R学习笔记(2):R中的数据类型和数据结构
本文最新版已更新至:http://thinkinside.tk/2013/05/09/r_notes_2_data_structure.html
尽管前面提到R是面向对象的,但是个人认为R中的所谓对象其实只是一种结构(struct)。还是要使用函数对其进行操作。
R中的数据结构主要面向《线性代数》中的一些概念,如向量、矩阵等。值得注意的是,R中其实没有简单数据(数值型、逻辑型、字符型等),对于简单类型会自动看做长度为1的向量。比如:
> b=5 > length(b) [1] 1 > typeof(b) [1] "double" > mode(b) [1] "numeric"
R中最重要的数据结构是向量(vector)和矩阵(matrix)。
向量由一系列类型相同的有序元素构成;矩阵是数组(array)的一个特例:维数为2的数组;而数组又是增加了维度(dim)属性的向量。
除此之外,列表(list)和数据框(data frame)分别是向量和矩阵的泛化——列表允许包含不同类型的元素,甚至可以把对象作为元素;数据框允许每列使用不同类型的元素。对于列表和数据框,其中的元素通常称为分量(components)。
对象的类型和长度
R中所有的对象都有类型和长度属性,可以通过函数typeof()和length()获取/设置。举例如下:
 View Code
View Code

> x = c(1,2,3,4) > x [1] 1 2 3 4 > typeof(x) [1] "double" > length(x) [1] 4 > dim(x)=c(2,2) > x [,1] [,2] [1,] 1 3 [2,] 2 4 > typeof(x) [1] "double" > length(x) [1] 4 > Lst <- list(name="Fred", wife="Mary", no.children=3, + child.ages=c(4,7,9)) > > Lst $name [1] "Fred" $wife [1] "Mary" $no.children [1] 3 $child.ages [1] 4 7 9 > typeof(Lst) [1] "list" > length(Lst) [1] 4
typeof()函数可能返回如下的值(在R源代码src/main/util.c的TypeTable中定义):
# 数据对象
logical 含逻辑值的向量
integer 含整数值的向量
double 含实数值的向量
complex 含复数值的向量
character 含字符值的向量
raw 含字节值的向量
# 其他对象
list 列表
NULL 空
closure 函数
special 不可针对参数求值的内置函数
builtin 可针对参数求值的内置函数
environment 环境
# 通常在R内部使用
symbol 变量名
pairlist 成对列表对象
promise 用于实现悠闲赋值的对象
language R 语言构建
... 特定变量长度参数
any 可以匹配任何类型的特殊类型
expression 表达式对象
externalptr 外表指针对象
weakref 弱引用对象
char 字符
bytecode 二进制
对象的类型不是一成不变的,可以随时进行转换。接着上面的例子:
> typeof(x) [1] "double" > y = as.logical(x) > typeof(y) [1] "logical" 转换的规则如下表: |----| | to numeric | to logical | to character |---+--- from numeric - |0 → FALSE 其它数字 → TRUE | 1, 2, ... → "1", "2" from logical FALSE → 0 TRUE → 1 |- | TRUE → "TRUE" FALSE → "FALSE" from character "1", "2", ... → 1, 2, ... "A",... →NA | "FALSE", "F" → FALSE "TRUE", "T" → TRUE 其它 → NA |
对象的长度也可以随时发生改变,常见的包括如下情况:
> # 扩大索引范围 > x = c(1,2,3) > x [1] 1 2 3 > x[5] = 12 > x [1] 1 2 3 NA 12 > length(x) [1] 5 > # 直接设置length属性 > length(x) = 2 > x [1] 1 2 > # 重新赋值(略) • ✓ 对象的class和attributes typeof()处理对象内元素的类型,而class()处理对象本身的类,例如: > x = 1:6 > x [1] 1 2 3 4 5 6 > typeof(x) [1] "integer" > class(x) [1] "integer" > dim(x) = c(3,2) > x [,1] [,2] [1,] 1 4 [2,] 2 5 [3,] 3 6 > typeof(x) [1] "integer" > class(x) [1] "matrix"
通过class还可以更改对象的类,例如:
> x = 1:6 > class(x) [1] "integer" > class(x) = "matrix" 错误于class(x) = "matrix" : 除非维度的长度为二(目前是0),否则不能设为矩阵类别 > class(x) = "logical" > x [1] TRUE TRUE TRUE TRUE TRUE TRUE
除了typeof和length之外,其他class的对象可能还会有其他的属性,可以通过函数attributes()和attr()进行操作,例如:
> x = 1:6 > attributes(x) NULL > dim(x) = c(3,2) > attributes(x) $dim [1] 3 2 > x [,1] [,2] [1,] 1 4 [2,] 2 5 [3,] 3 6 > attr(x,"dim") = c(2,3) > x [,1] [,2] [,3] [1,] 1 3 5 [2,] 2 4 6
从例子可以看出,属性以列表形式保存,其中所有元素都有名字。
从例子还可以看出,R的数组中,元素的排列顺序是第一下标变化最快,最后下标变化最慢。这在FORTRAN中叫做“ 按列次序”。
一些常见的属性如下:
names,可以为向量或列表的每个元素增加标签。
> x = 1:6 > x [1] 1 2 3 4 5 6 > attributes(x) NULL > attr(x,'names') = c('a','b','c') > x a b c <NA> <NA> <NA> 1 2 3 4 5 6 > attributes(x) $names [1] "a" "b" "c" NA NA NA
dim,标记对象的维度。除向量外,基于数组的对象都会有一个维度属性,是一个指定数组各维度长度的整数向量。与下标类似,维度也可以命名。通过dimnames属性可以实现这一目的:
> x = array(1:6,2:3) > x [,1] [,2] [,3] [1,] 1 3 5 [2,] 2 4 6 > attributes(x) $dim [1] 2 3 > names = list(c('x','y'),c('a','b','c')) > dimnames(x) = names > x a b c x 1 3 5 y 2 4 6 > attributes(x) $dim [1] 2 3 $dimnames $dimnames[[1]] [1] "x" "y" $dimnames[[2]] [1] "a" "b" "c"
访问对象中的元素
既然对象是元素的集合,很自然就会想到使用下标来访问对象中的元素:
> x = array(6:1,2:3) > x [,1] [,2] [,3] [1,] 6 4 2 [2,] 5 3 1 > x[1] #按照存储的顺序访问单个元素 [1] 6 > x[2] #按照存储的顺序访问单个元素 [1] 5 > x[3] #按照存储的顺序访问单个元素 [1] 4 > x[1,2] #通过多个下标访问单个元素 [1] 4 > x[1,] #返回一行 [1] 6 4 2 > x[,1] #返回一列 [1] 6 5
如果对象有names属性,还可以通过names进行索引:
> x = array(6:1,2:3) > > names(x) = c('a','b','c') > x [,1] [,2] [,3] [1,] 6 4 2 [2,] 5 3 1 attr(,"names") [1] "a" "b" "c" NA NA NA > x['b'] #等价于x[2] b 5
上面两个例子都是返回对象中的单个元素。在R中,还可以返回对象的多个元素,此时使用的索引不是简单的数值或字符串,而是一个向量。继续上面的例子:
> x[1:3] a b c 6 5 4 > x[c(3,4)] c <NA> 4 3 > x[c(1,2),c(1,2)] [,1] [,2] [1,] 6 4 [2,] 5 3 > x[c('a','b')] a b 6 5
用序列填充对象
前面的例子中,你可能会注意到一些与python类似的语法,比如序列:
a:b
R中提供了一些创建序列的方法,可以很方便的填充对象。包括规则序列和随机序列。
规则序列用于产生有规则的序列:
使用a:b的形式是最简单的用法;
如果需要更多的控制,可以使用seq(from,to,by,length,along)函数;
使用rep()函数可以产生重复的元素。
例如:
> 1:3 [1] 1 2 3 > 2*1:3 [1] 2 4 6 > 3:1 [1] 3 2 1 > seq(1,2,0.2) [1] 1.0 1.2 1.4 1.6 1.8 2.0 > seq(1,2,0.3) [1] 1.0 1.3 1.6 1.9 > seq(to=2,by=.2) [1] 1.0 1.2 1.4 1.6 1.8 2.0 > seq(to=2,by=.2,length=3) [1] 1.6 1.8 2.0 > rep(1:3,2) [1] 1 2 3 1 2 3 > rep(1:3,each=2) [1] 1 1 2 2 3 3
随机序列用于产生符合一定分布规则的数据。有大量的函数用于产生随机序列,这里只列出一些函数的名称:

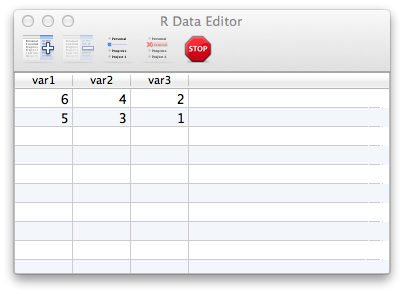
数据编辑器
我们当然可以使用下标操作对象,编辑对象中的数据元素。但是R提供的一个可视化的工具能够带来更多的便利,这就是数据编辑器。
使用data.entry()函数可以打开数据编辑器:
> x = array(6:1,2:3)
> data.entry(x)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号