增量式强化学习
线性逼近:
相比较于非线性逼近,线性逼近的好处是只有一个最优值,因此可以收敛到全局最优。其中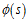 为状态s处的特征函数,或者称为基函数。
为状态s处的特征函数,或者称为基函数。
常用的基函数的类型为:
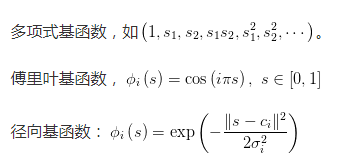
增量式方法参数更新过程随机性比较大,尽管计算简单,但样本数据的利用效率并不高。而批的方法,尽管计算复杂,但计算效率高。
批处理方法:

深度强化学习:


相比较于非线性逼近,线性逼近的好处是只有一个最优值,因此可以收敛到全局最优。其中为状态s处的特征函数,或者称为基函数。
常用的基函数的类型为:
增量式方法参数更新过程随机性比较大,尽管计算简单,但样本数据的利用效率并不高。而批的方法,尽管计算复杂,但计算效率高。
批处理方法:


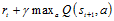 。
。