
Collection与Map
20145217 《Java程序设计》第5周学习总结(2)
教材学习内容总结
程序中常有收集对象的需求
9.1collection架构
收集对象的行为,像是新增对象的add()方法、移除对象的remove()方法等,都是定义在java.util.collection中。既然可以收集对象,也要能逐一取得对象,这就是java.lang.Iterable定义行为,它定义了Iterator()方法返回java.util.Iterator操作对象。收集对象共同定义在Collection中,然而根据收集对象会有不同的收集需求。Collection继承架构设计图如下:

java.util.Set:记录每个对象的索引顺序,并可依索引取回对象。java.util.List:收集对象不重复,具有集合的行为。java.util.Queue:收集对象时以队列方式,收集的对象加入至尾端,取得对象时从前端。java.util.Deque:对Queue的两端进行加入、移除等操作。
9.2具有索引的List
List是一种Collection,作用是收集对象,并以索引形式保留收集对象顺序。其操作类有java.util.ArrayList和java.util.LinkedList。ArrayList和LinkedList在性能上各有优缺点,都有各自所适用的地方,总的说来可以描述如下:
-
1.对
ArrayList和LinkedList而言,在列表末尾增加一个元素所花的开销都是固定的。对ArrayList而言,主要是在内部数组中增加一项,指向所添加的元素,偶尔可能会导致对数组重新进行分配;而对LinkedList而言,这个开销是统一的,分配一个内部Entry对象。 -
2.在
ArrayList的中间插入或删除一个元素意味着这个列表中剩余的元素都会被移动;而在LinkedList的中间插入或删除一个元素的开销是固定的。 -
3.
LinkedList不支持高效的随机元素访问。 -
4.
ArrayList的空间浪费主要体现在在list列表的结尾预留一定的容量空间,而LinkedList的空间花费则体现在它的每一个元素都需要消耗相当的空间
可以这样说:当操作是在一列数据的后面添加数据而不是在前面或中间,并且需要随机地访问其中的元素时,使用ArrayList会提供比较好的性能;当你的操作是在一列数据的前面或中间添加或删除数据,并且按照顺序访问其中的元素时,就应该使用LinkedList了。
Guest.java:用的是ArryList
package cc.openhome;
import java.util.*;
import static java.lang.System.out;
public class Guest {
public static void main(String[] args) {
List names = new ArrayList();
collectNameTo(names);
out.println("访客名单");
printUpperCase(names);
}
static void collectNameTo(List names){
Scanner console =new Scanner(System.in);
while(true){
out.println("访客名称:");
String name=console.nextLine();
if(name.equals("quit")){
break;
}
names.add(name);
}
}
static void printUpperCase(List names){
for(int i=0;i<names.size();i++){
String name =(String)names.get(i);
out.println(name.toUpperCase());
}
}
}
运行结果:输入Tom和Jack

9.3内容不重复的Set
同样是收集对象,在收集对象过程中若有相同对象则不再收集,若有这类需求可以用Set接口的操作对象。Word.java:
package word;
import java.util.*;
public class Word {
public static void main(String[] args) {
Scanner console=new Scanner(System.in);
System.out.println("请输入英文:");
Set words =tokenSet(console.nextLine());
System.out.printf("不重复的单子有%d个:%s%n",words.size(),words);
}
static Set tokenSet(String line){
String[] tokens=line.split(" ");
return new HashSet(Arrays.asList(tokens));
}
}
运行结果:

String的split()方法,可以指定切割字符串的方式,在这里指定空切割,split()会返回String[],包括切割的每个字符串。
Students.java:
package students;
import java.util.*;
class Student{
private String name;
private String number;
Student(String name,String number){
this.name=name;
this.number=number;
}
@Override
public String toString(){
return String.format("(%s,%s)", name,number);
}
}
public class Students {
public static void main(String[] args) {
Set students=new HashSet();
students.add(new Student("Justin","B835031"));
students.add(new Student("Monica","B835032"));
students.add(new Student("Justin","B835031"));
System.out.println(students);
}
}
由于没有告诉Set什么样的students实例才算重复的,所以显示结果为:
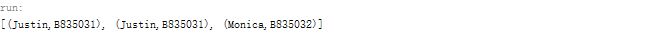
所加入hashCode()与equals()具体方法,重复的students将不会收集。
即加入下片段:
@Override
public int hashCode(){
int hash=7;
hash=47*hash+Objects.hashCode(this.name);
hash=47*hash+Objects.hashCode(this.number);
return hash;
}
@Override
public boolean equals(Object obj){
if(obj==null){
return false;
}
if(getClass()!=obj.getClass()){
return false;
}
final Student other=(Student)obj;
if(!Objects.equals(this.name, other.name)){
return false;
}
if(!Objects.equals(this.number, other.number)){
return false;
}
return true;
}
运行结果:

Hashset的操作概念是,在内存中开辟空间,每个空间会有一个哈希编码,这些空间成为哈希桶,如果对想要加入Hashset,则会调用对象的hashCde()取得哈希码,并尝试放入桶中,如果同中没有对象直接放入,如果有则调用对象的equals()进行比较。比较结果为false则收集,比较结果为true则不予收集。
9.4队列操作Queue
如果希望收集对象时以队列方式,收集的对象加入至尾端,取得对象时从前端,则可使用Queue接口的操作对象。队列是一种特殊的线性表,它只允许在表的前端front进行删除操作,而在表的后端rear进行插入操作。进行插入操作的端称为队尾,进行删除操作的端称为队头。队列中没有元素时,称为空队列。在队列这种数据结构中,最先插入的元素将是最先被删除的元素;反之最后插入的元素将是最后被删除的元素,因此队列又称为“先进先出”FIFO—first in first out的线性表。若对象有操作Queue,并打算一队列的方式使用,且队列长度受限,通常建议使用offer()、poll()、peek()等方法。
offer():用来在队列后端加入对象,成功返回true,失败返回false。poll():用来取出队列前端的对象,若队列为空则返回null。peek():用来取得但不取出队列前端对象。
LinkedList不仅操作了List接口,也操作了Queue的行为,所以可以将LinkedList当队列来使用,Requetqueue.java:
package requestqueue;
import java.util.*;
interface Request{
void execute();
}
public class Requestqueue {
public static void main(String[] args) {
Queue requests=new LinkedList();
offerRequestTo(requests);
process(requests);
}
static void offerRequestTo(Queue requests){
for(int i= 1;i<6;i++){
Request request =new Request(){
public void execute(){
System.out.printf("数据处理%f%n", Math.random());
}
};
requests.offer(request);
}
}
static void process(Queue requests){
while (requests.peek()!=null){
Request request=(Request) requests.poll();
request.execute();
}
}
}
运行结果为:

Deque是Queue的子接口,定义了在前端加入对象取出对象,在尾端加入对象取出对象。Queue的行为与Deque的行为有所重复,有几个操作是等义的:

二者对于offer()、poll()、peek()等方法操作失败返回特定值,对于add()、remove()、element()等方法操作失败会抛出异常。
课本第274页程序运行结果为:

堆栈结构是先进后出,所以最后才显示Justin。
9.5使用泛型
泛型语法在设计API时可以指定类或者方法支持泛型,而使用API的客户端在语法上也会更简洁,并得到编译时期检查。这类API在运用时,没有指定类型参数实际类型,程序代码中出现类型参数的地方,都会回归为使用Object类型。
- 名称类旁出现角括号
<E>,这表示支持泛型。E是类型代号表示Element,也可以用T、K、V等代号。 - 由于使用
<E>定义类型,在需要编译程序检查类型的地方,都可以使用E,像是add()方法必须传入的对象类型是E。
9.6Lambda表达式
Lambda表达式虽然看着很先进,其实Lambda表达式的本质只是一个"语法糖",由编译器推断并帮你转换包装为常规的代码,因此你可以使用更少的代码来实现同样的功能。因为这就和某些很高级的黑客写的代码一样,简洁,难懂,难以调试。
9.7Iterable与Iterator
iterator()方法会返回java.util.Iterator的接口操作对象,这个对象包括了Collection收集的所有对象。Iterator是迭代器类,而Iterable是接口。 好多类都实现了Iterable接口,这样对象就可以调用iterator()方法,一般二者都是结合着用。
- 为什么一定要实现
Iterable接口,为什么不直接实现Iterator接口呢? - 看一下
JDK中的集合类,比如List一族或者Set一族,都是实现了Iterable接口,但并不直接实现Iterator接口。 仔细想一下这么做是有道理的。
ForEach.java:
package cc.openhome;
import java.util.*;
public class ForEach {
public static void main(String[] args) {
List names = Arrays.asList("Justin","monica","Irene");
forEach(names);
forEach(new HashSet(names));
forEach(new ArrayDeque(names));
}
static void forEach(Iterable interable){
for(Object o:interable){
System.out.println(o);
}
}
}
运行结果如下图:

9.8Comparable与Comparator
Comparable & Comparator都是用来实现集合中元素的比较、排序的,只是 Comparable 是在集合内部定义的方法实现的排序,Comparator是在集合外部实现的排序,所以,如想实现排序,就需要在集合外定义Comparator接口的方法或在集合内实现Comparable接口的方法。Comparator位于包java.util下,而Comparable位于包java.lang下。Comparable是一个对象本身就已经支持自比较所需要实现的接口;Comparator是一个专用的比较器,当这个对象不支持自比较或者自比较函数不能满足你的要求时,你可以写一个比较器来完成两个对象之间大小的比较。
9.9Map操作类
Map 提供了一个更通用的元素存储方法。Map集合类用于存储元素对(称作“键”和“值”),其中每个键映射到一个值。从概念上而言,您可以将 List看作是具有数值键的Map。而实际上,除了List和Map都在定义java.util中外,两者并没有直接的联系。Map设计架构:
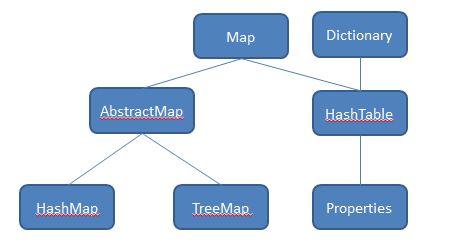
- HashMap:在HashMap中建立键值对应后,键是无序的。
- TreeMap:键的部分会排序,条件是作为键的对象必须操作Comparable接口,或者创建TreeMap时指定操作Comparator接口对象。
- Properties:主要用于读取Java的配置文件,各种语言都有自己所支持的配置文件。
代码调试中的问题和解决过程
上传代码到git:
学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第三周 | 300/600 | 2/6 | 20/50 | |
| 第四周 | 300/900 | 2/8 | 16/66 | |
| 第五周 | 300/1200 | 3/10 | 16/82 |
