


HTTP代理实现请求报文的拦截与篡改4--从客户端读取请求报文并封装
还记得前面提到的一次会话的四个过程吗,这次讲第一个
从客户端读取请求报文并封装
- HTTP代理实现请求报文的拦截与篡改1--开篇
- HTTP代理实现请求报文的拦截与篡改2--功能介绍+源码下载
- HTTP代理实现请求报文的拦截与篡改3--代码分析开始
- HTTP代理实现请求报文的拦截与篡改4--从客户端读取请求报文并封装
- HTTP代理实现请求报文的拦截与篡改5--将请求报文转发至目标服务器
- HTTP代理实现请求报文的拦截与篡改6--从目标服务器接收响应报文并封装
- HTTP代理实现请求报文的拦截与篡改7--将接收到的响应报文返回给客户端
- HTTP代理实现请求报文的拦截与篡改8--自动设置及取消代理+源码下载
- HTTP代理实现请求报文的拦截与篡改8补--自动设置及取消ADSL拔号连接代理+源码下载
- HTTP代理实现请求报文的拦截与篡改9--实现篡改功能后的演示+源码下载
- HTTP代理实现请求报文的拦截与篡改10--大结局 篡改部分的代码分析
先看ObtainRequest() 方法
1 public bool ObtainRequest() 2 { 3 if (!this.Request.ReadRequest()) 4 { 5 ...... 6 } 7 ...... 8 }
ObtainRequest就是调用了this.Request.ReadRequest()方法
所以上面可以变成
1 this.Request.ReadRequest() // 获取请求信息 2 this.Response.ResendRequest() // 将请求报文重新包装后转发给目标服务器 3 this.Response.ReadResponse () // 读取从目标服务器返回的信息 4 this.ReturnResponse() // 将从目标服务器读取的信息返回给客户端
后面的代码比较复杂,我们将不再详细的列出代码,只对其中的关键知识点进行讲解,只要能打通整个环节就行了。
在this.Request(ClientChatter类型).ReadRequest() 里 调用 this.ClientPipe(ClientPipe类型).Receive 来从客户端读取信息
下面我们来看下代码(ClientChatter类的ReadRequest方法)
1 Do 2 { 3 // 全局变量,用来存读取到的请求流 4 this.m_requestData = new MemoryStream(0x1000); 5 byte[] arrBuffer = new byte[_cbClientReadBuffer]; 6 try 7 { 8 iMaxByteCount = this.ClientPipe.Receive(arrBuffer); 9 } 10 catch (Exception exception) 11 { 12 flag = true; 13 } 14 if (iMaxByteCount <= 0) 15 { 16 flag2 = true; 17 } 18 else 19 { 20 if (this.m_requestData.Length == 0L) 21 { 22 this.m_session.Timers.ClientBeginRequest = DateTime.Now; 23 int index = 0; 24 while ((index < iMaxByteCount) && ((arrBuffer[index] == 13) || (arrBuffer[index] == 10))) 25 { 26 index++; 27 } 28 this.m_requestData.Write(arrBuffer, index, iMaxByteCount - index); 29 } 30 else 31 { 32 this.m_requestData.Write(arrBuffer, 0, iMaxByteCount); 33 } 34 } 35 } 36 while ((!flag2 && !flag) && !this.isRequestComplete()); 37
还记得前面的讲解吗,this.ClientPipe.Receive 其实就是对Socket.Receive的简单封装,而this.ClientPipe里封装的那个Socket就是和客户端进行通讯的那个Socket,如果不记得了,可以翻回去看一看 :)
这里没什么太难理解的,就是不停的读取请求信息,直到读取完成为止。读取的同时将这些请求信息存在this.m_requestData(MemoryStream类型)这个全局变量里。
不过有一点要注意一下,那就是判断接收结束的方法。 也就是while里面的那三个条件。 一个是 flag2 = true , 从上面的代码可以看出,就是iMaxByteCount = 0,另外一个条件是 flag = true,也就是出意外了,还有一个就是 isRequestComplete() 。
出意外了自然结束,这个不难理解,但为什么有了 iMaxByteCount = 0 了,还要再多加个isRequestComplete()的判断呢? iMaxByteCount = 0 了,不就代表,已经读取完客户端发过来的请求数据了吗,当然不是,这和iMaxByteCount什么时候为0有关,那么iMaxByteCount什么时候为0呢,这个我们先要来看看他的定义,我们知道这个iMaxByteCount 其实就是 Socket.Receive(this.ClientPipe.Receive就是他的封装,又讲一遍了)的返回值, 那么Socket.Receive是怎么定义的呢。
http://technet.microsoft.com/zh-cn/library/8s4y8aff(v=vs.90)
Socket.Receive(byte[] buffer) 从绑定的 Socket 套接字接收数据,将数据存入接收缓冲区。 参数 buffer 类型:System.Byte() Byte 类型的数组,它是存储接收到的数据的位置。 返回值 类型:System.Int32 接收到的字节数。
从上面的定义我们可以看到这个iMaxByteCount其实就是指Socket.Receive每次从客户端读取的数据长度。这不就结了,搞了半天还不是当读取到0的时候就代表再也读不到数据了吗,做人要有耐心,我们再往下看看他后面的备注
如果没有可读取的数据,则 Receive 方法将一直处于阻止状态,直到数据可用,除非使用 Socket.ReceiveTimeout 设置了超时值。如果超过超时值,Receive 调用将引发 SocketException。如果您处于非阻止模式,并且协议堆栈缓冲区中没有可用的数据,则 Receive 方法将立即完成并引发 SocketException。您可以使用Available 属性确定是否有数据可以读取。如果 Available 为非零,请重试接收操作。
如果当前使用的是面向连接的 Socket,那么 Receive 方法将会读取所有可用的数据,直到达到缓冲区的大小为止。如果远程主机使用 Shutdown 方法关闭了 Socket连接,并且所有可用数据均已收到,则 Receive 方法将立即完成并返回零字节。
备注里已经讲的很清楚了,当读不到数据的时候,Receive方法,会阻塞在那里,直到有数据到达,或者超时为止,而不是象我们想象的那样返回0,返回0只有一种情况,就是Socket.Shutdown(),也就是连接的那个Socket关闭了他的连接,在这里也就是客户端关闭了连接。
好的Socket的一些相关知识已经储备完了,但是要想明白刚才的问题,还需要一些其它知识的储备,那就是HTTP的报文和连接管理
众所周知(一般都是这样写的),HTTP协议是依托TCP协议的,客户端以HTTP请求报文的形式利用TCP将请求发送给服务端,服务端接收到来自客户端的请求报文,然后解析请求报文,再进行相应的处理,最后将处理结果以响应报文的形式发送回给客户端。
从上面的描述中,我们知道,HTTP的报文分为两种,请求报文和响应报文,这里先讲请求报文
HTTP请求报文的形式如下:

<method><request-url><version>
<header>
<entity-body>
<method>: get/post/put/delete/trace等。一般搞WEB开发的对GET和POST会比较熟悉。
<request-url> :也就是要请求的资源的URL。例如 /a.jpg 表示根目录下的a.jpg
<version>: 所用HTTP协议的版本 。例如HTTP1.0 或HTTP1.1
以上三个部分也被合起来称为<request-line>请求行
<header>:首部,可以有0个或者多个,每个首部都是key:value的形式,然后以CRLF(回车换行)结束 例如: host:www.domain.com
<entity-body>: 任意数据组成的数据块,例如POST时提交的数据,上传文件时文件的内容都放在这里。
<header>和<entity-body>通过两个CRLF分隔
具体的就不再详细的说明了,可以自行查HTTP的协议说明。这里我们只简单的举个例子,让大家有个直观的认识。
post / http/1.1 <method><request-url><version> CRLF host:www.domain.com <header> CRLF content-length:8 CRLF connection:keep-alive CRLF CRLF a=b&b=cd <entity-body>
上面就是一个简单的请求报文(红字部分是结构说明,不属于报文的内容),在这个报文里,请求方法是POST,使用的协议是HTTP1.1,发送到的主机是www.domain.com,内容长度是8。内容是a=b&b=cd 。
在我们的源码里时使用了一个类:HTTPRequestHeaders来封装(映射)这些报文里的报头信息,也就是除entity-body以外的部分。映射后的情形是这样的,这里假设有一个变量reqHeaders它就是HTTPRequestHeaders的实例,我们把刚才的示例报文分析完后然后映射到这个实例,那么这时使用
reqHeaders.HTTPMethod 得到的就是 post ; reqHeaders.HTTPVersion 得到的就是http/1.1 reqHeaders[“host”] 就是 www.domain.com reqHeaders[“content-length”] 就是 8
其它以此类推
报文讲完了,下完再简单讲讲HTTP连接管理。
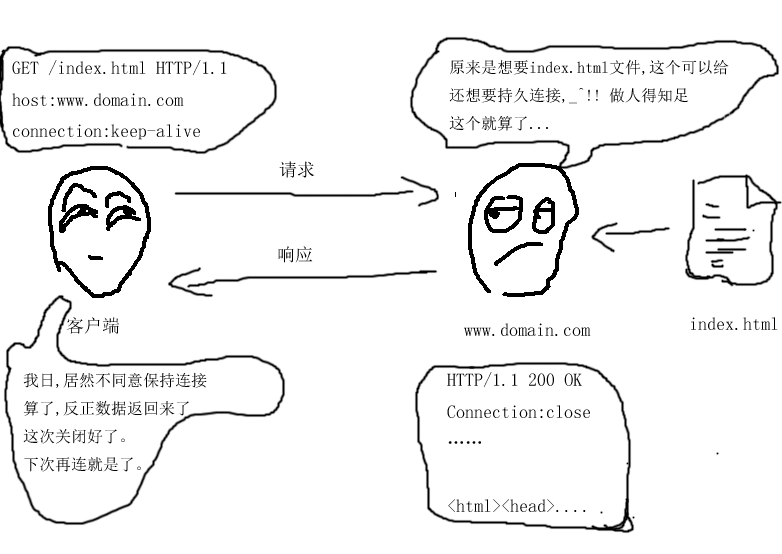
开篇的时候,我们用了一张简单的图来说明HTTP的一次会话(没有代理服务器的情况)情况,但这张图过于简单,反映不了HTTP协议的通讯细节,现在我们已经有了足够的知识储备,为了更好的理解HTTP的连接管理,我们有必要在程序的层面,再将客户端与服务端的一次会话说明一遍。
客户端先建立一个和服务端的TCP连接,然后利用这个TCP连接将一份象上面一样的HTTP请求报文发到服务端,服务端监听到这一个请求,然后利用Accept建立一条和这个客户端的专门连接,然后利用这个专门连接读取这一段请求报文,然后再分析这段报文,当他看到有connection:keep-alive的首部时,服务端就知道,客户端要求建立持久连接,服务端根据实际情况对这个请求进行处理。
1. 如果服务端不同意建立持久连接,那么会在响应报文里加上一个首部 connection:close 。然后再利用这个专门连接将这个响应报文发回给客户端,接着服务端就会关闭这条连接,最后,客户端会收到服务器刚才的应答信息,看到了connection:close,这时候客户端就知道服务端拒绝了他的持久连接,那么,客户端在完成这次响应报文的解析后会关闭这条连接,当下次再有请求发送到这个服务器的时候,会重新建一个连接。
2. 如果服务端同意建立持久连接,那么会在响应报文里加上一个首部connection:keep-alive。然后利用这个专门连接,将这个响应报文发回给客户端,但不关闭这条连接,而是阻塞在那里,直到监视到有新的请求从这个连接传来,再接着处理。客户端收到刚才的响应报名,看到了connection:keep-alive,于是客户端知道服务端同意了他的持久连接请求,那么客户端也不会关闭这个连接,当有新的向此服务器发送的请求时,客户端就会通过这个已经打开的连接进行传输,这样就可以节省很多时间(连接建立的时间是很耗时的)。
好了,所有的相关知识都已经储备完了,可以接着上面讲了。
从上面我们知道,当客户端将请求报文发送到服务器后,连接是不会关闭的,客户端是否关闭连接,要等到服务器响应后才决定。那也就是说一般情况下,我们是不可能通过iMaxByteCount=0(iMaxByteCount= Socket.receive())来判断是否已经读取完了客户端的请求报文(用户在请求过程上,关闭了浏览器可能会发生这种情况)。 那么我们又怎么来判断请求报文已经全部接收完成了呢。
答案就是利用content-length首部。 在刚才的例子报文里就有这个头部,我们再把刚才的例子复制过来看一看。
post / http/1.1 <method><request-url><version> CRLF host:www.domain.com <header> CRLF content-length:8 CRLF connection:keep-alive CRLF CRLF a=b&b=cd <entity-body>
看到上面的content-length:8 这句了吧,这就是content-length首部了。这个首部就是告诉你<entity-body>(在上面的例子里就是a=b&b=cd)的长度,那么<head>头部解析完后再读取content-length个字符,不就表示此次的请求已经全部读取完成了吗。
我们来看一下 ClientChatter.cs里的isRequestComplete方法。里面有段代码
1 if (this.m_headers.Exists("Content-Length")) 2 { 3 // 处理代码 4 }
这一段就是处理这种情况的。
当然content-length并不能判断所有的情况,只有确切的知道entity-body长度的情况下,content-length才是有意义的。但是事实上entity-body的长度并不总是可以预知的,尤其在传一些大文件的时候,为了节省资源和时间,一般会采用分块传输的方式,采用分块传输的时候,会在报文里增加一个首部transfer-encoding:chunked,另外在entity-body里也要遵循一定的格式,这种情况在请求报文里很少见,因为请求报文在不选择文件进行提交的时候,一般报文都很小,这种情况主要出现在响应报文里,后面讲响应报文的时候,会详细讲一下,这里只要提一下,因为Session.isRequestComplete 有处理这种情况的代码
1 if (this.m_headers.ExistsAndEquals("Transfer-encoding", "chunked")) 2 { 3 // 处理代码 4 }
上面两段代码没有帖出来具体的内容,各位可以自行去看一看,其实原理知道了,完全可以自己去写实现的代码,只要上面三种情况全部考虑到就可以了。
另外在ClientChatter.cs里的isRequestComplete方法里还有一句要注意下
if (!this.ParseRequestForHeaders())
这个就是分析报头的代码了,前面提到过,会将原始报头映射到一个HTTPRequestHeaders类型的对象里,那么这个方法就是做那个的了,此方法执行完成后,会把原始的请求报文流中的报头部分(除entity-body以外的部分)分析到一个HTTPRequestHeaders类型的私有属性(m_headers)里。 然后在ClientChatter里又暴露了一个Public的属性Headers来访问这个属性。当然这个方法里还会记录entity-body的起始位置,这样,在后面的TakeEntity方法就可以通过这个位置读取entity-body的内容了。而TakeEntity会在 Session类的ObtainRequest里被调用
this.RequestBodyBytes = this.Request.TakeEntity();
Session类的ObtainRequest方法终于分析完成了,调用套调用,是不是已经晕了,没关系,现在我们再来理一下刚才的调用过程
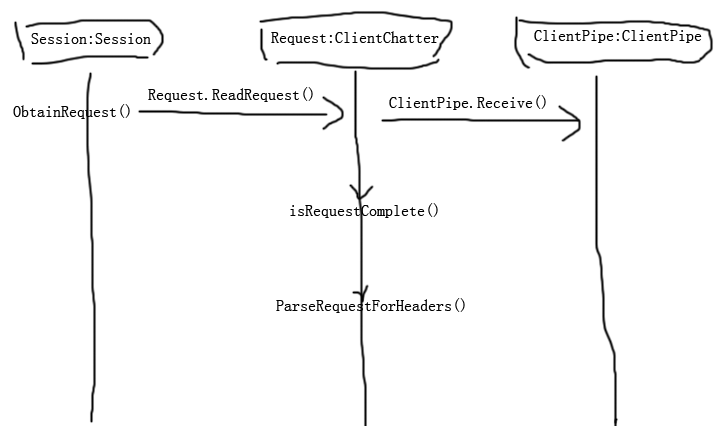
Okay,现在是不是又有点清晰了,那么调用完Session的ObtainRequest方法后,程序会变成什么样呢,经过刚才的分析其实已经很清楚了。
这时在Session类里,只要使用this.Request.Headers就可以获得所有的报头信息了。
而报体部分entity-body 则是通过this.RequestBodyBytes 进行调用 。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号