

Python程序的执行过程原理(解释型语言和编译型语言)
Python是一门解释型语言?
我初学Python时,听到的关于Python的第一句话就是Python是一门解释型语言,我就这样一直相信下去,直到发现.pyc文件的存在,如果真是解释型语言,那么生成的.pyc文件的是什么呢?c应该是compiled的缩写才对啊!
为了防止其他学习Python的人也被这句话误解,那么我们就在文中来澄清一下这个问题,并且把一些基础概念给理一理。
解释型语言和编译型语言
计算机是不能够识别高级语言的,所以当我们运行一个高级语言程序的时候,就需要一个“翻译机”来从事把高级语言转变成计算机能读懂的机器语言的过程。这个过程分成两类,第一种是编译,第二种是解释。
编译型语言在程序执行之前,先会通过编译器对程序执行一个编译的过程,把程序转变成集齐语言。运行时就不需要翻译,而直接执行就可以了,最典型的例子就是C语言。
解释型语言就没有这个编译过程,而是在程序运行的时候,通过解释器对程序逐行做出解释,然后直接运行,最典型的例子是Ruby。
通过以上的例子,我们可以来总结一下解释型语言和编译型语言的优缺点,因为编译型语言在程序运行之前就已经对程序做出了“翻译”,所以在运行时就少掉了“翻译”的过程,所以效率比较高。但是我们也不能一概而论,一些解释型语言也可以通过解释器的优化来在对程序做出翻译时对整个程序做出优化,从而在效率上超过编译型语言。
此外,随着Java等基于虚拟机的语言的兴起,我们又不能把语言纯粹的分成解释型和编译型这两种。
用Java来举例,Java首先是通过编译器编译成字节码文件,然后在运行时通过解释器给解释成机器文件。所以我们说Java是一种先编译后解释的语言。
再换成C#,C#首相是通过编译器将C#文件编译成IL文件,然后在通过CLR将IL文件编译成机器文件。所以我们说C#是一门纯编译语言,但是C#是一门需要二次编译的语言。同理也可以等效运用到基于.NET平台上的 其他语言。
Python到底属于哪一种类型?
其实Python和Java/C#一样,也是一门基于虚拟机的语言,我们先来从表面上简单的了解一下Python程序的运行过程吧。
当我们在命令行中输入python hello.py时,其实是激活了Python的“解释器”,告诉“解释器”:你要开始工作了。可是在“解释”之前,其实执行的第一项工作和Java一样,是编译。
熟悉Java的同学可以想象一下我们在命令行中如何执行一个Java的程序:
javac hello.java
java hello
只是我们在用eclipse之类的IDE时,将这两步给融合成了一步而已。其实Python也是一样的,当我们执行python hello.py时,它也一样执行了这么一个过程,所以我们应该这样来描述Python,Python是一门先编译后解释的语言。
简述Python中程序的运行过程
在说这个问题之前,我们先来说两个概念,PyCodeObject和pyc文件。
我们在硬盘上看到的pyc自然不必多说,而其实PyCodeObject则是Python编译器真正编译成的结果。我们先简单知道就可以了,继续向下看。
当Python程序运行时,编译的结果则是保存在位于内存中的PyCodeObject中,当Python程序运行结束时,Python解释器则将PyCodeObject写回到pyc文件中。
当Python程序第二次运行时,首先程序会在硬盘中寻找对应的pyc文件,如果找到,则直接载入,否则就重复上面的过程。
所以我们应该这样来定位PyCodeObject和pyc文件:pyc文件其实是PyCodeObject的一种持久化保存方式。
我们先来简单看两个例子
写一段简单的程序运行一下:
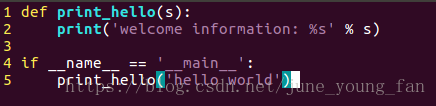
运行结果:
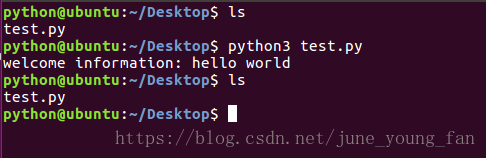
我们发现在运行完test.py这个程序后,当前路径下并没有生成相应的pyc文件。那是为什么呢?
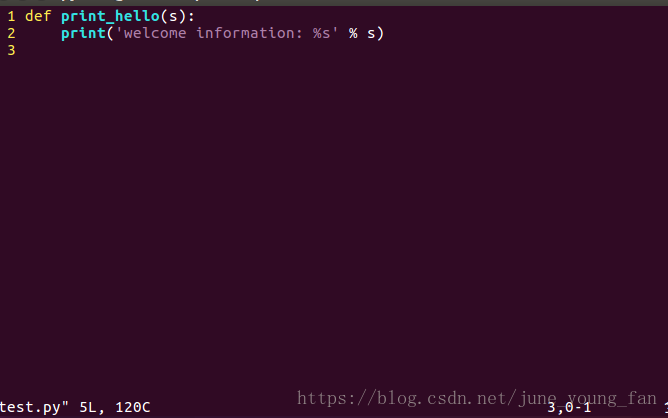
我们再来做一个小测试,将test.py当做模块导入到test888.py文件中,然后在这个程序中运行print_hello这个程序:
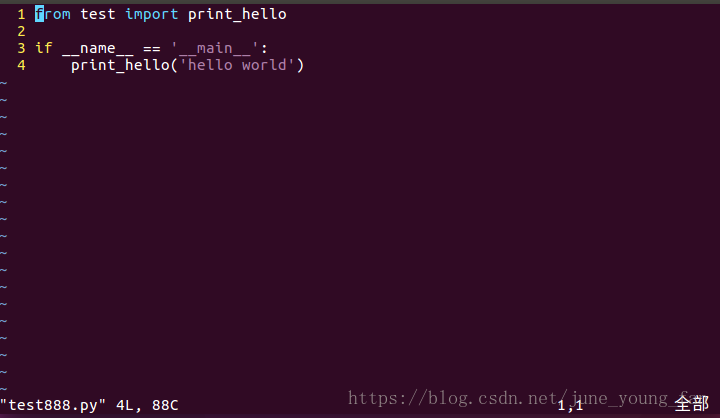
然后运行程序:
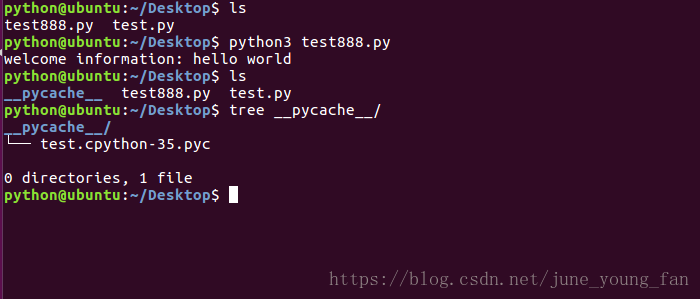
我们可以发现运行完test888.py文件后在当前路径下出现了一个名叫__pycache__的文件夹,里面包含了一个pyc文件,下面我们来分析一下这个过程到底发生了什么。
pyc文件的目的
回想上面我们在分析编译型语言和解释型语言的优缺点时,编译型语言的优点在于,我们可以在程序运行时不用解释,而直接利用已经翻译过的文件。也就是说,我们之所以要把py文件编译成pyc文件,最大的优点在于我们在运行程序时,不需要重新对该模块进行再次解释。
所以,需要编译成pyc文件的应该是那些可以重用的模块,这于我们在设计类时是一样的目的。所以Python的解释器认为:只有import进来的模块,才是需要被重用的模块。
这个时候也许有人会有疑问,我的test.py不是也需要运行吗,虽然不是一个模块,但是以后我每次运行也可以节省时间啊!
OK,我们从实际情况出发,思考一下我们在什么时候才可能运行python xxx.py文件:
1. 执行测试时;
2. 开启一个Web进程时;
3. 执行一个脚本时。
我们来逐条分析,第一种情况就不多说了,这个时候哪怕所有的文件都没有pyc文件都是无所谓的。
第二种情况,试想一个web.py的程序,通常是这样执行的:
然后这个程序就类似于一个守护进程一样一直监视着8000端口,而一旦中断,只可能是程序被杀死或者其他的意外情况,那么你要做的是把整个Web服务重启,那么既然一直监视着,把PyCodeObject一直放在内存中就足够了,完全没有必要持久化到硬盘上。
再来看看最后一个情况,执行一个程序脚本,一个程序的主入口其实很类似于Web程序中的Controller,也就是说,他负责的应该是Model之间的调度,而不包含任何的主逻辑在内,只是负责把参数转来转去而已,那么如果做算法的同学可以知道,在一段算法脚本中,最容易改变的就是算法的各个参数,那么这个时候将它持久化成pyc文件就未免有些画蛇添足了。
所以我们可以这样理解Python解释器的意图,Python解释器只是把我们可能重用到的模块持久化成pyc文件。
pyc文件的过期时间
说完了pyc文件,可能有人会想到,每次Python解释器都把模块给持久化成pyc文件,那么当我的模块发生改变的时候,是不是都要手动的把之前的pyc文件remove掉呢?
当然Python的设计者是不会犯这样的错误的,这个过程其实取决于PyCodeObject是如何写入pyc文件中的。
我们仔细看一下Import模块的源码其实不难发现,它在写入pyc文件的时候,写了一个Long型变量,变量的内容则是文件的最近修改日期,同理,在pyc文件中,每次在载入之前都会检查一下py文件和pyc文件保存的最后修改日期,如果不一致则重新生成新的pyc文件。
总结
其实了解Python程序的执行过程对于大部分程序员来说意义都是不大的,那么真正有意义的是,我们可以从Python解释器的做法上学到一些处理问题的方式和方法:
在Python中判断是否生成pyc文件和我们在设计缓存系统时是一样的,我们可以仔细想想,到底什么是值得扔在缓存里面的,什么是不值得的。
在运行一个耗时的Python脚本时,我们如何能够做到稍微压榨一些程序的运行时间呢?就是将模块从主模块分开。(虽然往往这都不是瓶颈)
在设计一个软件系统时,重用和非重用的东西是不是也可以分开来对待,这是软件设计原则的重要部分。
在设计缓存系统(或者其他系统)时,我们如何来避免程序的过期,其实Python解释器为我们提供了一个特别常见而且有效的解决方案。

