
论文笔记 Pyramid Scene Parsing Network
Background
1)Scene parsing:给输入的图像的每一个像素赋予一个类别标签。即在pixel集合与category label集合之间建立影射关系。如果category label数目多、pixel变化大,则对应的scene parsing任务难。ADE20K数据集:category label数目较多、场景复杂(pixel变化大),因此,对其进行scene parsing较难!
2)复杂场景scene parsing存在的问题,如下图所示(FCN是作者选取的Baseline,PSPNet是作者提出的网络)
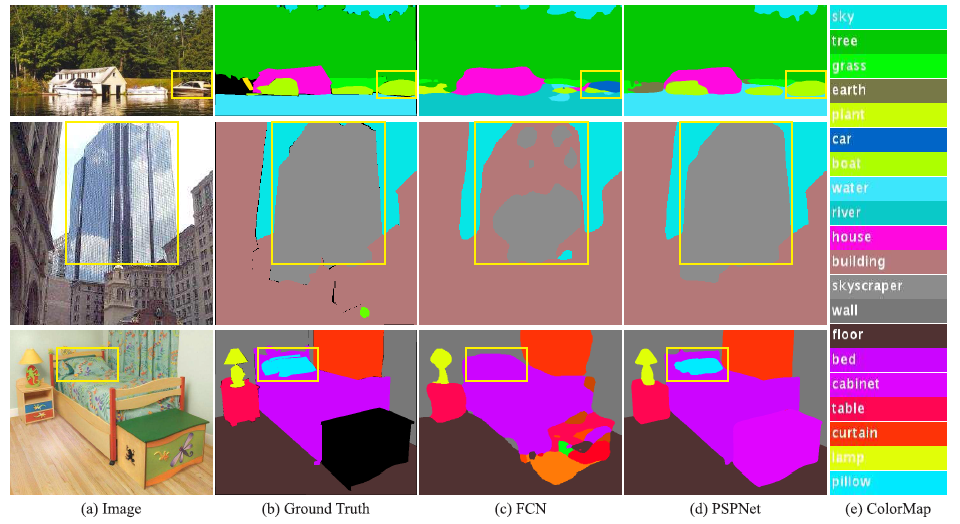
“There exist co-occurrent visual pattern”,例如“飞机要么在天上飞或者跑到上”、“car很少会出现在水面上”。上图第一行中的boat被FCN误标记为car。因此,引入上下文信息能够在一定程度上避免“误识别”。
“There are many class label pairs in the ADE20K dataset that are confusing in classification. Examples are field and earth; mountain and hill; wall, house, building and skyscraper”,在上图第二行我们可看出,FCN输出中,building中有Skyscraper,Skyscraper中有building。我们期望一个物体属于一个类别,而不是两个类别的组合,这可以通过类别之间的关系缓解。
上图第三行中,FCN将pillow误识别为sheet,这是由于pillow与sheet外观很相似,如果“Overlooking the global scene category may fail to parse the pillow”。为了提升小物体或者大物体的准确率,不同尺度的sub-regions是必须的。
为了获取global contextual prior、sub-regions contextual prior作者提出了Pyramid pooling module。
Main points
1)Pyramid pooling module

(c)中红色部分代表global pooling,捕获的是 global contextual prior。2x2、3x3、6x6捕获的是不同尺度sub-regions contextual prior(也隐含捕获了不同类别直接的关系)。
2)网络结构选择
作者选取了pre-trained ResNet model with the dilated network strategy。也实验了不同深度的ResNet(实验发现,ResNet越深越好)。
3)Deep Supervision for ResNet-Based FCN
网络越深性能越好,但是也越难训练。“ResNet solves this problem with skip connection in each block”。作者在网络中间引入了一个额外的loss函数,这个loss函数和网络输出层的loss pass through all previous layers,图示如下

4)实验
作者在实验部分详述了solver的细节,在ADE20K、PASCAL VOC 2012、Cityscapes数据集上测试了算法的性能。
Summary
1)作者分析了不同尺度上下文信息的重要性,据此提出了Pyramid pooling module。一点体会,“有需求,然后将需求转化为网络结构”。当然了,转化为网络结构时可以充分利用现有的结构。
2)引入了additional loss假设ResNet的训练,这种思想其实已经有了。
3)有了网络结构之外,其实下面的难点就是实验细节的处理,正如论文中所言“For a practical deep learning system, devil is always in the details”。我自己最近调实验的一个深切体会就是,idea很好产生,但是idea如何通过实验转化为一个不错的效果很难!这里面涉及到很多实验细节的处理问题!最好就是,我们有一个调整实验参数的基本原则或者思想,乱调试不行的哦!哈哈
posted on 2017-07-03 17:56 everyday_haoguo 阅读(3429) 评论(0) 编辑 收藏 举报
