

Linux 流量控制总结(TC)
TC对带宽的描述:
mbps = 1024 kbps = 1024 * 1024 bps => byte/s
mbit = 1024 kbit => kilo bit/s.
mb = 1024 kb = 1024 * 1024 b => byte
mbit = 1024 kbit => kilo bit.
TC的队列:
队列:决定了数据被发送的方式,注意是发送的方式,TC无法对接收的数据进行控制
无类队列:内部不包含可配置子类的队列规定。
分类队列:队列规定内可以包含更多的类,每个类又进一步地包含一个队列规定,被包含的队列可以使无类或者分类的
类:分类的队列规定可以拥有很多类,类内包含队列规定
分类器:决定什么样的包使用什么类进行发送
过滤器:分类是通过过滤器完成的
调度:使用分类器可以让某些数据包插队发送
整形:在一个数据包发送之前进行适当的延迟,以免超过事先规定好的最大速率,这种处理叫做“整形”。整形在 egress 处进行。习惯上,通过丢包来降速也经常被称为整形。
策略:通过延迟或是丢弃数据包来保证流量不超过事先规定的带宽。 linux中不存在Ingress队列
无类队列:可以接受数据并重新编排、丢弃或者延迟数据包,这里的操作是对网络的整体流量做处理,不会细分具体的类型,网卡默认的缺省队列是pfifo_fast
pfifo_fast:先进先出(FIFO)

原理:有三个频道 0 1 2 ,FIFO会应用到每个频道中。优先级是:如果0频道中有包发送,1中的包就会等待,2和1的优先级同0和1的一样
参数: 无法配置,队列的长度以来与网卡的配置,配置方法:ifconfig eth0 txqueuelen 10
优先级: 数据包的优先级依赖于包中的TOS字节
TBF:令牌桶过滤器(TBF)
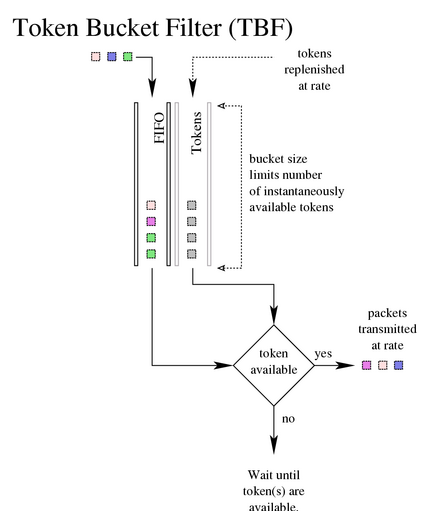
只允许以不超过事先设定的速率的数据包通过,但允许短暂突发流量朝过设定值
原理:实现一个缓冲器(桶), 不断地被一些叫做“令牌”的虚拟数据以特定速率填充着。桶最重要的参数就是它的大小,也就是它能够存储令牌的数量。每个来的令牌从数据队列中收集一个数据包, 然后从桶中被删除
令牌流和数据流:
数据流=令牌流的速率:每个到来的数据包都能对应一个令牌,然后无延迟地通过队列
数据流<令牌流的速率:令牌会在桶里积累下来直到桶被装满,剩下的令牌可以在发送数据流>令牌流速率的时候消耗掉,这种情况下会发生突发传输。
数据流>令牌流的速率:令牌耗尽,后续数据包如果继续接收,就会发生丢包
注意点: 1、实际的实现是对于字节数的
2、积累令牌可以使短时间的突发越限数据传输不丢包
参数:
limit/latency limit 确定最多有多少数据在队列中等待可用令牌。
latency 参数确定了一个包在TBF中等待传输的最长等待时间。用来计算决定桶的大小、速率和峰值速率。
burst/buffer/maxburst 桶的大小,指定最多可以有多少个令牌能够立刻使用
mpu(Minimum Packet Unit,最小分组单位):决定令牌的最低消耗
rate :令牌的产生速率
peakrate:用来控制峰值速率,指定令牌以多快的速度被删除
mtu/minburst:指定peakrate桶的大小。
配置: tc qdisc add dev eth0 root tbf rate 2000kbit latency 50ms burst 1540
SFQ:随机公平队列
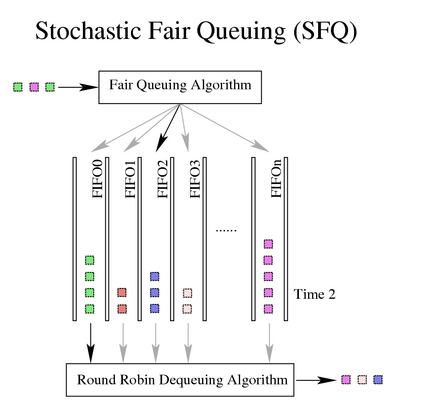
原理:针对一个TCP会话或者UDP流,流量给分到多个FIFO队列中,每个队列对应一个会话
使用散列算法,把所有的会话映射到有限的几个队列中去,所以可能多个会话分配在同一个队列里,从而需要共享共享带宽。SFQ 会频繁地改变散列算法
注意点:只有带宽满了才会起作用
参数:
perturb 重置散列算法的间隔时间
quantum 一个流最少要传输多少字节后才切换到下一个队列,默认是一个MTU的大小,如果设置这个数值不要小于MTU
配置: tc qdisc add dev eth0 root sfq perturb 10
分类队列:多种数据流需要进行区别对待
队列规定和类中数据流向:
数据包进入分类队列规定,会被送到某一个类中,对数据包进行分类的工具是过滤器,“分类器”是从队列规定内部调用的,队列规定就根据这个过滤器的决定把数据包送入相应的类进行排队,每个子类都可以再次使用它们的过滤器进行进一步的分类
根、句柄、兄弟和父辈:
根:网卡会有一个默认的 "根队列规定",缺省的队列规定是 pfifo_fast,每个队列规定会指向一个句柄,这是为后面的配置语句提供引用使用的
句柄:
主号码:根队列主号码默认为1: 等价于1:0
次号码:队列的次号码为0
类的主号码需要和父的主号码一致
数据包分类的链状图
1: -> 1:1 -> 12: -> 12:2
PRIO队列:
原理:不进行整形,依据过滤器把流量细分,和pfifo_fast的区别是每个频道都是一个单独的类,默认缺省是三个类,数据包进入PRIO队列后悔根据过滤器的设置选择一个类,优先处理标号为1的类中的数据包
参数:
bands:频道数量,每个频道代表一个类
priomap : PRIO队列默认参考TC_PRIO的优先级决定如何给数据包入队
注意: 0 频道的次标号是 1 1 频道的次标号是 2
配置:
# tc qdisc add dev eth0 root handle 1: prio
## 这个命令立即创建了类: 1:1, 1:2, 1:3
# tc qdisc add dev eth0 parent 1:1 handle 10: sfq
# tc qdisc add dev eth0 parent 1:2 handle 20: tbf rate 20kbit buffer 1600 limit 3000
# tc qdisc add dev eth0 parent 1:3 handle 30: sfq
CBQ:
原理:如果你试图把一个10Mbps的连接整形成1Mbps的速率,需要让链路90%的时间处于闲置状态,CBQ测量闲置时间根据 “来自硬件层的两个传输请求之间的毫秒数”来判断,硬件不同,造成结果也会有区别
参数:
avpkt: 平均包大小
bandwidth: 网卡的物理带宽
cell:一个数据包被发送出去的时间可以是基于包长度而阶梯增长的,需要设置为2的整数次幂
maxburst: 这个参数的值决定了计算 maxidle 所使用的数据包的个数。在avgidle跌落到0之前,这么多的数据包可以突发传输出去。 这个值越高,越能够容纳突发传输。无法直接设置 maxidle 的值,必须通过这个参数来控制。
minburst:minburst 值越大,整形越精确
minidle:如果 avgidle 值降到 0,也就是发生了越限,就需要等待,直到 avgidle 的值足够大才发送数据包。
mpu:最小包的尺寸
rate:预期的传输速率
CBQ可以将类赋予不同的优先级,优先级越小的类会被优先处理,下面是CBQ的WRR(加权)的参数:
allot:请求一个 CBQ 发包的时候,它就会按照“priority”参数指定的顺序轮流尝试其内部的每一个类的队列规定。 当轮到一个类发数据时, 它只能发送一定量的数据。“allot”参数就是这个量的基值
priority:prio值较低的类只要有数据就会被优先处理
weight:控制 WRR 过程。每个类都轮流取得发包的机会
链路共享和借用的参数:
Isolated/sharing: Ioslated是不会借用带宽出去,sharing相反
bounded/borrow :同Isolated/sharing
如果一个类设置为Isolated或者bounded,这个类的子类允许相互借用带宽
HTB:分层的令牌桶
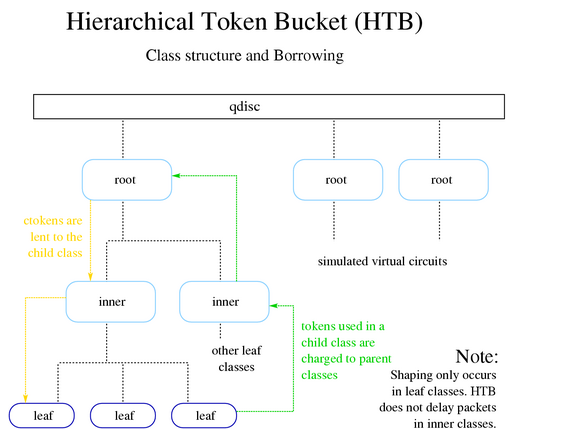
原理:CBQ过于复杂,HTB适用与一个固定速率的链路,需要将其分为多种不同用途并为每种不同用途分配不同带宽而且要实现带宽借用
配置:
一个生产中的例子:
共三台服务器,A B C , B通过eth1网卡和A C两台服务器交互数据,要求到A方向的带宽为100M,到C方向的带宽为50M
备注:1.1.1.1 是服务器A的地址
tc qdisc add dev eth1 root handle 1: htb
tc class add dev eth1 parent 1: classid 1:1 htb rate 150mbit
tc class add dev eth1 parent 1:1 classid 1:10 htb rate 100mbit
tc class add dev eth1 parent 1:1 classid 1:20 htb rate 50mbit
tc qdisc add dev eth1 parent 1:10 handle 10: sfq
tc qdisc add dev eth1 parent 1:20 handle 20: sfq
U32="tc filter add dev eth1 protocol ip parent 1:0 prio 1 u32"
$U32 match ip dst 1.1.1.1/32 flowid 1:10
$U32 match ip dst all flowid 1:20
过滤器:
为了决定用哪个类处理数据包,必须调用所谓的“分类器链” 进行选择。这个链中包含了这个分类队列规定所需的所有过滤器。
u32匹配:可以匹配到数据包的任意部分
根据源/目的地址,单个 IP 地址使用“/32”作为掩码即可。
根据源/目的端口,所有 IP 协议
根据 IP 协议 (tcp, udp, icmp, gre, ipsec) 使用/etc/protocols 所指定的数字。比如: icmp 是 1: 'match ip protocol 1 0xff'.
也可以使用 iptables 给数据包做上标记,这样就不需要用tc的语法了
iptables -A PREROUTING -t mangle -i eth0 -j MARK --set-mark 6
按 TOS 字段

