度上讲,R包就是针对于R的插件,不同的插件满足不同的需求,截至2013年3月6日,CRAN已经收录了各类包4338个。例如用于经济计量、财经分析、人文科学研究以及人工智能。
折叠安装包
1、通过选择菜单:
程序包->安装程序包->在弹出的对话框中,选择你要安装的包,然后确定。
2、使用命令
install.packages("package_name","dir")
package_name:是指定要安装的包名,请注意大小写。
dir:包安装的路径。默认情况下是安装在..\library 文件夹中的。可以通过本参数来进行修改,来选择安装的文件夹。
3、本地来安装
如果你已经下载的相应的包的压缩文件,则可以在本地来进行安装。请注意在windows、unix、macOS操作系统下安装文件的后缀名是不一样的:
1)linux环境编译运行:tar.gz文件
2)windows 环境编译运行 :.zip文件
3)MacOSg环境编译运行:.tgz文件
注:包安装好后,并不可以直接使用,如果在使用包中相关的函数,必须每次使用前包加载到内存中。通过library(package_name)来完成。
折叠加载包
包安装后,如果要使用包的功能。必须先把包加载到内存中(默认情况下,R启动后默认加载基本包),加载包命令:
Library("包名")
Require("包名")
折叠查看包的相关信息
1、查看包帮忙
library(help="package_name")
主要内容包括:例如:包名、作者、版本、更新时间、功能描述、开源协议、存储位置、主要的函数
help(package = "package_name")
主要内容包括:包的内置所有函数,是更为详细的帮助文档
2、查看当前环境哪些包加载
find.package() 或者 .path.package()
3、移除包出内存
detach()
4、把其它包的数据加载到内存中
data(dsname, package="package_name")
5、查看这个包里的包有数据
data( package="package_name")
6、列出所有安装的包
library()
CRAN为Comprehensive R Archive Network(R综合典藏网)的简称。它除了收藏了R的执行档下载版、源代码和说明文件,也收录了各种用户撰写的软件包。现时,全球有超过一百个CRAN镜像站。
以下简述R FOR WINDOWS的安装和使用:
下可以找到R的各个版本的安装程序和贝尔实验室美国总部源代码。点击进入:Windows (95 and later),再点击:base,下载SetupR.exe,约18兆,此便是R FOR WINDOWS的安装程序。双击SetupR.exe,按照提示一步步安装即可。
安装完成后,程序会创建R程序组并在桌面上创建R主程序的快捷方式(也可以在安装过程中选择不要创建)。通过快捷方式运行R,便可调出R的主窗口。
类似于许多以编程方式为主要工作方式的软件,R的界面简单而朴素,只有不多的几个菜单和快捷按钮。快捷按钮下面的窗口便是命令输入窗口,它也是部分运算结果的输出窗口,有些运算结果则会输出在新建的窗口中。
主窗口上方的一些文字是刚运行R时出现的一些说明和指引。文字下的:> 符号便是R的命令提示符,在其后可输出命令;>后的矩形是光标。R一般是采用交互方式工作的,在命令提示符后输入命令,回车后便会输出结果。
在R朴素的界面下,是丰富而复杂的运算功能。
R是一套由数据操作、计算和图形展示功能整合而成的套件。包括:有效的数据存储和处理功能,一套完整的数组(特别是矩阵)计算操作符,拥有完整体系的数据分析工具,为数据分析和显示提供的强大图形功能,一套(源自S语言)完善、简单、有效的编程语言(包括条件、循环、自定义函数、输入输出功能)。
在这里使用"环境"(environment)是为了说明R的定位是一个完善、统一的系统,而非其他数据分析软件那样作为一个专门、不灵活的附属工具。
书 名:R数据分析
作 者:方匡南 朱建平 姜叶飞编著
出 版 社:电子工业出版社
出版时间:2015-02-01
版 次:1
页 数:392
印刷时间:2015-02-01
本: 16开
纸 张:胶版纸印
印 次:1
包 装:平装
《R数据分析:方法与案例详解(双色)》是一本R语言和数据分析的入门教材,循序渐进、深入浅出,每个知识点尽量从实际的应用案例出发,以问题为导向,在解决问题中学习统计方法、R语言的基本使用以及编程技巧。
《R数据分析:方法与案例详解(双色)》内容涵盖R数据结构、函数与优化、抽样模拟、统计分析、假设检验、回归分析、统计绘图和R包制作等内容。
《R数据分析:方法与案例详解(双色)》的定位是为业界数据分析人员、经济管理类、医学的学生提供方法和程序上的参考,在写作过程中尽量删去比较理论的数学原理,这样能够帮助读者轻松上手学习。
stata 
?
所属类别 :
软件
Stata 是一套提供其使用者数据分析、数据管理以及绘制专业图表的完整及整合性统计软件。它提供许许多多功能,包含线性混合模型、均衡重复反复及多项式普罗比模式。用Stata绘制的统计图形相当精美。
词条
百科
精彩信息一览无遗
基本信息
- 中文名称
stata
- 外文名称
stata
- 用途
数据分析、数据管理以及绘制
- 属性
软件
- 功能
线性混合模型、均衡重复反复
- 类型
统计分析软件
|
目录 |
1简介 2统计功能 |
3作图功能 4程序设计 |
5功能列表 6学习资料 |
新版本的STATA采用最具亲和力的窗口接口,使用者自行建立程序时,软件能提供具有直接命令式的语法。Stata提供完整的使用手册,包含统计样本建立、解释、模型与语法、文献等超过一万余页的出版品。
除此之外,Stata软件可以透过网络实时更新每天的最新功能,更可以得知世界各地的使用者对于STATA公司提出的问题与解决之道。使用者也可以透过Stat软件logoa Journal获得许许多多的相关讯息以及书籍介绍等。另外一个获取庞大资源的管道就是Statalist,它是一个独立的listserver,每月交替提供使用者超过1000个讯息以及50个程序。[1]
Stata的统计功能很强,除了传统的统计分析方法外,还收集了近20年发展起来的新方法,如Cox比例风险回归,指数与Weibull回归,多类结果与有序结果的logistic回归,Poisson回归,负二项回归及广义负二项回归,随机效应模型等。具体说, Stata具有如下统计分析能力:
数值变量资料的一般分析:参数估计,t检验,单因素和多因素的方差分析,协方差分析,交互效应模型,平衡和非平衡设计,嵌套设计,随机效应,多个均数的两两比较,缺项数据的处理,方差齐性检验,正态性检验,变量变换等。
分类资料的一般分析:参数估计,列联表分析 ( 列联系数,确切概率 ) ,流行病学表格分析等。
等级资料的一般分析:秩变换,秩和检验,秩相关等
相关与回归分析:简单相关,偏相关,典型相关,以及多达数十种的回归分析方法,如多元线性回归,逐步回归,加权回归,稳键回归,二阶段回归,百分位数 ( 中位数 ) 回归,残差分析、强影响点分析,曲线拟合,随机效应的线性回归模型等。
其他方法:质量控制,整群抽样的设计效率,诊断试验评价, kappa等。
Stata的作图模块,主要提供如下八种基本图形的制作 : 直方图(histogram),条形图(bar),百分条图 (oneway),百分圆图(pie),散点图(two way),散点图矩阵(matrix),星形图(star),分位数图。这些图形的巧妙应用,可以满足绝大多数用户的统计作图要求。在有些非绘图命令中,也提供了专门绘制某种图形的功能,如在生存分析中,提供了绘制生存曲线图,回归分析中提供了残差图等。
Stata的矩阵运算功能
矩阵代数是多元统计分析的重要工具, Stata提供了多元统计分析中所需的矩阵基本运算,如矩阵的加、积、逆、 Cholesky分解、 Kronecker内积等;还提供了一些高级运算,如特征根、特征向量、奇异值分解等;在执行完某些统计分析命令后,还提供了一些系统矩阵,如估计系数向量、估计系数的协方差矩阵等。
Stata是一个统计分析软件,但它也具有很强的程序语言功能,这给用户提供了一个广阔的开发应用的天地,用户可以充分发挥自己的聪明才智,熟练应用各种技巧,真正做到随心所欲。事实上,Stata的ado文件(高级统计部分)都是用Stata自己的语言编写的。
Stata其统计分析能力远远超过了SPSS,在许多方面也超过了SAS!由于Stata在分析时是将数据全部读入内存,在计算全部完成后才和磁盘交换数据,因此计算速度极快(一般来说, SAS的运算速度要比SPSS至少快一个数量级,而Stata的某些模块和执行同样功能的SAS模块比,其速度又比SAS快将近一个数量级!)Stata也是采用命令行方式来操作,但使用上远比SAS简单。其生存数据分析、纵向数据(重复测量数据)分析等模块的功能甚至超过了SAS。用Stata绘制的统计图形相当精美,很有特色。
数据管理(Data management)
资料转换、分组处理、附加档案、 ODBC 、行 - 列转换、数据标记、字符串函数…等
基本统计(Basic statistics)
直交表、相关性、 t- 检定、变异数相等性检定、比例检定、信赖区间…等
线性模式(Linear models)
稳健Huber/White/sandwich变异估计 , 三阶最小平方法、类非相关回归、齐次多项式回归、GLS
广义型线性模式(Generalized linear models)
十连结函数、使用者-定义连结、 ML及IRLS估计、九变异数估计、七残差…等
二元、计数及有限应变量(Binary, count and limited dependent variables)
罗吉斯特、probit、卜松回归、tobit、truncated回归、条件罗吉斯特、多项式逻辑、巢状逻辑、负二项、 zero-inflated模型、Heckman 选择模式、边际影响
Panel数据/交叉 - 组合时间序列(Panel data/cross-sectional time-series)
随机及固定影响之回归、GEE、随机及固定-影响之卜松及负二项分配、随机 - 影响、工具变量回归、AR(1) 干扰回归
无母数方法(Nonparametric methods)
多变量方法(Multivariate methods)
因素分析、多变量回归、 anonical 相关系数
模型检定及事后估计量支持分析(Model testing and post-estimation support)
Wald检定、LR检定、线性及非线性组合、非线性限制检定、边际影响、修正平均数Hausman检定
群集分析(Cluster analysis)
加权平均、质量中心及中位数联结、kmeans、kmedians、dendrograms、停止规则、使用者扩充
图形(Graphics)
直线图、散布图、条状图、圆饼图、 hi-lo 图、回归诊断图…
调查方法(Survey methods)
抽样权重、丛集抽样、分层、线性变异数估计量、拟 - 概似最大估计量、回归、工具变量…
生存分析(Survival analysis)
Kaplan–Meier、Nelson–Aalen、Cox回归(弱性)、参数模式(弱性)、危险比例测试、时间共变项、左-右检查、韦柏分配、指数分配…
流行病学工具(Tools for epidemiologists)
比例标准化、病例控制、已配适病例控制、Mantel – Haenszel,药理学、ROC分析、ICD-9-CM
时间序列(Time series)
ARIMA、ARCH/GARCH、VAR、Newey–West、correlograms、periodograms、白色 - 噪音测试、最小整数根检定、时间序列运算、平滑化
最大概似法(Maximum likelihood)
转换及常态检定(Transforms and normality tests)
Box–Cox、次方转换Shapiro–Wilk、Shapiro–Francia检定
其它统计方法(Other statistical methods)
样本数量及次方、非线性回归、逐步式回归 、统计及数学函数
包含样本范例(Sample session)
再抽样及模拟方法(Resampling and simulation methods)
bootstrapping、jackknife、蒙地卡罗模拟、排列检定
网络功能
安装新指令、网络升级、网站档案分享、Stata 最新消息
epiman论坛学习资源丰富,学术氛围良好,在国内新生代公共卫生学术界有一定影响力。是探讨Stata、spss、sas、epidata等统计软件的主流论坛之一

折叠网络资源
Stata官方网站。Stata公司提供的Web resources,涵盖了大量相关网络资源;其FAQ则提供了各种常见问题的解答;Statalist则是一个类似于人大经济论坛的免费的讨论区。加入Statalist的方法很简单,你只需要发送邮件至Stata-maillist,邮件内容无需任何称谓,只需写上"subscribe Statalist"的字样即可。接到确认信息后,你便成为一名Statalist的成员了。当然,即使不加入,你仍然可以浏览,但不能提问。
UCLA(加州大学洛杉矶分校提供的网络教程。该网站提供的Data Management、Graphics、Regression、Logistic Regression、Multilevel Modeling、Survey Data Analysis等模块都非常出色;其Web Books、Textbook Examples模块则非常细致地呈现了几十本非常流行的统计和计量教材的Stata实例;对于LaTeX感兴趣的朋友,则可以通过Stata Tools for LaTeX模块获得诸多有用的信息;在Graph examples模块中,则列举了四十余种图形的绘制方法;最后,在Classes and Seminars模块中,你可以在线观看数十个Stata教学视频。
Stata中文讨论专区。目前,国内已有多个专门讨论Stata应用的论坛,包括人大经济论坛Stata专区,公卫人EpiMan等。这些论坛集中了国内外数十万的Stata用户,为交流和解决Stata应用过程中遇到的各种问题和经验提供了很好的平台。
折叠相关的书籍
自从Hamilton(1990)出版Statistics with Stata后,一系列将计量理论与软件操作结合起来的书籍开始相继面世,而在此之前,人们似乎都认为软件操作是件非常简单的事情。也正因为如此,很多学生在修改完了一个学年的计量经济学课程后,仍然不知道该如何完成OLS估计。为此,我列举的书籍多附有Stata实例(* 表示我的推荐程度),多数书中的范例数据都可通过Stata官方网站下载。
一份详细的书单:UCLA提供了的书单 。
入门教材:Baum(2006)*、Newton and Cox(2009)、Chen et al.(2005)、Adkins and Hill(2008)*;Wooldridge(2009)*,波士顿大学的网站上提供了该书所有章节的Stata范例,是一套非常好的学习资料。
综合性教材:Cameron and Trivedi(2005)撰写的Microeconometrics: Methods and applications一书全面介绍了微观计量中的基本分析工具,其中不乏最近十年中得到广泛应用的Bootstrap、Monte Carlo模拟,以及非参数估计法。二人于2009年出版的另一力作(Cameron and Trivedi(2009)*)是这本书的姊妹篇,重点介绍了常用计量模型的Stata实现方法。
Stata手册:我一直非常佩服撰写Stata手册的那些人,他们总能以最简洁的语言说清楚纠结我很久的问题。Stata11附有16本电子手册,仅需统一放置于D:\stata11\utilities目录下,即可从Stata内部的帮助文件中的Also see部分直接链接到相应的PDF说明书中。作为初学者,我强烈建议你将[U]和[D]打印出来,反复研读。stata手册内容齐全,但不便于阅读,把命令与例题割裂开来,阅读起来很不方便。
stata软件在社会科学研究中的高级应用:周文光,李尧远,梁炜 著,西北工业大学出版社出版。该书详细介绍了如何应用stata对连续变量与分类变量进行分析,包括回归分析,时间序列分析,面板数据分析等,并介绍了如何使用stata进行生存分析与聚类分析、编程等内容。
Stata视频。相比于网络教程和纸本教材,通过视频学习Stata可能是最快捷的方式了。UCLA免费发布的视频教程,内容涉及Stata入门、数据处理和绘图等。[2] 采用英文讲解,思路清晰。局限在于所涉及内容不够系统,但对于想快速入门的学生则是一份不错的参考资料。同时,藉由这份资料也可以练习一下英语听力。对于中文用户而言,人大论坛发布的Stata初级和高级视频则提供了更为快捷的学习方式。其中,初级视频主要介绍stata的操作方法,包括stata入门、stata数据处理、stata绘图、stata矩阵以及stata编程初步五个部分。[3] 高级视频主要介绍各种计量模型的基本原理,重点介绍其在stata中的实现方法,包括OLS、GLS、MLE、IV-GMM、时间序列分析、面板模型、stata高级编程、Bootstrap和Monte Carlo模拟等内容,比较全面的涵盖了计量经济学和核心内容。[4]
统计方法:Rabe-Hesketh and Everitt(2006)。
Stata绘图:Mitchell(2008),非常细致地介绍了各种图形的绘制方法。
Stata数据处理:Kohler and Kreuter(2005)*、Long(2009)*、杨菊华(2008)。
Stata编程:Baum(2009),当然,该书中有关数据处理的介绍也非常精彩。
Logit/Probit模型:Hosmer and Lemeshow(2000)*对相关的理论进行非常细致的介绍,是我学习Logit模型的入门教材;Long and Freese(2001)*、Long and Freese(2006)、Hilbe(2009)则涉及了大量的Stata实例,对解读Logit/Probit模型的结果很有帮助;Rabe-Hesketh et al.(2004)提供了在GLLAMM架构下估计xtlogit, xtprobit, xtmelogit以及xtmepoisson模型的方法。
Panel Data和多层次模型:Stata11 手册[XT]*,简洁明了,附有大量实例;Cameron and Trivedi(2009)*、王志刚(2008)、Rabe-Hesketh and Skrondal(2008)。
Mata:Schmidheiny(2008)*,简洁明了介绍了Mata的基本用法;详情则可参与Stata11手册[M]。
GLLAMM:Rabe-Hesketh et al.(2004)。
Meta:Sterne(2009)。
GLM:Hardin et al.(2007)。
MLE:Harrison(2008)(Lectures)、Gould et al.(2006)。
生存分析:Cleves et al.(2008)。
Python

?
所属类别 :
编程技术
Python(英语发音:/ˈpaɪθən/), 是一种面向对象、解释型计算机程序设计语言,由Guido van Rossum于1989年底发明,第一个公开发行版发行于1991年,Python 源代码同样遵循 GPL(GNU General Public License)协议。Python语法简洁而清晰,具有丰富和强大的类库。它常被昵称为胶水语言,能够把用其他语言制作的各种模块(尤其是C/C++)很轻松地联结在一起。常见的一种应用情形是,使用Python快速生成程序的原型(有时甚至是程序的最终界面),然后对其中有特别要求的部分,用更合适的语言改写,比如3D游戏中的图形渲染模块,性能要求特别高,就可以用C/C++重写,而后封装为Python可以调用的扩展类库。需要注意的是在您使用扩展类库时可能需要考虑平台问题,某些可能不提供跨平台的实现。
词条
百科
精彩信息一览无遗
基本信息
- 外文名称
Python
- 经典教材
Head First Python
- 发行时间
1991年
- 设计者
Guido van Rossum
- 最新版本
3.6.2/2.7.13
- 荣誉
2017年度编程语言
|
目录 |
1基本概念 2主要特点 3优点 |
4基本术语 5发展历程 6其他资料 |
7著名应用 |
Python(KK 英语发音:/'paɪθɑn/, DJ 英语发音:/ˈpaiθən/)是一种面向对象、直译式计算机程序设计语言,由Guido van Rossum于1989年底发明。第一个公开发行版发行于1991年。Python语法简捷而清晰,具有丰富和强大的类库。
它常被昵称为胶水语言,它能够很轻松的把用其他语言制作的各种模块(尤其是C/C++)轻松地联结在一起。常见的一种应用情形是,使用python快速生成程序的原型(有时甚至是程序的最终界面),然后对其中有特别要求的部分,用更合适的语言改写。比如3D游戏中的图形渲染模块,速度要求非常高,就可以用C++重写。
简单:Python是一种代表简单主义思想的语言。阅读一个良好的Python程序就感觉像是在读英语一样。它使你能够专注于解决问题而不是去搞明白语言本身。
易学:Python极其容易上手,因为Python有极其简单的语法。
免费、开源:Python是FLOSS(自由/开放源码软件)之一。使用者可以自由地发布这个软件的拷贝、阅读它的源代码、对它做改动、把它的一部分用于新的自由软件中。FLOSS是基于一个团体分享知识的概念。
高层语言:用Python语言编写程序的时候无需考虑诸如如何管理你的程序使用的内存一类的底层细节。
可移植性:由于它的开源本质,Python已经被移植在许多平台上(经过改动使它能够工作在不同平台上)。这些平台包括Linux、Windows、FreeBSD、Macintosh、Solaris、OS/2、Amiga、AROS、AS/400、BeOS、OS/390、z/OS、Palm OS、QNX、VMS、Psion、Acom RISC OS、VxWorks、PlayStation、Sharp Zaurus、Windows CE、PocketPC、Symbian以及Google基于linux开发的android平台。
解释性:一个用编译性语言比如C或C++写的程序可以从源文件(即C或C++语言)转换到一个你的计算机使用的语言(二进制代码,即0和1)。这个过程通过编译器和不同的标记、选项完成。
运行程序的时候,连接/转载器软件把你的程序从硬盘复制到内存中并且运行。而Python语言写的程序不需要编译成二进制代码。你可以直接从源代码运行 程序。
在计算机内部,Python解释器把源代码转换成称为字节码的中间形式,然后再把它翻译成计算机使用的机器语言并运行。这使得使用Python更加简单。也使得Python程序更加易于移植。
面向对象:Python既支持面向过程的编程也支持面向对象的编程。在“面向过程”的语言中,程序是由过程或仅仅是可重用代码的函数构建起来的。在“面向对象”的语言中,程序是由数据和功能组合而成的对象构建起来的。
可扩展性:如果需要一段关键代码运行得更快或者希望某些算法不公开,可以部分程序用C或C++编写,然后在Python程序中使用它们。
可嵌入性:可以把Python嵌入C/C++程序,从而向程序用户提供脚本功能。
丰富的库:Python标准库确实很庞大。它可以帮助处理各种工作,包括正则表达式、文档生成、单元测试、线程、数据库、网页浏览器、CGI、FTP、电子邮件、XML、XML-RPC、HTML、WAV文件、密码系统、GUI(图形用户界面)、Tk和其他与系统有关的操作。这被称作Python的“功能齐全”理念。除了标准库以外,还有许多其他高质量的库,如wxPython、Twisted和Python图像库等等。
规范的代码:Python采用强制缩进的方式使得代码具有较好可读性。而Python语言写的程序不需要编译成二进制代码。
Python 是一种不受局限、跨平台的开源编程语言,它功能强大且简单易学。因而得到了广泛应用和支持。
ArcGIS 9.0 社区中引入了 Python。此后,Python 被视为可供地理处理用户选择的脚本语言并得以不断发展。每个版本都进一步增强了 Python 体验,从而为您提供更多的功能以及更丰富、更友好的 Python 体验。
ESRI 已将 Python 完全纳入 ArcGIS 中,并将其视为可满足我们用户社区需求的语言。下面仅介绍 Python 的部分优势[1]:
- 易于学习,非常适合初学者,也特别适合专家使用
- 可伸缩程度高,适于大型项目或小型的一次性程序(称为脚本)
- 可移植,跨平台
- 可嵌入(使 ArcGIS 可脚本化)
- 稳定成熟
- 用户社区规模大
Python 已延伸到 ArcGIS 中,成为了一种用于进行数据分析、数据转换、数据管理和地图自动化的语言,因而有助于提高工作效率。
折叠局限
强制缩进:这也许不应该被称为局限,但是它用缩进来区分语句关系的方式还是给很多初学者带来了困惑。
单行语句和命令行输出问题:很多时候不能将程序连写成一行,如import sys;for i in sys.path:print i。而perl和awk就无此限制,可以较为方便的在shell下完成简单程序,不需要如Python一样,必须将程序写入一个.py文件。
折叠应用
系统编程:提供API(Application Programming Interface应用程序编程接口),能方便进行系统维护和管理,Linux下标志性语言之一,是很多系统管理员理想的编程工具。
图形处理:有PIL、Tkinter等图形库支持,能方便进行图形处理。
数学处理:NumPy扩展提供大量与许多标准数学库的接口。
文本处理:python提供的re模块能支持正则表达式,还提供SGML,XML分析模块,许多程序员利用python进行XML程序的开发。
数据库编程:程序员可通过遵循Python DB-API(数据库应用程序编程接口)规范的模块与Microsoft SQL Server,Oracle,Sybase,DB2,Mysql、SQLite等数据库通信。python自带有一个Gadfly模块,提供了一个完整的SQL环境。
网络编程:提供丰富的模块支持sockets编程,能方便快速地开发分布式应用程序。很多大规模软件开发计划例如Zope,Mnet 及BitTorrent. Google都在广泛地使用它。
Web编程:应用的开发语言,支持最新的XML技术。
多媒体应用:Python的PyOpenGL模块封装了“OpenGL应用程序编程接口”,能进行二维和三维图像处理。PyGame模块可用于编写游戏软件。
Python的创始人为Guido van Rossum。1989年圣诞节期间,在阿姆斯特丹,Guido为了打发圣诞节的无趣,决心开发一个新的脚本解释程序,做为ABC 语言的一种继承。之所以选中Python(大蟒蛇的意思)作为程序的名字,是因为他是一个叫Monty Python的喜剧团体的爱好者。
ABC是由Guido参加设计的一种教学语言。就Guido本人看来,ABC 这种语言非常优美和强大,是专门为非专业程序员设计的。但是ABC语言并没有成功,究其原因,Guido 认为是非开放造成的。Guido 决心在Python 中避免这一错误。同时,他还想实现在ABC 中闪现过但未曾实现的东西。
就这样,Python在Guido手中诞生了。实际上,第一个实现是在Mac机上。可以说,Python是从ABC发展起来,主要受到了Modula-3(另一种相当优美且强大的语言,为小型团体所设计的)的影响。并且结合了Unix shell和C的习惯。
折叠风格
Python在设计上坚持了清晰划一的风格,这使得Python成为一门易读、易维护,并且被大量用户所欢迎的、用途广泛的语言。
设计者开发时总的指导思想是,对于一个特定的问题,只要有一种最好的方法来解决就好了。这在由Tim Peters写的python格言(称为The Zen of Python)里面表述为:There should be one-- and preferably only one --obvious way to do it. 这正好和Perl语言(另一种功能类似的高级动态语言)的中心思想TMTOWTDI(There's More Than One Way To Do It)完全相反。
Python的作者有意的设计限制性很强的语法,使得不好的编程习惯(例如if语句的下一行不向右缩进)都不能通过编译。其中很重要的一项就是Python的缩进规则。
一个和其他大多数语言(如C)的区别就是,一个模块的界限,完全是由每行的首字符在这一行的位置来决定的(而C语言是用一对花括号{}来明确的定出模块的边界的,与字符的位置毫无关系)。这一点曾经引起过争议。因为自从C这类的语言诞生后,语言的语法含义与字符的排列方式分离开来,曾经被认为是一种程序语言的进步。不过不可否认的是,通过强制程序员们缩进(包括if,for和函数定义等所有需要使用模块的地方),Python确实使得程序更加清晰和美观。
折叠执行
Python在执行时,首先会将.py文件中的源代码编译成Python的byte code(字节码),然后再由Python Virtual Machine(Python 虚拟机)来执行这些编译好的byte code。这种机制的基本思想跟Java,.NET是一致的。然而,Python Virtual Machine与Java或.NET的Virtual Machine不同的是,Python的Virtual Machine是一种更高级的Virtual Machine。
这里的高级并不是通常意义上的高级,不是说Python的Virtual Machine比Java或.NET的功能更强大,而是说和Java 或.NET相比,Python的Virtual Machine距离真实机器的距离更远。或者可以这么说,Python的Virtual Machine是一种抽象层次更高的Virtual Machine。
基于C的Python编译出的字节码文件,通常是.pyc格式。
折叠工具
|
部分工具列表 |
|
|
名称 |
功能 |
|
Tkinter |
Python默认的图形界面接口。Tkinter是一个和Tk接口的Python模块,Tkinter库提供了对Tk API的接口,它属于Tcl/Tk的GUI工具组。 |
|
PyGTK |
用于python GUI程序开发的GTK+库。GTK就是用来实现GIMP和Gnome的库。 |
|
PyQt |
用于python的Qt开发库。QT就是实现了KDE环境的那个库,由一系列的模块组成,有qt, qtcanvas, qtgl, qtnetwork, qtsql, qttable, qtui and qtxml,包含有300个类和超过5750个的函数和方法。PyQt还支持一个叫qtext的模块,它包含一个QScintilla库。该库是Scintillar编辑器类的Qt接口。 |
|
wxPython |
GUI编程框架,熟悉MFC的人会非常喜欢,简直是同一架构(对于初学者或者对设计要求不高的用户来说,使用Boa Constructor可以方便迅速的进行wxPython的开发) |
|
PIL |
python提供强大的图形处理的能力,并提供广泛的图形文件格式支持,该库能进行图形格式的转换、打印和显示。还能进行一些图形效果的处理,如图形的放大、缩小和旋转等。是Python用户进行图象处理的强有力工具。 |
|
Psyco |
一个Python代码加速度器,可使Python代码的执行速度提高到与编译语言一样的水平。 |
|
xmpppy |
Jabber服务器采用开发的XMPP协议,Google Talk也是采用XMPP协议的IM系统。在Python中有一个xmpppy模块支持该协议。也就是说,我们可以通过该模块与Jabber服务器通信,是不是很Cool。 |
|
PyMedia |
用于多媒体操作的python模块。它提供了丰富而简单的接口用于多媒体处理(wav, mp3, ogg, avi, divx, dvd, cdda etc)。可在Windows和Linux平台下使用。 |
|
Pmw |
Python megawidgets,Python超级GUI组件集,一个在python中利用Tkinter模块构建的高级GUI组件,每个Pmw都合并了一个或多个Tkinter组件,以实现更有用和更复杂的功能。 |
|
PyXML |
用Python解析和处理XML文档的工具包,包中的4DOM是完全相容于W3C DOM规范的。它包含以下内容: |
|
PyGame |
用于多媒体开发和游戏软件开发的模块。 |
|
PyOpenGL |
模块封装了“OpenGL应用程序编程接口”,通过该模块python程序员可在程序中集成2D和3D的图形。 |
|
NumPy、NumArray、SAGE |
NumArray是Python的一个扩展库,主要用于处理任意维数的固定类型数组,简单说就是一个矩阵库。它的底层代码使用C来编写,所以速度的优势很明显。SAGE是基于NumPy和其他几个工具所整合成的数学软件包,目标是取代Magma, Maple, Mathematica和Matlab 这类工具。 |
|
MySQLdb |
用于连接MySQL数据库。还有用于zope的ZMySQLDA模块,通过它就可在zope中连接mysql数据库。 |
|
Python-ldap |
提供一组面向对象的API,可方便地在python中访问ldap目录服务,它基于OpenLDAP2.x。 |
|
smtplib |
发送电子邮件。 |
|
ftplib |
定义了FTP类和一些方法,用以进行客户端的ftp编程。如果想了解ftp协议的详细内容,请参考RFC959。 |
展开

折叠升级
Python的3.0版本,在开发阶段被称为Python 3000,或简称Py3k。相对于Python的早期版本,这是一个较大的升级。为了不带入过多的累赘,Python 3.0在设计的时候就没有考虑向下兼容。许多针对早期Python版本设计的程序都无法在Python 3.0上正常运行。为了照顾现有程序,Python 2.6作为一个过渡版本,基本使用了Python 2.x的语法和库,同时考虑了向Python 3.0的迁移。基于早期Python版本而能正常运行于Python 2.6并无警告的程序可以通过一个2 to 3的转换工具无缝迁移到Python 3.0。
Python 3.0的变化主要在以下几个方面:
部分函数和语句的改变:最引人注意的改变是print语句没有了,取而代之的是print函数。
字符串和字节:类似Java,str类表示一个Unicode字符串,代替了早期版本的unicode类。而一堆字节则用类似b"abc"的语法创建,用bytes类表示。
折叠PythonIDE
●IDLE:Python内置IDE (随python安装包提供)
●Komodo和Komodo Edit:后者是前者的免费精简版
●PythonWin:ActivePython或pywin32均提供该IDE,仅适用于Windows
●SPE(Stani's Python Editor):功能较多的自由软件,基于wxPython
●Ulipad:功能较全的自由软件,基于wxPython;作者是中国Python高手limodou
●WingIDE:可能是功能最全的IDE,但不是自由软件(教育用户和开源用户可以申请免费key)
●Eric:基于PyQt的自由软件,功能强大。全名是:The Eric Python IDE
●DrPython
●PyScripter:使用Delphi开发的轻量级的开源Python IDE, 支持Python2.6和3.0。
●PyPE:一个开源的跨平台的PythonIDE。
●bpython: 类Unix操作系统下使用curses库开发的轻量级的Python解释器。语法提示功能。
折叠IDE软件
●eclipse + pydev插件:方便调试程序
●emacs:自带python支持,自动补全、refactor等功能需要插件支持
●Vim: 最新7.3版编译时可以加入python支持,提供python代码自动提示支持
●Visual Studio 2003 + VisualPython:仅适用Windows,已停止维护,功能较差
●SlickEdit
●Visual Studio 2010 + Python Tools for Visual Studio
●TextMate
●Netbeans IDE
另外,诸如EditPlus、UltraEdit、PSPad等通用的程序员文本编辑器软件也能对Python代码编辑提供一定的支持,比如代码自动着色、注释快捷键等,但是否够得上集成开发环境的水平,尚有待评估。
折叠问题
1. 运行速度慢。
2. 国内市场较小。
3. 中文资料匮乏(好的python中文资料屈指可数)。托社区的福,有几本优秀的教材已经被翻译了,但入门级教材多,高级内容还是只能看英语版。
4. 构架选择太多。不过这也从另一个侧面说明,python比较优秀,吸引的人才多,项目也多。
折叠程序
使用Python创建第一个CGI程序,文件名为hello.py,文件位于/var/www/cgi-bin目录中,内容如下,修改文件的权限为755:
#!/usr/bin/env python print("Content-type:text/html\r\n\r\n") print("<html>") print("<head>") print("") print("</head>") print("<body>") print("<h2>Hello World! This is my first CGI program</h2>") print("</body>") print("</html>")
以上程序在浏览器访问显示结果如下:
Hello World! This is my first CGI program
这个的hello.py脚本是一个简单的Python脚本,脚本第一的输出内容"Content-type:text/html\r\n\r\n"发送到浏览器并告知浏览器显示的内容类型为"text/html"。
折叠学习网站
1. python终极学习站点
折叠在Python中学习机器学习的四个步骤
1、首先你要使用书籍、课程、视频来学习 Python 的基础知识[2]
2、然后你必需掌握不同的模块,比如 Pandas、Numpy、Matplotlib、NLP (自然语言处理),来处理、清理、绘图和理解数据。
3、接着你必需能够从网页抓取数据,无论是通过网站API,还是网页抓取模块Beautiful Soap。通过网页抓取可以收集数据,应用于机器学习算法。
4、最后一步,你必需学习机器学习工具,比如 Scikit-Learn,或者在抓取的数据中执行机器学习算法(ML-algorithm)。
Zope- 应用服务器
Plone- 内容管理系统
Django- 鼓励快速开发的Web应用框架
Uliweb- 国人开发的轻量级Web框架
TurboGears- 另一个Web应用快速开发框架
Twisted--Python的网络应用程序框架
Python Wikipedia Robot Framework- MediaWiki的机器人程序
MoinMoinWiki- Python写成的Wiki程序
flask- Python 微Web框架
tornado- 非阻塞式服务器
Webpy- Python 微Web框架
Bottle- Python 微Web框架
EVE- 网络游戏EVE大量使用Python进行开发
Reddit - 社交分享网站
Dropbox - 文件分享服务
Pylons - Web应用框架
TurboGears - 另一个Web应用快速开发框架
Fabric - 用于管理成百上千台Linux主机的程序库
Trac - 使用Python编写的BUG管理系统
Mailman - 使用Python编写的邮件列表软件
Mezzanine - 基于Django编写的内容管理系统
Blender - 以C与Python开发的开源3D绘图软件
数据分析
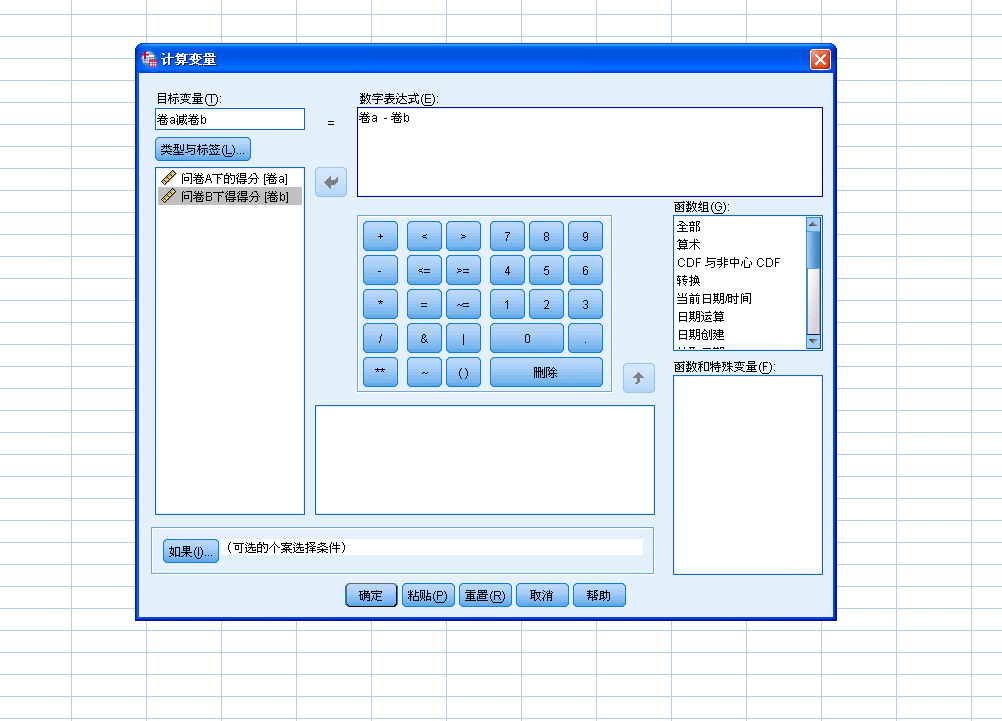
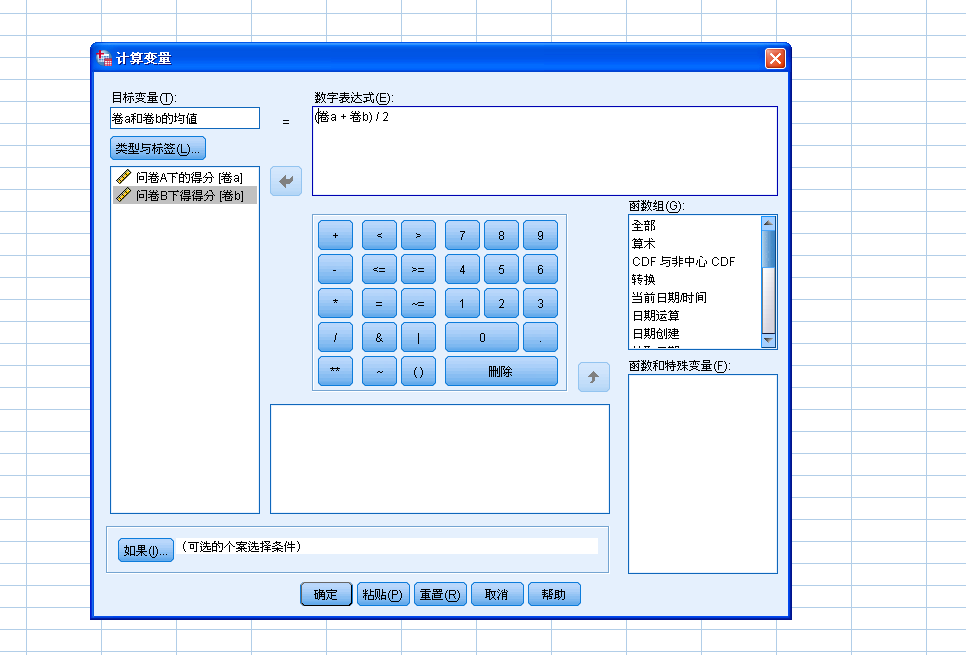
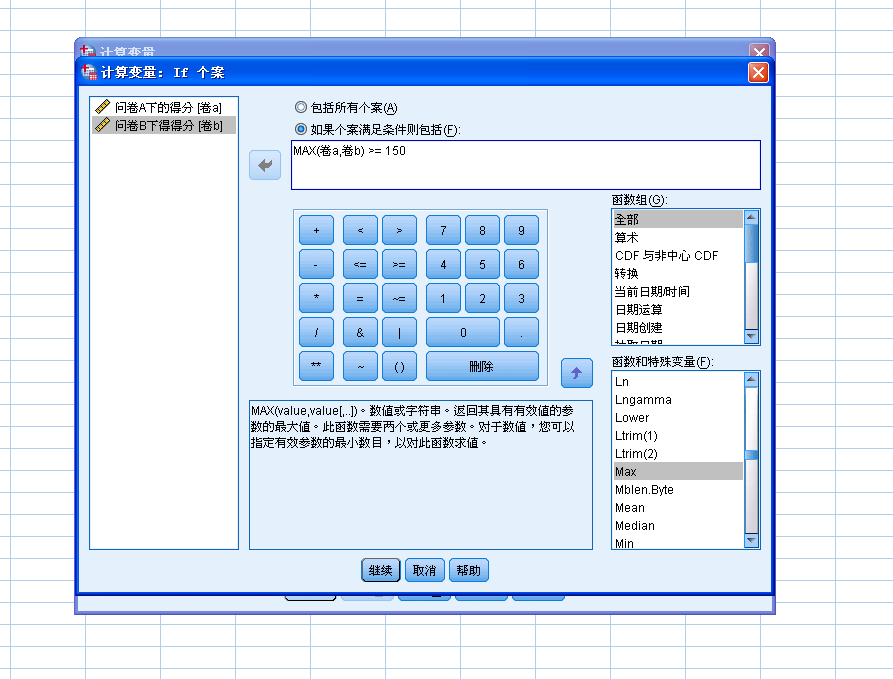
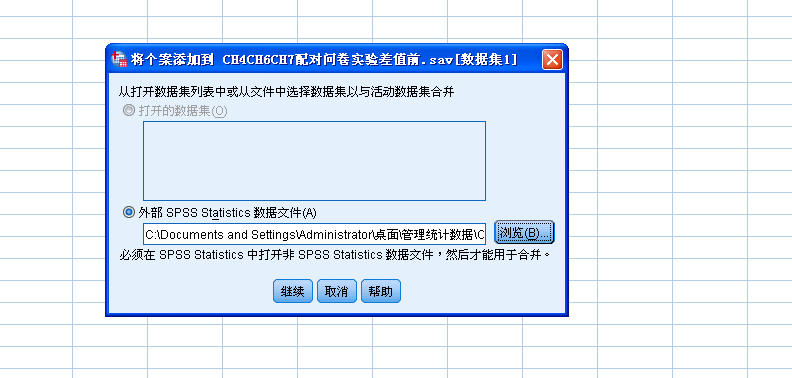


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}