

浅谈分布式事务
前言应用场景
事务必须满足传统事务的特性,即原子性,一致性,分离性和持久性。但是分布式事务处理过程中,
某些场地比如在电商系统中,当有用户下单后,除了在订单表插入一条记录外,对应商品表的这个商品数量必须减1吧,怎么保证?
在搜索广告系统中,当用户点击某广告后,除了在点击事件表中增加一条记录外,
还得去商家账户表中找到这个商家并扣除广告费吧,怎么保证?
一 本地事务
以用户A转账用户B为例,假设有
用户A账户表:A(id,userId,amount)
用户B账户表:B(id,userId,amount)
用户的userId=1;
从用户A转账1万块钱到用户B的动作分为两步:
1)用户A表扣除1万:update A set amount=amount-10000 where userId=1;
2)用户B表增加1万:update B set amount=amount+10000 where userId=1;
如何确保用户A用户B收支平衡呢?有人说这个很简单嘛,可以用事务解决。
Begin transaction update A set amount=amount-10000 where userId=1 update B set amount=amount+10000 where userId=1 End transaction commit;
|
1
2
3
4
5
|
@Transactional(rollbackFor=Exception.class)public void update() {updateATable(); //更新A表updateBTable(); //更新B表} |
如果系统规模较小,数据表都在一个数据库实例上,上述本地事务方式可以很好地运行,但是如果系统规模较大,
比如用户A账户表和用户B账户表显然不会在同一个数据库实例上,他们往往分布在不同的物理节点上,这时本地事务已经失去用武之地。
既然本地事务失效,分布式事务自然就登上舞台。
二 XA
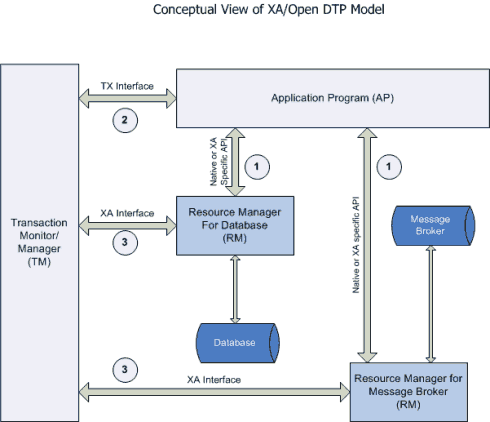
XA是由X/Open组织提出的分布式事务的规范。XA规范主要 定义了(全局)事务管理器(Transaction Manager)和(局部)资源管理器(Resource Manager)之间的接口。
XA接口是双向的系统接口,在事务管理器(Transaction Manager)以及一个或多个资源管理器(Resource Manager)之间形成通信桥梁。
XA之所以需要引入事务管理器是因为,在分布式系统中,从理论上讲(参考Fischer等的论文),两台机器理论上无 法达到一致的状态,需要引入一个单点进行协调。
事务管理器控制着全局事务,管理事务生命周期,并协调资源。资源管理器负责控制和管理实际资源(如数据库或 JMS队列)。
下图说明了事务管理器、资源管理器,与应用程序之间的关系:
三 两阶段提交协议
分布式事务必须满足传统事务的特性,即原子性,一致性,分离性和持久性。但是分布式事务处理过程中,某些场地(Server)可能发生故障,
或 者由于网络发生故障而无法访问到某些场地。为了防止分布式系统部分失败时产生数据的不一致性。
在分布式事务的控制中采用了两阶段提交协议(Two- Phase Commit Protocol)。即事务的提交分为两个阶段:
预提交阶段(Pre-Commit Phase)
决策后阶段(Post-Decision Phase)
两阶段提交用来协调参与一个更新中的多个服务器的活动,以防止分布式系统部分失败时产生数据的不一致性。例如,如果一个更新操作要求位于三个不同结点上的记录被改变,且其中只要有一个结点失败,另外两个结点必须检测到这个失败并取消它们所做的改变。
为了支持两阶段提交,一个分布式更新事务中涉及到的服务器必须能够相互通信。一般来说一个服务器会被指定为"控制"或"提交"服务器并监控来自其它服务器的信息。
在分布式更新期间,各服务器首先标志它们已经完成(但未提交)指定给它们的分布式事务的那一部分,并准备提交(以使它们的更新部分成为永久性的)。这是 两阶段提交的第一阶段。如果有一结点不能响应,那么控制服务器要指示其它结点撤消分布式事务的各个部分的影响。如果所有结点都回答准备好提交,控制服务器 则指示它们提交并等待它们的响应。等待确认信息阶段是第二阶段。
在接收到可以提交指示后,每个服务器提交分布式事务中属于自己的那一部分,并给控制服务器 发回提交完成信息。
在一个分布式事务中,必须有一个场地的Server作为协调者(coordinator),它能向 其它场地的Server发出请求,并对它们的回答作出响应,由它来控制一个分布式事务的提交或撤消。该分布式事务中涉及到的其它场地的Server称为参 与者(Participant)。
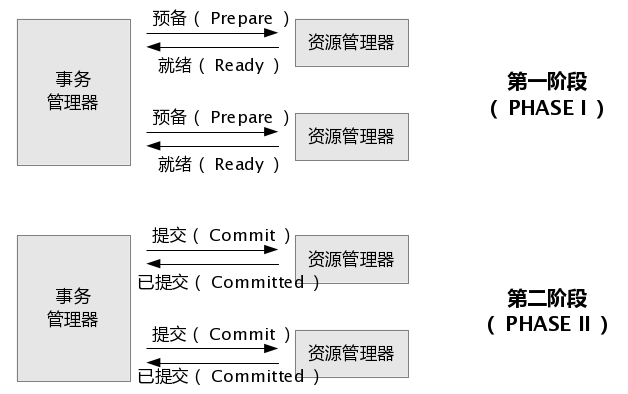
事务两阶段提交的过程如下:
● 两阶段提交在应用程序向协调者发出一个提交命令时被启动。这时提交进入第一阶段,即预提交阶段。在这一阶段中:
(1) 协调者准备局部(即在本地)提交并在日志中写入"预提交"日志项,并包含有该事务的所有参与者的名字。
(2) 协调者询问参与者能否提交该事务。一个参与者可能由于多种原因不能提交。例如,该Server提供的约束条件(Constraints)的延迟检查不符合 限制条件时,不能提交;参与者本身的Server进程或硬件发生故障,不能提交;或者协调者访问不到某参与者(网络故障),这时协调者都认为是收到了一个 否定的回答。
(3) 如果参与者能够提交,则在其本身的日志中写入"准备提交"日志项,该日志项立即写入硬盘,然后给协调者发回,已准备好提交"的回答。
(4) 协调者等待所有参与者的回答,如果有参与者发回否定的回答,则协调者撤消该事务并给所有参与者发出一个"撤消该事务"的消息,结束该分布式事务,撤消该事务的所有影响。
● 如果所有的参与者都送回"已准备好提交"的消息,则该事务的提交进入第二阶段,即决策后提交阶段。在这一阶段中:
(1) 协调者在日志中写入"提交"日志项,并立即写入硬盘。
(2) 协调者向参与者发出"提交该事务"的命令。各参与者接到该命令后,在各自的日志中写入"提交"日志项,并立即写入硬盘。然后送回"已提交"的消息,释放该事务占用的资源。
(3) 当所有的参与者都送回"已提交"的消息后,协调者在日志中写入"事务提交完成"日志项,释放协调者占用的资源 。这样,完成了该分布式事务的提交。
现如今实现基于两阶段提交的分布式事务也没那么困难了,如果使用java,那么可以使用开源软件atomikos来快速实现。
缺点
不过但凡使用过的上述两阶段提交的同学都可以发现性能实在是太差,根本不适合高并发的系统。为什么?
1)两阶段提交涉及多次节点间的网络通信,通信时间太长!
2)事务时间相对于变长了,锁定的资源的时间也变长了,造成资源等待时间也增加好多。
四 使用消息队列来避免分布式事务
如果仔细观察生活的话,生活的很多场景已经给了我们提示。
比如在北京很有名的姚记炒肝点了炒肝并付了钱后,他们并不会直接把你点的炒肝给你,往往是给你一张小票,然后让你拿着小票到出货区排队去取。
为什么他们要将付钱和取货两个动作分开呢?原因很多,其中一个很重要的原因是为了使他们接待能力增强(并发量更高)。
还是回到我们的问题,只要这张小票在,你最终是能拿到炒肝的。同理转账服务也是如此,当用户A账户扣除1万后,
我们只要生成一个凭证(消息)即可,这个凭证(消息)上写着“让用户B账户增加 1万”,只要这个凭证(消息)能可靠保存,
我们最终是可以拿着这个凭证(消息)让用户B账户增加1万的,即我们能依靠这个凭证(消息)完成最终一致性。
4.1 如何可靠保存凭证(消息)
有两种方法:
4.1.1 业务与消息耦合的方式
用户A在完成扣款的同时,同时记录消息数据,这个消息数据与业务数据保存在同一数据库实例里(消息记录表表名为message);
|
1
2
3
4
5
|
<span style="color: #000000;">Begin transactionupdate A set amount</span>=amount-10000 where userId=1<span style="color: #000000;">;insert into message(userId, amount,status) values(</span>1, 10000, 1<span style="color: #000000;">);End transactioncommit;</span> |
上述事务能保证只要用户A账户里被扣了钱,消息一定能保存下来。
当上述事务提交成功后,我们通过实时消息服务将此消息通知用户B,用户B处理成功后发送回复成功消息,用户A收到回复后删除该条消息数据。
4.1.2 业务与消息解耦方式
上述保存消息的方式使得消息数据和业务数据紧耦合在一起,从架构上看不够优雅,而且容易诱发其他问题。为了解耦,可以采用以下方式。
1)用户A在扣款事务提交之前,向实时消息服务请求发送消息,实时消息服务只记录消息数据,而不真正发送,只有消息发送成功后才会提交事务;
2)当用户A扣款事务被提交成功后,向实时消息服务确认发送。只有在得到确认发送指令后,实时消息服务才真正发送该消息;
3)当用户A扣款事务提交失败回滚后,向实时消息服务取消发送。在得到取消发送指令后,该消息将不会被发送;
4)对于那些未确认的消息或者取消的消息,需要有一个消息状态确认系统定时去用户A系统查询这个消息的状态并进行更新。为什么需要这一步骤,
举个例子:假设在第2步用户A扣款事务被成功提交后,系统挂了,此时消息状态并未被更新为“确认发送”,从而导致消息不能被发送。
优点:消息数据独立存储,降低业务系统与消息系统间的耦合;
缺点:一次消息发送需要两次请求;业务处理服务需要实现消息状态回查接口。
4.2 如何解决消息重复投递的问题
还有一个很严重的问题就是消息重复投递,以我们用户A转账到用户B为例,如果相同的消息被重复投递两次,那么我们用户B账户将会增加2万而不是1万了。
为什么相同的消息会被重复投递?比如用户B处理完消息msg后,发送了处理成功的消息给用户A,正常情况下用户A应该要删除消息msg,但如果用户A这时候悲剧的挂了,
重启后一看消息msg还在,就会继续发送消息msg。
解决方法很简单,在用户B这边增加消息应用状态表(message_apply),通俗来说就是个账本,用于记录消息的消费情况,每次来一个消息,
在真正执行之前,先去消息应用状态表中查询一遍,如果找到说明是重复消息,丢弃即可,如果没找到才执行,同时插入到消息应用状态表(同一事务)。
|
1
2
3
4
5
6
7
8
|
for each msg in queueBegin transactionselect count(*) as cnt from message_apply where msg_id=msg.msg_id;if cnt==0 thenupdate B set amount=amount+10000 where userId=1;insert into message_apply(msg_id) values(msg.msg_id);End transactioncommit; |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号