
Supervised Learning-Regression
假设我们有一张房子属性及其价格之间的关系表(如下图所示) ,根据这些数据如何估计其他房子的价格?我们的第一个反应肯定是参考属性相似的房子的价格。在属性较少时这个方法还行得通,属性太复杂时就不那么简单了。很显然,我们最终目的是根据这些数据学习到房子属性和价格之间的某种关系,然后利用这种关系预测其他房子的价格。
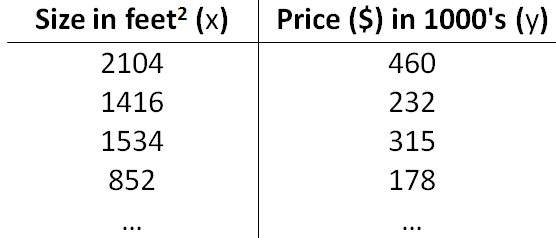
我们将问题形式化,给出如下相关说明。训练集—用于学习这种关系的数据集合;测试集—用于测试所学关系准确性的数据集合;\(x\)—输入变量/特征;\(y\)—目标变量;\((x,y)\)—单个训练样本;\(m\)—训练集中的样本数目;\(n\)—特征维度;\((x^{(i)},y^{(i)})\)—第\(i\)个训练样本。
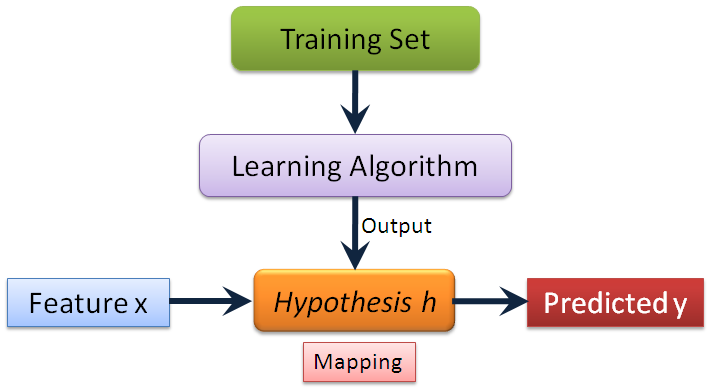
在这类问题中,我们可以利用目标变量调整模型,属于监督学习(Supervised Learning)范畴。由于目标变量是连续的,是一个典型的回归(Regression)问题。监督学习的框架如下图所示:设计学习算法,再用训练集进行训练,最后得到一个反映输入变量和目标变量之间映射关系的模型,利用该模型可以预测出测试数据的目标变量。
在监督学习中,我们有\(m\)个训练样本组成的训练集。如何表述模型是设计学习算法的第一步。在这里,我们简单地采用一个线性模型
\begin{equation}h_{\theta}(x)=\theta_0+\theta_1x_1+\cdots+\theta_nx_n=\sum_{i=0}^n\theta_ix_i=\theta^Tx\end{equation}
其中\(\theta_0\)为截距,\(\theta_1,\cdots,\theta_n\)为输入变量\(x)\)每一维变量对应的参数。为了便于表述,引入\(x_0=1\)。
学习算法的职责在于利用训练集选择合适的参数\(\theta\),使得模型尽可能做出准确的预测。在回归问题中,使\(h_{\theta}(x)\)以最大限度接近\(y\)是最合理的切入角度。我们使用如下的代价函数(cost function):
\begin{equation}J(\theta)=\frac{1}{2}\sum_{i=1}^m(h_{\theta}(x^{(i)})-y^{(i)})^2\end{equation}
\(J(\theta)\)是关于参数\(\theta\)的函数,我们要做的就是\(\min_{\theta}J(\theta)\)。
接下来讨论两类求解算法。一类是迭代形式的搜索算法(Search algorithm),另一类是解析表达式。
搜索算法的基本策略就是先在参数空间赋予参数\(\theta\)一个猜测的初始值,然后以此初始值为出发点,不断修改\(\theta\)以减小\(J(\theta)\),直到\(\theta\)收敛到可使\(J(\theta)\)收敛到最小值,这时的参数\(\theta\)就是我们要求解的可使模型性能最好的参数。下面,我们以梯度下降(Gradient descent)为基础,介绍三种搜索算法。
梯度下降的思想源于函数沿着梯度的反方向下降速度最快,参数更新规则为
\begin{equation}\theta_i=\theta_i-\alpha\frac{\partial}{\partial\theta_i}J(\theta)\end{equation}
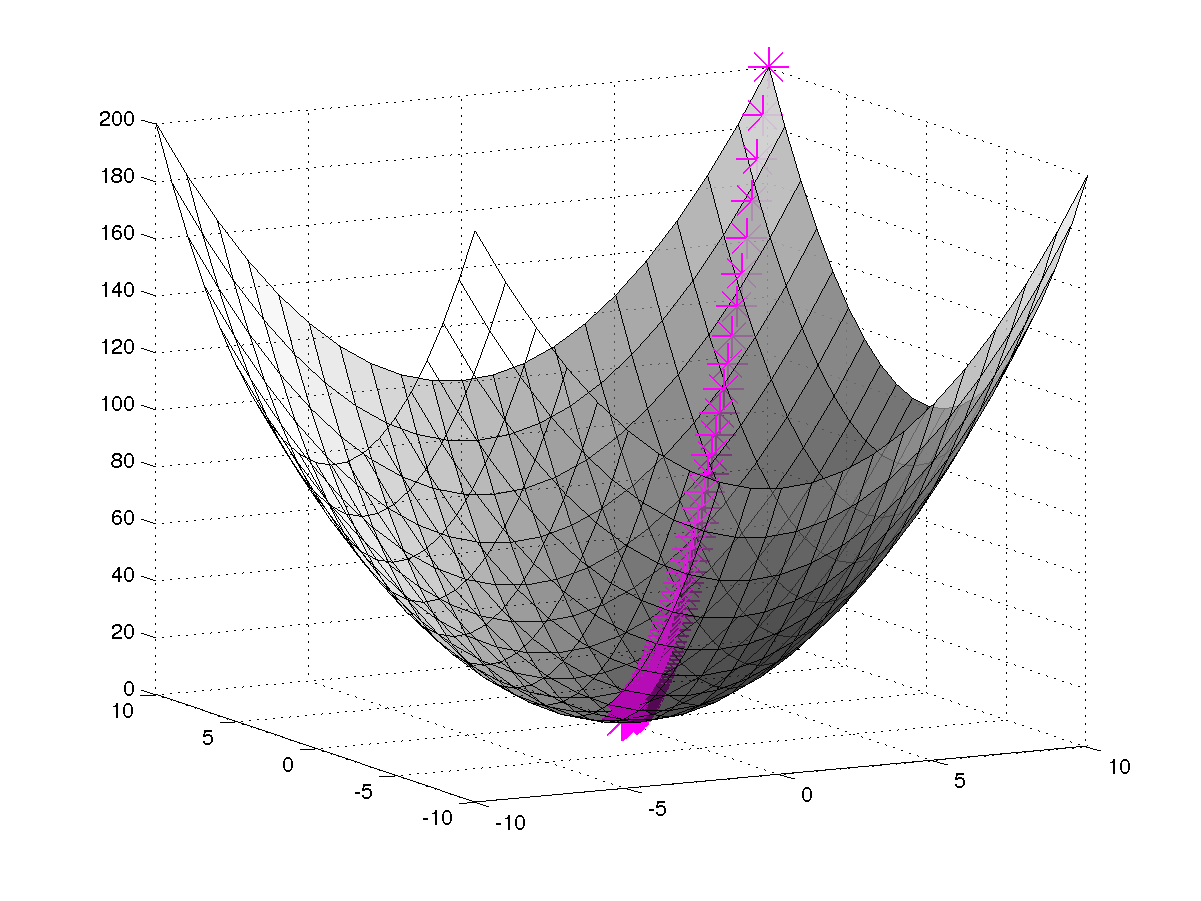
其中\(\alpha\)为学习率(learning rate),控制在梯度反方向上移动的步长。这是一个很自然的算法,只要我们始终沿着梯度方向走,就能不断减小\(J(\theta)\)。但是该算法存在两个问题,一是依赖初始点的位置,二是依赖于学习率。如果\(J(\theta)\)仅存在一个极小值,那么初始点的选取无所谓,最终总会收敛到全局最优解(如下左图);否则,\(J(\theta)\)会因初始点的不同而收敛到不同极小值,只能达到局部最优,而局部最优解里面也存在优劣之分(如下右图),我们的问题属于第一种情况。学习率\(\alpha\)太小,收敛花费的时间太长;但\(\alpha\)过大,又很可能会错过极小值。针对第一个问题,现在的解决办法就是选择不同的初始值进行迭代,最后选择最优的解;第二个问题的解决办法有线性搜索(Line Search)等,这里不进行介绍。
 |
 |
现在仅考虑单个样本\((x,y)\)情况下的梯度下降问题:
\begin{align}\frac{\partial}{\partial\theta_j}J(\theta)&=\frac{\partial}{\partial\theta_i}\frac{1}{2}(h_{\theta}(x)-y)^2\\&=2\cdot \frac{1}{2}(h_{\theta}(x)-y)\cdot \frac{\partial}{\partial\theta_i}(h_{\theta}(x)-y)\\&=(h_{\theta}(x)-y)\cdot\frac{\partial}{\partial\theta_i}(\theta_0x_0+\theta_1x_1+\cdots+\theta_nx_n-y)\\&=(h_{\theta}(x)-y)\cdot x_i\end{align}
结合公式(3)和公式(7),我们得到的参数更新规则如下:
\begin{equation}\theta_i=\theta_i-\alpha(h_{\theta}(x^{(j)})-y^{(j)})x_i^{(j)}\end{equation}
有了上述更新规则,下面就直接引出三种搜索算法:

批梯度下降(Batch gradient descent)的特点在于每次更新参数都要扫描训练集中的所有样本。对于较小的训练集,该方法还是不错的;但对于人口普查等有海量样本的数据库就不合适了,其计算量之大可想而知。

随机梯度下降(Stochastic gradient descent,SGD)规避了批梯度下降的缺陷,每次只用一个样本更新所有参数。对于大的数据集,随机梯度下降比批梯度下降更快趋近到极小值。但随机梯度下降并不能保证收敛到极小值,而是会在极小值邻域振荡。在实际应用中,最小值的邻域也在可接受的范围内。

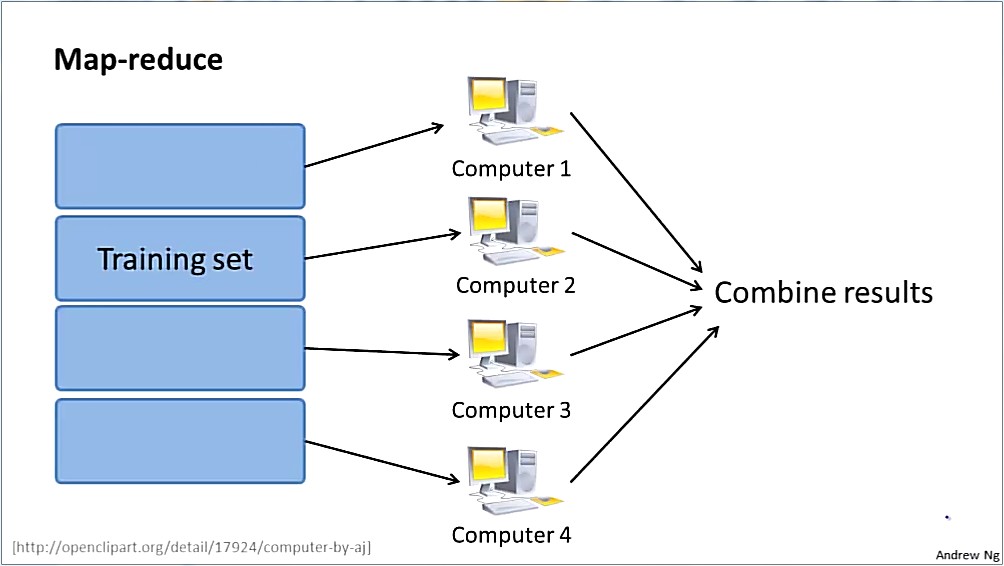
算法3是前面两种算法的折衷方案,其思路是先将整训练集随机置乱,再以滑动窗口形式将其划分成若干块,然后在每块上以批梯度下降的方式更新参数,以块为单位用随机梯度下降方式更新参数。这样做的有两点好处:一是综合了算法1和2的优点;二是分块计算为并行处理提供了条件(如下图所示)。
我们怎样判断是否收敛呢?这里简单介绍两种办法:
- 参数\(\theta\)在连续几次迭代中变化非常小,可视为达到收敛
- 函数值\(J(\theta)\)在连续几次迭代中没什么变化也可视为处于收敛状态
下面,我们讨论该问题的解析形式求解方法。
首先,有必要在这里提供基本的矩阵知识:
- 矩阵的迹(Trace)操作
\begin{align}&Tr(A)=\sum_{i=1}^nA_{ii}\\&Tr(a)=a\\&Tr(AB)=Tr(BA)\\&Tr(ABC)=Tr(CAB)=Tr(BCA)\\\end{align}
- 矩阵的求导规则
函数\(f:\mathbb{R}^{m\times n}\mapsto \mathbb{R}\),将\(m\times n\)的矩阵映射到实数空间,其求导规则如下:
\begin{equation} \nabla_Af(A)=\left[ \begin{array}{ccc}\frac{\partial f}{\partial A_{11}} & \cdots & \frac{\partial f}{\partial A_{1n}}\\\vdots & \ddots & \vdots \\\frac{\partial f}{\partial A_{m1}} & \cdots & \frac{\partial f}{\partial A_{mn}}\end{array} \right]\end{equation}
针对矩阵迹求导的规则如下:
\begin{align} &\nabla_ATr(AB)=B^T\\ &\nabla_ATr(A)=\nabla_ATr(A^T)\\ &\nabla_ATr(ABA^TC)=CAB+C^TAB^T\\ &\nabla_ATr(BAC)=B^TC^T=CB\\ &\nabla_{A^T}f(A)=(\nabla_Af(A))^T \end{align}
更多内容请参考《Matrix Cookbook》,这份文档只给出结论,没有具体证明,可以作为日常矩阵运算的参考手册,内容比较全面。
定义矩阵\(X\)为每个训练样本在行级叠加成的矩阵:\(X=\left[ \begin{array}{c}(x^{(1)})^T\\ \vdots\\ (x^{(m)})^T \end{array}\right],\vec{y}=\left[ \begin{array}{c}y^{(1)}\\ \vdots\\ y^{(m)}\end{array}\right]\)。
代价函数转化为矩阵的形式:
\begin{equation} J(\theta)=\frac{1}{2}\sum_{i=1}^m(h_\theta(x^{(i)})-y^{(i)})^2=\frac{1}{2}(X\theta-\vec{y})^T(X\theta-\vec{y}) \end{equation}
我们的问题只存在一个最优解,所以最小值肯定是在极值点处取得,直接对\(\theta\)求导即可得到最优参数:
\begin{align}\nabla_\theta J(\theta)&=\frac{1}{2}\nabla_\theta Tr[(X\theta-\vec{y})^T(X\theta-\vec{y})]\\ &=\frac{1}{2}\nabla_\theta Tr[\theta^TX^TX\theta-\theta^TX^T\vec{y}-\vec{y}^TX\theta+\vec{y}^T\vec{y}]\\ &=\frac{1}{2}[\nabla_\theta Tr(\theta\theta^TX^TX)-\nabla_\theta Tr(\theta^TX^T\vec{y})-\nabla_\theta Tr(\vec{y}^TX\theta)]\\ &=\frac{1}{2}(X^TX\theta+X^TX\theta-X^T\vec{y}-X^T\vec{y})=0\\ &\Rightarrow \theta=(X^TX)^{-1}X^T\vec{y} \end{align}
上述结果看起来相当完美!稍微留意一下我们就可以发现,矩阵\((X^TX)^{-1}\)不一定存在。当样本数目\(m\)小于特征的维度\(n\)时,\((X^TX)^{-1}\)肯定是不存在的;反过来,我们也只能说\((X^TX)^{-1}\)可能存在。这个问题我还不知道怎么破...
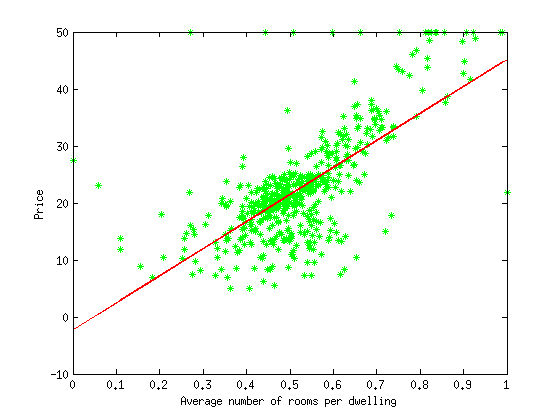
下面展示一下我在数据集Housing Data Set上做的实验。模型采用上述的线性回归,以批梯度下降方式学习最优参数。编程语言为Matlab,数据集在data目录下,minFunc目录里面是采用了线性搜索的梯度下降工具包,代码在这里下载。数据集中一共有506个样本,每个样本有14个属性,最后一个属性为房子价格,其他13个属性则作为每个样本的特征,更详细的描述请移步Housing Data Set。为了便于观察实验结果,我选取的第6个属性作为每个样本的特征,因为这个属性在整个数据集上变换范围比较小,绘制的图形美观一些。如果要改用其他的数据,只需修改loadData.m这个文件。最后的展示的结果是二维的图,绿色的为样本点,红色的直线为我们学习到的线性模型。
在回归问题中,为什么最小二乘(Least Square)是代价函数的一个合理选择?我们先给出两个假设,然后从概率论角度进一步解释线性回归中最小二乘是如何与最大似然(Maximum Likelihood)统一的。
- 假设一:样本特征和输出变量间的关系为
\begin{equation}y^{(i)}=\theta^Tx^{(i)}+\epsilon^{(i)}\end{equation}
其中误差项\(\epsilon^{(i)}\)既可以被看作未考虑的其他相关因素,也可以被视为随机噪声。
- 假设二:\(\epsilon^{(i)}\)满足独立同分布(Independently Identically Distributed,IID)的高斯模型\(\epsilon^{(i)}\sim\mathcal{N}(0,\sigma^2)\),其概率密度函数如下:
\begin{equation}p(\epsilon^{(i)})=\frac{1}{\sqrt{2\pi}\sigma}\exp\left(-\frac{\epsilon^2}{2\sigma^2}\right)\end{equation}
由上式很容易得到如下的关系:
\begin{equation}p(y^{(i)}|x^{(i)};\theta)=\frac{1}{\sqrt{2\pi}\sigma}\exp(-\frac{(y^{(i)}-\theta^Tx^{(i)})^2}{2\sigma^2})\end{equation}
根据独立同分布的假设,似然函数形式如下:\begin{align}L(\theta)&=p(\vec{y}|X;\theta)\\&=\prod_{i=1}^mP(y^{(i)}|x^{(i)};\theta)\\&=\prod_{i=1}^m\frac{1}{\sqrt{2\pi}\sigma}\exp\left(-\frac{(y^{(i)}-\theta^Tx^{(i)})^2}{2\sigma^2}\right)\end{align}
为便于计算,求得相应的对数似然函数:
\begin{align}\ell(\theta)&=\log L(\theta)\\&=\log\prod_{i=1}^m\frac{1}{\sqrt{2\pi}\sigma}\exp\left(-\frac{(y^{(i)}-\theta^Tx^{(i)})^2}{2\sigma^2}\right)\\&=\sum_{i=1}^m\log\frac{1}{\sqrt{2\pi}\epsilon}\exp\left(-\frac{(y^{(i)}-\theta x^{(i)})^2}{2\sigma^2}\right)\\&=m\log\frac{1}{\sqrt{2\pi}\sigma}-\frac{1}{2\sigma^2}\sum_{i=1}^m(y^{(i)}-\theta^Tx^{(i)})^2\end{align}
根据最大似然的规则,能使公式(34)最大的参数\(\theta\)为最佳参数。最大化\(\ell(\theta)\)等价于最小化\(J(\theta)=\frac{1}{2}\sum_{i=1}^m(y^{(i)}-\theta^Tx^{(i)})^2\)。在前面两个假设的前提下,最小二乘回归与最大似然是对应统一的。
作者:JeromeWang
邮箱:yunfeiwang@hust.edu.cn
出处:http://www.cnblogs.com/jeromeblog/
本文版权归作者所有,欢迎转载,未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号