

机器学习算法原理与编程实践之朴素贝叶斯分类
在介绍朴素贝叶斯分类之前,首先介绍一下大家都比较了解的贝叶斯定理,即已知某条件概率,如何得到两个时间交换后的概率,
也就是在已知P(A|B)的情况下如何求得P(B|A)?可以通过如下公式求得:
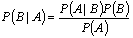
而朴素贝叶斯分类是一种简单的分类算法,称其朴素是因为其思想基础的简单性:就文本分类而言,它认为词袋中的两两词之间的关系
是相互独立的,即一个对象的特征向量中的每个维度都是相互独立。
朴素贝叶斯分类的正式定义如下:
(1)设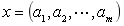 为一个待分类项,而每个a为x的一个特征属性。
为一个待分类项,而每个a为x的一个特征属性。
(2)有类别集合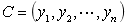 。
。
(3)计算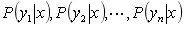 。
。
(4)如果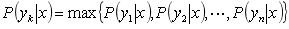 ,则
,则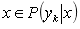 。
。
因此,现在问题的关键就是如何计算第(3)步中的每个条件概率。我们可以按以下步骤计算。
(1)找到一个已知分类的待分类项集合,也就是训练集。
(2)统计得到在各类别下各个特征属性的条件概率估计。即:
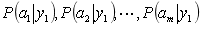
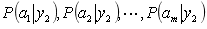
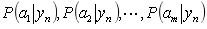
(3)如果每个特征属性是条件独立的(或者假设他们之间是相互独立的),则根据贝叶斯定理有如下推导:
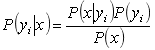
因为分母对于所有的类别都是一样的,为常数,因此只要将分子最大化即可。又因为个特征属性是条件独立的,所以有
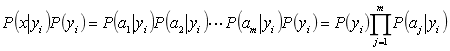
这就是Scikit-Learn中的公式推导过程的说明。根据上述分析,朴素贝叶斯分类的流程可以表示如下:
第一阶段:训练数据生成训练样本集合:TF-IDF
第二阶段:对每个类别计算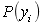 。
。
第三阶段:对每个特征属性计算所有类别划分的条件概率。
第四阶段:对每个类别计算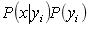 。
。
第五阶段:以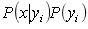 的最大项做为x的所属类别。
的最大项做为x的所属类别。
