

Robot Framework + Selenium2Library环境下,结合Selenium Grid实施分布式自动化测试
最近一段时间,公司在推行自动化测试流程,本人有幸参与了自定义通用控件的关键字封装和脚本辅助编写、数据驱动管理、测试用例执行管理等一系列工具软件的研发工作,积累了一些经验,在此与大家做一下分享,也算是做一个总结吧,希望能给大家带来启发和帮助。由于业界没有成熟的解决方案可供参考,本人在研究过程中也是摸着石头过河,纰漏之处在所难免,如果大家有更好的方案,敬请不吝赐教。
分布式并行执行用例需求背景
公司的产品属于web app,采用的是Robot Framework + Selenium2Library 作为自动化测试的框架。脚本开发完毕,在推广试用的过程中,测试人员反馈了一个问题:当case数量很多的时候,需要执行很长的时间才能跑完,这往往无法跟上产品发布迭代的节奏。他们的要求是:100个case要求在一个小时之内跑完(平均一个case需要3到5分钟)。经过对比和研究,最终决定利用Selenium Grid来将这些case分散到多台机器去执行,通过分布式并行执行的方式,压缩执行时间。
关于Selenium Grid的介绍、运行原理、安装部署等细节,请参考 http://blog.csdn.net/five3/article/details/9428655,在此不作详述。
分布式并行执行用例管理工具一览
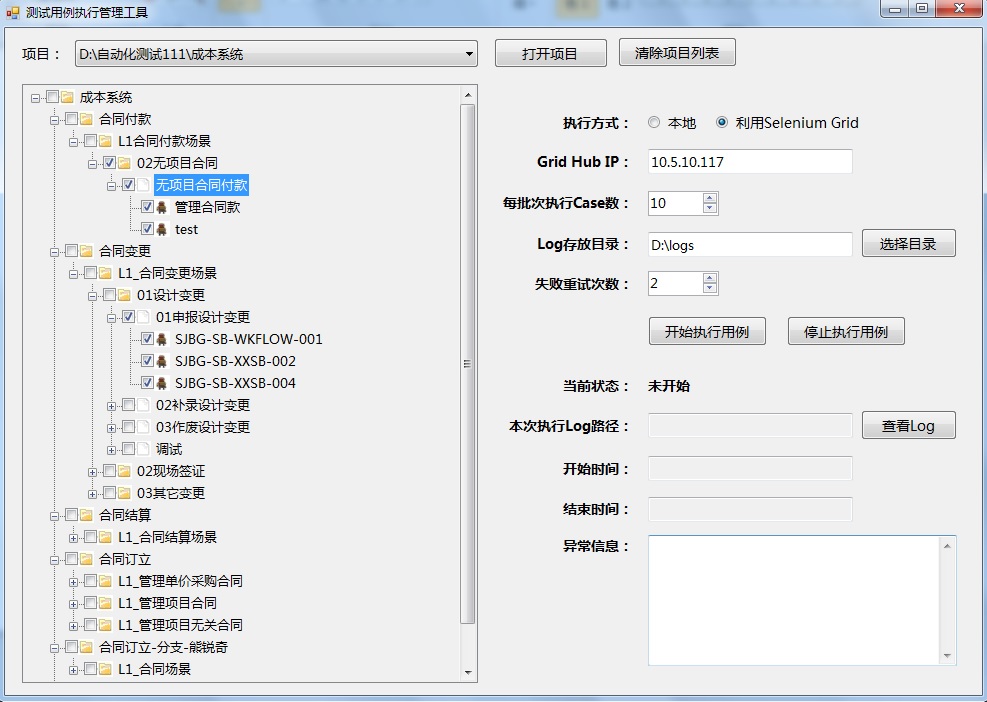
为了更好的贴合公司实际需求,我开发了一个winform应用程序来管理case的执行过程。主要功能包括:
1. 支持本机执行和分布式并行执行这两种执行方式
2. 由于环境和框架本身的不稳定性,需要在脚本出错的情况下(包括case fail掉了或者是robot framework框架出错),能自动对出错的case做一定的重试,以此消除环境的不稳定因素对执行过程的影响。
3. 支持有条件的并行(有条件并行的概念将在后面介绍)。
工具界面如下(左侧是case选择界面,右侧是选项面板和执行结果信息):
Robot Framework 与 Selenium Grid 之间的桥梁
Selenium Grid安装好之后,是一个独立的系统,与外界没有任何联系,它不会自动获取case、自动分发请求。所以,要利用Selenium Grid,首先要研究如何把case执行请求发送给Grid。
网上有不少介绍Selenium Grid的文章,多以webdriver的API作为与Selenium Grid交互的途径,典型代码如下:
DesiredCapabilities dc = DesiredCapabilities.firefox(); WebDriver dr = new RemoteWebDriver(new URL("http://192.168.40.67:5555/wd/hub"),dc); dr.get("http://www.baidu.com");
但是Robot Framework如何与Selenium Grid进行交互呢?我们知道,Robot Framework只是一个自动化测试框架而已,它之所以能够测试各种类型的应用程序,是因为它可以挂接不同的库,比如,挂接Selenium2Library,就可以测试web app,最终执行测试的动作还是由相应的库来完成的。
Selenium2Library对selenium类库做了一下包装,形成了相应的python类,与selenium相关的关键字就是调用这些类的方法,比如:关键字 “open browser” 就是调用的_BrowserManagementKeywords这个类的open_browser方法(python文件路径为C:\Python27\Lib\site-packages\Selenium2Library\keywords\_browsermanagement.py,安装方式不同,路径会略有不同)。
研究这个方法的代码可以知道,参数remote_url的作用与上面RemoteWebDriver类构造方法的第一个参数的作用是类似的。于是,我们可以考虑在这个参数上做文章。那么,我们是否需要修改所有case的脚本,如下图所示加上这个参数呢? 
显然,这种方式不好。两个原因:1. 需要大量的修改现有的脚本;2. 参数是写死的,无法与工具选项设置关联起来。
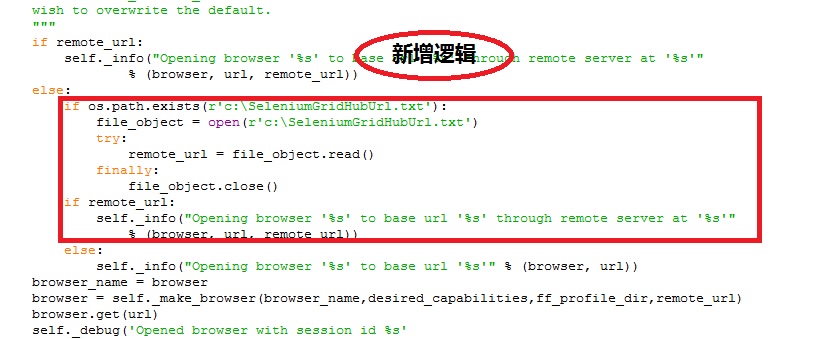
所以,在不修改脚本的情况下,要同时支持在本地和分布式执行用例,最直接的方法就是修改_BrowserManagementKeywords类的open_browser方法,因为不管是哪种执行方式,这个方法都会被调用。
另外,工具选项面板上的执行方式选项如何通知给这个方法呢?我的办法是通过一个全局桥梁文件来作为彼此通信的纽带,工具依据选项设置生成或者删除桥梁文件;open_browser方法判断文件是否存在并读取文件内容作为remote_url参数的值。
工具选项设置代码片段:
//Hub URL存放文件 private const string SeleniumGridHubUrlFilePath = "c:\\SeleniumGridHubUrl.txt"; //生成、删除remote url参数文件 if (this.radioButton1.Checked) { File.Delete(SeleniumGridHubUrlFilePath); } else { File.WriteAllText(SeleniumGridHubUrlFilePath,string.Format("http://{0}:4444/wd/hub",this.textBox3.Text.Trim())); }
py文件方法修改:
Robot Framework 命令行介绍
打通了Robot Framework与Selenium Grid之间的联系之后,我们开始研究如何通过工具执行case。
在脚本开发调试过程中,一般用的RIDE集成环境,但是如果用工具来管理执行过程的话,就无法再使用RIDE了,只能想别的办法。如果仔细观察过RIDE的一些窗口输出信息的话,一定能注意到它会把本次执行对应的DOS command打印出来,如下图所示:
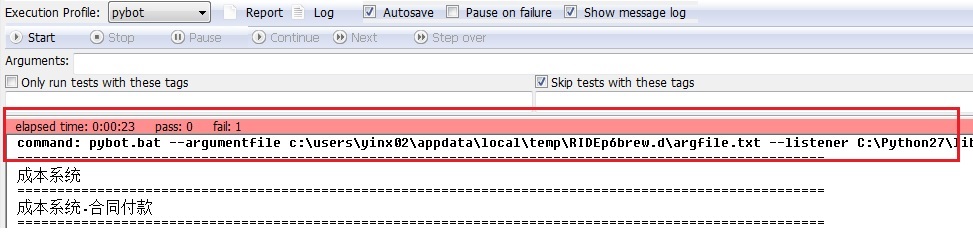
其实,RIDE就是调用这个命令行来执行用例的,所以我们也可以通过调用命令行的方式来执行用例。由于工具会涉及到执行用例、错误用例重试、合并报告这三种功能,所以这里就简单介绍一下这三个命令。更多命令,可以通过在dos命令行里面输入 pybot --help 查询。
1. 执行用例
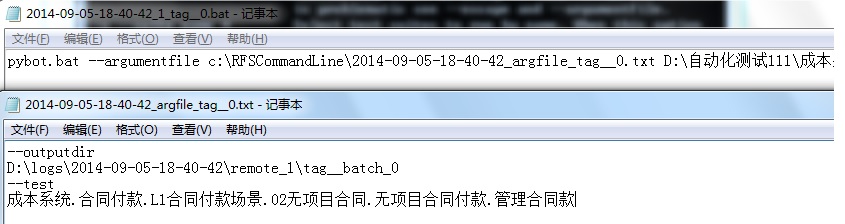
--test : 指定要执行的case名称(全路径) --outputdir : log存放路径 --argumentfile : 选项文件路径 参数1 : 要执行的suite路径
示例:
2. 重试用例
-R : 表示要重试错误用例 -d : 本次执行log存放路径 参数一 : 需要执行重试的output.xml文件路径 参数二 : suite路径
示例:
pybot -R D:\logs\2014-09-05-18-40-42\remote_1\tag__batch_0\output.xml -d D:\logs\2014-09-05-18-40-42\remote_2\tag__batch_0 D:\自动化测试111\成本系统
3. 合并报告(使用rebot指令,详细说明可以通过 rebot --help 查看)
-N : 重命名报告 -d :产生的新log的存放路径 参数一 : 需要合并的log路径(支持通配符)
示例:
rebot -N 第1次执行 -d D:\logs\2014-09-05-18-40-42\1 D:\logs\2014-09-05-18-40-42\remote_1\*\output.xml
工具就是通过调用上述三个命令并辅以一定的流程控制逻辑来完成执行、重试、合并报告的功能。
代码片段:首先生成一个批处理文件,然后启动一个DOS命令行窗口执行这个bat文件
//生成参数文件 string argFilePath = @"c:\RFSCommandLine\" + batchTime + "_argfile.txt"; string argFileContent = "--outputdir\r\n" + Path.Combine(logFolder, "1") + "\r\n" + BuildTestCaseCommandOption(selectedCases); File.WriteAllText(argFilePath, argFileContent, Encoding.GetEncoding("utf-8")); //生成批处理文件 batchFilePath = @"c:\RFSCommandLine\" + batchTime + "_1.bat"; content = string.Format(@"pybot.bat --argumentfile {0} {1}", argFilePath, currentProjectPath); File.WriteAllText(batchFilePath, content, Encoding.GetEncoding("gb2312"));
//调用批处理文件
try
{
Process p = new Process();
p.StartInfo.FileName = batchFilePath;
p.Start();
p.WaitForExit();
}
工具设计思路分析
一. 基本概念介绍
1. hub分发请求的粒度
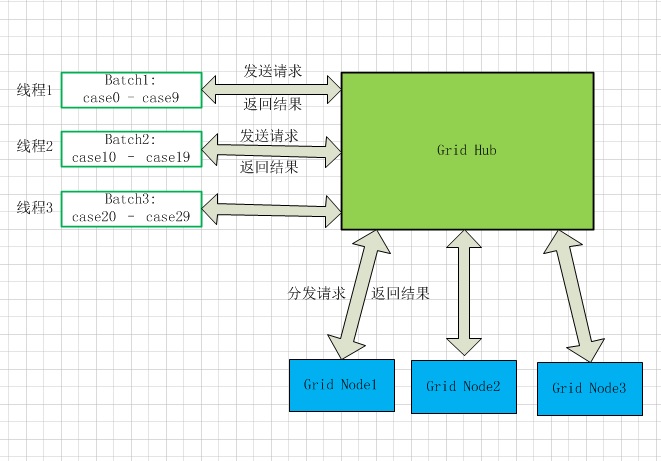
刚开始研究Selenium Grid的时候,以为只要把所有选中的case放到一个批处理文件里面,然后运行该批处理,这样就可以把执行请求发送给hub,hub就会自动分发请求到各个空闲节点。但事实证明,不是这样的,hub只会随机选择一个空闲节点,然后一根筋的把所有的case都分发到该节点执行,而不是分发给所有空闲的节点。这说明hub分发请求的粒度是批处理DOS命令行为单位的,而不是单个的case,一个DOS命令行里的所有case始终是在同一个节点上执行,不会被打散。为了能多节点并行执行,我们需要人为的将这些case拆成一批一批的,也就是下面要介绍的请求批次的概念。
2. 请求批次
所谓“请求批次”,指的是按照某种算法逻辑,将需要执行的case列表进行拆分,形成批次。举个例子,我有100条case,如果设定每个批次包含10个case,那么我们可以将这100个case拆分成10个批次。如果我同时将这10个批次发送给hub,那么hub此时就会寻找所有空闲的节点,并将这些批次调度分发给这些节点执行,这样就可以达到并行的目的了。我这里是采用多线程技术完成这个任务,一个线程启动一个批处理文件,一个批处理文件中包含着一个批次的case,三者之间是一一对应的关系。示意图如下:
代码片段:
for (int i = 0; i < splittedCaseList.Count; i++) { string argFilePath = @"c:\RFSCommandLine\" + batchTime + "_argfile_tag_" + tag + "_" + i.ToString() + ".txt"; string argFileContent = "--outputdir\r\n" + Path.Combine(Path.Combine(logFolder, "remote_1"), "tag_" + tag + "_batch_" + i.ToString()) + "\r\n" + BuildTestCaseCommandOption(splittedCaseList[i]); File.WriteAllText(argFilePath, argFileContent, Encoding.GetEncoding("utf-8")); batchFilePath = @"c:\RFSCommandLine\" + batchTime + "_1_tag_" + tag + "_" + i.ToString() + ".bat"; content = string.Format(@"pybot.bat --argumentfile {0} {1}", argFilePath, currentProjectPath); File.WriteAllText(batchFilePath, content, Encoding.GetEncoding("gb2312")); Thread thread = new Thread(new ParameterizedThreadStart(RunRemoteCommand)); threads.Add(thread); thread.Start(batchFilePath); }
3. 串行与并行
“并行”指的是多个批次的case可以分散到不同的节点同时执行;“串行”指的是有些流程必须按顺序执行,比如:只有完成了第一次执行的所有批次之后,才可以进入第一次重试环节,第一次重试结束了,才可以开始第二次重试,所有重试结束之后,才可以开始合并报告。那么启动了那么多的线程,我们如何管理好它们的执行顺序呢?这里可以利用线程同步机制,在串行流程中,适当地做一下等待。代码片段:
//阻塞调用线程,等待所有并行线程都结束,才开始后续串行操作
foreach (Thread thread in threads) { thread.Join(); }
4. 全局资源与并行干扰(有条件并行)
"全局资源“指的是各个模块功能共用的一些配置、选项、或者数据库中公共的表之类的一些全局型的资源。全局资源具有排他性,比如:不能一个case把某个选项开关打开,而另外一个case同时又把这个开关关掉。如果这样的话,这两个case之间互相造成干扰,会导致case执行出错,或者测试结果不准确。所以说,并行并不是绝对的并行,而是有条件的,我们需要识别出这种隐藏在业务逻辑中的排斥关系。
5. tag分组
目前,我是采用按tag分组的办法解决有条件并行的问题。我们可以在case上打上相关的特性tag,先按照tag进行分组,每个组内再分批次。这样,tag组内可以并行执行,tag组与组之间必须串行执行。
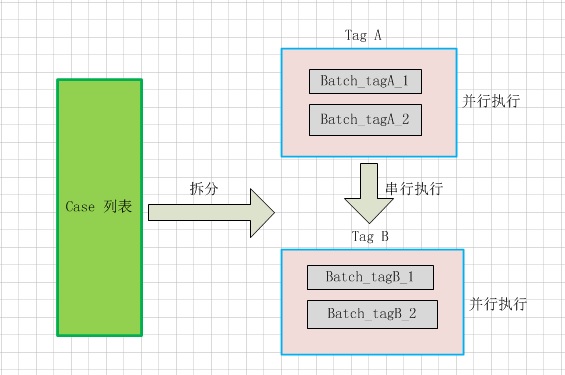
二. 整体流程示意图
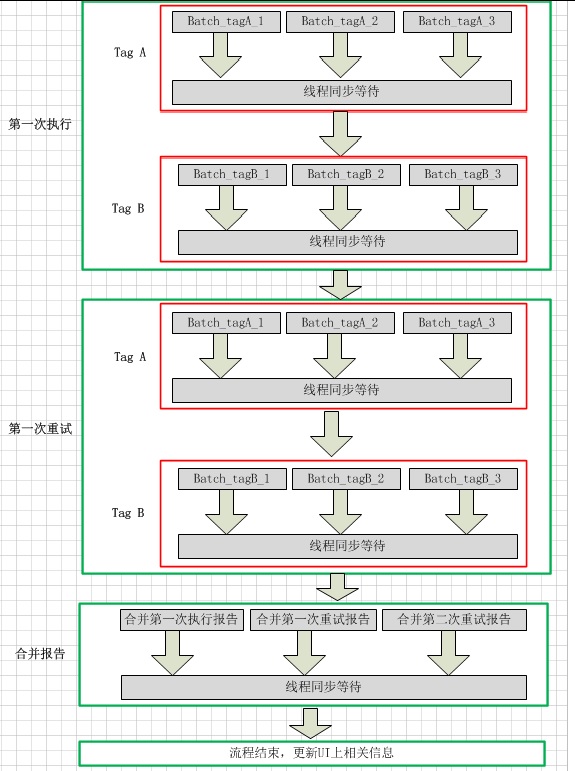
三. 工具开发中碰到的问题、优化、展望
问题1: 合并log时,rebot命令不会自动把相关的出错截图拷贝到目标路径
解决办法:合并之前,先修改一下每个批次里面的output.xml文件,对截图路径做一个修正,保持正确的相对路径即可。
log存放目录结构如下:
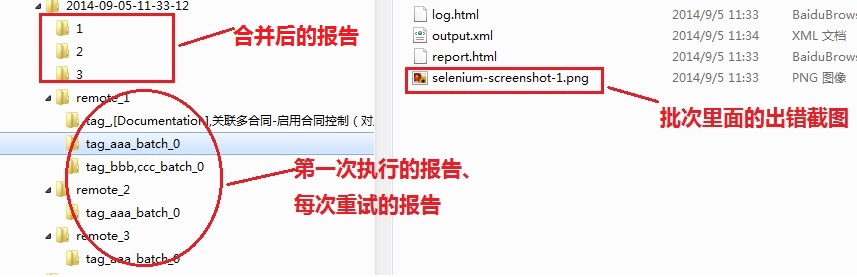
代码片段:
//截图文件名关键字 string eleniumScreenshotKeyword = "selenium-screenshot-"; //读output.xml文件 string outputContent = File.ReadAllText(Path.Combine(remotePath, "output.xml"), Encoding.UTF8); //修正截图路径为相当路径 outputContent = outputContent.Replace(eleniumScreenshotKeyword, string.Format("../remote_{0}/tag_{1}_batch_{2}/", i,tag, j) + eleniumScreenshotKeyword); //保存output.xml文件 File.WriteAllText(Path.Combine(remotePath, "output.xml"), outputContent, Encoding.UTF8);
问题2: 批次同时执行suite setup会互相干扰
我们有时需要在suite执行时先做一个初始化的动作,比如还原数据库快照,这可以通过设置suite的suite setup完成。问题是,当我们把case列表拆成多个批次并行执行时,每个批次都会执行一遍suite setup,这同样存在并行干扰的问题。比如:批次A刚还原了数据库,正在跑case,突然批次B又把数据库还原了,那么这两个批次之间就互相干扰了。
解决办法:将suite setup的事情挪到工具里面来做,工具可以控制在适当的时机执行suite setup,比如:第一次执行完毕,还原数据库,第一次重试,再还原数据库,第二次重试,再还原数据库......如此穿插执行。假设我有一个叫“还原数据库”的关键字,如何在工具里面调它呢?工具只会调case,不会调关键字啊。我们知道,Robot Framework的case和关键字资源文件其实都是一些普通的文本文件,是可以直接编辑的。于是想了一个变通的办法:修改某个case的内容,在最后追加一个case,随便起个名字,就叫“RestoreDB”吧,这个case就调用“还原数据库”关键字。这样,就可以在工具中执行RestoreDB这个case做数据库还原了。
代码片段:
string restoreDBCaseStatement = "\r\n\r\nRestoreDB\r\n 数据库还原"; string fileContent = File.ReadAllText(caseFilePath); //往case文件中增加RestoreDB File.WriteAllText(caseFilePath, fileContent + restoreDBCaseStatement);
问题3: 执行环境不稳定、挂死
在实际执行case的过程中,经常会出现一些莫名其妙的问题,比如:
1. 跑着跑着IEDriverServer.exe这个进程不起作用了,僵死了
2. 模态对话框很讨厌,特别是无法预知的模态框,如果不调用confirm action把它消掉的话,即使你在test teardown里面调close all browsers,也是关不掉IE窗口的,这极有可能会导致case结束了,但IE进程和IEDriverServer.exe进程都还在的情形。
不管怎么样,总是会出现case结束了,但IEDriverServer.exe进程还在的情况。对于本地执行方式来说,一旦有两个IEDriverServer.exe进程同时存在的话,那么执行环境就很不稳定了,什么奇怪的事情都可能发生;而对于selenium grid环境来说,如果一个case结束了,但IEDriverServer.exe进程还活着的话,会被hub认为该节点处于繁忙状态,hub就不会给它分发下一个case,那么当前批次一直被阻塞,其他批次也要等待这个批次(线程同步),进而整个执行流程都会被阻塞,后果相当严重。
如果是在本地执行的话,我可以在case setup里面调用OperationSystem.Run关键字去杀 IEDriverServer.exe进程和IE进程;但是,如果是利用selenium grid分布式执行的话,这种操作系统级别的关键字,是无法通过hub转发到节点机器上执行的,因为hub只会转发webdriver支持的指令,其他指令都是在本地执行的。
所有,必须要想办法保证每个case执行完毕后,IEDriverServer.exe进程和IE进程都必须被清理掉,否则整个Selenium Grid体系就玩不转了,这点很重要。
解决办法:我也没想到一个比较优雅的办法来解决Selenium Grid稳定性的问题,用的一个比较偏门的办法:
1. 开发一个WCF服务部署到节点机器,它暴露的URL为:http://localhost:8732/gridservice/action/killprocess,其作用就是杀IE进程和IEDriverServer进程。
2. 定义一个关键字,叫“安全退出case”,内容如下:

3. 在case的teardown里面调用“安全退出case”关键字
这样做,为什么能达到目的呢?
1. 首先调用“close all browsers”是为了杀IEDriverServer进程的(但是有可能IE进程杀不掉,不过没关系),保证hub会开一个新的session执行后续的那个”open browser“命令。
2. ”open browser“是selenium库支持的命令,所有是可以分发到hub的。
3. 不管请求分发到哪个节点,localhost都是指的是节点本机,所以调的是节点本机的服务,当然杀的也是节点自己的进程。
4. 调用“open browser”访问WCF服务的URL,类似于自杀式袭击。因为这个调用会报错,但是可以不用管,所有用“Run Keyword And Ignore Error”关键字保护起来。袭击完毕,各种残余都被清理的干干净净(包括IE进程和IEDriverServer进程)。
这个方案经过测试之后,发现有一个问题:正常情况下,IEDriverServer.exe进程是在webdriver调用quit方法之后自动退出的,hub与节点之间也是正常的交换信息;而采用自杀式袭击,来的比较突然,hub根本不知道节点发生什么事情,好像变的有点无所适从了,不停的试图与节点建立联系(但是节点又不会正确的通知自己的信息给hub,因为它的进程是非正常终止),直到超时时间到了,才重新和节点建立一个新的session,然后开始后续的执行。hub的默认超时时间是300秒,要等的时间有点久,那么只好把这个时间设短一点吧,希望它早点超时,早点建立新session。可以在启动hub的时候,通过 -timeout 选项设置超时时间。
java -jar selenium-server-standalone-2.39.0.jar -role hub -timeout 20
经过上述优化之后,实际跑下来效果还可以,后续还要经过大规模的实际运行来考察这个方案是否成熟稳定。
对于工具的后续规划,有两点考虑:
1. 开发一个grid的集中管理程序,可以在一台机器上统一管理hub、各个节点,包括hub的启动、关闭、节点与hub的连接及断开,这样就不用远程登录到每台机器去操作了。
2. 开发一个调度程序,用于管理整个公司的测试时间安排,希望可以协调好优先级,均衡的利用grid,不致于一会儿扎堆的使用grid,一会儿又长时间的让grid空闲。

