



机器学习--判别式模型与生成式模型
一、引言
本材料参考Andrew Ng大神的机器学习课程 http://cs229.stanford.edu
在上一篇有监督学习回归模型中,我们利用训练集直接对条件概率p(y|x;θ)建模,例如logistic回归就利用hθ(x) = g(θTx)对p(y|x;θ)建模(其中g(z)是sigmoid函数)。假设现在有一个分类问题,要根据一些动物的特征来区分大象(y = 1)和狗(y = 0)。给定这样的一种数据集,回归模型比如logistic回归会试图找到一条直线也就是决策边界,来区分大象与狗这两类,然后对于新来的样本,回归模型会根据这个新样本的特征计算这个样本会落在决策边界的哪一边,从而得到相应的分类结果。
现在我们考虑另外一种建模方式:首先,根据训练集中的大象样本,我们可以建立大象模型,根据训练集中的狗样本,我们可以建立狗模型。然后,对于新来的动物样本,我们可以让它与大象模型匹配看概率有多少,与狗模型匹配看概率有多少,哪一个概率大就是那个分类。
判别式模型(Discriminative Model)是直接对条件概率p(y|x;θ)建模。常见的判别式模型有 线性回归模型、线性判别分析、支持向量机SVM、神经网络等。
生成式模型(Generative Model)则会对x和y的联合分布p(x,y)建模,然后通过贝叶斯公式来求得p(yi|x),然后选取使得p(yi|x)最大的yi,即:

常见的生成式模型有 隐马尔可夫模型HMM、朴素贝叶斯模型、高斯混合模型GMM、LDA等。
二、高斯判别分析 Gaussian Discriminant Analysis
高斯判别分析GDA是一种生成式模型,在GDA中,假设p(x|y)满足多值正态分布。多值正态分布介绍如下:
2.1 多值正态分布 multivariate normal distribution
一个n维的多值正态分布可以表示为多变量高斯分布,其参数为均值向量![]() ,协方差矩阵
,协方差矩阵![]() ,其概率密度表示为:
,其概率密度表示为:
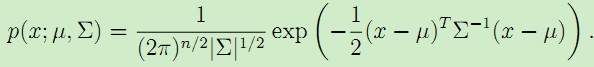
当均值向量为2维时概率密度的直观表示:
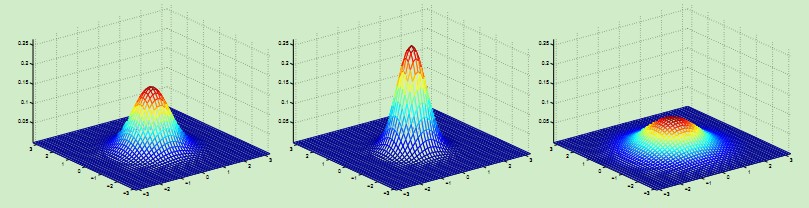
左边的图表示均值为0,协方差矩阵∑ = I;中间的图表示均值为0,协方差矩阵∑ = 0.6I;右边的图表示均值为0,协方差矩阵∑ = 2I。可以观察到,协方差矩阵越大,概率分布越扁平;协方差矩阵越小,概率分布越高尖。
2.2 高斯判别分析模型
如果有一个分类问题,其训练集的输入特征x是随机的连续值,就可以利用高斯判别分析。可以假设p(x|y)满足多值正态分布,即:
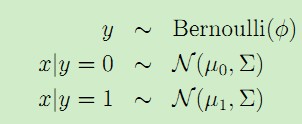
该模型的概率分布公式为:
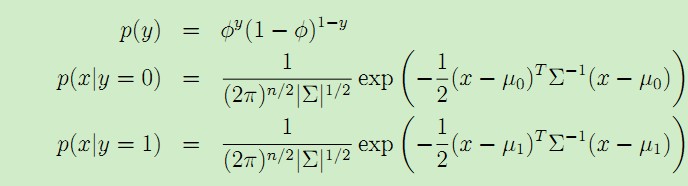
模型中的参数为Φ,Σ,μ0和μ1。于是似然函数(x和y的联合分布)为:

其中Φ是y = 1的概率,Σ是协方差矩阵,μ0是y = 0对应的特征向量x的均值 , μ1是y = 1对应的特征向量x的均值,于是得到它们的计算公式如下:
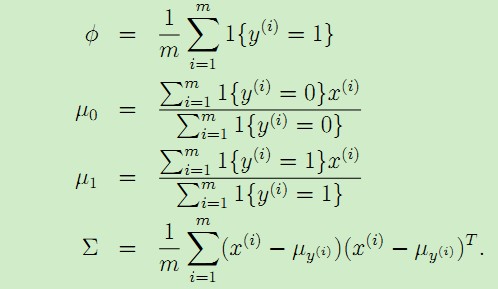
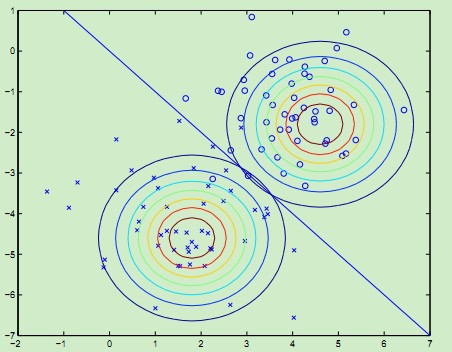
于是这样就可以对p(x,y)建模,从而得到概率p(y = 0|x)与p(y = 1|x),从而得到分类标签。其结果如下图所示:
三、朴素贝叶斯模型
在高斯判别分析GDA中,特征向量x是连续实数值,如果特征向量x是离散值,可以利用朴素贝叶斯模型。
3.1 垃圾邮件分类
假设我们有一个已被标记为是否是垃圾邮件的数据集,要建立一个垃圾邮件分类器。用一种简单的方式来描述邮件的特征,有一本词典,如果邮件包含词典中的第i个词,则设xi = 1,如果没有这个词,则设xi = 0,最后会形成这样的特征向量x:

这个特征向量表示邮件包含单词"a"和单词"buy",但是不包含单词"aardvark,"aardwolf","zygmurgy"。特征向量x的维数等于字典的大小。假设字典中有5000个单词,那么特征向量x就为5000维的包含0/1的向量,如果我们建立多项式分布模型,那么有25000中输出结果,这就意味着有接近25000个参数,这么多的参数,要建模很困难。
因此为了建模p(x|y),必须做出强约束假设,这里假设对于给定的y,特征x是条件独立的,这个假设条件称为朴素贝叶斯假设,得到的模型称为朴素贝叶斯模型。比如,如果y= 1表示垃圾邮件,其中包含单词200 "buy",以及单词300 "price",那么我们假设此时单词200 "buy" x200、单词300"price"x300 是条件独立的,可以表示为p(x200|y) = p(x200|y,x300)。注意,这个假设与x200与x300独立是不同的,x200与x300独立可以写作:p(x200) = p(x200|x300);这个假设是对于给定的y,x200与x300是条件独立的。
因此,利用上述假设,根据链式法则得到:
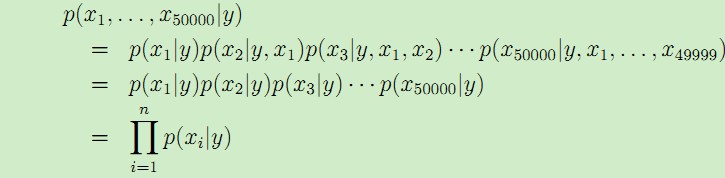
该模型有3个参数:
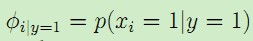 ,
, 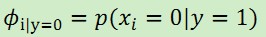 ,
, 
那么。根据生成式模型的规则,我们要使联合概率最大:

根据这3个参数意义,可以得到它们各自的计算公式:
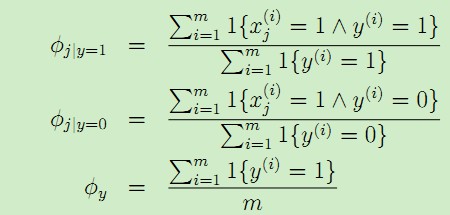
这样就得到了朴素贝叶斯模型的完整模型。对于新来的邮件特征向量x,可以计算:

实际上只要比较分子就行了,分母对于y = 0和y = 1是一样的,这时只要比较p(y = 0|x)与p(y = 1|x)哪个大就可以确定邮件是否是垃圾邮件。
3.2 拉普拉斯平滑
朴素贝叶斯模型可以在大部分情况下工作良好。但是该模型有一个缺点:对数据稀疏问题敏感。
比如在邮件分类中,对于低年级的研究生,NIPS显得太过于高大上,邮件中可能没有出现过,现在新来了一个邮件"NIPS call for papers",假设NIPS这个词在词典中的位置为35000,然而NIPS这个词从来没有在训练数据中出现过,这是第一次出现NIPS,于是算概率时:
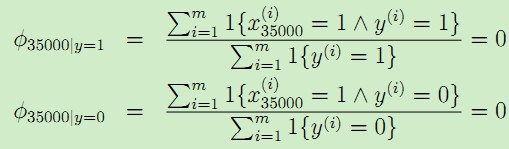
由于NIPS从未在垃圾邮件和正常邮件中出现过,所以结果只能是0了。于是最后的后验概率:
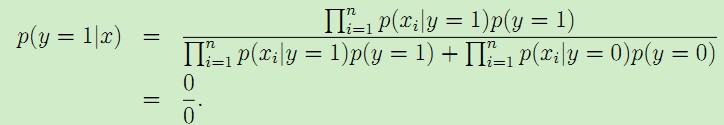
对于这样的情况,我们可以采用拉普拉斯平滑,对于未出现的特征,我们赋予一个小的值而不是0。具体平滑方法为:
假设离散随机变量取值为{1,2,···,k},原来的估计公式为:

使用拉普拉斯平滑后,新的估计公式为:
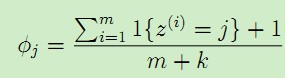
即每个k值出现次数加1,分母总的加k,类似于NLP中的平滑,具体参考宗成庆老师的《统计自然语言处理》一书。
对于上述的朴素贝叶斯模型,参数计算公式改为:
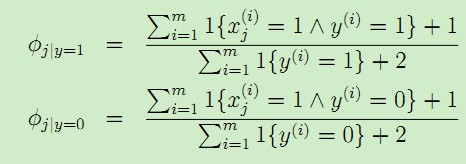


 浙公网安备 33010602011771号
浙公网安备 33010602011771号