第9章:MySQL之高级SQL语法
第9章:MySQL之高级SQL语法
修订日期:2021-08-13
一. 子查询
子查询就是指在一个select语句中嵌套另一个select语句。同时,子查询必须包含括号。
MySQL 5.6.x版本之前,MySQL的子查询性能较差,但是从5.6开始,不存在性能差的问题。
select a from t1 where a > any(select a from t2);
select a from t1是外部查询(outer query)(select a from t2)是子查询(subquery)
一般说来,子查询嵌套于外部查询中,可以将两个或两个以上的子查询进行嵌套
1. 子查询的使用
1.1. ANY / SOME
如果外部查询的列的结果和子查询的列的结果比较得到为True的话,则返回比较值为True的外查询的记录
(gcdb@localhost) 17:37:05 [mytest]> select * from t1;
+------+
| a |
+------+
| 1 |
| 3 |
| 4 |
| 5 |
| 7 |
+------+
5 rows in set (0.00 sec)
(gcdb@localhost) 17:37:22 [mytest]> select * from t2;
+------+
| a |
+------+
| 2 |
| 4 |
| 8 |
| 10 |
+------+
4 rows in set (0.00 sec)
(gcdb@localhost) 17:39:33 [mytest]> select a from t1 where a > any(select a from t2);
+------+
| a |
+------+
| 3 |
| 4 |
| 5 |
| 7 |
+------+
4 rows in set (0.00 sec)
-- 这个查询可以解释为,t1表内a列的值大于t2表中a列的`任意(any)`一个值`t1.a > any(t2.a) == true`,则返回t1.a的记录
ANY关键词必须与一个比较操作符一起使用:=,>,<,>=,<=,<>(这个是!=的意思)
子查询中
SOME和ANY是同一个意思
1.2. IN
in是ANY的一种特殊情况:"in" equals "= any"
(gcdb@localhost) 17:58:21 [mytest]> select a from t1 where a = any(select a from t2); -- t1.a==t2.a 的只有4
+------+
| a |
+------+
| 4 |
+------+
1 row in set (0.00 sec)
(gcdb@localhost) 17:57:01 [mytest]> select a from t1 where a in (select a from t2); -- in的结果等同于 =any 的结果
+------+
| a |
+------+
| 4 |
+------+
1 row in set (0.00 sec)
select a from s1 where a in (select a in t2);是用的比较多的一种语法
1.3. ALL
如果外部查询的列的结果和子查询的列的所有结果比较得到为True的话,则返回比较值为True的(外查询)的记录
(gcdb@localhost) 17:55:03 [mytest]> select a from t2 where a >all(select a from t1);
+------+
| a |
+------+
| 8 |
| 10 |
+------+
2 rows in set (0.00 sec)
ALL关键词必须与一个比较操作符一起使用
NOT IN是<> ALL的别名
2. 子查询的分类
-
独立子查询
- 不依赖外部查询而运行的子查询
(gcdb@localhost) 18:00:04 [mytest]> select a from t1 where a in (1,2,3,4,5); +------+ | a | +------+ | 1 | | 3 | | 4 | | 5 | +------+ 4 rows in set (0.00 sec) -
相关子查询
- 引用了外部查询列的子查询
-- 在这个例子中,子查询中使用到了外部的列t2.a (gcdb@localhost) 18:00:48 [mytest]> select a from t1 where a in (select * from t2 where t1.a = t2.a); +------+ | a | +------+ | 4 | +------+ 1 row in set (0.00 sec)
3. 子查询的优化
-
MySQL5.6之前
- 在
MySQL5.6之前,优化器会把子查询重写成exists的形式
select a from t1 where a in (select a from t2); -- 这个是一条独立的子查询,时间复杂度 O(M+N) -- -- 经过优化器重写后 -- select a from t1 where exists (select 1 from t2 where t1.a = t2.a); -- 这是相关子查询,复杂度O(M*N + M)- 在
MySQL 5.6之前,部分的子查询需要重写成join的形式 (注意表的大小)
mysql> select t1.a from t1 join t2 on t1.a = t2.a; +------+ | a | +------+ | 4 | +------+ 1 row in set (0.00 sec) - 在
-
MySQL 5.6之后
在MySQL 5.6之后,优化器不会将子查询重写成exists的形式,而是自动优化,性能有了大幅提升
4. 包含NULL值的NOT IN
mysql> select null in ('a', 'b', null);
+--------------------------+
| null in ('a', 'b', null) |
+--------------------------+
| NULL |
+--------------------------+
1 row in set (0.00 sec)
MySQL数据库的
比较操作,除了返回1(True),0(False)之外,还会返回NULL
NULL和NULL的比较,返回的还是NULL
mysql> select null not in ('a', 'b', null);
+------------------------------+
| null not in ('a', 'b', null) |
+------------------------------+
| NULL | -- null不在('a', 'b', null)中,返回的还是null,因为有null和null的比较
+------------------------------+
1 row in set (0.00 sec)
mysql> select 'a' not in ('a', 'b', null);
+-----------------------------+
| 'a' not in ('a', 'b', null) |
+-----------------------------+
| 0 | -- a 不在 ('a', 'b', null)中,返回0,即False
+-----------------------------+
1 row in set (0.00 sec)
mysql> select 'c' not in ('a', 'b');
+-----------------------+
| 'c' not in ('a', 'b') |
+-----------------------+
| 1 | -- 这个返回值可以理解 'c'不在('a', 'b')中,返回1,即为True
+-----------------------+
1 row in set (0.00 sec)
mysql> select 'c' not in ('a', 'b', null);
+-----------------------------+
| 'c' not in ('a', 'b', null) |
+-----------------------------+
| NULL | -- 理论上应该是返回1,即True的。但是包含了null值。则返回null
+-----------------------------+
1 row in set (0.00 sec)
对于包含了
NULL值的IN操作,总是返回True或者NULL
NOT IN返回NOT True (False)或者NOT NULL (NULL)
--
-- SQL语句一 使用 EXISTS
--
select customerid, companyname
from customers as A
where country = 'Spain'
and not exists
( select * from orders as B
where A.customerid = B.customerid );
--
-- SQL语句二 使用 IN
--
select customerid, companyname
from customers as A
where country = 'Spain'
and customerid not in (select customerid from orders);
-----
-- 当结果集合中没有NULL值时,上述两条SQL语句查询的结果是一致的
-----
--
-- 插入一个NULL值
--
insert into orders(orderid) values (null);
-----
-- SQL语句1 : 返回和之前一致
-- SQL语句2 : 返回为空表,因为子查询返回的结果集中存在NULL值。not in null 永远返回False或者NULL
-- 此时 where (country = 'Spain' and (False or NULL)) 为 False OR NULL,条件永远不匹配
-----
--
-- SQL语句2 改写后
--
select customerid, companyname
from customers as A
where country = 'Spain'
and customerid not in (select customerid from orders
where customerid is not null); -- 增加这个过滤条件,使用is not,而不是<>
--
-- 和 null比较,使用is和is not, 而不是 = 和 <>
--
mysql> select null = null;
+-------------+
| null = null |
+-------------+
| NULL |
+-------------+
1 row in set (0.00 sec)
mysql> select null <> null;
+--------------+
| null <> null |
+--------------+
| NULL |
+--------------+
1 row in set (0.00 sec)
mysql> select null is null;
+--------------+
| null is null |
+--------------+
| 1 | -- 返回 True
+--------------+
1 row in set (0.00 sec)
mysql> select null is not null;
+-------------------+
| null is not null |
+-------------------+
| 0 | -- 返回 False
+-------------------+
1 row in set (0.00 sec)
EXISTS不管返回值是什么,而是看是否有行返回,所以EXISTS中子查询都是select *、select 1等,因为只关心返回是否有行(结果集)
二. INSERT
(gcdb@localhost) 10:46:17 [mytest]> select * from t1;
+------+
| a |
+------+
| 1 |
| 3 |
| 4 |
| 5 |
| 7 |
+------+
5 rows in set (0.00 sec)
(gcdb@localhost) 10:46:36 [mytest]> insert into t1 values(9); -- 插入一个值
Query OK, 1 row affected (0.01 sec)
(gcdb@localhost) 10:46:44 [mytest]> insert into t1(a) values(9),(11); -- 插入多个值,MySQL独有
Query OK, 2 rows affected (0.00 sec)
Records: 2 Duplicates: 0 Warnings: 0
(gcdb@localhost) 10:47:11 [mytest]> insert into t1(a) select 13; -- insert XXX select XXX 语法,MySQ独有
Query OK, 1 row affected (0.00 sec)
Records: 1 Duplicates: 0 Warnings: 0
(gcdb@localhost) 10:53:34 [mytest]> select * from t1;
+------+
| a |
+------+
| 1 |
| 3 |
| 4 |
| 5 |
| 7 |
| 9 |
| 11 |
| 13 |
+------+
8 rows in set (0.00 sec)
(gcdb@localhost) 10:46:52 [mytest]> create table t3(a int, b int); -- 有多个列
Query OK, 0 rows affected (0.15 sec)
(gcdb@localhost) 10:47:24 [mytest]> insert into t3 select 12; -- 没有指定列,报错
ERROR 1136 (21S01): Column count doesn't match value count at row 1
(gcdb@localhost) 10:47:48 [mytest]> insert into t3(a) select 12; -- 指定列a
Query OK, 1 row affected (0.00 sec)
Records: 1 Duplicates: 0 Warnings: 0
(gcdb@localhost) 10:48:08 [mytest]> insert into t3(a,b) select 11,12; -- 不指定列,但是插入值匹配列的个数和类型
Query OK, 1 row affected (0.00 sec)
Records: 1 Duplicates: 0 Warnings: 0
(gcdb@localhost) 10:48:21 [mytest]> select * from t3;
+------+------+
| a | b |
+------+------+
| 12 | NULL |
| 11 | 12 |
+------+------+
2 rows in set (0.00 sec)
(gcdb@localhost) 10:49:19 [mytest]> insert into t3 select * from t3; -- 从t3表中查询数据并插回t3中
Query OK, 2 rows affected (0.00 sec)
Records: 2 Duplicates: 0 Warnings: 0
(gcdb@localhost) 10:55:49 [mytest]> insert into t3(a) select a from t2; -- 从t2表中查询数据并插入到t3(a)中,注意指定列
Query OK, 4 rows affected (0.00 sec)
Records: 4 Duplicates: 0 Warnings: 0
(gcdb@localhost) 10:59:02 [mytest]> select * from t3;
+------+------+
| a | b |
+------+------+
| 12 | NULL |
| 11 | 12 |
| 12 | NULL |
| 11 | 12 |
| 2 | NULL |
| 4 | NULL |
| 8 | NULL |
| 10 | NULL |
+------+------+
8 rows in set (0.00 sec)
--
-- 如果想快速增长表格中的数据,可以使用如下方法,使得数据成倍增长
--
mysql> insert into t3 select * from t3;
Query OK, 5 rows affected (0.03 sec) -- 插入了5列
Records: 5 Duplicates: 0 Warnings: 0
mysql> select * from t3;
+------+------+
| a | b |
+------+------+
| 8 | NULL |
| 8 | 9 |
| NULL | 5 |
| NULL | 4 |
| NULL | 3 |
| 8 | NULL |
| 8 | 9 |
| NULL | 5 |
| NULL | 4 |
| NULL | 3 |
+------+------+
10 rows in set (0.00 sec)
三. DELETE
(gcdb@localhost) 11:02:10 [mytest]> delete from t3 where b is null; -- 根据过滤条件删除
Query OK, 6 rows affected (0.00 sec)
(gcdb@localhost) 11:02:16 [mytest]> select * from t3;
+------+------+
| a | b |
+------+------+
| 11 | 12 |
| 11 | 12 |
+------+------+
2 rows in set (0.00 sec)
(gcdb@localhost) 11:02:48 [mytest]> delete from t3; -- 删除整个表
Query OK, 2 rows affected (0.00 sec)
(gcdb@localhost) 11:03:17 [mytest]> select * from t3;
Empty set (0.00 sec)
四. UPDATE
(gcdb@localhost) 11:03:19 [mytest]> insert into t3 select 1,2;
Query OK, 1 row affected (0.00 sec)
Records: 1 Duplicates: 0 Warnings: 0
(gcdb@localhost) 11:03:54 [mytest]> insert into t3 select 2,3;
Query OK, 1 row affected (0.00 sec)
Records: 1 Duplicates: 0 Warnings: 0
(gcdb@localhost) 11:03:58 [mytest]> insert into t3 select 3,4;
Query OK, 1 row affected (0.00 sec)
Records: 1 Duplicates: 0 Warnings: 0
(gcdb@localhost) 11:04:02 [mytest]> select * from t3;
+------+------+
| a | b |
+------+------+
| 1 | 2 |
| 2 | 3 |
| 3 | 4 |
+------+------+
3 rows in set (0.00 sec)
(gcdb@localhost) 11:04:30 [mytest]> update t3 set a =10 where a=1;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
(gcdb@localhost) 11:05:02 [mytest]> select * from t3;
+------+------+
| a | b |
+------+------+
| 10 | 2 |
| 2 | 3 |
| 3 | 4 |
+------+------+
3 rows in set (0.00 sec)
--
-- 关联后更新
--
(gcdb@localhost) 11:05:07 [mytest]> select * from t2;
+------+
| a |
+------+
| 2 | --和t3中的a列2相等
| 4 |
| 8 |
| 10 | --和t3中的a列10相等
+------+
4 rows in set (0.00 sec)
(gcdb@localhost) 11:06:05 [mytest]> select * from t3;
+------+------+
| a | b |
+------+------+
| 10 | 2 | -- 和t2中的10相等
| 2 | 3 | -- 和t2中的2相等
| 3 | 4 |
+------+------+
3 rows in set (0.00 sec)
(gcdb@localhost) 11:08:08 [mytest]> update t2 join t3 on t2.a = t3.a set t2.a=1000; -- 先得到t2.a=t3.a的结果然后将结果集中的t2.a设置为100
Query OK, 2 rows affected (0.00 sec)
Rows matched: 2 Changed: 2 Warnings: 0
(gcdb@localhost) 11:08:16 [mytest]> select * from t2;
+------+
| a |
+------+
| 1000 | -- 该行原先2被更新成100
| 4 |
| 8 |
| 1000 | -- 该行原先10被更新成100
+------+
4 rows in set (0.01 sec)
五. REPLACE
(gcdb@localhost) 11:18:41 [mytest]> create table t4(a int primary key auto_increment,b int);
Query OK, 0 rows affected (0.01 sec)
(gcdb@localhost) 11:18:47 [mytest]> insert into t4 values(null,1);
Query OK, 1 row affected (0.00 sec)
(gcdb@localhost) 11:19:17 [mytest]> insert into t4 values(null,2);
Query OK, 1 row affected (0.00 sec)
(gcdb@localhost) 11:19:19 [mytest]> insert into t4 values(null,3);
Query OK, 1 row affected (0.00 sec)
(gcdb@localhost) 11:19:22 [mytest]> select * from t4;
+---+------+
| a | b |
+---+------+
| 1 | 1 |
| 2 | 2 |
| 3 | 3 |
+---+------+
3 rows in set (0.00 sec)
(gcdb@localhost) 11:20:01 [mytest]> insert into t4 values(1,10); -- error,主键值1,重复
ERROR 1062 (23000): Duplicate entry '1' for key 'PRIMARY'
(gcdb@localhost) 11:20:28 [mytest]> replace into t4 values(1,10); -- 替换该主键对应的值
Query OK, 2 rows affected (0.00 sec) -- 两行记录受到影响
(gcdb@localhost) 11:20:54 [mytest]> select * from t4;
+---+------+
| a | b |
+---+------+
| 1 | 10 | -- 已经被更新
| 2 | 2 |
| 3 | 3 |
+---+------+
3 rows in set (0.00 sec)
-----
-- replace的原理是:先delete,在insert ;注意:需要delete和insert权限
-----
(gcdb@localhost) 11:24:23 [mytest]> replace into t4 values(5,15); -- 没有替换对象时,类似插入效果
Query OK, 1 row affected (0.03 sec) -- 只影响1行
(gcdb@localhost) 11:24:32 [mytest]> select * from t4;
+---+------+
| a | b |
+---+------+
| 1 | 10 |
| 2 | 2 |
| 3 | 3 |
| 5 | 15 | -- 新插入一行
+---+------+
4 rows in set (0.00 sec)
--
-- replace原理更明显的例子
--
(gcdb@localhost) 11:24:35 [mytest]> create table t6
-> (a int primary key,
-> b int auto_increment, -- b是auto_increment的int型数据
-> c int,key(b));
Query OK, 0 rows affected (0.01 sec)
(gcdb@localhost) 11:26:54 [mytest]> insert into t6 values(1,null,10),(2,null,20),(3,null,30);
Query OK, 3 rows affected (0.00 sec)
Records: 3 Duplicates: 0 Warnings: 0
(gcdb@localhost) 11:28:08 [mytest]> select * from t6;
+---+---+------+
| a | b | c | --b类为自增列
+---+---+------+
| 1 | 1 | 10 |
| 2 | 2 | 20 |
| 3 | 3 | 30 |
+---+---+------+
3 rows in set (0.00 sec)
(gcdb@localhost) 11:29:14 [mytest]> replace into t6 values(1,null,99);
Query OK, 2 rows affected (0.00 sec)
(gcdb@localhost) 11:29:40 [mytest]> select * from t6;
+---+---+------+
| a | b | c |
+---+---+------+
| 1 | 4 | 99 | --当a=1时,c列值10被替换为99和b列值3自增加1为4
| 2 | 2 | 20 |
| 3 | 3 | 30 |
+---+---+------+
3 rows in set (0.00 sec)
-----
--
-- insert on duplicate 效果和 replace类似
--
(gcdb@localhost) 11:29:50 [mytest]> select * from t4;
+---+------+
| a | b |
+---+------+
| 1 | 10 |
| 2 | 2 |
| 3 | 3 |
| 5 | 15 |
+---+------+
4 rows in set (0.00 sec)
(gcdb@localhost) 11:33:31 [mytest]> insert into t4 values(1,1); -- 插入报错,存在key为1的记录
ERROR 1062 (23000): Duplicate entry '1' for key 'PRIMARY'
(gcdb@localhost) 11:34:26 [mytest]> insert into t4 values(1,1) on duplicate key update b=1; -- 带上on duplicate参数(非SQL标准,不推荐)
Query OK, 2 rows affected (0.00 sec)
(gcdb@localhost) 11:34:31 [mytest]> select * from t4;
+---+------+
| a | b |
+---+------+
| 1 | 1 | - 该行的b列从10被替换成1
| 2 | 2 |
| 3 | 3 |
| 5 | 15 |
+---+------+
4 rows in set (0.00 sec)
--
-- insert ignore
--
(gcdb@localhost) 11:34:34 [mytest]> insert ignore into t4 values(1,1); -- 忽略重复的错误
Query OK, 0 rows affected, 1 warning (0.00 sec)
(gcdb@localhost) 11:36:37 [mytest]> show warnings;
+---------+------+---------------------------------------+
| Level | Code | Message |
+---------+------+---------------------------------------+
| Warning | 1062 | Duplicate entry '1' for key 'PRIMARY' |
+---------+------+---------------------------------------+
1 row in set (0.00 sec)
六. UNION
- UNION的作用是
将两个查询的结果集进行合并。 - UNION必须由
两条或两条以上的SELECT语句组成,语句之间用关键字UNION分隔。 - UNION中的每个查询必须包含相同的列(
类型相同或可以隐式转换)、表达式或聚集函数。
(gcdb@localhost) 11:14:02 [mytest]> create table t_union01(a int,b int);
Query OK, 0 rows affected (0.00 sec)
(gcdb@localhost) 11:14:31 [mytest]> create table t_union02(a int,b int);
Query OK, 0 rows affected (0.01 sec)
(gcdb@localhost) 11:15:41 [mytest]> insert into t_union01 values(1,2),(2,3),(3,4),(99,100);
Query OK, 4 rows affected (0.01 sec)
Records: 4 Duplicates: 0 Warnings: 0
(gcdb@localhost) 11:16:04 [mytest]> insert into t_union02 values(10,20),(20,30),(30,40),(99,100);
Query OK, 4 rows affected (0.00 sec)
Records: 4 Duplicates: 0 Warnings: 0
(gcdb@localhost) 11:16:26 [mytest]> select * from t_union01;
+------+------+
| a | b |
+------+------+
| 1 | 2 |
| 2 | 3 |
| 3 | 4 |
| 99 | 100 | --t_union01 中的99, 100
+------+------+
4 rows in set (0.00 sec)
(gcdb@localhost) 11:16:42 [mytest]> select * from t_union02;
+------+------+
| a | b |
+------+------+
| 10 | 20 |
| 20 | 30 |
| 30 | 40 |
| 99 | 100 | --t_union02 中的99, 100
+------+------+
4 rows in set (0.00 sec)
(gcdb@localhost) 11:22:16 [mytest]> select * from t_union02
-> union
-> select * from t_union01;
+------+------+
| a | b |
+------+------+
| 10 | 20 |
| 20 | 30 |
| 30 | 40 |
| 99 | 100 | -- 只出现了一次 99, 100,union会去重
| 1 | 2 |
| 2 | 3 |
| 3 | 4 |
+------+------+
7 rows in set (0.00 sec)
(gcdb@localhost) 11:22:35 [mytest]> select * from t_union02 union all select * from t_union01; -- 使用 union all 显示不去重
+------+------+
| a | b |
+------+------+
| 10 | 20 |
| 20 | 30 |
| 30 | 40 |
| 99 | 100 |
| 1 | 2 |
| 2 | 3 |
| 3 | 4 |
| 99 | 100 |
+------+------+
8 rows in set (0.00 sec)
如果知道数据本身具有唯一性,没有重复,则建议使用
union all,因为union会做去重操作,性能会比union all要低
七. 关联更新和行号查询
7.1. 关联更新
(gcdb@localhost) 11:38:36 [mytest]> create table t5 (a int, b int);
Query OK, 0 rows affected (0.14 sec)
(gcdb@localhost) 11:39:38 [mytest]> insert into t5 values(1,1);
Query OK, 1 row affected (0.03 sec)
(gcdb@localhost) 11:39:49 [mytest]> select * from t5;
+------+------+
| a | b |
+------+------+
| 1 | 1 |
+------+------+
1 row in set (0.00 sec)
(gcdb@localhost) 11:39:51 [mytest]> update t5 set a= a+1,b=a where a=1;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
(gcdb@localhost) 11:40:03 [mytest]> select * from t5;
+------+------+
| a | b |
+------+------+
| 2 | 2 | -- SQL Server和Oracle中得到的值是2, 1
+------+------+
1 row in set (0.00 se
7.2. 显示行号(RowNumber)
--
-- 方法一
--
(gcdb@localhost) 11:41:08 [mytest]> use employees;
Database changed
(gcdb@localhost) 11:42:15 [employees]> set @rn:=0; -- 产生 SESSION(会话)级别的变量
Query OK, 0 rows affected (0.00 sec)
(gcdb@localhost) 11:42:21 [employees]> select @rn:=@rn+1 as rownumber, emp_no, gender from employees limit 10; -- @rn:=1 是赋值的意思
+-----------+--------+--------+
| rownumber | emp_no | gender |
+-----------+--------+--------+
| 1 | 10001 | M |
| 2 | 10002 | F |
| 3 | 10003 | M |
| 4 | 10004 | M |
| 5 | 10005 | M |
| 6 | 10006 | F |
| 7 | 10007 | F |
| 8 | 10008 | M |
| 9 | 10009 | F |
| 10 | 10010 | F |
+-----------+--------+--------+
10 rows in set (0.00 sec)
--
-- 方法二 (推荐)
--
(gcdb@localhost) 11:42:31 [employees]> select @rn1:=@rn1+1 as rownumber, emp_no, gender from employees, (select @rn1:=0) as a limit 10;
+-----------+--------+--------+
| rownumber | emp_no | gender |
+-----------+--------+--------+
| 1 | 10001 | M |
| 2 | 10002 | F |
| 3 | 10003 | M |
| 4 | 10004 | M |
| 5 | 10005 | M |
| 6 | 10006 | F |
| 7 | 10007 | F |
| 8 | 10008 | M |
| 9 | 10009 | F |
| 10 | 10010 | F |
+-----------+--------+--------+
10 rows in set (0.00 sec)
-- MySQL 自定义变量,根据每一记录进行变化的
(gcdb@localhost) 11:44:55 [employees]> select @rn1:=0;
+---------+
| @rn1:=0 |
+---------+
| 0 | -- 只有一行记录
+---------+
1 row in set (0.00 sec)
-- 相当于 把 employees 和 (select @rn1:=0)做了笛卡尔积,然后使用@rn1:=@rn + 1,根据每行进行累加
--
-- ":=" 和 "="
--
(gcdb@localhost) 11:42:15 [employees]> set @rn:=0; -- 赋值为0
Query OK, 0 rows affected (0.00 sec)
(gcdb@localhost) 11:44:55 [employees]> select @rn1:=0;
+---------+
| @rn1:=0 |
+---------+
| 0 |
+---------+
1 row in set (0.00 sec)
(gcdb@localhost) 11:46:37 [employees]> set @a:=100; -- 赋值为100
Query OK, 0 rows affected (0.00 sec)
(gcdb@localhost) 11:46:54 [employees]> select @a;
+------+
| @a |
+------+
| 100 |
+------+
1 row in set (0.00 sec)
(gcdb@localhost) 11:49:25 [employees]> select @a=99; -- 进行比较
+-------+
| @a=99 |
+-------+
| 0 |
+-------+
1 row in set (0.00 sec)
7.3. 使用子查询实现RowNumber
-
思路
- 假设当前在第N行记录,通过主键emp_no遍历有多少行的记录
小于等于当前行,即为当前行的行数.
- 假设当前在第N行记录,通过主键emp_no遍历有多少行的记录
-
SQL语句
(gcdb@localhost) 12:07:39 [employees]> SELECT (SELECT COUNT(1) FROM employees b WHERE b.emp_no <= a.emp_no ) AS row_number, emp_no,CONCAT(last_name," ",first_name) name,gender,hire_date FROM employees a ORDER BY emp_no LIMIT 10;
+------------+--------+--------------------+--------+------------+
| row_number | emp_no | name | gender | hire_date |
+------------+--------+--------------------+--------+------------+
| 1 | 10001 | Facello Georgi | M | 1986-06-26 |
| 2 | 10002 | Simmel Bezalel | F | 1985-11-21 |
| 3 | 10003 | Bamford Parto | M | 1986-08-28 |
| 4 | 10004 | Koblick Chirstian | M | 1986-12-01 |
| 5 | 10005 | Maliniak Kyoichi | M | 1989-09-12 |
| 6 | 10006 | Preusig Anneke | F | 1989-06-02 |
| 7 | 10007 | Zielinski Tzvetan | F | 1989-02-10 |
| 8 | 10008 | Kalloufi Saniya | M | 1994-09-15 |
| 9 | 10009 | Peac Sumant | F | 1985-02-18 |
| 10 | 10010 | Piveteau Duangkaew | F | 1989-08-24 |
+------------+--------+--------------------+--------+------------+
10 rows in set (0.59 sec)
-- 假设当前在第5行
(gcdb@localhost) 12:08:38 [employees]> select b.emp_no from employees.employees as b order by b.emp_no limit 5;
+--------+
| emp_no |
+--------+
| 10001 |
| 10002 |
| 10003 |
| 10004 |
| 10005 | -- 第5行的emp_no是10005
+--------+
5 rows in set (0.00 sec)
(gcdb@localhost) 12:10:28 [employees]> select count(*) from employees.employees as b where b.emp_no<= 10005 order by b.emp_no;
--查找小于等于5的行数有几行
+----------+
| count(*) |
+----------+
| 5 | -- 小于等于10005的记录有5行,则5就是10005该行记录的行号
+----------+
1 row in set (0.00 sec)
-- 将该子查询的结果即可作为RowNumber,子查询循环多次,不推荐使用。
-- 推荐使用下面这种方法
(gcdb@localhost) 12:12:01 [employees]> SELECT @a:=@a+1 AS row_number,emp_no,CONCAT(last_name," ",first_name) name,gender,hire_date FROM employees,(SELECT @a:=0) AS a LIMIT 10;
+------------+--------+--------------------+--------+------------+
| row_number | emp_no | name | gender | hire_date |
+------------+--------+--------------------+--------+------------+
| 1 | 10001 | Facello Georgi | M | 1986-06-26 |
| 2 | 10002 | Simmel Bezalel | F | 1985-11-21 |
| 3 | 10003 | Bamford Parto | M | 1986-08-28 |
| 4 | 10004 | Koblick Chirstian | M | 1986-12-01 |
| 5 | 10005 | Maliniak Kyoichi | M | 1989-09-12 |
| 6 | 10006 | Preusig Anneke | F | 1989-06-02 |
| 7 | 10007 | Zielinski Tzvetan | F | 1989-02-10 |
| 8 | 10008 | Kalloufi Saniya | M | 1994-09-15 |
| 9 | 10009 | Peac Sumant | F | 1985-02-18 |
| 10 | 10010 | Piveteau Duangkaew | F | 1989-08-24 |
+------------+--------+--------------------+--------+------------+
10 rows in set (0.00 sec)
3.查询employees表下基层用户的最近详细信息(员工号,员工名字,职位,部门,工资)
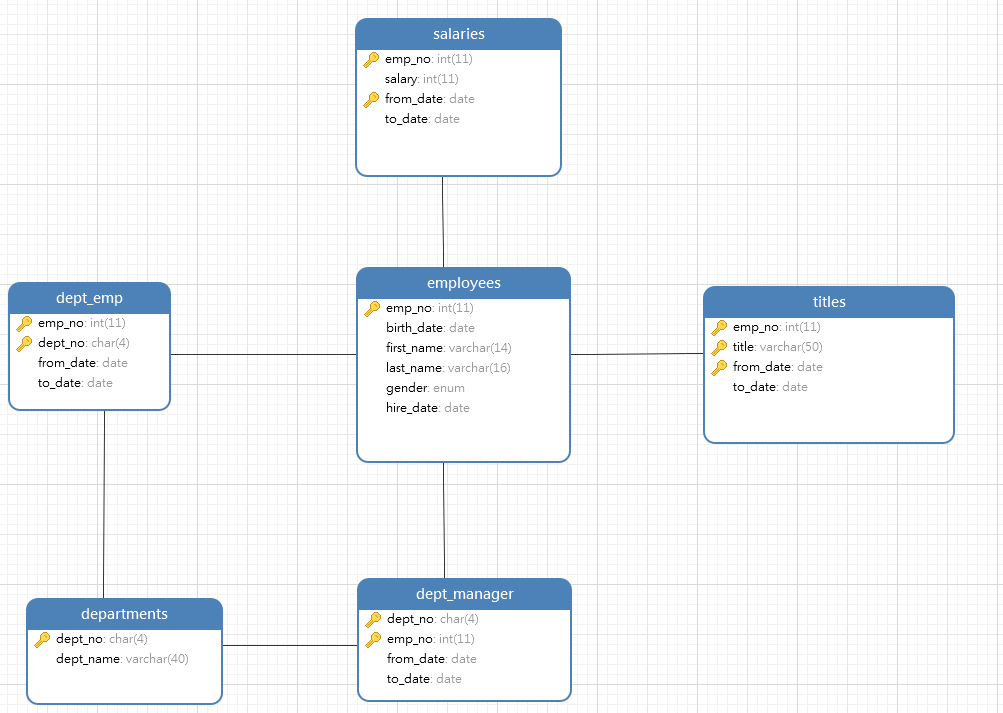
关于
Group By在《SQL必知必会》中提及的部分规定:
GROUP BY子句中列出的每一列都必须是检索列或有效的表达式(但不能是聚集函数),如果在SELECT中使用表达式,则必须在GROUP BY子句中指定相同的表达式不能使用别名。
除聚集计算语句外,SELECT语句中的每一列都必须在GROUP BY子句中给出。
SELECT
e.emp_no AS 员工号,
CONCAT(last_name, ' ', first_name) AS 姓名,
t.title AS 职位,
dp.dept_name AS 部门,
s.salary AS 工资
FROM
employees e
LEFT JOIN
dept_manager d ON e.emp_no = d.emp_no
LEFT JOIN
(SELECT
emp_no, title, from_date, to_date
FROM
titles
WHERE
(emp_no , from_date, to_date) IN (SELECT
emp_no, MAX(from_date), MAX(to_date)
FROM
titles AS b
GROUP BY b.emp_no)) t ON t.emp_no = e.emp_no
LEFT JOIN
(SELECT
dept_no, emp_no, from_date, to_date
FROM
dept_emp
WHERE
(emp_no , from_date, to_date) IN (SELECT
emp_no, MAX(from_date), MAX(to_date)
FROM
dept_emp AS b
GROUP BY b.emp_no)) de ON de.emp_no = e.emp_no
LEFT JOIN
(SELECT
emp_no, salary, from_date, to_date
FROM
salaries
WHERE
(emp_no , from_date, to_date) IN (SELECT
emp_no, MAX(from_date), MAX(to_date)
FROM
salaries AS b
GROUP BY b.emp_no)) s ON s.emp_no = e.emp_no
LEFT JOIN
departments dp ON dp.dept_no = de.dept_no
WHERE
d.emp_no IS NULL
LIMIT 10;
--
-- 改进的子查询语句 - 1
--
SELECT
emp_no, title, from_date, to_date
FROM
titles
WHERE
(emp_no , from_date, to_date) IN
(
SELECT
emp_no, MAX(from_date), MAX(to_date) -- 因为数据本身的问题,这里from_date和to_date都要
FROM
titles AS b
GROUP BY b.emp_no
) -- 这个子查询表示以emp_no分类,找到最大(最近)的from_date和to_date
-- 而where条件在这个最大的基础上,过滤出我们要的title。(salary同理)
--
-- 改进的子查询语句 - 2
--
SELECT
emp_no, title, from_date, to_date
FROM
titles AS a
WHERE
(from_date, to_date) = (SELECT
MAX(from_date), MAX(to_date) -- 同样使用from_date和to_date
FROM
titles AS b
WHERE
a.emp_no = b.emp_no -- 这个是一个关联子查询
GROUP BY b.emp_no);
八. 存储过程和函数
1.存储过程和函数介绍
存储过程和函数是在数据库中定义一些SQL语句的集合,然后直接调用这些存储过程和函数来执行已经定义好的SQL语句;- 用户可以通过
存储过程名和传参多次调用的程序模块; - 存储过程和函数的特点:
- 使用灵活,可以使用流控语句、自定义变量等
完成复杂的业务逻辑; - 提高数据安全性,屏蔽应用程序直接对表的操作,易于进行审计;
- 减少网络传输;
- 提高代码维护的复杂度,实际使用需要结合业务评估;
- 使用灵活,可以使用流控语句、自定义变量等
CREATE
[DEFINER = { user | CURRENT_USER }]
PROCEDURE sp_name ([proc_parameter[,...]])
[characteristic ...] routine_body
-
--sp_name参数是存储过程的名称;
--proc_parameter表示存储过程的参数列表;
--characteristic参数指定存储过程的特性;
--routine_body参数是SQL代码的内容,可以用BEGIN…END来标志SQL代码的开始和结束。
-
CREATE
[DEFINER = { user | CURRENT_USER }]
FUNCTION sp_name ([func_parameter[,...]])
RETURNS type
[characteristic ...] routine_body
-
--sp_name参数是存储函数的名称;
--func_parameter表示存储函数的参数列表;
--characteristic参数指定存储函数的特性;
--routine_body参数是SQL代码的内容,可以用BEGIN…END来标志SQL代码的开始和结束。
-
proc_parameter:
[ IN | OUT | INOUT ] param_name type
-
--IN表示输入参数;OUT表示输出参数; INOUT表示既可以是输入,也可以是输出; param_name参数是存储过程的参数名称;type参数指定存储过程的参数类型,该类型可以是MySQL数据库的任意数据类型。
--注意:只有procedure才有in(传入),out(传出),inout(传入传出)参数,自定义函数(只有)默认就是IN
-
func_parameter:
param_name type
type:
Any valid MySQL data type
characteristic:
COMMENT 'string' --COMMENT‘string’ 注释信息
| LANGUAGE SQL
| [NOT] DETERMINISTIC
| { CONTAINS SQL | NO SQL | READS SQL DATA | MODIFIES SQL DATA }
| SQL SECURITY { DEFINER | INVOKER }
-
--LANGUAGE SQL:说明routine_body部分是由SQL语言的语句组成,这也是数据库系统默认的语言。
--[NOT] DETERMINISTIC:指明存储过程的执行结果是否是确定的。DETERMINISTIC表示结果是确定的。每次执行存储过程时,相同的输入会得到相同的输出。NOT DETERMINISTIC表示结果是非确定的,相同的输入可能得到不同的输出。默认情况下,结果是非确定的
-- CONSTAINS SQL 子程序包含SQL,但不包含读写数据的语句,默认
-- NO SQL 子程序中不包含SQL语句
-- READS SQL DATA 子程序中包含读数据的语句
-- MODIFIES SQL DATA 子程序中包含了写数据的语句
-- SQLSECURITY {DEFINER|INVOKER},指明谁有权限执行。
-- DEFINER 只有定义者自己才能够执行,默认
-- INVOKER 表示调用者可以执行
-- 技巧:创建存储过程时,系统默认指定CONTAINS SQL,表示存储过程中使用了SQL语句。但是,如果存储过程中没有使用SQL语句,最好设置为NO SQL。而且,存储过程中最好在COMMENT部分对存储过程进行简单的注释,以便以后在阅读存储过程的代码时更加方便
-
routine_body:
Valid SQL routine statement
2.创建存储过程和函数
2.1 创建存储过程
gcdb@gczheng 22:45: [employees]> delimiter //
gcdb@gczheng 22:47: [employees]> CREATE PROCEDURE proc_from_employees (IN emp_id INT, OUT count_num INT )
-> READS SQL DATA
-> BEGIN
-> SELECT COUNT(*) INTO count_num
-> FROM employees
-> WHERE emp_no=emp_id ;
-> END ;//
Query OK, 0 rows affected (0.00 sec)
gcdb@gczheng 22:47: [employees]> delimiter ;
gcdb@gczheng 22:47: [employees]> call proc_from_employees(10010,@num); --调用存储过程
Query OK, 1 row affected (0.00 sec)
gcdb@gczheng 22:47: [employees]> select @num;
+------+
| @num |
+------+
| 1 |
+------+
1 row in set (0.00 sec)
上述代码中,存储过程名称为
proc_from_employees;输入变量为emp_id;输出变量为count_num。SELECT语句从employee表查询emp_no值等于emp_id的记录,并用COUNT(*)计算emp_no值相同的记录的条数,最后将计算结果存入count_num中。
说明:MySQL中默认的语句结束符为
分号(;)。存储过程中的SQL语句需要分号来结束。为了避免冲突,首先用"DELIMITER //"将MySQL的结束符设置为//。最后再用"DELIMITER ;"来将结束符恢复成分号。这与创建触发器时是一样的。
2.2 创建存储函数
root@gczheng 23:27: [employees]> delimiter //
root@gczheng 23:27: [employees]> CREATE FUNCTION func_from_employees (emp_id INT )
-> RETURNS VARCHAR(50)
-> BEGIN
-> RETURN ( SELECT concat(last_name," ",first_name) as name
-> FROM employees
-> WHERE emp_no=emp_id );
-> END ;//
ERROR 1418 (HY000): This function has none of DETERMINISTIC, NO SQL, or READS SQL DATA in its declaration and binary logging is enabled (you *might* want to use the less safe log_bin_trust_function_creators variable)
root@gczheng 23:27: [employees]> delimiter ;
- 上面error是由于开启了binlog, 它控制是否可以信任存储函数创建者,不会创建写入二进制日志引起不安全事件的存储函数。明确指明函数的类型:
- 1 DETERMINISTIC 不确定的
- 2 NO SQL 没有SQl语句,当然也不会修改数据
- 3 READS SQL DATA 只是读取数据,当然也不会修改数据
- 4 MODIFIES SQL DATA 要修改数据
- 5 CONTAINS SQL 包含了SQL语句
- 其中在function里面,只有 DETERMINISTIC, NO SQL 和 READS SQL DATA 被支持。如果我们开启了 bin-log, 我们就必须为我们的function指定一个参数。
root@gczheng 23:34: [employees]> delimiter //
root@gczheng 23:34: [employees]> CREATE FUNCTION func_from_employees (emp_id INT )
-> RETURNS VARCHAR(50)
-> READS SQL DATA --指定了数据是读类型
-> BEGIN
-> RETURN ( SELECT concat(last_name," ",first_name) as name
-> FROM employees
-> WHERE emp_no=emp_id );
-> END ;//
Query OK, 0 rows affected (0.00 sec)
root@gczheng 23:34: [employees]> delimiter ;
root@gczheng 23:52: [employees]> select func_from_employees(20000); --调用函数
+----------------------------+
| func_from_employees(20000) |
+----------------------------+
| Matzke Jenwei |
+----------------------------+
1 row in set (0.00 sec)
上述代码中,存储函数的名称为
func_from_employees;该函数的参数为emp_id;返回值是VARCHAR类型;SELECT语句从employee表查询emp_no值等于emp_id的记录,并将该记录的name字段的值返回
3. 变量的使用
在存储过程和函数中,可以定义和使用变量。用户可以使用
DECLARE关键字来定义变量。然后可以为变量赋值。这些变量的作用范围是BEGIN…END程序段中
3.1 定义变量
--定义变量的基本语法如下:
DECLARE var_name[,...] type [DEFAULT value]
DECLARE关键字是用来声明变量的;var_name参数是变量的名称,这里可以同时定义多个变量;type参数用来指定变量的类型;DEFAULT value子句将变量默认值设置为value,没有使用DEFAULT子句时,默认值为NULL。
--下面定义变量myid,数据类型为INT型,默认值为10。
DECLARE myid INT DEFAULT 10 ;
3.2 为变量赋值
- 赋值方法一
MySQL中可以使用SET关键字来为变量赋值。SET语句的基本语法如下:
SET var_name = expr [, var_name = expr] ...
SET关键字是用来为变量赋值的;var_name参数是变量的名称;expr参数是赋值表达式。一个SET语句可以同时为多个变量赋值,各个变量的赋值语句之间用逗号隔开。
--下面为变量my_age赋值为30。
SET my_age = 30 ;
- 赋值方法二
MySQL中还可以使用SELECT…INTO语句为变量赋值。其基本语法如下:
SELECT col_name[,…] INTO var_name[,…]
FROM table_name WEHRE condition
其中,
col_name参数表示查询的字段名称;var_name参数是变量的名称;table_name参数指表的名称;condition参数指查询条件。
下面从dept_emp表中查询emp_no为10020的记录,将该记录的dept_no值赋给变量dept_id。
SELECT dept_no INTO dept_id FROM dept_emp WHERE emp_no=10020;
4.定义条件和处理程序
定义条件和处理程序是事先定义程序执行过程中可能遇到的问题。并且可以在处理程序中定义解决这些问题的办法。这种方式可以提前预测可能出现的问题,并提出解决办法。这样可以增强程序处理问题的能力,避免程序异常停止。MySQL中都是通过DECLARE关键字来定义条件和处理程序。
4.1 定义条件
MySQL中可以使用DECLARE关键字来定义条件。其基本语法如下:
DECLARE condition_name CONDITION FOR condition_value
condition_value:
SQLSTATE [VALUE] sqlstate_value | mysql_error_code
condition_name参数表示条件的名称;condition_value参数表示条件的类型;sqlstate_value参数和mysql_error_code参数都可以表示MySQL的错误。例如ERROR 1146 (42S02)中,sqlstate_value值是42S02,mysql_error_code值是1146。
下面定义"ERROR 1146 (42S02)"这个错误,名称为can_not_find。可以用两种不同的方法来定义,代码如下:
//方法一:使用sqlstate_value
DECLARE can_not_find CONDITION FOR SQLSTATE '42S02' ;
//方法二:使用mysql_error_code
DECLARE can_not_find CONDITION FOR 1146 ;
4.2 定义处理程序
MySQL中可以使用DECLARE关键字来定义处理程序。其基本语法如下:
DECLARE handler_type HANDLER FOR
condition_value[,...] sp_statement
handler_type:
CONTINUE | EXIT | UNDO
condition_value:
SQLSTATE [VALUE] sqlstate_value |
condition_name | SQLWARNING
| NOT FOUND | SQLEXCEPTION | mysql_error_code
其中,
handler_type参数指明错误的处理方式,该参数有3个取值。这3个取值分别是CONTINUE、EXIT和UNDO。CONTINUE表示遇到错误不进行处理,继续向下执行;EXIT表示遇到错误后马上退出;UNDO表示遇到错误后撤回之前的操作,MySQL中暂时还不支持这种处理方式。
- condition_value参数指明错误类型,该参数有6个取值。
- sqlstate_value和mysql_error_code与条件定义中的是同一个意思。
- condition_name是DECLARE定义的条件名称。
- SQLWARNING表示所有以01开头的sqlstate_value值。
- NOT FOUND表示所有以02开头的sqlstate_value值。
- SQLEXCEPTION表示所有没有被SQLWARNING或NOT FOUND捕获的sqlstate_value值。
- sp_statement表示一些存储过程或函数的执行语句。
下面是定义处理程序的几种方式。代码如下:
//方法一:捕获sqlstate_value
DECLARE CONTINUE HANDLER FOR SQLSTATE '42S02'
SET @info='CAN NOT FIND';
//方法二:捕获mysql_error_code
DECLARE CONTINUE HANDLER FOR 1146 SET @info='CAN NOT FIND';
//方法三:先定义条件,然后调用
DECLARE can_not_find CONDITION FOR 1146 ;
DECLARE CONTINUE HANDLER FOR can_not_find SET
@info='CAN NOT FIND';
//方法四:使用SQLWARNING
DECLARE EXIT HANDLER FOR SQLWARNING SET @info='ERROR';
//方法五:使用NOT FOUND
DECLARE EXIT HANDLER FOR NOT FOUND SET @info='CAN NOT FIND';
//方法六:使用SQLEXCEPTION
DECLARE EXIT HANDLER FOR SQLEXCEPTION SET @info='ERROR';
-
第一种方法是捕获sqlstate_value值。如果遇到sqlstate_value值为42S02,执行CONTINUE操作,并且输出"CAN NOT FIND"信息。
-
第二种方法是捕获mysql_error_code值。如果遇到mysql_error_code值为1146,执行CONTINUE操作,并且输出"CAN NOT FIND"信息。
-
第三种方法是先定义条件,然后再调用条件。这里先定义can_not_find条件,遇到1146错误就执行CONTINUE操作。
-
第四种方法是使用SQLWARNING。SQLWARNING捕获所有以01开头的sqlstate_value值,然后执行EXIT操作,并且输出"ERROR"信息。
-
第五种方法是使用NOT FOUND。NOT FOUND捕获所有以02开头的sqlstate_value值,然后执行EXIT操作,并且输出"CAN NOT FIND"信息。
-
第六种方法是使用SQLEXCEPTION。SQLEXCEPTION捕获所有没有被SQLWARNING或NOT FOUND捕获的sqlstate_value值,然后执行EXIT操作,并且输出"ERROR"信息。
5.游标的使用
查询语句可能查询出多条记录,在存储过程和函数中使用游标来逐条读取查询结果集中的记录。游标的使用包括
声明游标、打开游标、使用游标和关闭游标。游标必须声明在处理程序之前,并且声明在变量和条件之后。
5.1 声明游标
MySQL中使用DECLARE关键字来声明游标。其语法的基本形式如下:
DECLARE cursor_name CURSOR FOR select_statement ;
其中,
cursor_name参数表示游标的名称;select_statement参数表示SELECT语句的内容。
下面声明一个名为cur_employee的游标。
DECLARE cur_employee CURSOR FOR SELECT emp_no,birth_date FROM employees ;
上面的示例中,游标的名称为cur_employee;SELECT语句部分是从employee表中查询出emp_no和birth_date字段的值。
5.2 打开游标
MySQL中使用OPEN关键字来打开游标。其语法的基本形式如下:
OPEN cursor_name ;
--其中,cursor_name参数表示游标的名称。
--下面打开一个名为cur_employee的游标:
OPEN cur_employee ;
5.3 使用游标
MySQL中使用FETCH关键字来使用游标。其语法的基本形式如下:
FETCH cur_employee INTO var_name[,var_name…] ;
其中,
cursor_name参数表示游标的名称;var_name参数表示将游标中的SELECT语句查询出来的信息存入该参数中。var_name必须在声明游标之前就定义好。
下面使用一个名为cur_employee的游标。将查询出来的数据存入row_emp_no和row_birth_date这两个变量中,代码如下:
FETCH cur_employee INTO row_emp_no,row_birth_date;
将游标cur_employee中SELECT语句查询出来的信息存入row_emp_no和row_birth_date中。row_emp_no和row_birth_date必须在前面已经定义。
5.4 关闭游标
MySQL中使用CLOSE关键字来关闭游标。其语法的基本形式如下:
CLOSE cursor_name ;
--cursor_name参数表示游标的名称。
下面关闭一个名为cur_employee的游标:
CLOSE cur_employee ;
关闭了这个名称为cur_employee的游标。关闭之后就不能使用FETCH来使用游标了。
技巧:如果存储过程或函数中执行SELECT语句,并且SELECT语句会查询出多条记录。这种情况最好使用游标来逐条读取记录。游标必须在处理程序之前且在变量和条件之后声明。而且,游标使用完后一定要关闭。
--定义游标,employees表`emp_no`和`birth_date`字段取十行
root@gczheng 13:37: [employees]> DELIMITER //
root@gczheng 13:39: [employees]> CREATE PROCEDURE proc_cursor()
-> BEGIN
-> DECLARE row_emp_no INT;
-> DECLARE row_birth_date DATE;
-> DECLARE rownum INT DEFAULT 10; -- 定义取10行
-> DECLARE i INT DEFAULT 0;
-> DECLARE cur_employee CURSOR FOR SELECT emp_no,birth_date FROM employees ;
-> OPEN cur_employee;
-> REPEAT
-> SET i:=i+1;
-> FETCH cur_employee INTO row_emp_no,row_birth_date;
-> SELECT row_emp_no, row_birth_date;
-> UNTIL i>=rownum END REPEAT;
-> CLOSE cur_employee;
-> END ;//
Query OK, 0 rows affected (0.00 sec)
root@gczheng 13:39: [employees]> DELIMITER ;
root@gczheng 13:39: [employees]> CALL proc_cursor();
+------------+----------------+
| row_emp_no | row_birth_date |
+------------+----------------+
| 10001 | 1953-09-02 |
+------------+----------------+
1 row in set (0.13 sec)
+------------+----------------+
| row_emp_no | row_birth_date |
+------------+----------------+
| 10002 | 1964-06-02 |
+------------+----------------+
1 row in set (0.13 sec)
+------------+----------------+
| row_emp_no | row_birth_date |
+------------+----------------+
| 10003 | 1959-12-03 |
+------------+----------------+
1 row in set (0.13 sec)
+------------+----------------+
| row_emp_no | row_birth_date |
+------------+----------------+
| 10004 | 1954-05-01 |
+------------+----------------+
1 row in set (0.13 sec)
+------------+----------------+
| row_emp_no | row_birth_date |
+------------+----------------+
| 10005 | 1955-01-21 |
+------------+----------------+
1 row in set (0.13 sec)
+------------+----------------+
| row_emp_no | row_birth_date |
+------------+----------------+
| 10006 | 1953-04-20 |
+------------+----------------+
1 row in set (0.13 sec)
+------------+----------------+
| row_emp_no | row_birth_date |
+------------+----------------+
| 10007 | 1957-05-23 |
+------------+----------------+
1 row in set (0.13 sec)
+------------+----------------+
| row_emp_no | row_birth_date |
+------------+----------------+
| 10008 | 1958-02-19 |
+------------+----------------+
1 row in set (0.13 sec)
+------------+----------------+
| row_emp_no | row_birth_date |
+------------+----------------+
| 10009 | 1952-04-19 |
+------------+----------------+
1 row in set (0.13 sec)
+------------+----------------+
| row_emp_no | row_birth_date |
+------------+----------------+
| 10010 | 1963-06-01 |
+------------+----------------+
1 row in set (0.13 sec)
Query OK, 0 rows affected (0.13 sec)
root@gczheng 13:39: [employees]> DROP PROCEDURE proc_cursor;
Query OK, 0 rows affected (0.01 sec)
6. 流程控制语句
6.1 IF语句
IF语句用来进行条件判断。根据是否满足条件,将执行不同的语句
-- 语法
IF search_condition THEN statement_list
[ELSEIF search_condition THEN statement_list] ...
[ELSE statement_list]
END IF
--
-- 例子
--
gcdb@gczheng 23:04: [employees]> DELIMITER //
gcdb@gczheng 23:04: [employees]> CREATE PROCEDURE proc_test1 (IN emp_id INT,OUT countnum INT)
-> BEGIN
-> IF emp_id > 20000 THEN
-> SELECT COUNT(*) INTO countnum FROM employees WHERE emp_no > emp_id ;
-> ELSEIF emp_id = 20000 THEN
-> SELECT COUNT(*) INTO countnum FROM employees WHERE emp_no = 20000 ;
-> ELSE
-> SELECT COUNT(*) INTO countnum FROM employees WHERE emp_no < emp_id ;
-> END IF;
-> END //
Query OK, 0 rows affected (0.00 sec)
gcdb@gczheng 23:04: [employees]> DELIMITER ;
gcdb@gczheng 23:04: [employees]> call proc_test1(20000,@countnum);
Query OK, 1 row affected (0.01 sec)
gcdb@gczheng 23:05: [employees]> SELECT @countnum;
+-----------+
| @countnum |
+-----------+
| 1 |
+-----------+
1 row in set (0.00 sec)
gcdb@gczheng 23:05: [employees]> call proc_test1(20050,@countnum);
Query OK, 1 row affected (0.06 sec)
gcdb@gczheng 23:05: [employees]> SELECT @countnum;
+-----------+
| @countnum |
+-----------+
| 289974 |
+-----------+
1 row in set (0.00 sec)
gcdb@gczheng 23:05: [employees]> call proc_test1(10050,@countnum);
Query OK, 1 row affected (0.00 sec)
gcdb@gczheng 23:05: [employees]> SELECT @countnum;
+-----------+
| @countnum |
+-----------+
| 49 |
+-----------+
1 row in set (0.00 sec)
gcdb@gczheng 23:05: [employees]>
6.2 CASE WHEN 语法
CASE语句也用来进行条件判断,其可以实现比IF语句更复杂的条件判断
CASE case_value
WHEN when_value THEN statement_list
[WHEN when_value THEN statement_list] ...
[ELSE statement_list]
END CASE
-- 或者是
CASE
WHEN search_condition THEN statement_list
[WHEN search_condition THEN statement_list] ...
[ELSE statement_list]
END CASE
--
-- CASE WHEN 例子
--
gcdb@gczheng 23:23: [employees]> DELIMITER //
gcdb@gczheng 23:23: [employees]> CREATE PROCEDURE proc_case (IN id INT)
-> BEGIN
-> CASE id
-> WHEN 1 THEN
-> SELECT * FROM departments WHERE dept_no='d001';
-> WHEN 2 THEN
-> SELECT * FROM departments WHERE dept_no='d002';
-> WHEN 3 THEN
-> SELECT * FROM departments WHERE dept_no='d003';
-> ELSE
-> SELECT * FROM departments WHERE dept_no='d004';
-> END CASE;
-> END //
Query OK, 0 rows affected (0.01 sec)
gcdb@gczheng 23:23: [employees]> DELIMITER ;
gcdb@gczheng 23:23: [employees]> call proc_case(1);
+---------+-----------+
| dept_no | dept_name |
+---------+-----------+
| d001 | Marketing |
+---------+-----------+
1 row in set (0.00 sec)
Query OK, 0 rows affected (0.00 sec)
gcdb@gczheng 23:23: [employees]> call proc_case(3);
+---------+-----------------+
| dept_no | dept_name |
+---------+-----------------+
| d003 | Human Resources |
+---------+-----------------+
1 row in set (0.00 sec)
Query OK, 0 rows affected (0.00 sec)
gcdb@gczheng 23:23: [employees]> call proc_case(4);
+---------+------------+
| dept_no | dept_name |
+---------+------------+
| d004 | Production |
+---------+------------+
1 row in set (0.00 sec)
Query OK, 0 rows affected (0.00 sec)
gcdb@gczheng 23:23: [employees]> call proc_case(5);
+---------+------------+
| dept_no | dept_name |
+---------+------------+
| d004 | Production |
+---------+------------+
1 row in set (0.00 sec)
Query OK, 0 rows affected (0.00 sec)
gcdb@gczheng 23:23: [employees]>
6.3 WHILE 循环
WHILE语句也是有条件控制的循环语句。但WHILE语句和REPEAT语句是不一样的。WHILE语句是当满足条件时,执行循环内的语句。
-- WHILE 语法
[begin_label:] WHILE search_condition DO
statement_list
END WHILE [end_label]
-- WHILE举例
(gcdb@localhost) 09:53:00 [employees]> DELIMITER //
(gcdb@localhost) 09:53:01 [employees]> CREATE PROCEDURE proc_while (IN p_num INT, OUT p_result INT)
-> BEGIN
-> SET p_result = 1 ;
-> WHILE p_num > 1 DO
-> SET p_result = p_result * p_num ;
-> SET p_num = p_num - 1 ;
-> END
-> WHILE ;
-> END ;//
Query OK, 0 rows affected (0.00 sec)
(gcdb@localhost) 09:53:33 [employees]> CALL proc_while(5,@p_result);
Query OK, 0 rows affected (0.00 sec)
(gcdb@localhost) 09:54:09 [employees]> SELECT @p_result;
+-----------+
| @p_result |
+-----------+
| 120 |
+-----------+
1 row in set (0.00 sec)
(gcdb@localhost) 09:54:34 [employees]> CALL proc_while(1,@p_result);
Query OK, 0 rows affected (0.00 sec)
(gcdb@localhost) 09:54:39 [employees]> SELECT @p_result;
+-----------+
| @p_result |
+-----------+
| 1 |
+-----------+
1 row in set (0.00 sec)
(gcdb@localhost) 09:54:40 [employees]> CALL proc_while(0,@p_result);
Query OK, 0 rows affected (0.00 sec)
(gcdb@localhost) 09:54:44 [employees]> SELECT @p_result;
+-----------+
| @p_result |
+-----------+
| 1 |
+-----------+
1 row in set (0.00 sec)
(gcdb@localhost) 09:54:45 [employees]>
6.4 REPEAT循环
REPEAT语句是
有条件控制的循环语句。当满足特定条件时,就会跳出循环语句。
-- REPEAT 语法
[begin_label:] REPEAT
statement_list
UNTIL search_condition
END REPEAT [end_label]
(gcdb@localhost) 09:36:12 [employees]> DELIMITER //
(gcdb@localhost) 09:36:14 [employees]> CREATE PROCEDURE proc_repeat (IN p_num INT, OUT p_result INT)
-> BEGIN
-> SET p_result = 1;
-> REPEAT
-> SET p_result = p_result * p_num;
-> SET p_num = p_num - 1 ;
-> UNTIL p_num <= 1 END REPEAT ;
-> END;//
Query OK, 0 rows affected (0.00 sec)
(gcdb@localhost) 09:36:14 [employees]> DELIMITER ;
(gcdb@localhost) 09:36:15 [employees]> call proc_repeat(5,@p_result);
Query OK, 0 rows affected (0.00 sec)
(gcdb@localhost) 09:36:27 [employees]> select @p_result;
+-----------+
| @p_result |
+-----------+
| 120 |
+-----------+
1 row in set (0.00 sec)
(gcdb@localhost) 09:36:34 [employees]> call proc_repeat(1,@p_result);
Query OK, 0 rows affected (0.00 sec)
(gcdb@localhost) 09:36:44 [employees]> select @p_result;
+-----------+
| @p_result |
+-----------+
| 1 |
+-----------+
1 row in set (0.00 sec)
(gcdb@localhost) 09:36:45 [employees]> call proc_repeat(0,@p_result);
Query OK, 0 rows affected (0.00 sec)
(gcdb@localhost) 09:36:49 [employees]> select @p_result;
+-----------+
| @p_result |
+-----------+
| 0 |
+-----------+
1 row in set (0.00 sec)
(gcdb@localhost) 09:36:51 [employees]>
- while 和 repeat对比
6.5 loop循环、LEAVE和ITERATE语句
-- loop语法
[begin_label:] LOOP
statement_list
END LOOP [end_label]
LEAVE label
ITERATE label
-- ITERATE 和label相结合,表示继续从label处执行
-- LEAVE 和label相结合,表示从label 标记的代码段离开
LOOP语句可以使某些特定的语句重复执行,实现一个简单的循环。但是LOOP语句本身
没有停止循环的语句,必须是遇到LEAVE语句等才能停止循环。
LEAVE语句主要用于跳出
循环控制。
ITERATE语句也是用来跳出循环的语句。但是,ITERATE语句是跳出
本次循环,然后直接进入下一次循环。
-- loop 例子
(gcdb@localhost) 10:23:38 [employees]> DELIMITER //
(gcdb@localhost) 10:24:15 [employees]> CREATE PROCEDURE proc_loop (IN p_num INT)
-> BEGIN
-> t_label : LOOP
-> SET p_num := p_num + 1 ; -- 参数累加
-> IF p_num < 10 THEN
-> ITERATE t_label ; -- 如果累加的值小于10,继续执行t_label
-> END IF ;
-> LEAVE t_label ; -- 如果>=10则离开这个t_label(loop)
-> END LOOP t_label ;
-> SET @x = p_num ; -- 设置会话级别的变量
-> END ;//
Query OK, 0 rows affected (0.00 sec)
(gcdb@localhost) 10:24:15 [employees]> DELIMITER ;
(gcdb@localhost) 10:24:17 [employees]> CALL proc_loop(11); -- 11>10 执行LEAVE,离开整个循环
Query OK, 0 rows affected (0.00 sec)
(gcdb@localhost) 10:24:28 [employees]> SELECT @x;
+------+
| @x |
+------+
| 12 |
+------+
1 row in set (0.00 sec)
(gcdb@localhost) 10:24:28 [employees]> CALL proc_loop(9); -- 9<10 ,累加1次后>=10为true,执行ITERATE离开循环,再对比执行LEAVE,离开整个循环
Query OK, 0 rows affected (0.00 sec)
(gcdb@localhost) 10:24:34 [employees]> SELECT @x; -- 累加到10的 param_1 赋值给 x, 即为10
+------+
| @x |
+------+
| 10 |
+------+
1 row in set (0.00 sec)
(gcdb@localhost) 10:24:37 [employees]> CALL proc_loop(8); -- 8<10 ,累加2次后>=10为true,离开循环,执行ITERATE离开循环,再对比执行LEAVE,离开整个循环
Query OK, 0 rows affected (0.00 sec)
(gcdb@localhost) 10:24:40 [employees]> SELECT @x;
+------+
| @x |
+------+
| 10 |
+------+
1 row in set (0.00 sec)
(gcdb@localhost) 10:24:41 [employees]>
7. 查看、修改、删除存储过程和函数
7.1 查看存储过程和函数
--SHOW STATUS语句查看存储过程和函数的状态
(gcdb@localhost) 11:00:51 [employees]> show procedure status like 'proc_loop'\G;
*************************** 1. row ***************************
Db: employees
Name: proc_loop
Type: PROCEDURE
Definer: gcdb@%
Modified: 2017-12-18 10:24:15
Created: 2017-12-18 10:24:15
Security_type: DEFINER
Comment:
character_set_client: utf8
collation_connection: utf8_general_ci
Database Collation: utf8_general_ci
1 row in set (0.00 sec)
ERROR:
No query specified
-- SHOW CREATE语句查看存储过程和函数的定义
(gcdb@localhost) 11:05:23 [employees]> show create procedure proc_loop \G;
*************************** 1. row ***************************
Procedure: proc_loop
sql_mode:
Create Procedure: CREATE DEFINER=`gcdb`@`%` PROCEDURE `proc_loop`(IN p_num INT)
BEGIN
t_label : LOOP
SET p_num := p_num + 1 ;
IF p_num < 10 THEN
ITERATE t_label ;
END IF ;
LEAVE t_label ;
END LOOP t_label ;
SET @x = p_num ;
END
character_set_client: utf8
collation_connection: utf8_general_ci
Database Collation: utf8_general_ci
1 row in set (0.00 sec)
ERROR:
No query specified
--从information_schema.Routines表中查看存储过程和函数的信息
(gcdb@localhost) 11:08:15 [employees]> SELECT * FROM information_schema.Routines WHERE ROUTINE_NAME='proc_loop' \G;
*************************** 1. row ***************************
SPECIFIC_NAME: proc_loop
ROUTINE_CATALOG: def
ROUTINE_SCHEMA: employees
ROUTINE_NAME: proc_loop
ROUTINE_TYPE: PROCEDURE
DATA_TYPE:
CHARACTER_MAXIMUM_LENGTH: NULL
CHARACTER_OCTET_LENGTH: NULL
NUMERIC_PRECISION: NULL
NUMERIC_SCALE: NULL
DATETIME_PRECISION: NULL
CHARACTER_SET_NAME: NULL
COLLATION_NAME: NULL
DTD_IDENTIFIER: NULL
ROUTINE_BODY: SQL
ROUTINE_DEFINITION: BEGIN
t_label : LOOP
SET p_num := p_num + 1 ;
IF p_num < 10 THEN
ITERATE t_label ;
END IF ;
LEAVE t_label ;
END LOOP t_label ;
SET @x = p_num ;
END
EXTERNAL_NAME: NULL
EXTERNAL_LANGUAGE: NULL
PARAMETER_STYLE: SQL
IS_DETERMINISTIC: NO
SQL_DATA_ACCESS: CONTAINS SQL
SQL_PATH: NULL
SECURITY_TYPE: DEFINER
CREATED: 2017-12-18 10:24:15
LAST_ALTERED: 2017-12-18 10:24:15
SQL_MODE:
ROUTINE_COMMENT:
DEFINER: gcdb@%
CHARACTER_SET_CLIENT: utf8
COLLATION_CONNECTION: utf8_general_ci
DATABASE_COLLATION: utf8_general_ci
1 row in set (0.01 sec)
ERROR:
No query specified
7.2 修改存储过程和函数
修改存储过程和函数是
指修改已经定义好的存储过程和函数。MySQL中通过ALTER PROCEDURE语句来修改存储过程。通过ALTER FUNCTION语句来修改存储函数。
MySQL中修改存储过程和函数的语句的语法形式如下:
ALTER {PROCEDURE | FUNCTION} sp_name [characteristic ...]
characteristic:
{ CONTAINS SQL | NO SQL | READS SQL DATA | MODIFIES SQL DATA }
| SQL SECURITY { DEFINER | INVOKER }
| COMMENT 'string'
其中,
sp_name参数表示存储过程或函数的名称;
characteristic参数指定存储函数的特性;
CONTAINS SQL表示子程序包含SQL语句,但不包含读或写数据的语句;
NO SQL表示子程序中不包含SQL语句;
READS SQL DATA表示子程序中包含读数据的语句;
MODIFIES SQL DATA表示子程序中包含写数据的语句;
SQL SECURITY { DEFINER | INVOKER }指明谁有权限来执行;
DEFINER表示只有定义者自己才能够执行;
INVOKER表示调用者可以执行;
COMMENT 'string'是注释信息
说明:修改存储过程使用
ALTER PROCEDURE语句,修改存储函数使用ALTER FUNCTION语句。但是,这两个语句的结构是一样的,语句中的所有参数都是一样的。而且,它们与创建存储过程或函数的语句中的参数也是基本一样的。
(gcdb@localhost) 11:13:05 [employees]> show create procedure num_from_employees\G;
*************************** 1. row ***************************
Procedure: num_from_employees
sql_mode:
Create Procedure: CREATE DEFINER=`gcdb`@`%` PROCEDURE `num_from_employees`(in emp_id int,out count_numint)
READS SQL DATA --原来READS SQL DATA
begin
select count(*) into count_num from employees where emp_no = emp_id;
end
character_set_client: utf8
collation_connection: utf8_general_ci
Database Collation: utf8_general_ci
1 row in set (0.00 sec)
ERROR:
No query specified
(gcdb@localhost) 11:13:20 [employees]> alter procedure num_from_employees modifies sql data sql security inUvoker; --修改成MODIFIES SQL DATA
Query OK, 0 rows affected (0.00 sec)
(gcdb@localhost) 11:15:15 [employees]> show create procedure num_from_employees\G;
*************************** 1. row ***************************
Procedure: num_from_employees
sql_mode:
Create Procedure: CREATE DEFINER=`gcdb`@`%` PROCEDURE `num_from_employees`(in emp_id int,out count_numint)
MODIFIES SQL DATA --修改成MODIFIES SQL DATA
SQL SECURITY INVOKER
begin
select count(*) into count_num from employees where emp_no = emp_id;
end
character_set_client: utf8
collation_connection: utf8_general_ci
Database Collation: utf8_general_ci
1 row in set (0.00 sec)
ERROR:
No query specified
7.3 删除存储过程和函数
(gcdb@localhost) 11:15:19 [employees]> drop procedure num_from_employees;
Query OK, 0 rows affected (0.00 sec)
(gcdb@localhost) 11:22:21 [employees]> show create procedure num_from_employees\G;
ERROR 1305 (42000): PROCEDURE num_from_employees does not exist
ERROR:
No query specified
(gcdb@localhost) 11:22:25 [employees]>
