

使用YOLOv2进行图像检测
- 基本配置信息
tensorflow (1.4.0)
tensorflow-tensorboard (0.4.0)
Keras (2.1.5)
Python (3.6.0)
Anaconda 4.3.1 (64-bit)
Windows 7
- darknet链接
https://github.com/pjreddie/darknet
下载后在cfg文件夹下找到yolov2的配置文件yolov2.cfg
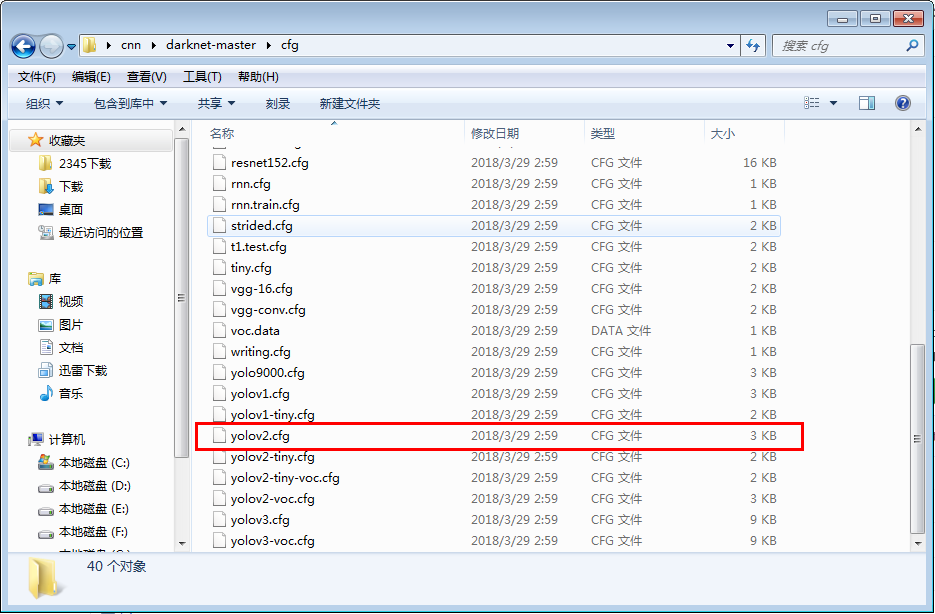
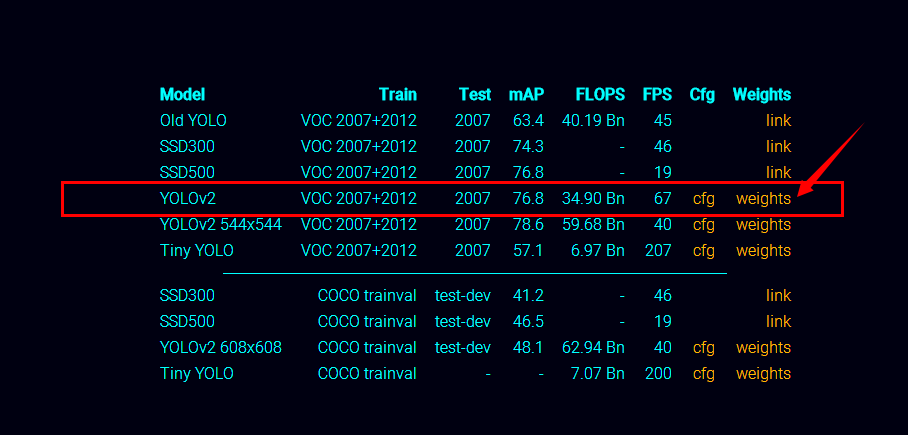
- yolov2权重文件链接
https://pjreddie.com/darknet/yolov2/
在页面中选择YOLOV2 weights下载
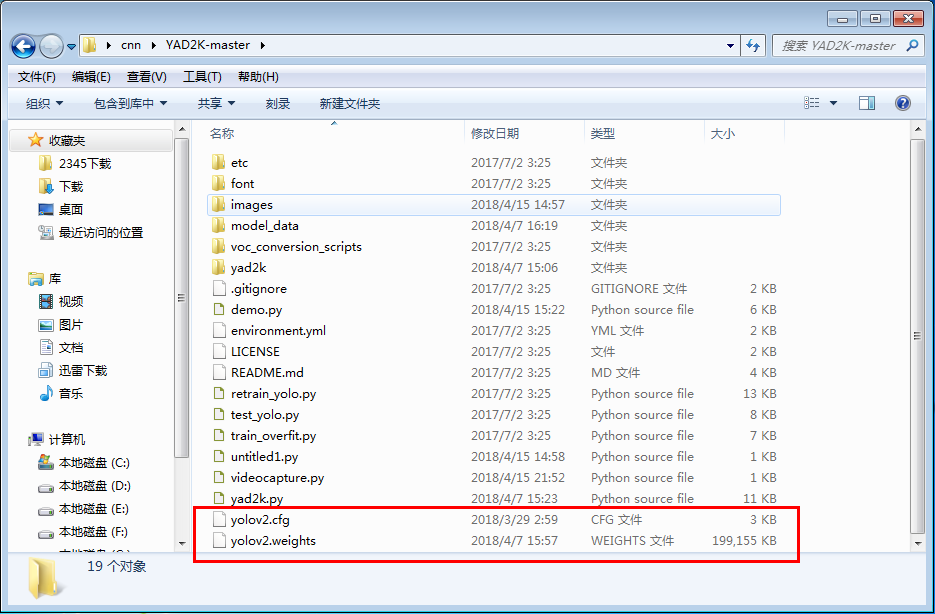
- yad2k 链接
https://github.com/allanzelener/YAD2K
下载完成后将之前下载好的yolov2.cfg文件,YOLOV2 weights文件拷贝到yad2k目录下
- 使用spyder 运行yad2k目录下的yad2k.py文件
在运行配置里设置运行时所需的参数信息
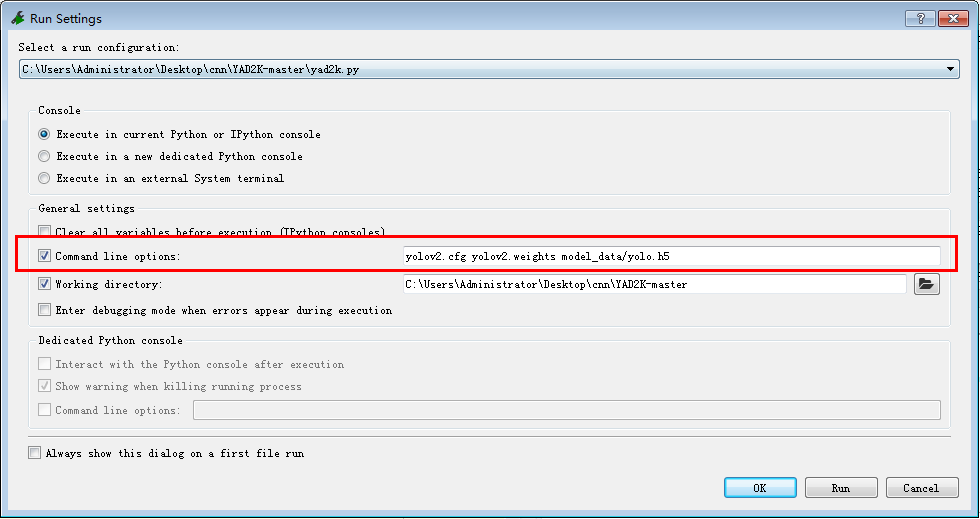
或使用命令行运行yad2k.py
python yad2k.py yolov2.cfg yolov2.weights model_data/yolo.h5
运行结果如图所示

生成的yolo.h5文件在model_data文件夹内
- 利用生成的权重信息,进行图像检测
使用opencv调用电脑摄像头,进行视频图像信息的检测
opencv版本
opencv-python (3.2.0)
在yad2k目录下创建自己的demo,参考https://www.jianshu.com/p/3e77cefeb49b
1 import cv2 2 import os 3 import time 4 import numpy as np 5 from keras import backend as K 6 from keras.models import load_model 7 8 from yad2k.models.keras_yolo import yolo_eval, yolo_head 9 10 11 class YOLO(object): 12 def __init__(self): 13 self.model_path = 'model_data/yolo.h5' 14 self.anchors_path = 'model_data/yolo_anchors.txt' 15 self.classes_path = 'model_data/coco_classes.txt' 16 self.score = 0.3 17 self.iou = 0.5 18 19 self.class_names = self._get_class() 20 self.anchors = self._get_anchors() 21 self.sess = K.get_session() 22 self.boxes, self.scores, self.classes = self.generate() 23 24 def _get_class(self): 25 classes_path = os.path.expanduser(self.classes_path) 26 with open(classes_path) as f: 27 class_names = f.readlines() 28 class_names = [c.strip() for c in class_names] 29 return class_names 30 31 def _get_anchors(self): 32 anchors_path = os.path.expanduser(self.anchors_path) 33 with open(anchors_path) as f: 34 anchors = f.readline() 35 anchors = [float(x) for x in anchors.split(',')] 36 anchors = np.array(anchors).reshape(-1, 2) 37 return anchors 38 39 def generate(self): 40 model_path = os.path.expanduser(self.model_path) 41 assert model_path.endswith('.h5'), 'Keras model must be a .h5 file.' 42 43 self.yolo_model = load_model(model_path) 44 45 # Verify model, anchors, and classes are compatible 46 num_classes = len(self.class_names) 47 num_anchors = len(self.anchors) 48 # TODO: Assumes dim ordering is channel last 49 model_output_channels = self.yolo_model.layers[-1].output_shape[-1] 50 assert model_output_channels == num_anchors * (num_classes + 5), \ 51 'Mismatch between model and given anchor and class sizes' 52 print('{} model, anchors, and classes loaded.'.format(model_path)) 53 54 # Check if model is fully convolutional, assuming channel last order. 55 self.model_image_size = self.yolo_model.layers[0].input_shape[1:3] 56 self.is_fixed_size = self.model_image_size != (None, None) 57 58 # Generate output tensor targets for filtered bounding boxes. 59 # TODO: Wrap these backend operations with Keras layers. 60 yolo_outputs = yolo_head(self.yolo_model.output, self.anchors, len(self.class_names)) 61 self.input_image_shape = K.placeholder(shape=(2, )) 62 boxes, scores, classes = yolo_eval(yolo_outputs, self.input_image_shape, score_threshold=self.score, iou_threshold=self.iou) 63 return boxes, scores, classes 64 65 def detect_image(self, image): 66 start = time.time() 67 #image = cv2.imread(image) 68 #cv2.imshow('image',image) 69 y, x, _ = image.shape 70 71 if self.is_fixed_size: # TODO: When resizing we can use minibatch input. 72 resized_image = cv2.resize(image, tuple(reversed(self.model_image_size)), interpolation=cv2.INTER_CUBIC) 73 image_data = np.array(resized_image, dtype='float32') 74 else: 75 image_data = np.array(image, dtype='float32') 76 77 image_data /= 255. 78 image_data = np.expand_dims(image_data, 0) # Add batch dimension. 79 80 out_boxes, out_scores, out_classes = self.sess.run( 81 [self.boxes, self.scores, self.classes], 82 feed_dict={ 83 self.yolo_model.input: image_data, 84 self.input_image_shape: [image.shape[0], image.shape[1]], 85 K.learning_phase(): 0 86 }) 87 print('Found {} boxes for {}'.format(len(out_boxes), 'img')) 88 89 for i, c in reversed(list(enumerate(out_classes))): 90 predicted_class = self.class_names[c] 91 box = out_boxes[i] 92 score = out_scores[i] 93 94 label = '{} {:.2f}'.format(predicted_class, score) 95 top, left, bottom, right = box 96 top = max(0, np.floor(top + 0.5).astype('int32')) 97 left = max(0, np.floor(left + 0.5).astype('int32')) 98 bottom = min(y, np.floor(bottom + 0.5).astype('int32')) 99 right = min(x, np.floor(right + 0.5).astype('int32')) 100 print(label, (left, top), (right, bottom)) 101 102 cv2.rectangle(image, (left, top), (right, bottom), (255, 0, 0), 2) 103 cv2.putText(image, label, (left, int(top - 4)), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 255), 1, cv2.LINE_AA) 104 end = time.time() 105 print(end - start) 106 return image 107 108 def close_session(self): 109 self.sess.close() 110 111 112 def detect_vedio(yolo): 113 camera = cv2.VideoCapture(0) 114 115 while True: 116 res, frame = camera.read() 117 118 if not res: 119 break 120 121 image = yolo.detect_image(frame) 122 cv2.imshow("detection", image) 123 124 if cv2.waitKey(1) & 0xFF == ord('q'): 125 break 126 yolo.close_session() 127 128 129 def detect_img(img, yolo): 130 image = cv2.imread(img) 131 r_image = yolo.detect_image(image) 132 cv2.namedWindow("detection") 133 while True: 134 cv2.imshow("detection", r_image) 135 if cv2.waitKey(110) & 0xff == 27: 136 break 137 yolo.close_session() 138 139 140 if __name__ == '__main__': 141 yolo = YOLO() 142 detect_vedio(yolo)

