
Python 数据科学系列 の Numpy、Series 和 DataFrame介绍
本課主題
- Numpy 的介绍和操作实战
- Series 的介绍和操作实战
- DataFrame 的介绍和操作实战
Numpy 的介绍和操作实战
numpy 是 Python 在数据计算领域里很常用的模块
import numpy as np np.array([11,22,33]) #接受一个列表数据
- 创建 numpy array
![]() 创建 numpy array(例子)
创建 numpy array(例子)>>> import numpy as np >>> mylist = [1,2,3] >>> x = np.array(mylist) >>> x array([1, 2, 3]) >>> y = np.array([4,5,6]) >>> y array([4, 5, 6]) >>> m = np.array([[7,8,9],[10,11,12]]) >>> m array([[ 7, 8, 9], [10, 11, 12]])
- 查看 numpy array 的
![]() View Code
View Code>>> m.shape #array([1, 2, 3]) (2, 3) >>> x.shape #array([4, 5, 6]) (3,) >>> y.shape #array([[ 7, 8, 9], [10, 11, 12]]) (3,)
- numpy.arrange
![]() numpy.arrange( )(例子)
numpy.arrange( )(例子)>>> n = np.arange(0,30,2) >>> n array([ 0, 2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28])
- 改变numpy array的位置
![]() numpy.reshape( )(例子一)
numpy.reshape( )(例子一)>>> n = np.arange(0,30,2) >>> n array([ 0, 2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28]) >>> n.shape (15,) >>> n = n.reshape(3,5) #从15列改成3列5行 >>> n array([[ 0, 2, 4, 6, 8], [10, 12, 14, 16, 18], [20, 22, 24, 26, 28]])
![]() numpy.reshape( )(例子二)
numpy.reshape( )(例子二)>>> o = np.linspace(0,4,9) >>> o array([ 0. , 0.5, 1. , 1.5, 2. , 2.5, 3. , 3.5, 4. ]) >>> o.resize(3,3) >>> o array([[ 0. , 0.5, 1. ], [ 1.5, 2. , 2.5], [ 3. , 3.5, 4. ]])
- numpy.ones( ) ,numpy.zeros( ),numpy.eye( )
![]() numpy.ones/zeros/eye( )(例子)
numpy.ones/zeros/eye( )(例子)>>> r1 = np.ones((3,2)) >>> r1 array([[ 1., 1.], [ 1., 1.], [ 1., 1.]]) >>> r1 = np.zeros((2,3)) >>> r1 array([[ 0., 0., 0.], [ 0., 0., 0.]]) >>> r2 = np.eye(3) >>> r2 array([[ 1., 0., 0.], [ 0., 1., 0.], [ 0., 0., 1.]])
可以定义整数
![]() numpy.ones(x,int)(例子)
numpy.ones(x,int)(例子)>>> r5 = np.ones([2,3], int) >>> r5 array([[1, 1, 1], [1, 1, 1]]) >>> r5 = np.ones([2,3]) >>> r5 array([[ 1., 1., 1.], [ 1., 1., 1.]])
- numpy.diag( )
![]() diag( )(例子)
diag( )(例子)>>> y = np.array([4,5,6]) >>> y array([4, 5, 6]) >>> np.diag(y) array([[4, 0, 0], [0, 5, 0], [0, 0, 6]])
- 复制 numpy array
![]() 复制numpy array(例子)
复制numpy array(例子)>>> r3 = np.array([1,2,3] * 3) >>> r3 array([1, 2, 3, 1, 2, 3, 1, 2, 3]) >>> r4 = np.repeat([1,2,3],3) >>> r4 array([1, 1, 1, 2, 2, 2, 3, 3, 3])
- numpy中的 vstack和 hstack
![]() numpy.vstack( )和np.hstack( )(例子)
numpy.vstack( )和np.hstack( )(例子)>>> r5 = np.ones([2,3], int) >>> r5 array([[1, 1, 1], [1, 1, 1]]) >>> r6 = np.vstack([r5,2*r5]) >>> r6 array([[1, 1, 1], [1, 1, 1], [2, 2, 2], [2, 2, 2]]) >>> r7 = np.hstack([r5,2*r5]) >>> r7 array([[1, 1, 1, 2, 2, 2], [1, 1, 1, 2, 2, 2]])
- numpy 中的加减乘除操作一 (+-*/)
![]() numpy中的加减乘除(例子一)
numpy中的加减乘除(例子一)>>> mylist = [1,2,3] >>> x = np.array(mylist) >>> y = np.array([4,5,6]) >>> x+y array([5, 7, 9]) >>> x-y array([-3, -3, -3]) >>> x*y array([ 4, 10, 18]) >>> x**2 array([1, 4, 9]) >>> x.dot(y) 32
- numpy 中的加减乘除操作二:sum( )、max( )、min( )、mean( )、std( )
![]() numpy中的加减乘除(例子二)
numpy中的加减乘除(例子二)>>> a = np.array([1,2,3,4,5]) >>> a.sum() 15 >>> a.max() 5 >>> a.min() 1 >>> a.mean() 3.0 >>> a.std() 1.4142135623730951 >>> a.argmax() 4 >>> a.argmin() 0
- 查看numpy array 的数据类型
![]() numpy array 的数据类型
numpy array 的数据类型>>> y = np.array([4,5,6]) >>> z = np.array([y, y**2]) >>> z array([[ 4, 5, 6], [16, 25, 36]]) >>> z.shape (2, 3) >>> z.T.shape (3, 2) >>> z.dtype dtype('int64') >>> z = z.astype('f') >>> z.dtype dtype('float32')
- numpy 中的索引和切片
![]() numpy索引和切片(例子一)
numpy索引和切片(例子一)>>> s = np.arange(13) >>> s array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12]) >>> s = np.arange(13) ** 2 >>> s array([ 0, 1, 4, 9, 16, 25, 36, 49, 64, 81, 100, 121, 144]) >>> s[0],s[4],s[0:3] (0, 16, array([0, 1, 4])) >>> s[1:5] array([ 1, 4, 9, 16]) >>> s[-4:] array([ 81, 100, 121, 144]) >>> s[-5:-2] array([ 64, 81, 100])
![]() numpy索引和切片(例子二)
numpy索引和切片(例子二)>>> r = np.arange(36) >>> r.resize((6,6)) >>> r array([[ 0, 1, 2, 3, 4, 5], [ 6, 7, 8, 9, 10, 11], [12, 13, 14, 15, 16, 17], [18, 19, 20, 21, 22, 23], [24, 25, 26, 27, 28, 29], [30, 31, 32, 33, 34, 35]]) >>> r[2,2] 14 >>> r[3,3:6] array([21, 22, 23]) >>> r[:2,:-1] array([[ 0, 1, 2, 3, 4], [ 6, 7, 8, 9, 10]]) >>> r[-1,::2] array([30, 32, 34]) >>> r[r > 30] #取r大于30的数据 array([31, 32, 33, 34, 35]) >>> re2 = r[r > 30] = 30 >>> re2 30 >>> r8 = r[:3,:3] >>> r8 array([[ 0, 1, 2], [ 6, 7, 8], [12, 13, 14]]) >>> r8[:] = 0 >>> r8 array([[0, 0, 0], [0, 0, 0], [0, 0, 0]]) >>> r array([[ 0, 0, 0, 3, 4, 5], [ 0, 0, 0, 9, 10, 11], [ 0, 0, 0, 15, 16, 17], [18, 19, 20, 21, 22, 23], [24, 25, 26, 27, 28, 29], [30, 30, 30, 30, 30, 30]])
- copy numpy array 的数组
![]() copy( )例子
copy( )例子>>> r = np.arange(36) >>> r.resize((6,6)) >>> r_copy = r.copy() >>> r array([[ 0, 1, 2, 3, 4, 5], [ 6, 7, 8, 9, 10, 11], [12, 13, 14, 15, 16, 17], [18, 19, 20, 21, 22, 23], [24, 25, 26, 27, 28, 29], [30, 31, 32, 33, 34, 35]]) >>> r_copy array([[ 0, 1, 2, 3, 4, 5], [ 6, 7, 8, 9, 10, 11], [12, 13, 14, 15, 16, 17], [18, 19, 20, 21, 22, 23], [24, 25, 26, 27, 28, 29], [30, 31, 32, 33, 34, 35]]) >>> r_copy[:] = 10 >>> r_copy array([[10, 10, 10, 10, 10, 10], [10, 10, 10, 10, 10, 10], [10, 10, 10, 10, 10, 10], [10, 10, 10, 10, 10, 10], [10, 10, 10, 10, 10, 10], [10, 10, 10, 10, 10, 10]])
- 其他操作
![]() numpy array 的其他操作例子
numpy array 的其他操作例子>>> test = np.random.randint(0,10,(4,3)) >>> test array([[3, 5, 2], [7, 7, 9], [8, 9, 2], [2, 9, 1]]) >>> for row in test: ... print(row) ... [3 5 2] [7 7 9] [8 9 2] [2 9 1] >>> for i in range(len(test)): ... print(test[i]) ... [3 5 2] [7 7 9] [8 9 2] [2 9 1] >>> for i, row in enumerate(test): ... print('row', i, 'is', row) ... row 0 is [3 5 2] row 1 is [7 7 9] row 2 is [8 9 2] row 3 is [2 9 1] >>> test2 = test ** 2 >>> test2 array([[ 9, 25, 4], [49, 49, 81], [64, 81, 4], [ 4, 81, 1]]) >>> for i,j, in zip(test,test2): ... print(i, '+', j, '=', i + j) ... [3 5 2] + [ 9 25 4] = [12 30 6] [7 7 9] + [49 49 81] = [56 56 90] [8 9 2] + [64 81 4] = [72 90 6] [2 9 1] + [ 4 81 1] = [ 6 90 2] >>>

Series 的介绍和操作实战
如果是输入一个字典类型的话,字典的键会自动变成 Index,然后它的值是Value
from pandas import Series, DataFrame import pandas as pd pd.Series(['Dog','Bear','Tiger','Moose','Giraffe','Hippopotamus','Mouse'], name='Animals') #接受一个列表类型的数据

def __init__(self, data=None, index=None, dtype=None, name=None, copy=False, fastpath=False):

- 创建 Series 类型
第一:你可以传入一个列表或者是字典来创建 Series,如果传入的是列表,Python会自动把 [0,1,2] 作为 Series 的索引。
第二:如果你传入的是字符串类型的数据,Series 返回的dtype是object;如果你传入的是数字类型的数据,Series 返回的dtype是int64
![]() 创建 Series
创建 Series>>> from pandas import Series, DataFrame >>> import pandas as pd >>> animals = ['Tiger','Bear','Moose'] >>> s1 = pd.Series(animals) >>> s1 0 Tiger 1 Bear 2 Moose dtype: object >>> s2 = pd.Series([1,2,3]) >>> s2 0 1 1 2 2 3 dtype: int64
Series如何处理 NaN的数据?
![]() Series NaN数据(范例)
Series NaN数据(范例)>>> animals2 = ['Tiger','Bear',None] >>> s3 = pd.Series(animals2) >>> s3 0 Tiger 1 Bear 2 None dtype: object >>> s4 = pd.Series([1,2,None]) >>> s4 0 1.0 1 2.0 2 NaN dtype: float64
- Series 中的 NaN数据和如何检查 NaN数据是否相等,这时候需要调用 np.isnan( )方法
![]() np.isnan( )
np.isnan( )>>> import numpy as np >>> np.nan == None False >>> np.nan == np.nan False >>> np.isnan(np.nan) True
- Series 默应 Index 是 [0,1,2],但也可以自定义 Series 中的Index
![]() 自定义 Series 中的Index(例子一)
自定义 Series 中的Index(例子一)>>> import numpy as np >>> sports = { ... 'Archery':'Bhutan', ... 'Golf':'Scotland', ... 'Sumo':'Japan', ... 'Taekwondo':'South Korea' ... } >>> s5 = pd.Series(sports) >>> s5 Archery Bhutan Golf Scotland Sumo Japan Taekwondo South Korea dtype: object >>> s5.index Index(['Archery', 'Golf', 'Sumo', 'Taekwondo'], dtype='object')
![]() 自定义 Series 中的Index(例子一)
自定义 Series 中的Index(例子一)>>> from pandas import Series, DataFrame >>> import pandas as pd >>> s6 = pd.Series(['Tiger','Bear','Moose'], index=['India','America','Canada']) >>> s6 India Tiger America Bear Canada Moose dtype: object
- 查询 Series 的数据有两种方法,第一是通过index方法 e.g. s.iloc[2];第二是通过label方法 e.g. s.loc['America']
![]() 查询Series(例子)
查询Series(例子)>>> from pandas import Series, DataFrame >>> import pandas as pd >>> s6 India Tiger America Bear Canada Moose dtype: object >>> s6.iloc[2] #获取 index2位置的数据 'Moose' >>> s6.loc['America'] #获取 label: America 的值 'Bear' >>> s6[1] #底层调用了 s6.iloc[1] 'Bear' >>> s6['India'] #底层调用了 s6.loc['India'] 'Tiger'
- Series 的数据操作: sum( ),它底层也是调用 numpy 的方法
![]() np.sum(s7)
np.sum(s7)>>> s7 = pd.Series([100.00,120.00,101.00,3.00]) >>> s7 0 100.0 1 120.0 2 101.0 3 3.0 dtype: float64 >>> total = 0 >>> for item in s7: ... total +=item ... >>> total 324.0 >>> total2 = np.sum(s7) >>> total2 324.0
![]() head( )例子
head( )例子>>> s8 = pd.Series(np.random.randint(0,1000,10000)) >>> s8.head() 0 25 1 399 2 326 3 479 4 603 dtype: int64 >>> len(s8) 10000
- Series 也可以存储混合型数据
![]() 混合型存储数据(例子)
混合型存储数据(例子)>>> s9 = pd.Series([1,2,3]) >>> s9.loc['Animals'] = 'Bears' >>> s9 0 1 1 2 2 3 Animals Bears dtype: object
- Series 中的 append( ) 用法
![]() Series类型的append( )
Series类型的append( )>>> original_sports = pd.Series({'Archery':'Bhutan', ... 'Golf':'Scotland', ... 'Sumo':'Japan', ... 'Taekwondo':'South Korea'}) >>> cricket_loving_countries = pd.Series(['Australia', 'Barbados','Pakistan','England'], ... index=['Cricket','Cricket','Cricket','Cricket']) >>> all_countries = original_sports.append(cricket_loving_countries) >>> original_sports Archery Bhutan Golf Scotland Sumo Japan Taekwondo South Korea dtype: object >>> cricket_loving_countries Cricket Australia Cricket Barbados Cricket Pakistan Cricket England dtype: object >>> all_countries Archery Bhutan Golf Scotland Sumo Japan Taekwondo South Korea Cricket Australia Cricket Barbados Cricket Pakistan Cricket England dtype: object
DataFrame
这是创建一个DataFrame对象的基本语句:接受字典类型的数据;字典中的Key (e.g. Animals, Owners) 对应 DataFrame中的Columns,它的 Value 也相当于数据库表中的每一行数据。
data = {
'Animals':['Dog','Bear','Tiger','Moose','Giraffe','Hippopotamus','Mouse'],
'Owners':['Chris','Kevyn','Bob','Vinod','Daniel','Fil','Stephanie']
}
df = DataFrame(data, columns=['Animals','Owners'])
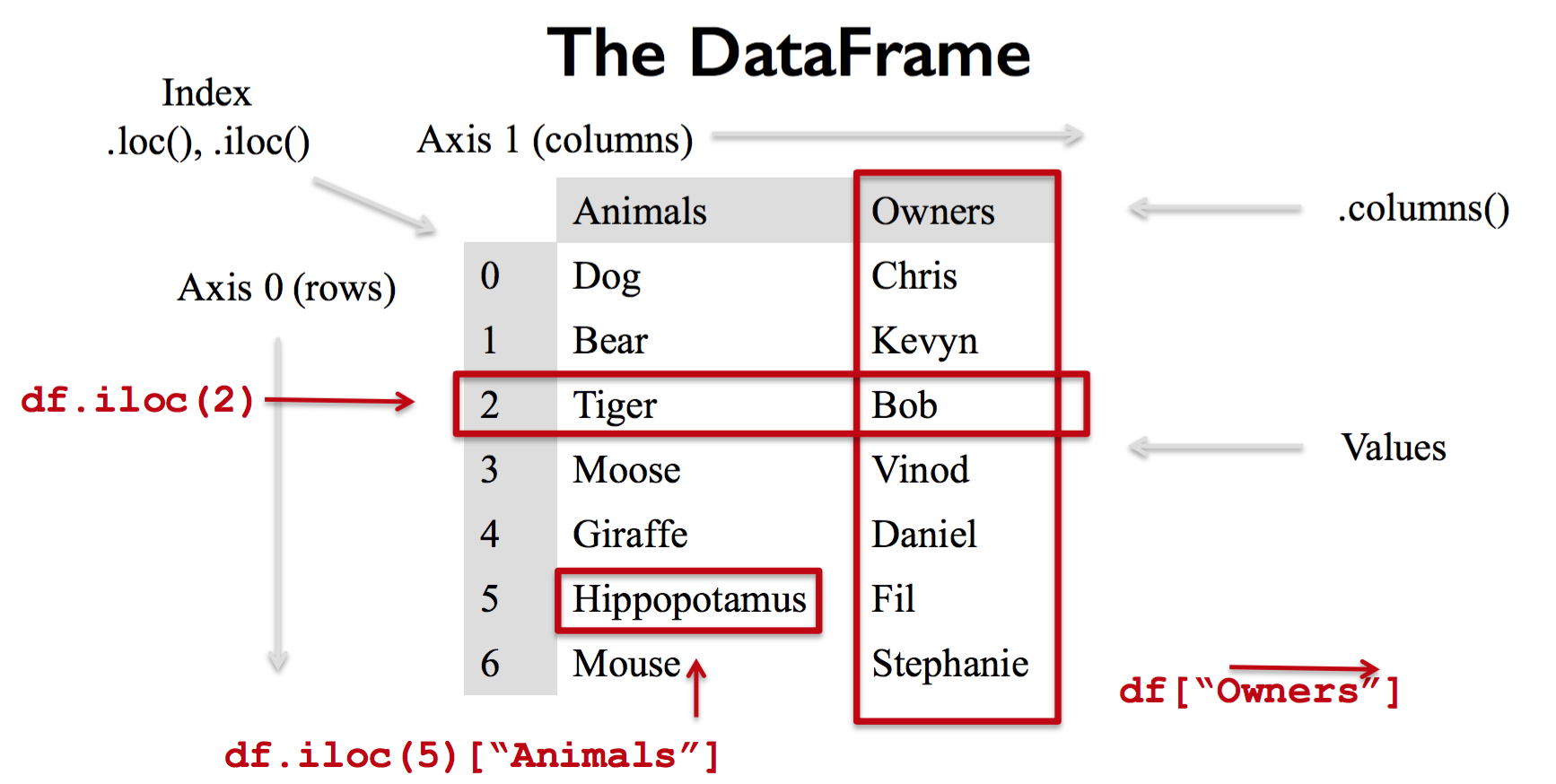
基础操作
- 创建DataFrame
![]() 创建DataFrame(例子一)
创建DataFrame(例子一)>>> from pandas import Series, DataFrame >>> import pandas as pd >>> data = {'name':['yahoo','google','facebook'], ... 'marks':[200,400,800], ... 'price':[9,3,7]} >>> df = DataFrame(data) >>> df marks name price 0 200 yahoo 9 1 400 google 3 2 800 facebook 7
![]() 创建DataFrame(例子二)
创建DataFrame(例子二)>>> df2 = DataFrame(data, columns=['name','price','marks']) >>> df2 name price marks 0 yahoo 9 200 1 google 3 400 2 facebook 7 800 >>> df3 = DataFrame(data, columns=['name','price','marks'], index=['a','b','c']) >>> df3 name price marks a yahoo 9 200 b google 3 400 c facebook 7 800 >>> df4 = DataFrame(data, columns=['name','price','marks', 'debt'], index=['a','b','c']) >>> df4 name price marks debt a yahoo 9 200 NaN b google 3 400 NaN c facebook 7 800 NaN
![]() 创建DataFrame(例子三)
创建DataFrame(例子三)>>> import pandas as pd >>> purchase_1 = pd.Series({'Name':'Chris','Item Purchased':'Dog Food','Cost':22.50}) >>> purchase_2 = pd.Series({'Name':'Kelvin','Item Purchased':'Kitty Litter','Cost':2.50}) >>> purchase_3 = pd.Series({'Name':'Vinod','Item Purchased':'Bird Seed','Cost':5.00}) >>> >>> df = pd.DataFrame([purchase_1,purchase_2,purchase_3],index=['Store 1','Store 2','Store 1']) >>> df Cost Item Purchased Name Store 1 22.5 Dog Food Chris Store 2 2.5 Kitty Litter Kelvin Store 1 5.0 Bird Seed Vinod
- 查询 dataframe 的index:df.loc['index']
![]() df.loc['Store 2']
df.loc['Store 2']>>> df.loc['Store 2'] Cost 2.5 Item Purchased Kitty Litter Name Kelvin Name: Store 2, dtype: object
![]() df.loc['Store 1']
df.loc['Store 1']>>> df.loc['Store 1'] Cost Item Purchased Name Store 1 22.5 Dog Food Chris Store 1 5.0 Bird Seed Vinod
![]() df['Item Purchased']
df['Item Purchased']>>> df['Item Purchased'] Store 1 Dog Food Store 2 Kitty Litter Store 1 Bird Seed Name: Item Purchased, dtype: object
- 查 store1 的 cost 是多少
![]() df.loc['Store 1', 'Cost']
df.loc['Store 1', 'Cost']>>> df.loc['Store 1', 'Cost'] Store 1 22.5 Store 1 5.0 Name: Cost, dtype: float64
- 查询Cost大于3的Name
![]() df['Name'][df['Cost']>3]
df['Name'][df['Cost']>3]>>> df['Name'][df['Cost']>3] Store 1 Chris Store 1 Vinod Name: Name, dtype: object
- 查询DataFrame 的类型
![]() type( )例子
type( )例子>>> type(df.loc['Store 2']) <class 'pandas.core.series.Series'>
- drop dataframe (但这不会把原来的 dataframe drop 掉)
![]() df.drop('Store 1')
df.drop('Store 1')>>> df.drop('Store 1') Cost Item Purchased Name Store 2 2.5 Kitty Litter Kelvin >>> df Cost Item Purchased Name Store 1 22.5 Dog Food Chris Store 2 2.5 Kitty Litter Kelvin Store 1 5.0 Bird Seed Vinod
![]() 把dataframe数据drop的例子
把dataframe数据drop的例子>>> copy_df = df.copy() >>> copy_df Cost Item Purchased Name Store 1 22.5 Dog Food Chris Store 2 2.5 Kitty Litter Kelvin Store 1 5.0 Bird Seed Vinod >>> copy_df = df.drop('Store 1') >>> copy_df Cost Item Purchased Name Store 2 2.5 Kitty Litter Kelvin
也可以用 del 把 Column 列删除掉
![]() del copy_df['Name']
del copy_df['Name']>>> del copy_df['Name'] >>> copy_df Cost Item Purchased Store 2 2.5 Kitty Litter
- set_index
- rename column
- 可以修改dataframe里的数据
![]() df['Cost'] * 0.8
df['Cost'] * 0.8>>> df = pd.DataFrame([purchase_1,purchase_2,purchase_3],index=['Store 1','Store 2','Store 1']) >>> df Cost Item Purchased Name Store 1 22.5 Dog Food Chris Store 2 2.5 Kitty Litter Kelvin Store 1 5.0 Bird Seed Vinod >>> df['Cost'] = df['Cost'] * 0.8 >>> df Cost Item Purchased Name Store 1 18.0 Dog Food Chris Store 2 2.0 Kitty Litter Kelvin Store 1 4.0 Bird Seed Vinod
![]() costs = df['Cost']
costs = df['Cost']>>> df = pd.DataFrame([purchase_1,purchase_2,purchase_3],index=['Store 1','Store 2','Store 1']) >>> costs = df['Cost'] >>> costs Store 1 22.5 Store 2 2.5 Store 1 5.0 Name: Cost, dtype: float64 >>> costs += 2 >>> costs Store 1 24.5 Store 2 4.5 Store 1 7.0 Name: Cost, dtype: float64
进阶操作
- Merge
Full Outer Join
Inner Join
Left Join
Right Join - apply
- group by
- agg
- astype
- cut
![]() cut( )
cut( )s = pd.Series([168, 180, 174, 190, 170, 185, 179, 181, 175, 169, 182, 177, 180, 171]) pd.cut(s, 3) pd.cut(s, 3, labels=['Small', 'Medium', 'Large'])
- pivot table
Date in DataFrame
- Timestampe
- period
- DatetimeINdex
- PeriodIndex
- to_datetime
- Timedelta
- date_range
- difference between date value
- resample
- asfreq - changing the frequency of the date
读取 csv 文件
import pandas as pd
pd.read_csv('student.csv')
- 读取csv
![]() pd.read_csv('student.csv')(例子一)
pd.read_csv('student.csv')(例子一)>>> from pandas import Series, DataFrame >>> import pandas as pd >>> df_student = pd.read_csv('student.csv') >>> df_student name class marks age janice python 80 22 alex python 95 21 peter python 85 25 ken java 75 28 lawerance java 50 22
![]() pd.read_csv('student.csv')(例子二)
pd.read_csv('student.csv')(例子二)df_student = pd.read_csv('student.csv', index_col=0, skiprows=1)
- 获取分数大于70的数据
![]() 方法一: df_student['marks'] > 70
方法一: df_student['marks'] > 70>>> df_student['marks'] > 70 True True True True False Name: marks, dtype: bool
![]() 方法二: df_student.where(df_student['marks']>70)
方法二: df_student.where(df_student['marks']>70)>>> df_student.where(df_student['marks']>70) name class marks age janice python 80.0 22.0 alex python 95.0 21.0 peter python 85.0 25.0 ken java 75.0 28.0 NaN NaN NaN NaN
![]() 方法三: df_student[df_student['marks'] > 70]
方法三: df_student[df_student['marks'] > 70]>>> df_student[df_student['marks'] > 70] name class marks age 0 janice python 80 22 1 alex python 95 21 2 peter python 85 25 3 ken java 75 28
- 获取class = 'python' 的数据,df.count( ) 是不会把 NaN数据计算在其中
![]() df_student.where( )例子
df_student.where( )例子>>> df2 = df_student.where(df_student['class'] == 'python') >>> df2 name class marks age 0 janice python 80.0 22.0 1 alex python 95.0 21.0 2 peter python 85.0 25.0 3 NaN NaN NaN NaN 4 NaN NaN NaN NaN >>> df2 = df_student[df_student['class'] == 'python'] >>> df2 name class marks age 0 janice python 80 22 1 alex python 95 21 2 peter python 85 25
- 计算 class 的数目 e.g. count( )
![]() df.count( )例子
df.count( )例子>>> df2['class'].count() #不会把 NaN也计算 3 >>> df_student['class'].count() #会把 NaN也计算 5
- 删取NaN数据
![]() df2.dropna()
df2.dropna()>>> df3 = df2.dropna() >>> df3 name class marks age 0 janice python 80.0 22.0 1 alex python 95.0 21.0 2 peter python 85.0 25.0
- 获取age大于23 学生的数据
![]() df_student[df_student['age'] > 23]
df_student[df_student['age'] > 23]>>> df_student name class marks age 0 janice python 80 22 1 alex python 95 21 2 peter python 85 25 3 ken java 75 28 4 lawerance java 50 22 >>> df_student[df_student['age'] > 23] name class marks age 2 peter python 85 25 3 ken java 75 28 >>> df_student['age'] > 23 0 False 1 False 2 True 3 True 4 False Name: age, dtype: bool >>> len(df_student[df_student['age'] > 23]) 2
- 获取age大于23和分数大于80分学生的数据
![]() df_student[(df_student['age'] > 23) & (df_student['marks'] > 80)]
df_student[(df_student['age'] > 23) & (df_student['marks'] > 80)]>>> df_student name class marks age 0 janice python 80 22 1 alex python 95 21 2 peter python 85 25 3 ken java 75 28 4 lawerance java 50 22 >>> df_and = df_student[(df_student['age'] > 23) & (df_student['marks'] > 80)] >>> df_and name class marks age 2 peter python 85 25
- 获取age大于23或分数大于80分学生的数据
![]() df_student[(df_student['age'] > 23) | (df_student['marks'] > 80)]
df_student[(df_student['age'] > 23) | (df_student['marks'] > 80)]>>> df_student name class marks age 0 janice python 80 22 1 alex python 95 21 2 peter python 85 25 3 ken java 75 28 4 lawerance java 50 22 >>> df_or = df_student[(df_student['age'] > 23) | (df_student['marks'] > 80)] >>> df_or name class marks age 1 alex python 95 21 2 peter python 85 25 3 ken java 75 28
- 重新定义index的数值 df.set_index( )
![]() df_student.set_index( )例子
df_student.set_index( )例子>>> df_student = pd.read_csv('student.csv') >>> df_student name class marks age 0 janice python 80 22 1 alex python 95 21 2 peter python 85 25 3 ken java 75 28 4 lawerance java 50 22 >>> df_student['order_id'] = df_student.index >>> df_student name class marks age order_id 0 janice python 80 22 0 1 alex python 95 21 1 2 peter python 85 25 2 3 ken java 75 28 3 4 lawerance java 50 22 4 >>> df_student = df_student.set_index('class') >>> df_student name marks age order_id class python janice 80 22 0 python alex 95 21 1 python peter 85 25 2 java ken 75 28 3 java lawerance 50 22 4
- 获取在 dataframe column 中唯一的数据
![]() df.unique( )例子
df.unique( )例子>>> df_student = pd.read_csv('student.csv') >>> df_student['class'].unique() array(['python', 'java'], dtype=object)
python 的可视化 matplotlib
- plot
參考資料
Coursera: Introduction to Data Science in Python
Data Science: GoodHart's Law | Goodhart's Law

 浙公网安备 33010602011771号
浙公网安备 33010602011771号