分页解决方案 之 分页算法——Pager_SQL的思路和使用方法
2009-05-15 07:03 金色海洋(jyk) 阅读(5524) 评论(23) 收藏 举报
分页算法(也就是分页读取数据的时候使用的select 语句)面临两大难题:一个是不同的数据库使用的分页算法是不一样的(比如SQL Server 2000可以使用Max、表变量、颠倒Top,SQL Server 2005可以使用Row_Number,MySql可以使用limit ,Orcale可以使用ROWNUM等);另一个是,不同的分页需求,可以采用的分页算法也是不一样的(比如单字段排序和多字段排序)。那么我们应该如何来选择呢?
好多人都想找到一种即通用,效率又高的分页算法,那么能不能找到呢?我是找了很久都没有找到,看了许多人写得文章,我也没有发现(请不要和我说那个什么表变量的)。既然找不到,那就要做多手准备了。
我的想法就是准备多种分页算法的“模板”,然后根据数据库的种类,根据分页需求来选择到底是用哪一种分页算法。就是说使用哪一种是不固定的,依据条件而定。那么如何来实现呢?我做了一个类库来做这个事情,请看下面的图示:
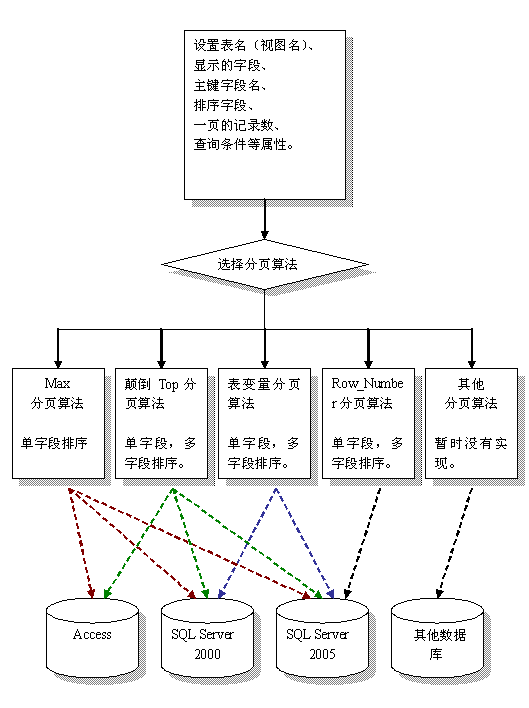
Pager_SQL原来是QuickPager分页控件的一部分,现在独立出来可以单独使用。
Pager_SQL就好像一个加工厂,给他输入“原料”(表名、字段名、排序字段等),然后再选择“加工方式”(选择分页算法),最后我们就可以得到所需的“产品”(分页用的select 语句)了。
因为不管是什么数据库(只要是关系型数据库),那么就会有表、字段、视图,要分页就要有排序字段等,所以呢这些原料都是固定的,变化的只是分页用的SQL语句,这个Pager_SQL就是“生产”各种SQL语句的工厂。这样不同的分页算法既可以适应不同的数据库,也可以使用不同的分页需求。
Pager_SQL的原理很简单,就是拼接字符串(也就是拼接SQL语句),然后通过数据访问函数库(或者其他的help等)提交给数据库执行。采用了基类的方式,所以如果需要增加分页算法的话,那么只要继承这个基类写一个子类,如果有不同的地方,覆盖一下就可以了。下面是类图:
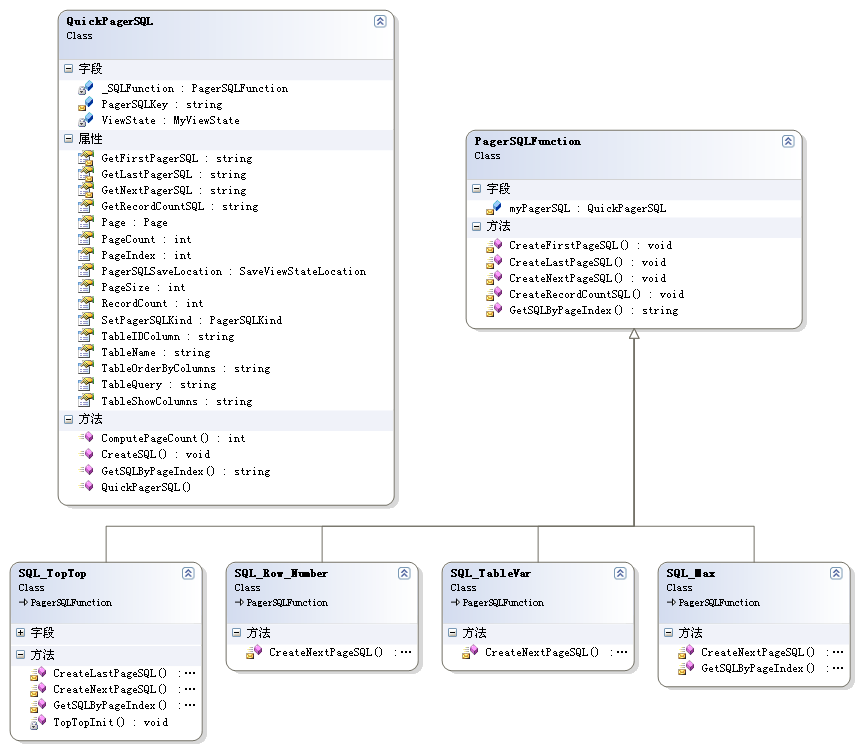
说到这里,您可能会有两个疑问:1、拼接字符串的效率是不是会很慢?2、SQL语句和储存过程相比是不是很慢?两个“慢”加起来,是不是变成了“巨慢”。一开始我也是比较担心,但是用了五年多,也用100万条记录做过测试,效率还是很理想的。这两天我又详细的测试了一下,在测试的过程中也发现了不少细节问题,以前忽略的地方,由于测试的比较乱,所以我想整理一下然后再写出来。
使用方法:
 //实例化JYK.Controls.Pager.QuickPagerSQL PagerSQL = new QuickPagerSQL();protected void Page_Load(object sender, EventArgs e)
//实例化JYK.Controls.Pager.QuickPagerSQL PagerSQL = new QuickPagerSQL();protected void Page_Load(object sender, EventArgs e) {
{
 //设置属性 PagerSQL.TableName = "News_NewsInfo"; //表名或者视图名称 PagerSQL.TableShowColumns = "*"; //需要显示的字段 PagerSQL.TableIDColumn = "NewsID"; //主键名称,不支持复合主键 PagerSQL.TableOrderByColumns = "NewsID"; //排序字段,根据分页算法而定,可以支持多个排序字段 PagerSQL.TableQuery = ""; //查询条件 PagerSQL.PageSize = 4; //一页显示的记录数 PagerSQL.PageCount = 100; PagerSQL.ComputePageCount(100,4);
//设置属性 PagerSQL.TableName = "News_NewsInfo"; //表名或者视图名称 PagerSQL.TableShowColumns = "*"; //需要显示的字段 PagerSQL.TableIDColumn = "NewsID"; //主键名称,不支持复合主键 PagerSQL.TableOrderByColumns = "NewsID"; //排序字段,根据分页算法而定,可以支持多个排序字段 PagerSQL.TableQuery = ""; //查询条件 PagerSQL.PageSize = 4; //一页显示的记录数 PagerSQL.PageCount = 100; PagerSQL.ComputePageCount(100,4); }
} 测试拼接字符串的效率
测试拼接字符串的效率

 }
}
源码下载:http://www.cnblogs.com/jyk/archive/2008/07/29/1255891.html
ps:下一篇里我会测试程序里面拼接字符串的时间、SQL Server2000分析、制作执行计划的时间,SQL语句和储存过程的对比,exe (@sql)和 exec sp_executesql @sql 的区别。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号