


Windows kernel pool 初探(2014.12)
Windows kernel pool
1. 简介
Kernel pool类似于Windows用户层所使用Heap,其为内核组件提供系统资源。在系统初始化的时候,内存管理模块就创建了pool。
严格的来说,pool只分为nonpaged pool和paged pool两类。
nonpaged pool:
-
只能常驻于物理内存地址,不能映射。(reside in physical memory at all times and can be accessed at any time without incurring page fault.)
-
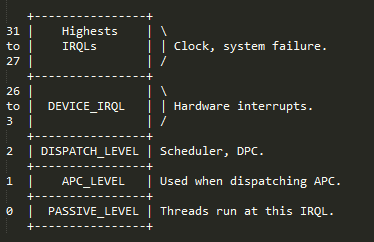
只能在DPC/dispatch level或者更高IRQL才可以访问。
Paged pool:
-
可以映射(can be paged into and out of the system).
-
任何级别的IRQL都可以访问,所以每个进程都可以访问。
两种pool都会被映射到每一个进程空间内,都使用ExAllocatePool()和ExFreePool()来分配和释放。
IRQL是系统用来管理中断优先权,下图中的数值越大就表示优先权越高。
2. 一些结构
系统默认的pool有:
– One nonpaged pool
– Two paged pools
– One session paged pool (和每一个session有关,每一个用户都不同)
每一个pool 都有一个POOL_DESCRIPTOR结构来管理pool,其功能包括:
1.跟踪pool的分配和释放,使用的page数量等。
2.维护free pool thunks lists。
初始化的POOL_DESCRIPTOR是放在nt!PoolVector数组(这个值是系统的全局变量)里面的。
POOL_DESCRIPTOR的结构如下:

该结构相关的一些变量介绍:
– PoolType:
NonPagedPool=0,PagedPool=1
– PoolIndex:
nonpaged pool & paged session pool =0
paged pool=index of the pool descriptor in nt!ExpPagedPoolDescriptor
– PendingFrees:
单项链表,表示将要释放的pool
– ListHeads:
大小512的ListEntry结构数组(从0开始,8个字节递增),双向链表,表示已经释放了的pool,可以随时再次被使用。
2.1 NonPaged Pool
1. pool的数量存储在nt!ExpNumberOfNonPagedPools中。
2. 单处理器系统中,nt!PoolVector数组的第一成员就是nonpaged pool descriptor:
nt!NonPagedPoolDescriptor,其是写入到.data中的定值。
kd> dt nt!_POOL_DESCRIPTOR poi(nt!PoolVector)
3.多处理系统中,每一个node(NUMA system call processors and memory)都有自己的nonpaged pool descriptor。
存储在nt!ExpNonPagedPoolDescriptor中。
Windbg中:


PoolVector数组(似乎在xp下是一个定值):

2.2 Paged Pool
1. Pool的数量存储在nt!ExpNumberOfPagedPools中。
2. 单处理器系统中,4个paged pool descriptors地址在nt!ExpPagedPoolDescriptor数组中存储(index of 1-4)。
3. 多处理器系统中,每一个node定义一个paged pool descriptor。
4. 还有一类特殊的按页分配的pool(prototype pools/full page allocations),位于nt!ExpPagedPoolDescriptor的第一个索引(index 0)。
现在用windbg查看一下nonpaged pool和paged pool在内核中的模样:
paged pool descriptor

nt!ExpPagedPoolDescriptor[0]= PoolVector[1]:poi(0x8055c520)=poi(0x8055c560+4)
paged pool descriptor of prototy pools

paged pool descriptor of normal paged pool
 ‘
‘
2.3 Session Pool
xp下,win7的差别似乎有点大
1. Pageable system memory(paged pool)。
2. PagedPool member of nt!MmSessionSpace structure。
Usually 0xbf7f0000+0x244(XP下)
3. 使用函数nt!MiInitializeSessionPool初始化。
作为session space 使用,不会使用Lookaside lists(快表)。
4. Point of pool descriptor 存放在nt! ExpSessionPoolDescriptor中。

2.4 ListHeads(x86)
作为pool descriptor的成员之一,其是由大小为512,每个成员为LIST_ENTRY的数组构成的:
– LIST_ENTRY为一个双向链表,表示大小相同的free chunks。
– 所表示的pool大小以8字节递增,最大为4080 bytes。
– 空闲的chunks是以BlockSize为索引加入到ListHeads 中去,1 BlockSize=8 bytes。
– chunk的BlockSize计算公式BlockSize= (NumBytes+0xF) >> 3。 – 每一个chunk 都有一个8 byte 的pool header用来管理该chunk。
ListHeads的样子大概如下:

2.5 Kernel Pool Header(x86)
Pool Header是用来管理pool thunk的,里面存放一些为释放和分配所需要的信息。

– PreviousSize: 前一个chunk的BlockSize。
– PoolIndex : 所在大pool的pool descriptor的index。这是用来检查释放pool的算法是否释放正确了。
– PoolType: Free=0,Allocated=(PoolType|2)
– PoolTag: 4个可打印字符,标明由哪段代码负责。(4 printable characters identifying the code responsible for the allocation)
2.6 LIST_ENTRY
当一个pool chunk释放并准备放到ListJHeads list的时候,其pool header结构会添加一个LIST_ENTRY结构,这个LIST_ENTRY是ListHeads 使用管理free pool thunk的双向链表。

BlockSize 为n的pool chunk ,free之后链入到ListHeads中的样子
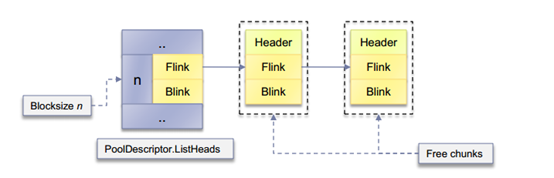
Chunk释放前和释放后的变化:

利用windbg看一下pool chunk吧。
首先利用!pool列出系统中所有的paged pool(似乎不包括Lookaside lists):
一部分如下:

可以发现其都是以一个page大小(0x1000)显示出来的,那么接下来查看其中任意一个page,部分为如:
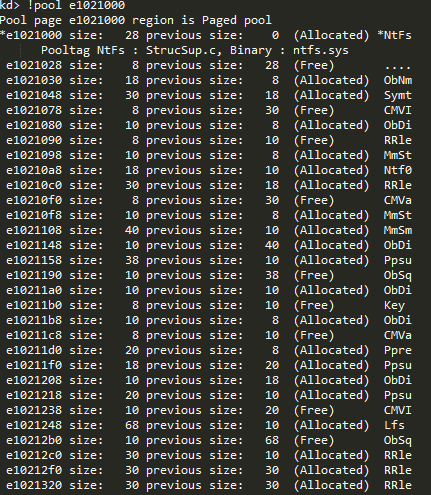
查看其中一个首地址为e10212b0,大小为10 bytes,标记为free的pool chunk。

再看看LIST_ENTRY里面的内容:

ListHeads中和该pool thunk相邻的thunk:

两者的大小相同。
2.7 Lookaside List
(xp下)
Windows 还使用了Lookaside(快表?)这种单项链表(LIFO)来管理更快的pool分配。
1. BlockSize最大为32,也就是最大为256 bytes.
2. 以8 bytes大小递增,每种类型的Lookaside 只有32项。
3. 在The Prcessor Control Block(KPRCB)中定,Each entry(KPRCB定义的_PP_LOOKASIDE_LIST) holds 2 single chained lists of nt!_GENERAL_LOOKASIDE structures: one "per processor" P, one "system wide" L。
4. 不会存在"找零钱"的现象(类似应用层的heap)。
利用windbg查看相关值。
查看fs:[20]的值或使用!prcb命令,都可以得到KPRCB:


– PPPagedLookasideList for paged pool.
– PPNPagedLookasideList for nonpaged pool.
– PPLookasideList for frequently requested fixed size allocations(比如I/O 请求包和memory descriptor lists?)

P: "per processor"
L: "system wide"
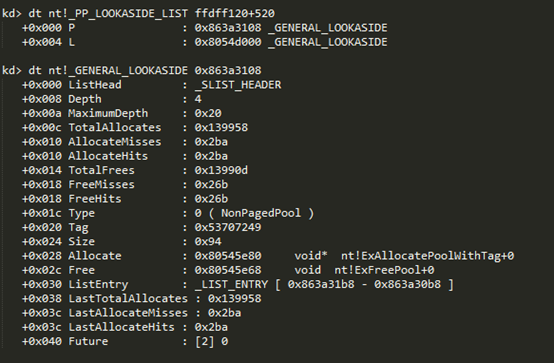
关于Lookasdide的单项链表是怎么管理其空闲链表的,还未知,留疑。
2.8 Large Pool
(存在多处疑问)
如果需求的pool大于4080 bytes,ListHeads将无法满足。用户调用nt!ExpAllocateBigPool函数,而系统是使用nt!AllcocatePoolPages来处理。当pool page allocator分配了一块pool。A "frag" chunk(BlockSize=1,previous size 0)会马上加入到这块page后,便于ListHeads来管理这块剩下的page。
3.分配和释放算法
3.1 分配
内核函数ExAllocatePoolWithTag(或者其衍生函数)来负责pool的分配,该函数会依次尝试Lookaside lists和ListHeads lists最后才会向pool page allocator申请一块page。
1. 如果没有找到刚好合适的chunk,会对返回的chunk进行拆分。
2. 如果需要,会扩充pool的大小。
分配算法的伪代码(xp):

分配算法的伪代码(win7):
增加了session paged pool 和 safe unlink

如果返回的thunk大于所需要的,就会被分割:
1. 如果分配的thunk在页的开始(页的开始都是0x1000的倍数),那么就使用该thunk开始的部分
2. 否则是否使用thunk结束的部分。
两种情况,没有用完的thunk都会重新加入到ListHeads合适位置,以减小碎片化。

3.2 释放
使用内核函数ExFreePoolWithTag(或者其衍生函数)来处理pool的释放。其会根据pool header提供的信息来操作。
1. 依次尝试使用Lookaside List和ListHeads。
2. 如果相邻的pool thunk为free,会发生合并(Merge)操作,减小碎片化。
3. 必要时会释放page。
释放函数的伪代码(XP)

注意发生合并的条件!
PAGE_ALIGNED(NextEntry)可以理解为判断NextEntry是否为一个page的开始。
释放函数的伪代码(Win7)
增加了safe unlink、PendingFree Lists和Session pool。


Free Pool Chunk Ordering
1. 释放到the lookaside和pool descriptor ListHeads pool thunk一般是在其管理free pool thunk链表中的首个位置。但是被分割剩下来的thunk是放在其尾部的。
2. 一般分配pool时都会从appropriate list选用最近所使用过的。这样可以尽可能减少CPU的使用。
4.Kernel Pool Exploitation
Traditional ListEntry Attacks (< Windows 7)
Pool BugChecks(XP)
当系统因为pool的相关原因发生异常的时候,会出现以下蓝屏代码:
0x19: BAD_POOL_HEADER
0x41: MUST_SUCCEED_POOL_EMPTY
0xc1: SPECIAL_POOL_DETECTED_MEMORY_CORRUPTION
0xc2: BAD_POOL_CALLER
其中的一些只有在"Checked Build"的版本才会出现。
一些BugCheck发生的条件:
0xc2|0x7:if PoolType&4=0 尝试释放已经释放掉了的pool chunk
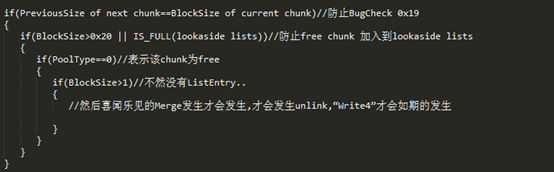
0x19|0x20:if PreviousSize of next chunk !=BlockSize of current chunk
Checked Build(测试版本):
BugCheck 0x19 |0x3:if (Entry->Flink)->Blink!=Entry or (Entry->Blink)->Flink!=Entry
这似乎是Win7中加入的safe unlink的思想,但是没有在XP的消费者版本中加入该安全机制。
Write 4 Techniques
如有这样一段双向链表关系:
PLIST_ENTRY e,b,f;
f=e->Flink;
b=e->Blink;
当e从双向链表中卸载的时候,会发生这样的操作:
b->Flink=f;
f->Blink=b;
Or
e->Blink->Flink=f;
e->Flink->Blink=b;
如果可以控制e的Flink(What)和Blink(Where)的值,那么借此unlink就有了一个对任意地址写入任意数据的机会了。
*(Where)=What
*(What+4)=Where

前面两种情况都发生在pool chunk free的时候,而后两种情况发生在pool chunk分配的时候,第4项中的MmNonPagedPoolFreeListHead是XP下用来管理大于1 page的pool的。
所谓的Kernel Pool Overflow:
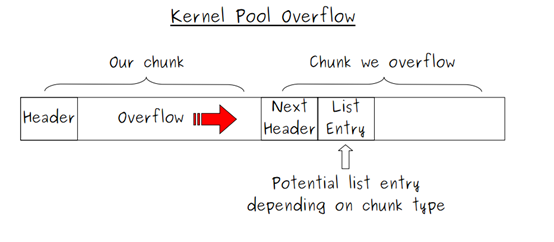
a. Write4 on Merge with Next
首先our chunk发生overflow,覆盖掉了和其相邻的chunk,如果被覆盖的nextchunk为free,这个时候our chunk释放的时候,就会和next chunk发生合并操作。但是在合并的操作发生之前,会发生一次unlink操作:nextchunk会从所在ListHeads卸载下来,而这次卸载就为"Write4"提供了机会。因为"Flink"和"Blink"都是我们可以控制的。

注意图中两个chunk的状态(free or not free)
要让此时的"Write4"按照预期发生,需要一些条件:
b. Write4 on Merge with Previous
和上面类似,our chunk覆盖了下一个chunk,但是此时要释放的并不是our chunk而是next chunk,使"Write4"发生的方法有所不同:需要在next chunk的Pool Header结构之前构造一个fake pool chunk,并标记为free。这样next chunk free的时候,因为其会先检查相邻的pool chunk,如果发现free pool chunk,就会发生合并操作,我们构造的fake free pool chunk会从ListHeads List卸载下来,此时"Write4"就有机会了。
同样,"Write4"发生的一些条件:
以chunk we overflowed作为current chunk,描述中的previous chunk和next chunk都是相对比chunk we overflowed的。

对此有一个疑问:怎么样保证的fake chunk会从ListHeads执行卸载操作?而不是从Lookaside?
下面的这两种方法和上面的不同,都是在chunk分配的时候才会发生"Write4"。
c.Write4 on ListHeads Unlink
如果overflow的free pool chunk 被再次的分配,那么其从ListHeads中unlink的时候,"Write4"就有可能发生了。条件:
1. If the chunk was requested through ListHeads list:no other constraint on BlockSize, PreviousSize…
2. 如果可以我们overflow的free pool chunk是ListHeads[BlockSize]->Flink。
3. 下一次申请BlockSize大小的pool时,overflow的chunk就会被再使用。
d.Write4 on MMFREE_POOL_ENTRY Unlink
MmNonPagedPoolFreeListHead 是XP下管理大于1 page free pool的双向链表,MMFREE_POOL_ENTRY用来管理每一个pool chunk。和上面的方法类似,如果overflowed pool chunk被再次利用(allocated)的时候,就会产生"Write4"的机会了。
What & Where
上面简单的介绍了各种"Write4"方法,那么拥有了这样一个对任意地址写任意内容的机会,应该怎么来利用呢?
关于pool overflows expliot的一些坑:

一些想法:
1. nt!KiDebugRoutine function pointer
内核发生异常时,KiDispatchException会检查KiDebugRoutione是否为NULL,如果不为NULL 会进行调用。所以可以通过改写该处的值达到让shellcode执行的目的。
2.Context specific function pointers 上下文的函数调用?
3. Function pointers arrays
-nt!HalDispatchTable
-Interrupt Dispatch Table (IDT)
4. Kernel instructions – page is RWE!(什么意思??)
一些善后工作:

by:会飞的猫
转载请注明:http://www.cnblogs.com/flycat-2016

 浙公网安备 33010602011771号
浙公网安备 33010602011771号