
3.2 Lucene实战:一个简单的小程序
在讲解Lucene索引和检索的原理之前,我们先来实战Lucene:一个简单的小程序!
一、索引小程序
首先,new一个java project,名字叫做LuceneIndex。
然后,在project里new一个class,名字叫做Indexer。这个类用来给文件建索引(建好索引以后就可以高效检索了)。
在写代码之前,我们要先引入一下lucene包。分为三步:
1. 创建lib文件夹。
2. 将所需要的lucene包复制到lib文件夹中。
3. Build path-> lib->Configure Build Path->Add JARS,选择LuceneIndex工程下lib文件夹下的所有jar包并添加到路径,连续点击两次ok。

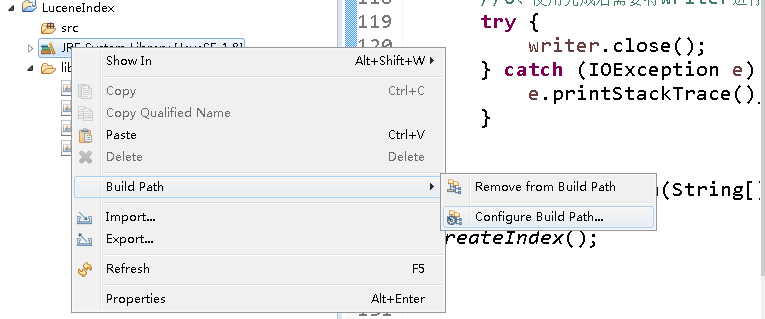
步骤2 步骤3
在这些准备工作完成后我们就可以开始写代码了。
1. 首先在LuceneIndex里new一个class,名字叫做Indexer。
2. 然后,在LuceneIndex工程里新建一个文件夹,叫做raw。
3. 接下来,在raw文件夹里新建两个utf-8编码的txt文件。比如第一个文件命名为hello.txt,内容为"Hello",第二个文件命名为nihao.txt,内容为"你好"。这里要注意的是,上面的代码是针对中文搜索的问题使用了utf-8编码,所以要求文件也是utf-8的编码。如图:

4. 写入如下代码:


import java.nio.charset.StandardCharsets; import java.nio.file.Files; import java.nio.file.Paths; import java.io.*; import org.apache.lucene.analysis.standard.StandardAnalyzer; import org.apache.lucene.document.Document; import org.apache.lucene.document.Field; import org.apache.lucene.document.StringField; import org.apache.lucene.document.TextField; import org.apache.lucene.index.IndexWriter; import org.apache.lucene.index.IndexWriterConfig; import org.apache.lucene.store.Directory; import org.apache.lucene.store.FSDirectory; import org.apache.lucene.util.Version; /** * @author csl * @description: * 依赖jar:Lucene-core,lucene-analyzers-common,lucene-queryparser * 作用:简单的索引建立 */ public class Indexer { public static Version luceneVersion = Version.LATEST; /** * 建立索引 */ public static void createIndex(){ IndexWriter writer = null; try{ //1、创建Directory //Directory directory = new RAMDirectory();//创建内存directory Directory directory = FSDirectory.open(Paths.get("index"));//在硬盘上生成Directory00 //2、创建IndexWriter IndexWriterConfig iwConfig = new IndexWriterConfig( new StandardAnalyzer()); writer = new IndexWriter(directory, iwConfig); //3、创建document对象 Document document = null; //4、为document添加field对象 File f = new File("raw");//索引源文件位置 for (File file:f.listFiles()){ document = new Document(); document.add(new StringField("path", f.getName(),Field.Store.YES)); System.out.println(file.getName()); document.add(new StringField("name", file.getName(),Field.Store.YES)); InputStream stream = Files.newInputStream(Paths.get(file.toString())); document.add(new TextField("content", new BufferedReader(new InputStreamReader(stream, StandardCharsets.UTF_8))));//textField内容会进行分词 //document.add(new TextField("content", new FileReader(file))); 如果不用utf-8编码的话直接用这个就可以了 writer.addDocument(document); } }catch(Exception e){ e.printStackTrace(); }finally{ //6、使用完成后需要将writer进行关闭 try { writer.close(); } catch (IOException e) { e.printStackTrace(); } } } public static void main(String[] args) throws IOException { createIndex(); } }
5. 最后,运行Indexer.java。会看到索引建立完成。LuceneIndex工程下多了一个index文件夹。
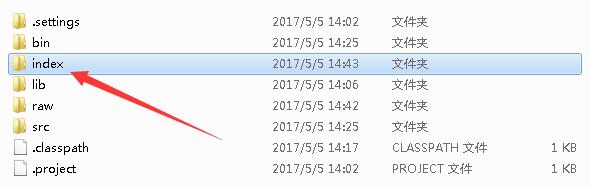
二、检索小程序
下面我们就要用这个index来检索了。
1. new一个class,命名为Searcher。然后在里面写入如下代码:
1 import java.nio.file.Paths; 2 import java.io.*; 3 4 import org.apache.lucene.analysis.standard.StandardAnalyzer; 5 import org.apache.lucene.document.Document; 6 import org.apache.lucene.index.DirectoryReader; 7 import org.apache.lucene.queryparser.classic.QueryParser; 8 import org.apache.lucene.search.IndexSearcher; 9 import org.apache.lucene.search.Query; 10 import org.apache.lucene.search.ScoreDoc; 11 import org.apache.lucene.search.TopDocs; 12 import org.apache.lucene.store.Directory; 13 import org.apache.lucene.store.FSDirectory; 14 import org.apache.lucene.util.Version; 15 16 /** 17 * @author csl 18 * @description: 19 * 依赖jar:Lucene-core,lucene-analyzers-common,lucene-queryparser 20 * 作用:使用索引搜索文件 21 */ 22 public class Searcher { 23 public static Version luceneVersion = Version.LATEST; 24 /** 25 * 查询内容 26 */ 27 public static String indexSearch(String keywords){ 28 String res = ""; 29 DirectoryReader reader = null; 30 try{ 31 // 1、创建Directory 32 Directory directory = FSDirectory.open(Paths.get("index"));//在硬盘上生成Directory 33 // 2、创建IndexReader 34 reader = DirectoryReader.open(directory); 35 // 3、根据IndexWriter创建IndexSearcher 36 IndexSearcher searcher = new IndexSearcher(reader); 37 // 4、创建搜索的query 38 // 创建parse用来确定搜索的内容,第二个参数表示搜索的域 39 QueryParser parser = new QueryParser("content",new StandardAnalyzer());//content表示搜索的域或者说字段 40 Query query = parser.parse(keywords);//被搜索的内容 41 // 5、根据Searcher返回TopDocs 42 TopDocs tds = searcher.search(query, 20);//查询20条记录 43 // 6、根据TopDocs获取ScoreDoc 44 ScoreDoc[] sds = tds.scoreDocs; 45 // 7、根据Searcher和ScoreDoc获取搜索到的document对象 46 int cou=0; 47 for(ScoreDoc sd:sds){ 48 cou++; 49 Document d = searcher.doc(sd.doc); 50 // 8、根据document对象获取查询的字段值 51 /** 查询结果中content为空,是因为索引中没有存储content的内容,需要根据索引path和name从原文件中获取content**/ 52 res+=cou+". "+d.get("path")+" "+d.get("name")+" "+d.get("content")+"\n"; 53 } 54 55 56 }catch(Exception e){ 57 e.printStackTrace(); 58 }finally{ 59 //9、关闭reader 60 try { 61 reader.close(); 62 } catch (IOException e) { 63 e.printStackTrace(); 64 } 65 } 66 return res; 67 } 68 public static void main(String[] args) throws IOException 69 { 70 System.out.println(indexSearch("你好")); //搜索的内容可以修改 71 } 72 }
2.
1 public static void main(String[] args) throws IOException 2 { 3 System.out.println(indexSearch("你好")); //搜索的内容可以修改 4 }
搜索内容为"你好"时,搜索结果为内容包含"你好"的nihao.txt

3.
1 public static void main(String[] args) throws IOException 2 { 3 System.out.println(indexSearch("Hello")); //搜索的内容可以修改 4 }
搜索内容为"Hello"时,搜索结果为内容包含"Hello"的hello.txt
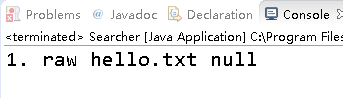
至此,我们已经进行了Lucene实战,学会了简单的建立索引和检索了!
三、工程源码
可以先试一下我的项目:https://github.com/shelly-github/my_simple_Lucenetest
1. 下载这个工程
2. 然后解压
3. 导入Eclipse
首先,打开Eclipse,选定一个workspace。
然后,点击File->import->Existing Projects into workspace
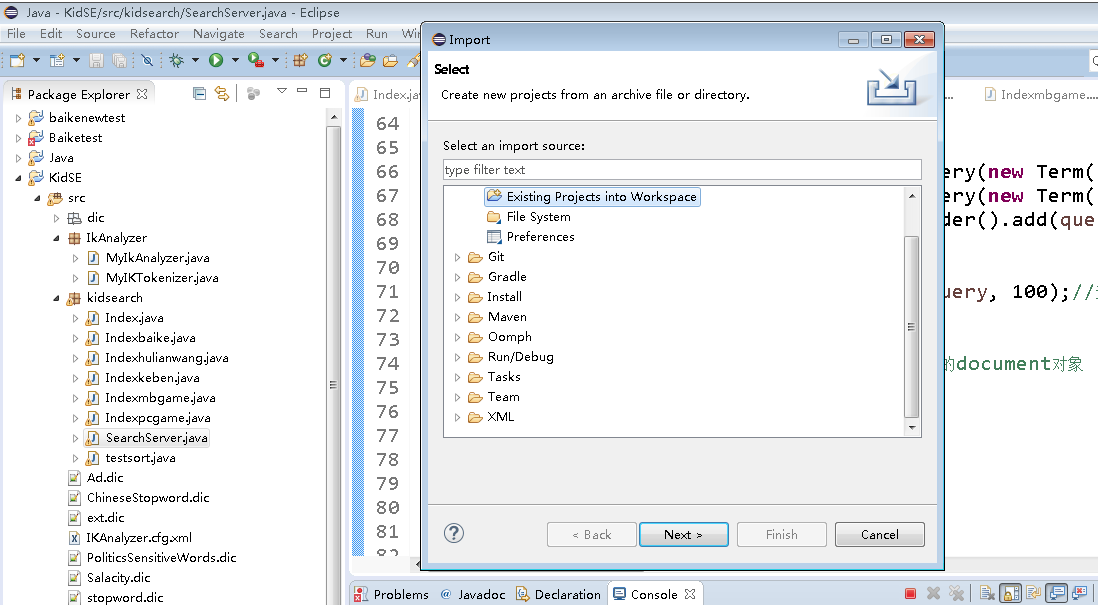
双击Existing Projects into workspace,选择工程所在目录

点击确定->finish,完成工程的导入。
接下来就可以运行程序了,注意这个工程里没有包含Index,你需要先运行Indexer建立索引,然后再用Searcher进行检索。
四、遍历文件系统
这是一个简单的Lucene演示程序,只能索引同一目录下的txt文件,下面我来介绍一种遍历文件系统并且索引.txt文件的方法。
这个方法很简单,就是一个递归实现的深度优先遍历。
1 import java.nio.charset.StandardCharsets; 2 import java.nio.file.Files; 3 import java.nio.file.Paths; 4 import java.io.*; 5 6 import org.apache.lucene.analysis.standard.StandardAnalyzer; 7 import org.apache.lucene.document.Document; 8 import org.apache.lucene.document.Field; 9 import org.apache.lucene.document.StringField; 10 import org.apache.lucene.document.TextField; 11 import org.apache.lucene.index.IndexWriter; 12 import org.apache.lucene.index.IndexWriterConfig; 13 import org.apache.lucene.store.Directory; 14 import org.apache.lucene.store.FSDirectory; 15 import org.apache.lucene.util.Version; 16 public class Indexer { 17 static int numIndexed=0; 18 //索引 19 private static void indexFile(IndexWriter writer,File f) throws IOException 20 { 21 if(f.isHidden()||!f.exists()||!f.canRead()) 22 { 23 return; 24 } 25 System.out.println("Indexing"+f.getCanonicalPath()); 26 Document document = new Document(); 27 document.add(new StringField("path", f.getName(),Field.Store.YES)); 28 System.out.println(f.getName()); 29 document.add(new StringField("name", f.getName(),Field.Store.YES)); 30 InputStream stream = Files.newInputStream(Paths.get(f.toString())); 31 document.add(new TextField("content", new BufferedReader(new InputStreamReader(stream, StandardCharsets.UTF_8))));//textField内容会进行分词 32 //document.add(new TextField("content", new FileReader(file))); 如果不用utf-8编码的话直接用这个就可以了 33 writer.addDocument(document); 34 } 35 //深度优先遍历文件系统并索引.txt文件 36 private static int indexDirectory(IndexWriter writer,File dir) throws IOException 37 { 38 39 File[] files=dir.listFiles(); 40 for(int i=0;i<files.length;i++) 41 { 42 File f=files[i]; 43 System.out.println(f.getAbsolutePath()); 44 if(f.isDirectory()) 45 { 46 indexDirectory(writer,f); 47 } 48 else if(f.getName().endsWith(".txt")) 49 { 50 indexFile(writer,f);//递归 51 numIndexed+=1; 52 } 53 } 54 return numIndexed; 55 } 56 //创建IndexWriter并开始文件系统遍历 57 public static int index(File indexDir,File dataDir) throws IOException 58 { 59 if(!dataDir.exists()||!dataDir.isDirectory()) 60 { 61 throw new IOException(dataDir+"does not exist or is not a directory!"); 62 } 63 Directory directory = FSDirectory.open(Paths.get("index")); 64 IndexWriterConfig iwConfig = new IndexWriterConfig( new StandardAnalyzer()); 65 IndexWriter writer = new IndexWriter(directory, iwConfig); 66 int numIndexed=indexDirectory(writer,dataDir); 67 writer.close(); 68 return numIndexed; 69 } 70 public static void main(String[] args) throws Exception 71 { 72 File indexDir=new File("index"); 73 File dataDir=new File("raw"); 74 int numIndexed=index(indexDir,dataDir); 75 System.out.println("Indexing " + numIndexed + " files"); 76 } 77 78 79 }
这个程序的源代码可以到这里下载:https://github.com/shelly-github/my_simple_Lucenetest
下载及导入方法同上,同样注意的是,我没有上传Index文件,需要先运行Indexer建立索引,然后再利用Searcher进行检索~
现在,我们已经学会了遍历一个文件系统来建立索引,是不是很简单呢?
下一节,我们来深入了解一下Lucene的检索原理~~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号