

hadoop的安装和配置(三)完全分布式模式
博主会用三篇文章为大家详细说明hadoop的三种模式:
完全分布模式
完全分布式模式:
前面已经说了本地模式和伪分布模式,这两种在hadoop的应用中并不用于实际,因为几乎没人会将整个hadoop集群搭建在一台服务器上(hadoop主要是围绕:分布式计算和分布式存储,如果以一台服务器做,那就完全违背了hadoop的核心方法)。简单说,本地模式是hadoop的安装,伪分布模式是本地搭建hadoop的模拟环境。(当然实际上并不是这个样子的,小博主有机会给大家说!)
那么在hadoop的搭建,其实真正用于生产的就是完全分布式模式:
思路简介
域名解析
ssh免密登陆
java和hadoop环境
配置hadoop文件
复制主节点到其他节点
格式化主节点
hadoop搭建过程+简介
在搭建完全分布式前大家需要了解以下内容,以便于大家更好的了解hadoop环境:
1.hadoop的核心:分布式存储和分布式计算(用官方的说法就是HDFS和MapReduce)
2.集群结构:1+1+n 集群结构(主节点+备用节点+多个从节点)
3.域名解析:这里为了方便,我们选择修改/etc/hosts实现域名解析(hadoop会在.../etc/hadoop/salves下添加从节点,这里需要解析名,当然你也能直接输入ip地址,更简单)
4.hadoop的命令发放,需要从ssh接口登录到其他服务器上,所以需要配置ssh免密登陆
5.本文采取1+1+3 集群方式:域名为:s100(主),s10(备主),s1,s2,s3(从)
一:配置域名解析
主——s100:
[root@localhost ~]# vim /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.1.68 s100 192.168.1.108 s1 192.168.1.104 s2 192.168.1.198 s3 192.168.1.197 s10

将s100上的/etc/hosts拷贝到其他hadoop的集群服务器上。例如:
将s100的/etc/hosts拷贝到s1上
1 [root@localhost ~]# scp /etc/hosts root@192.168.1.108:/etc/hosts 2 The authenticity of host '192.168.1.108 (192.168.1.108)' can't be established. 3 RSA key fingerprint is dd:64:75:5f:96:11:07:39:a3:fb:aa:3c:30:ae:59:82. 4 Are you sure you want to continue connecting (yes/no)? yes 5 Warning: Permanently added '192.168.1.108' (RSA) to the list of known hosts. 6 root@192.168.1.108's password: 7 hosts 100% 246 0.2KB/s 00:00

将所有服务器的域名解析配置完成,进行下一步
二:配置ssh免密码登录
备注:考虑到有的小伙伴可能没有openssh-server(ssh服务)【百度一下帮大家搜索了一下,总结如下】——小博主是不是很暖呢?
Ubuntu等——ssh:sudo apt-get install openssh-server Redhat等——ssh:yum install openssh-server
主——s100:
ssh生成相应密钥对:id_rsa私钥和id_rsa.pub公钥
1 [root@localhost ~]# ssh-keygen -t rsa -P '' 2 Generating public/private rsa key pair. 3 Enter file in which to save the key (/root/.ssh/id_rsa): 4 Your identification has been saved in /root/.ssh/id_rsa. 5 Your public key has been saved in /root/.ssh/id_rsa.pub. 6 The key fingerprint is: 7 a4:6e:8d:31:66:e1:92:04:37:8e:1c:a5:83:5e:39:c5 root@localhost.localdomain 8 The key's randomart image is: 9 +--[ RSA 2048]----+ 10 | o.=. | 11 | o BoE | 12 |. =+o . . | 13 |. .o.o + | 14 | . o B S | 15 | = = | 16 | + . | 17 | . | 18 | | 19 +-----------------+ 20 [root@localhost ~]# cd /root/.ssh/ 21 [root@localhost .ssh]# ls 22 id_rsa id_rsa.pub known_hosts
默认是存在/当前user/.ssh(/root/.ssh或者/home/user/.ssh)下的!
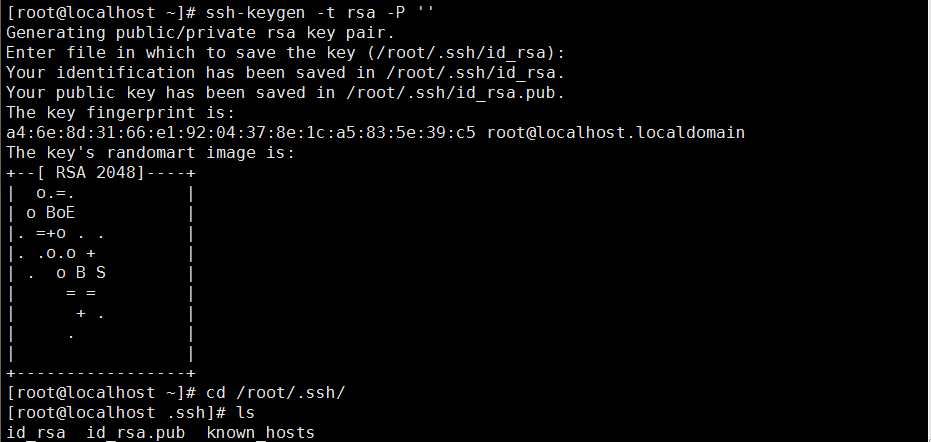
有了密钥对:将id_rsa.pub加到授权中:
1 [root@localhost .ssh]# cat id_rsa.pub >> authorized_keys(/root/.ssh下) 2 [root@localhost .ssh]# ls 3 authorized_keys id_rsa id_rsa.pub known_hosts

备注:
authorized_keys的权限可能会限制免密登陆
试一下是否本地免密登陆设置成功:
1 [root@localhost .ssh]# ssh localhost 2 The authenticity of host 'localhost (::1)' can't be established. 3 RSA key fingerprint is 9e:e0:91:0f:1f:98:af:1a:83:5d:33:06:03:8a:39:93. 4 Are you sure you want to continue connecting (yes/no)? yes(第一次登陆需要确定) 5 Warning: Permanently added 'localhost' (RSA) to the list of known hosts. 6 Last login: Tue Dec 26 19:09:23 2017 from 192.168.1.156 7 [root@localhost ~]# exit 8 logout 9 Connection to localhost closed.
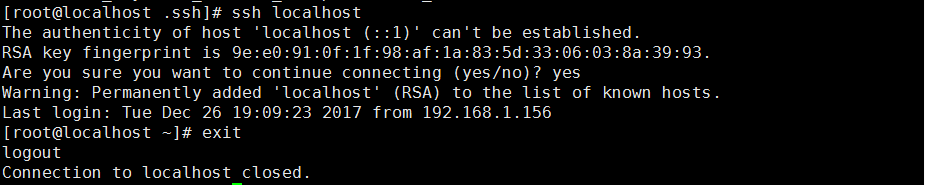
ok!没有问题,那么配置其他服务器,其实只需要把本机s100的id_rsa.pub复制到其他服务器上就可以了!
这里就选择ssh-copy-id命令传送到其他服务器上(小博主这可不是偷懒!有命令就应该拿过来!)
1 [root@localhost .ssh]# ssh-copy-id root@s1(s1是主机地址,这里提醒大家一下,因为有人因为这个问题问过我╭(╯^╰)╮) 2 The authenticity of host 's1 (192.168.1.108)' can't be established. 3 RSA key fingerprint is dd:64:75:5f:96:11:07:39:a3:fb:aa:3c:30:ae:59:82. 4 Are you sure you want to continue connecting (yes/no)? yes 5 Warning: Permanently added 's1' (RSA) to the list of known hosts. 6 root@s1's password: 7 Now try logging into the machine, with "ssh 'root@s1'", and check in: 8 9 .ssh/authorized_keys 10 11 to make sure we haven't added extra keys that you weren't expecting.

登录了一下,没有问题
1 [root@localhost .ssh]# ssh s1 2 Last login: Wed Dec 27 18:50:12 2017 from 192.168.1.156
将剩余的配置完成!
有对于ssh免密登陆不清楚的小伙伴请移步下面的链接:
主节点
三:配置java环境和安装hadoop(hadoop环境)
备注:这里小伙伴必须要知道的是,不管hadoop的主节点还是从节点甚至说备主节点,他们的java环境和hadoop环境都一样,所以我们只需要配置完一台服务器,就完成了所有的配置过程
因为完全分布模式也是在本地模式的基础上配置的,所以我们首先配置本地模式:
完全分布式模式 = 本地模式 + 配置文件
java环境和hadoop的安装等过程就是前面所说的本地模式了,这里就不多说了:
四:配置内容:
备注:对于配置文件以后会有时间会单独写一篇相关的文档
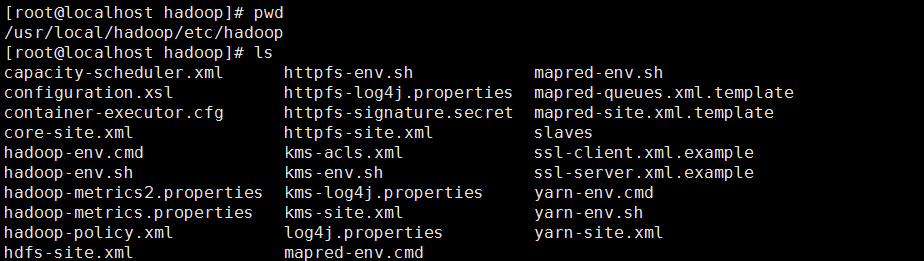
主要修改以下五个文件:
1 hadoop的配置文件:/usr/local/hadoop/etc/hadoop 2 [root@localhost hadoop]# cd /usr/local/hadoop/etc/hadoop 3 [root@localhost hadoop]# ls 4 core-site.xml 5 hdfs-site.xml 6 mapred-site.xml 7 yarn-site.xml4 8 slaves
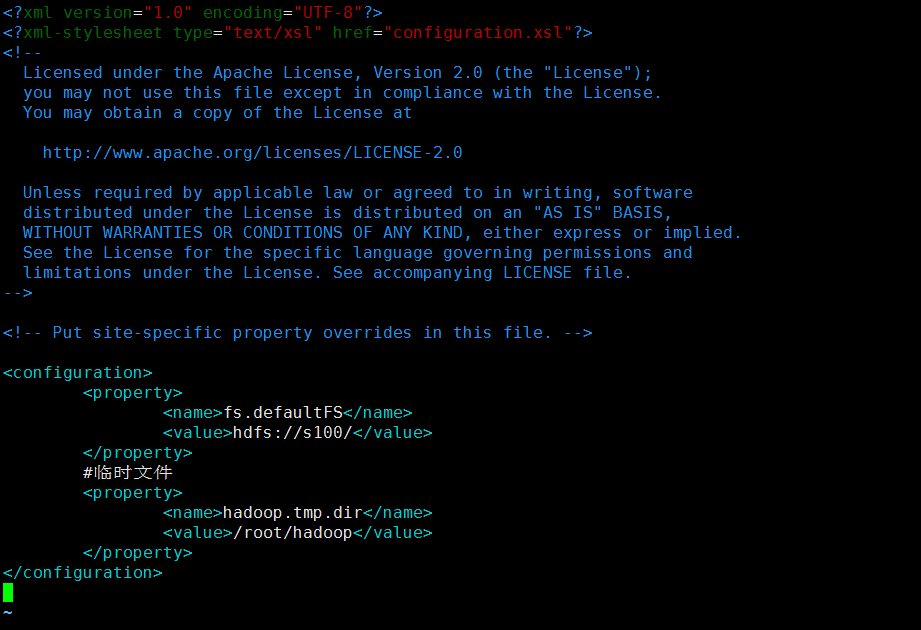
配置 core-site.xml:
主要:指定主节点
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://s100/</value> </property> #临时文件 <property> <name>hadoop.tmp.dir</name> <value>/root/hadoop</value> </property> </configuration>
配置hdfs-site.xml:
主要:指定备份数量
<configuration> #默认备份数为3,如果采取默认数,那么slaves不能少于备份数 <property> <name>dfs.replication</name> <value>2</value>#备份数 </property> #备主 <property> <name>dfs.namenode.secondary.http-address</name> <value>s10:50000</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:///${hadoop.tmp.dir}/dfs/name</value> </property> </configuration>
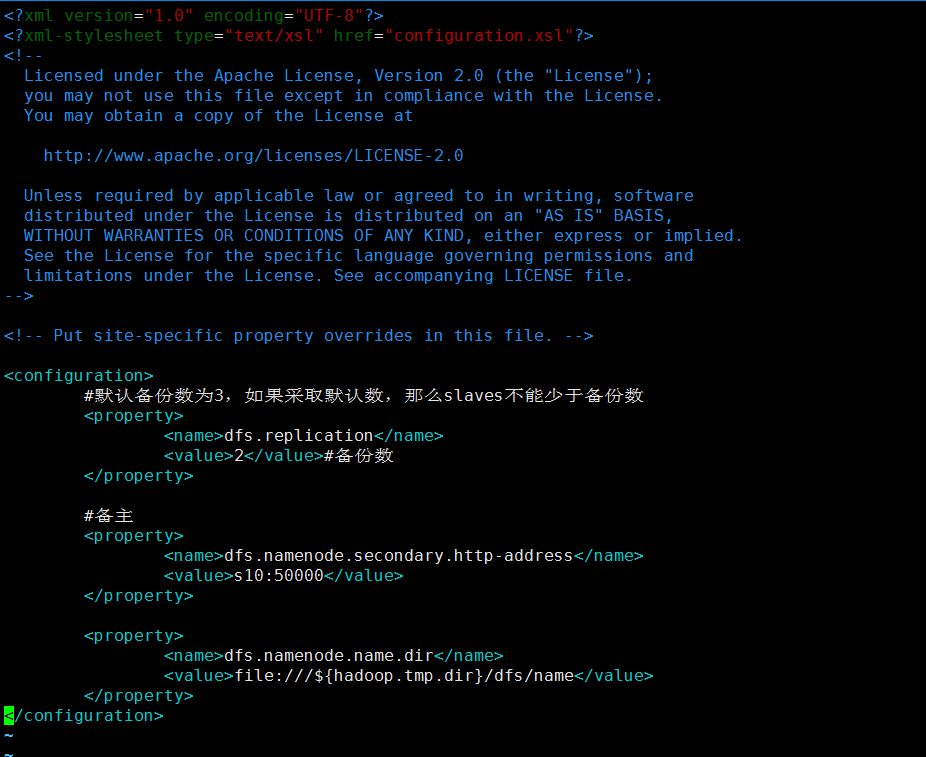
配置mapred-site.xml:
主要:指定资源管理yran方法
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
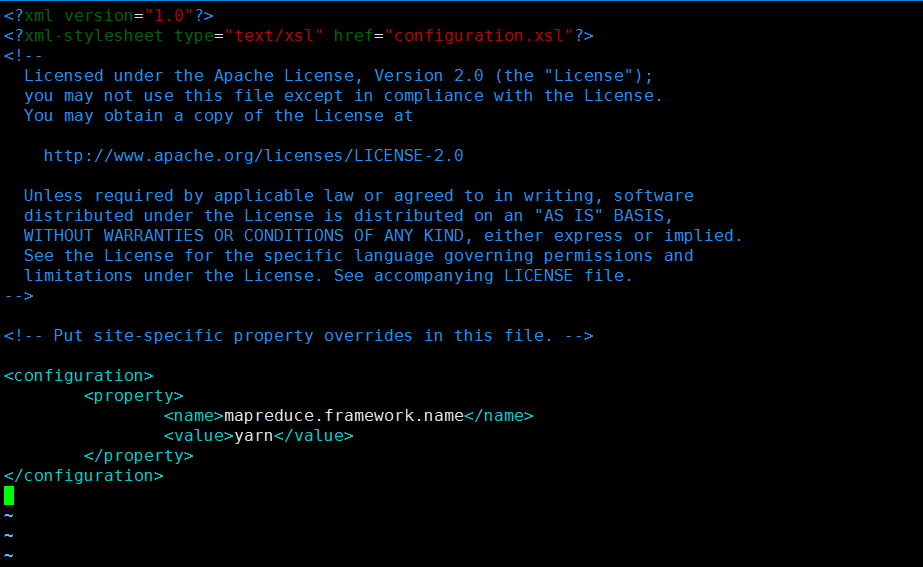
配置yarn-site.xml:
<configuration> <property> <name>yarn.resourcemanager.hostname</name> <value>s100</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
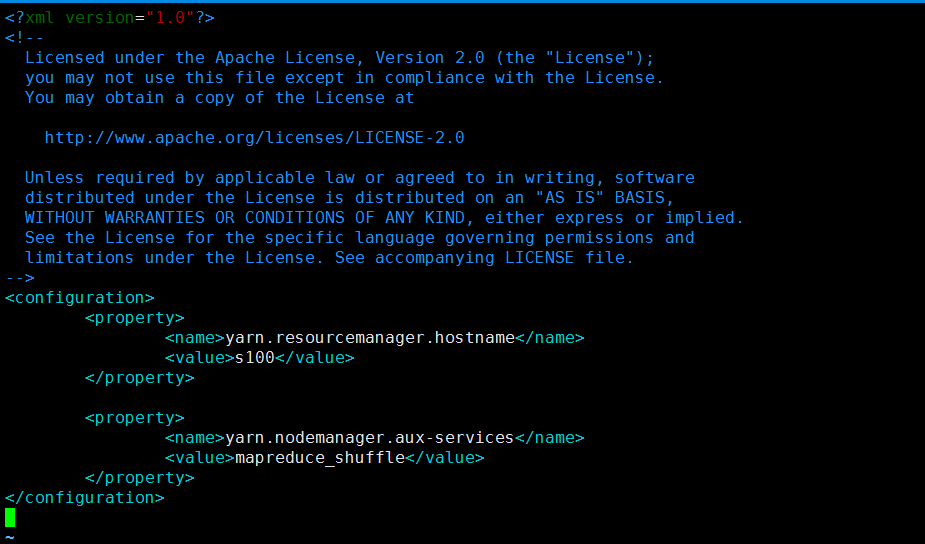
配置slaves:
s1 s2 s3

五:scp-java环境和hadoop配置文件(hadoop环境)
做到这里,基本就完成了,现在就把主节点的所以配置都放到从节点上!
1 [root@localhost ~]# scp -r /usr/local/java root@s1:/usr/local/
复制java
1 scp -r /usr/local/hadoop root@s1:/usr/local/
复制hadoop
1 [root@localhost ~]# scp /etc/profile root@s1:/etc/profile
环境变量
登录到s1中执行source
1 [root@localhost ~]# ssh s1 2 Last login: Wed Dec 27 23:18:48 2017 from s100 3 [root@localhost ~]# source /etc/profile
s1配置完成,其他的服务器一样!
六:格式化主节点
1 [root@localhost ~]# hadoop namenode -format
启动hadoop:
start-all.sh
关闭hadoop:
stop-all.sh
jps查询进程信息
主节点:
1 [root@localhost ~]# jps 2 30996 Jps 3 30645 NameNode 4 30917 ResourceManager
2主节点:
1 [root@localhost ~]# jps 2 33571 Jps 3 33533 SecondaryNameNode
从节点:
1 [root@localhost ~]# jps 2 33720 Jps 3 33691 NodeManager 4 33630 DataNode
本文版权声明:
本文作者:魁·帝小仙
博文主页地址:http://www.cnblogs.com/dxxblog/
欢迎对小博主的博客内容批评指点,如果问题,可评论或邮件联系(2335228250@qq.com)
欢迎转载,转载请在文章页面明显位置给出原文链接,谢谢

 浙公网安备 33010602011771号
浙公网安备 33010602011771号