caffe学习笔记1——运行caffe自带的程序,mnist和cifar10
学习参考:http://www.cnblogs.com/denny402/category/759199.html 非常详细,非常优质的caffe入门博客
为了程序的简洁,在caffe中是不带练习数据的,因此需要自己去下载。但在caffe根目录下的data文件夹里,作者已经为我们编写好了下载数据的脚本文件,我们只需要联网,运行这些脚本文件就行了。但是呢,我是在windows下用的caffe,不能直接运行.sh的shell文件,不过我们可以用Git Shell来运行它,我们只需要安装github桌面版就会安装上Git Shell。(由于windows与linux的差别,并不是caffe中提供的所有shell文件在windows中都能成功运行,此时就需要自己将shell文件改写成windows下bat文件)
注意:在caffe中运行所有程序,都必须在根目录下进行,否则会出错(因为很多文件设置时,就是假设执行目录是caffe根目录)
1、mnist实例
mnist是一个手写数字库,由DL大牛Yan LeCun进行维护。mnist最初用于支票上的手写数字识别, 现在成了DL的入门练习库。征对mnist识别的专门模型是Lenet,算是最早的cnn模型了。
mnist数据训练样本为60000张,测试样本为10000张,每个样本为28*28大小的黑白图片,手写数字为0-9,因此分为10类。
首先下载mnist数据,假设当前路径为caffe根目录,可以在Git Shell中执行
sh data/mnist/get_mnist.sh
运行成功后,在 data/mnist/目录下有四个文件:
train-images-idx3-ubyte: 训练集样本 (9912422 bytes)
train-labels-idx1-ubyte: 训练集对应标注 (28881 bytes)
t10k-images-idx3-ubyte: 测试集图片 (1648877 bytes)
t10k-labels-idx1-ubyte: 测试集对应标注 (4542 bytes)
或者直接去官网下载 http://yann.lecun.com/exdb/mnist/
将下载后的文件解压到data/mnist/目录下
这些数据不能在caffe中直接使用,需要转换成LMDB数据
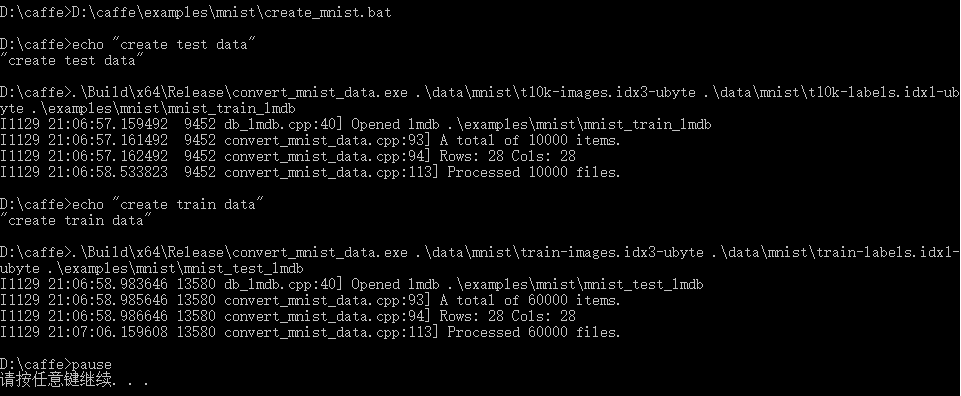
在.\examples\mnist\下建立文件create_mnist.bat输入以下内容
echo "create test data" .\Build\x64\Release\convert_mnist_data.exe .\data\mnist\t10k-images.idx3-ubyte .\data\mnist\t10k-labels.idx1-ubyte .\examples\mnist\mnist_train_lmdb echo "create train data" .\Build\x64\Release\convert_mnist_data.exe .\data\mnist\train-images.idx3-ubyte .\data\mnist\train-labels.idx1-ubyte .\examples\mnist\mnist_test_lmdb pause
如果出现下面错误,说明路径中已经存在mnist_train_lmdb或者mnist_test_lmdb系统无法创建目录,需要先删掉它们

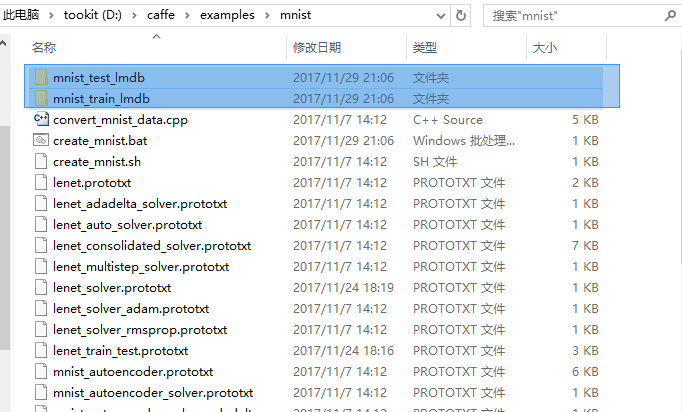
执行成功会在examlpes\mnist\下面生成两个文件夹mnist_train_lmdb和mnist_test_lmdb,里面存放了转换好的数据
接下来是修改配置文件,caffe最主要的两个配置文件就是lenet_solver.prototxt和train_lenet.prototxt.
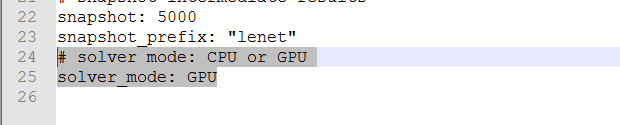
打开lenet_solver_prototxt,根据需要修改slover_model,train_lenet.prototxt这里可以不做修改
用下面命令运行这个例子
caffe.exe train --solver=.\examples\mnist\lenet_solver.prototxt
Pause
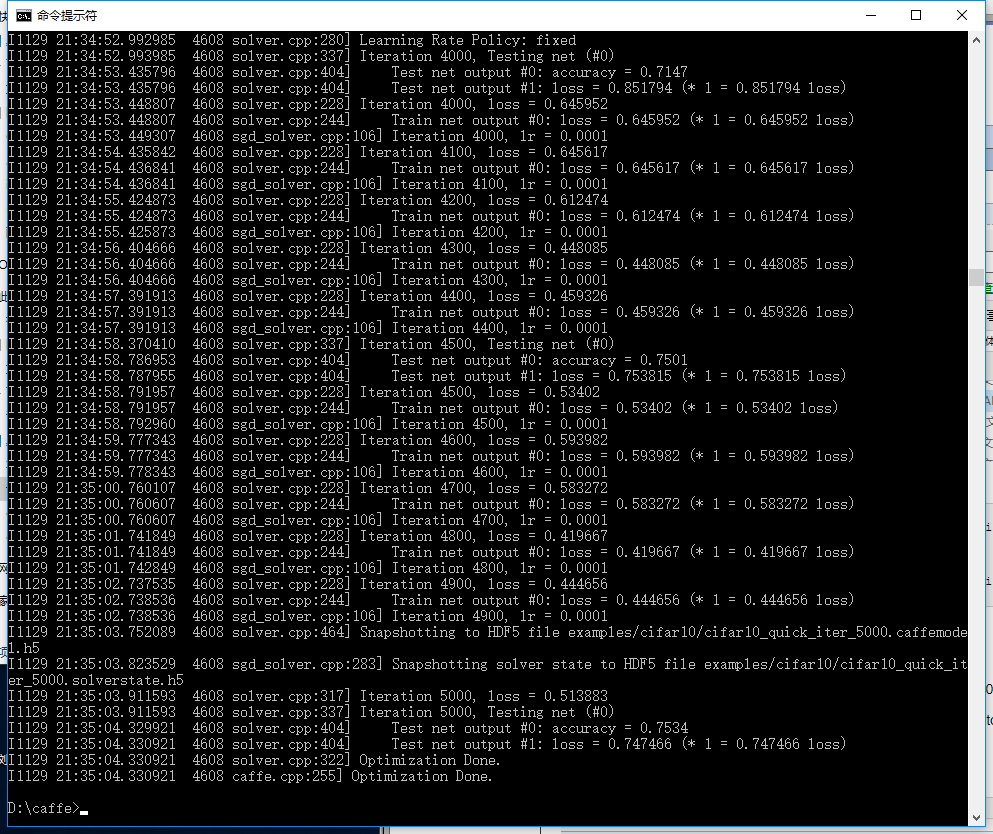
运行结果如下

2、cifar10实例
cifar10数据训练样本50000张,测试样本10000张,每张为32*32的彩色三通道图片,共分为10类。
下载数据:
sh data/cifar10/get_cifar10.sh
(或者通过链接http://www.cs.toronto.edu/~kriz/cifar-10-binary.tar.gz下载)
运行成功后,会在 data\cifar10\文件夹下生成一堆bin文件(其中的cifar-10-binary.tar.gz是我通过链接下载的,解压后会得到哪些bin文件)
转换数据格式为lmdb:
在examples\cifar10\下建立文件create_cifar10.bat,并输入
.\Build\x64\Release\convert_cifar_data.exe .\data\cifar10 .\examples\cifar10 lmdb pause .\Build\x64\Release\compute_image_mean.exe -backend=lmdb .\examples\cifar10\cifar10_train_lmdb .\examples\cifar10\mean.binaryproto pause
在caffe根目录下运行create_cifar10.bat后会在examples\cifar10\中生成两个文件夹cifar10_test_lmdb和cifar10_train_lmdb和均值文件mean.binaryproto
继续在examples\cifar10\下建立文件train_quick.bat,输入
.\Build\x64\Release\caffe.exe train --solver=examples\cifar10\cifar10_quick_solver.prototxt
.\Build\x64\Release\caffe.exe train --solver=examples\cifar10\cifar10_quick_solver_lr1.prototxt --snapshot=examples\cifar10\cifar10_quick_iter_4000.solverstate.h5
运行train_quick.bat开始i训练
该例子为了节省时间,进行快速训练(train_quick),
训练分为两个阶段,第一个阶段(迭代4000次)调用配置文件cifar10_quick_solver.prototxt, 学习率(base_lr)为0.001
第二阶段(迭代1000次)调用配置文件cifar10_quick_solver_lr1.prototxt, 学习率(base_lr)为0.0001
训练结果如下图