

[Spark内核] 第33课:Spark Executor内幕彻底解密:Executor工作原理图、ExecutorBackend注册源码解密、Executor实例化内幕、Executor具体工作内幕
本課主題
- Spark Executor 工作原理图
- ExecutorBackend 注册源码鉴赏和 Executor 实例化内幕
- Executor 具体是如何工作的
[引言部份:你希望读者看完这篇博客后有那些启发、学到什么样的知识点]
更新中......
Spark Executor 工作原理图
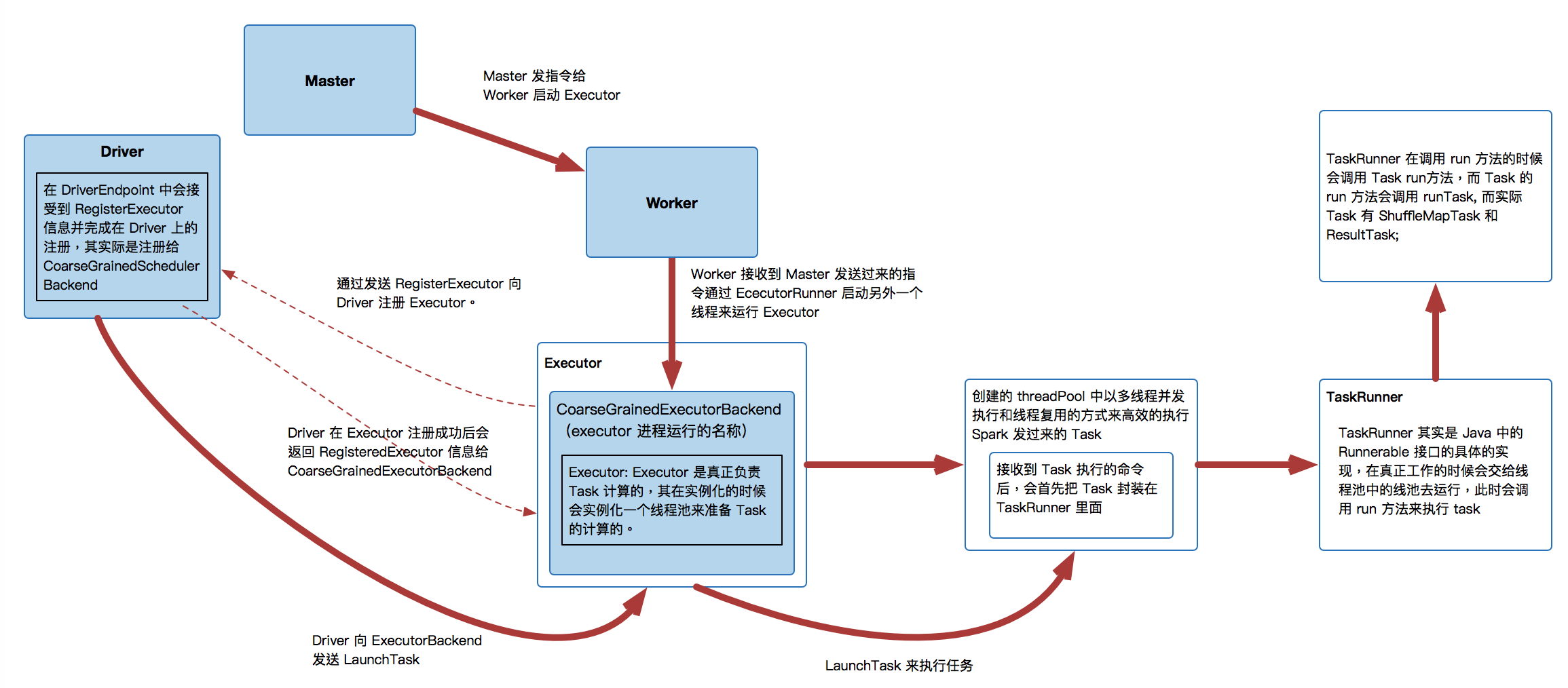
- 第一步:Master 发指令给 Worker 启动 Executor;
- 第二步:Worker 接收到 Master 发送过来的指令通过 EcecutorRunner 远程启动另外一个线程来运行 Executor;
- 第三步:通过发送 RegisterExecutor 向 Driver 注册 Executor,这个时侯Worker 会启动另外一个进程来向 Driver 发送注册的信息,思考题:为什么要多开一个新进程而不在原有的 Worker 进程里发送信息给 Driver 呢?因为Worker 主要是管理当前机器上的资源的,而当前机器上的资源有变动的时候需要汇报给 Master,Worker 不是用来计算的,所以不可以在 Worker 里做计算;而且,在 Spark 中可能有很多不同的的应用程序,有很多应用程序你就需要有很多 Executor,如果你不是为每个 Executor 启动一个进程的话,这会导致当一个程序崩溃时,其他程序也会崩溃。
需要特别注意的是在 CoarseGrainedExecutorBackend 启动时向 Driver 注册 Executor 其实质上是注册 ExecutorBackend 实例,和 Executor 实例之间没有直接关系! CoarseGrainedExecutorBackend 是 Executor 运行所在的进程名称,Executor 才是真正处理 Task 的对象Executor 内部是通过线程池的方式来完成 Task 的计算的,CoarseGrainedExecutorBackend 和 Executor 是一对一的关系![]()
![]()
CoarseGrainedExecutorBackend 是一个消息通信体(其实现了 (ThreadSafeRpcEndPoint) ,可以发送信息给 Driver 并可以接受 Driver 中发过来的指令,例如启动 Task 等。![]()
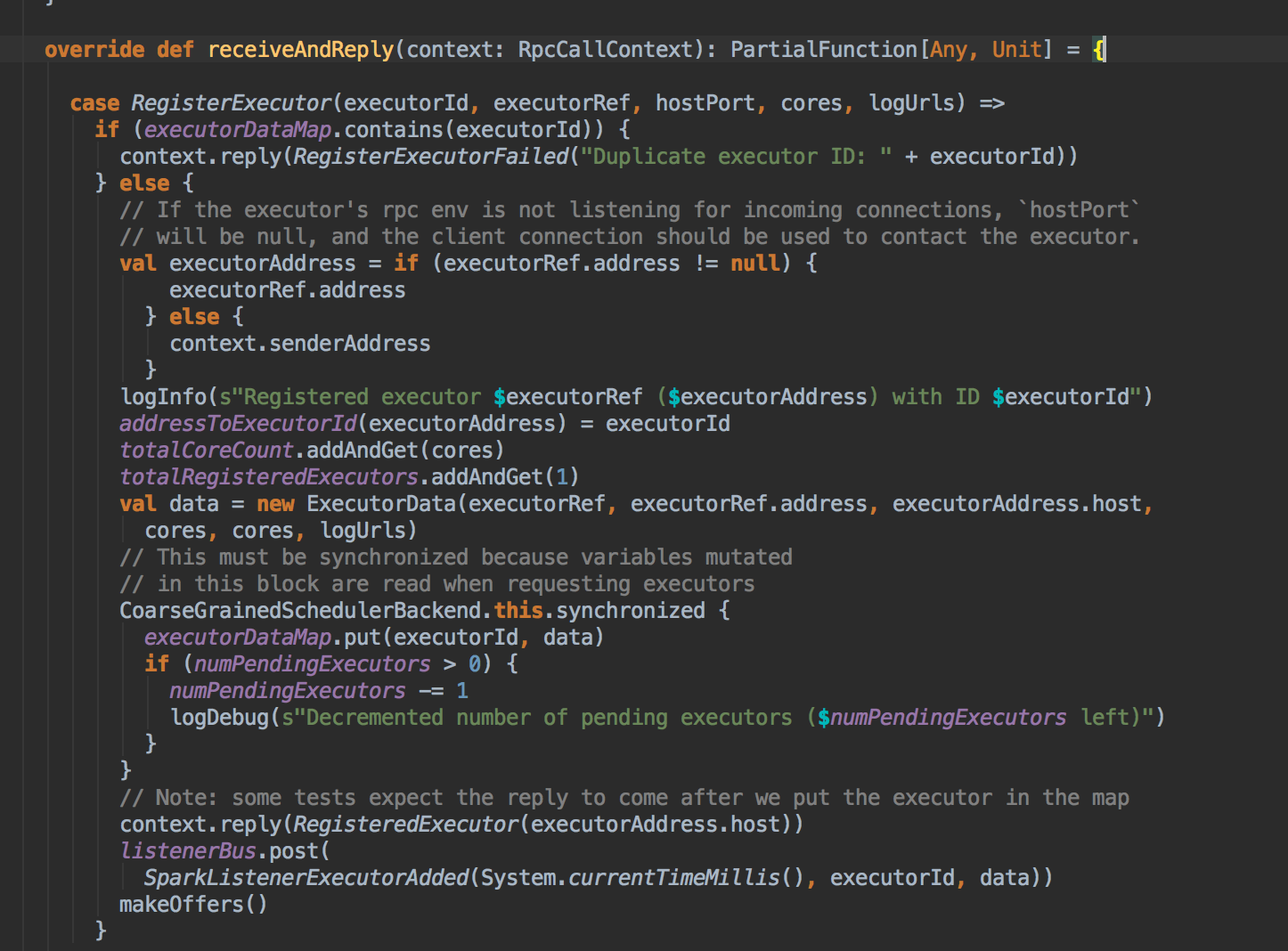
- 第四步:在 DriverEndpoint 中会接受到 RegisterExecutor 信息并完成在 Driver 上的注册,其实际是注册给 CoarseGrainedSchedulerBackend
![]()
![]()
![]()
在 Driver 进程中有两个至关重要的 Endpoint: (注册的内幕源码可以参考第28课:Spark天堂之门解密)
1) ClientEndpoint: 主要负责向 Master 注册当前的程序,是 AppClient 的内部成员;![]()
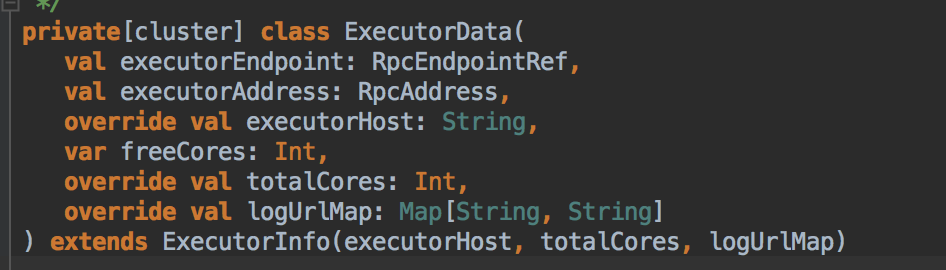
2) DriverEndpoint: 这是整个程序运行时候的驱动器,是CoraseGraninedSchedulerBackend 的内部成员。 - 在 Driver 中通过 ExecutorData 封装并注册 ExecutorBackend 的信息到 Driver 的内存数据结构 executorMapData 中:
![]()
- 实际在执行的时候DriverEndpoint 会把信息写下CoarseGraninedSchedulerBackend 的内存数据结构executorMapData 中,所以说最终是注册给了CoarseGraninedSchedulerBackend,也就是说CoarseGraninedSchedulerBackend 掌握了为当前程序分配的所有的ExecutorBackend 进程,而每一个ExecutorBackend 进程实例中会通过Executor对象来负责具体Task 的运行。
- 在运行的时候使用 synchronised 关键字来保证 executorMapData 安全的并发写操作。
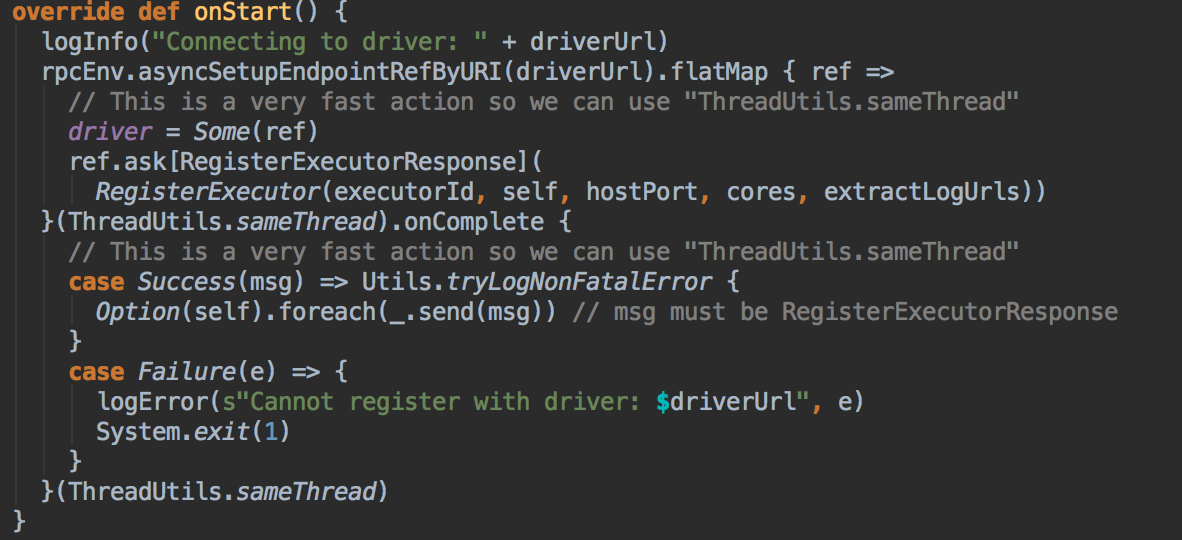
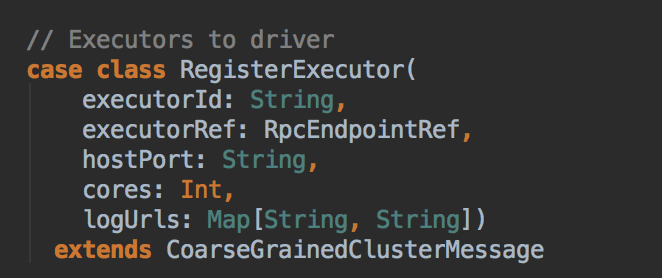
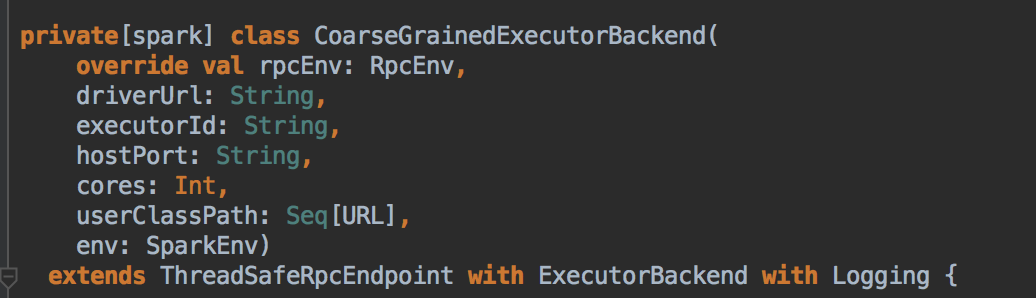


ExecutorBackend 注册源码鉴赏和 Executor 实例化内幕
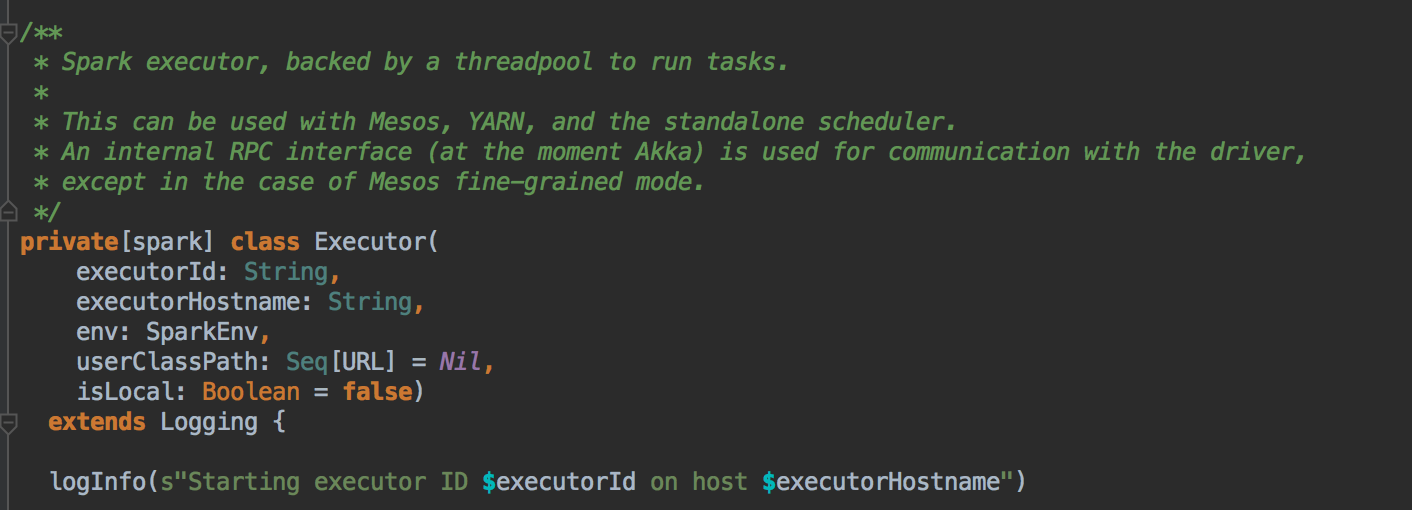
- CoarseGrainedExecutorBackend 收到 DriverEndpoint (CoraseGrainedSchedulerBackend) 发送过来的 RegisteredExecutor 消息后会启动 Executor 实例对象,而 Executor 实例对象是事实上负责真正的 Task 的计算的;
![]()
![]()
![]()
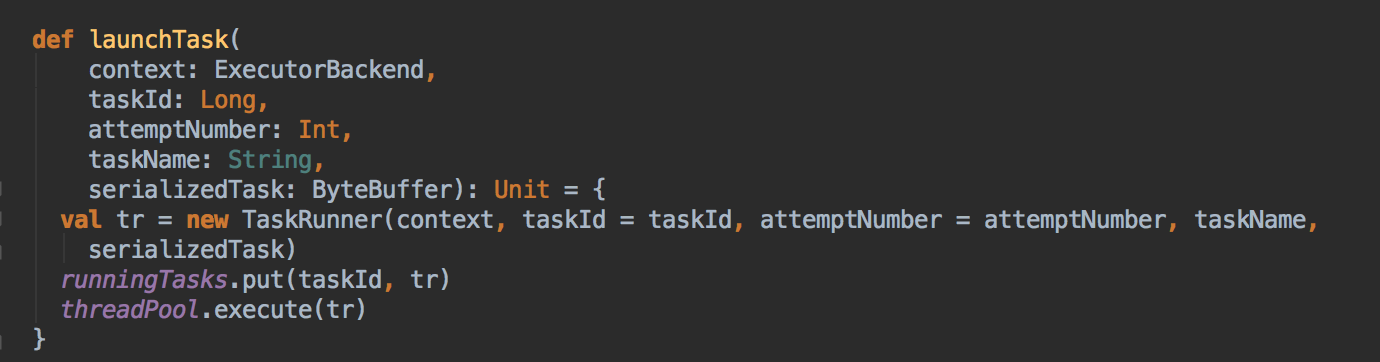
- Executor在实例化的时候会实例化一个线程池来准备 Task 的计算的。
![]()
![]()



Executor 具体是如何工作的
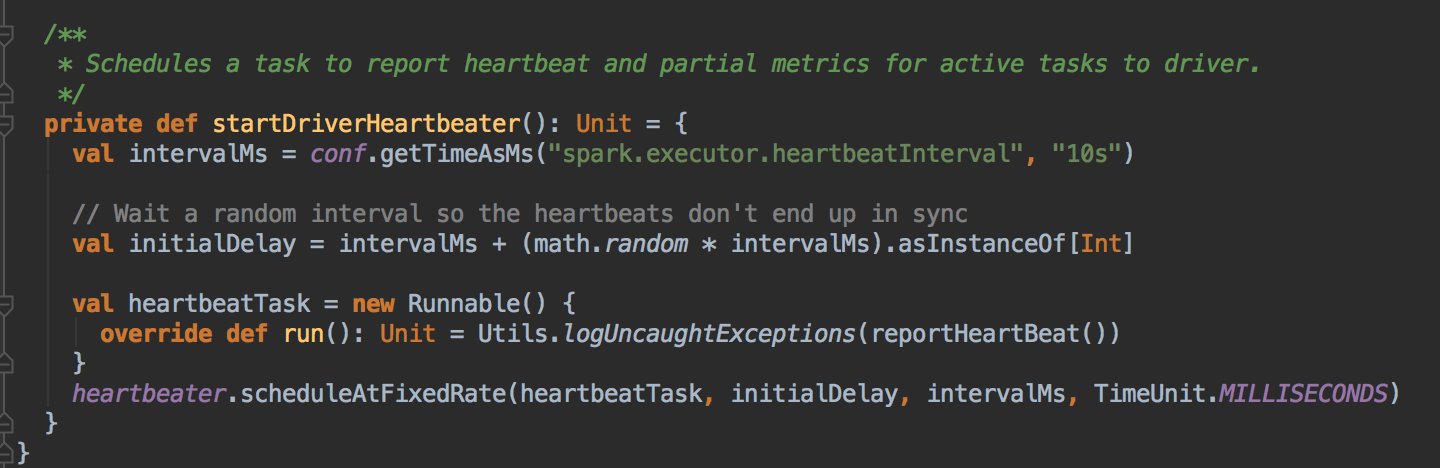
- 当 Driver 发送过来 Task 的时候,其实是发送给了 CoarseGrainedExecutorBackend 这个 RpcEndpoint ,而不是直接发送给了 Executor (Executor 由于不是消息循环体,所以永远也无法直接接受远程发过来的信息);
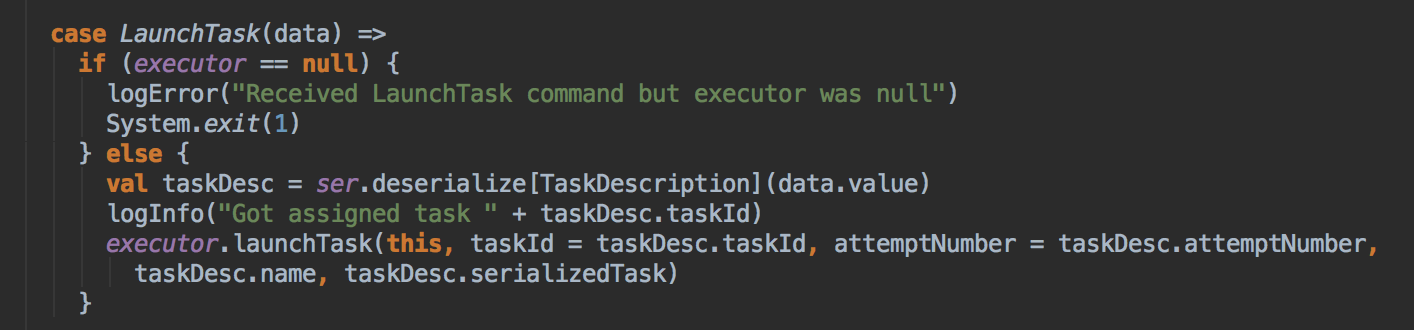
- ExecutorBackend 在收到 Driver 中发送过来的消息后会通过调用 LaunchTask 来交给 Executor 去执行:
![]()
![]()
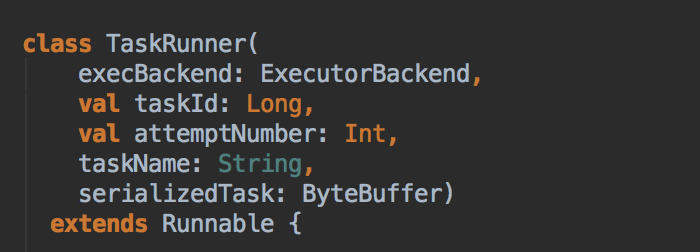
- 创建的 threadPool 中以多线程并发执行和线程复用的方式来高效的执行 Spark 发过来的 Task,接收到 Task 执行的命令后,会首先把 Task 封装在 TaskRunner 里面,TaskRunner 其实是 Java 中的 Runnerable 接口的具体的实现,在真正工作的时候会交给线程池中的线池去运行,此时会调用 run 方法来执行 task,TaskRunner 在调用 run 方法的时候会调用 Task run方法,而 Task 的 run 方法会调用 runTask, 而实际 Task 有 ShuffleMapTask 和 ResultTask;
![]()
[总结部份]
更新中......
参考资料
资料来源来至 DT大数据梦工厂 大数据传奇行动 第33课:Spark Executor内幕彻底解密:Executor工作原理图、ExecutorBackend注册源码解密、Executor实例化内幕、Executor具体工作内幕
Spark源码图片取自于 Spark 1.6.0版本

 浙公网安备 33010602011771号
浙公网安备 33010602011771号