
ASF(Apache软件基金会) 新兴的顶级大数据项目
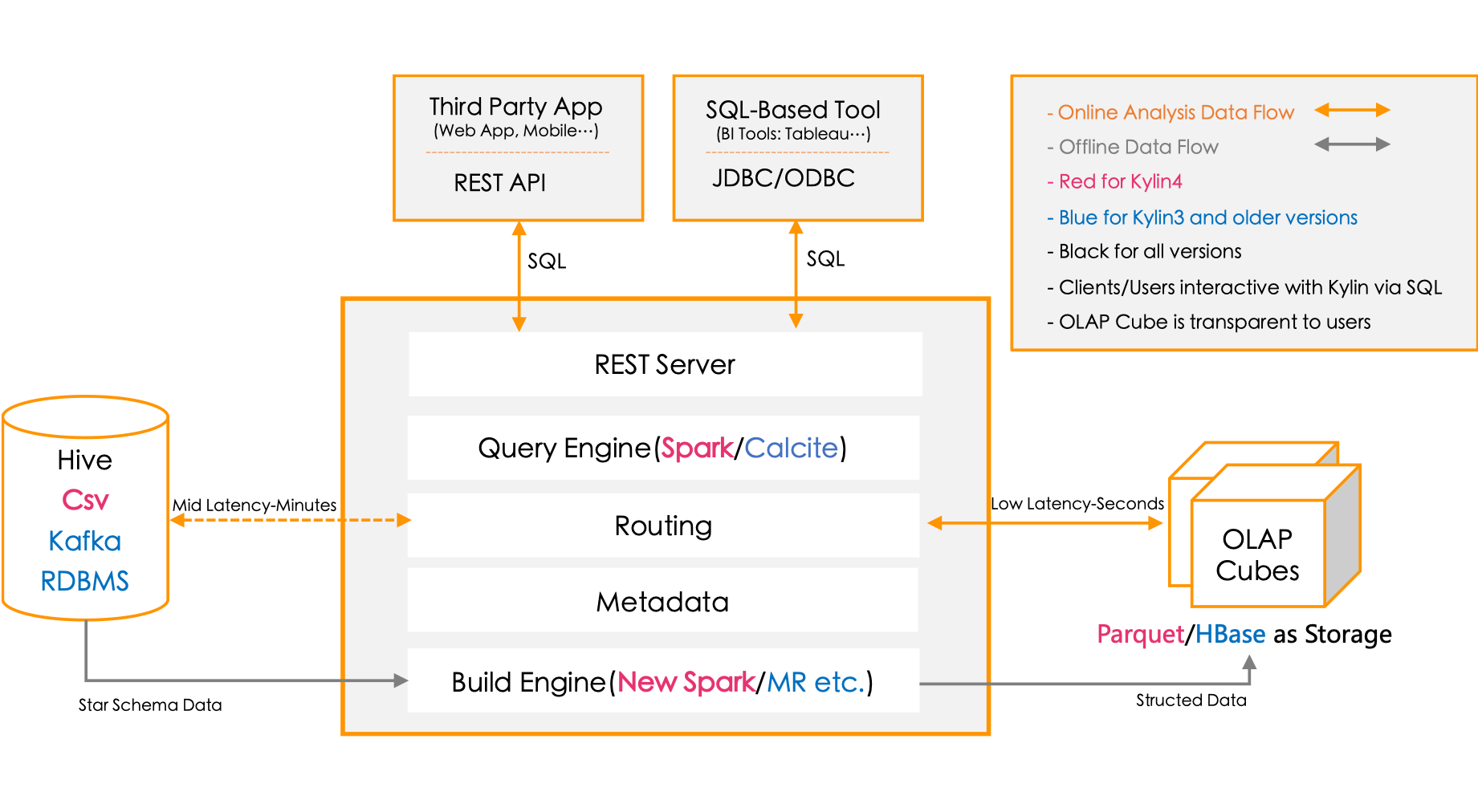
Kylin
ebay开源, 分布式分析引擎. 提供Hadoop之上的SQL查询接口及多维分析(OLAP)能力以支持超大规模数据
http://kylin.apache.org/
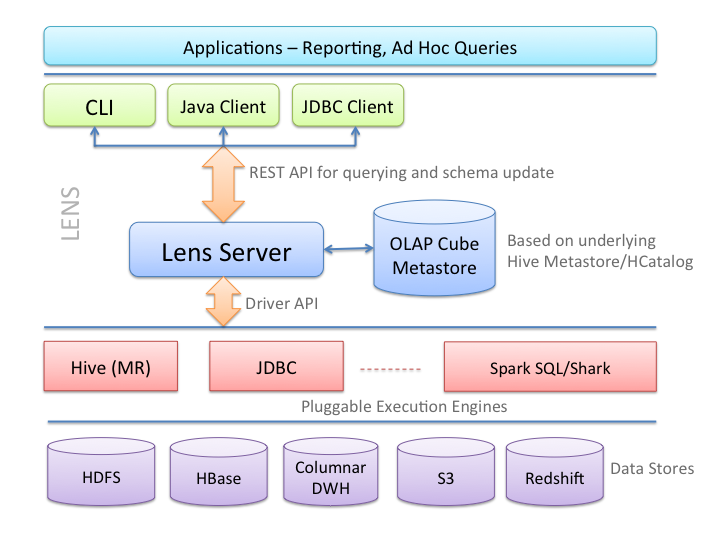
lens
一个开源的大数据和分析工具. 通过提供一个跨多个数据存储的单一视图来横向打通数据分析中遇到的异构单元.
https://lens.apache.org/
Ignite
Apache Ignite内存数据架构是一个高性能, 可集成并且分布式内存平台, 用于对大规模数据集进行实时的计算和处理, 比传统基于磁盘或闪存的技术大约快一个数量级.

Brooklyn
https://brooklyn.apache.org/
一个基于微服务架构的部署监控平台.
1, 模型
Blueprints describe your application, stored as text files in version control
Compose from the dozens of supported components or your own components using bash, Java, Chef…
2, 部署
Components configured & integrated across multiple machines automatically
20+ public clouds, or your private cloud or bare servers - and Docker containers
3, 管理
Monitor key application metrics; scale to meet demand; restart and replace failed components
View and modify using the web console or automate using the REST API
Apex
http://apex.apache.org/
企业级的统一大数据流处理和批处理引擎.
3大特点:
1, 企业级: 它是内置了YARN的平台, 统一了大数据流处理和批处理. 它能动态处理大数据, 并且高扩展, 高性能, 高容错, 带有状态, 安全, 分布式, 容易操作.
2, 低门槛: Write your business logic and leave all operability to the platform. It provides a simple API that enables developers to write or re-use generic Java code, thereby lowering the expertise needed to write big data applications.
3, 带操作库: The Apex platform comes with Malhar, a library of operators (modular units of business logic) that can be leveraged to quickly create new and non-trivial applications.
Tajo
http://tajo.apache.org/
相关文章:http://dongxicheng.org/mapreduce-nextgen/apache-tajo/
一个基于Hadoop的大型数据仓库系统.
它是一个用于Hadoop的大型关系型数据和分布式数据仓库系统.
它被用于对存储于HDFS或别的数据源的大数据集进行低延迟, 可扩展的专用查询, 在线聚合, ETL(提取-转换-加载 处理) , 通过支持标准SQL和利用高级的传统数据库技术, Tajo allows direct control of distributed execution and data flow across a variety of query evaluation strategies and optimization opportunities.
Features
- Fast and Efficient
- Fully distributed SQL query processing engine
- Advanced query optimization such as cost-based and progressive query optimization
- Interactive analysis on reasonable data set
- Scalable
- Fault tolerance and dynamic scheduling for long-running queries
- Out-of-core algorithms for data sets larger than main memory
- Compatible
- ANSI/ISO SQL standard compliance
- Hive MetaStore access support
- JDBC driver support
- Various file formats support, such as CSV, JSON, RCFile, SequenceFile, ORC and Parquet
- Easy
- User-defined functions
- Interactive shell
- Convenient Backup/Restore utility
- Asynchronous/Synchronous Java API


