

Bloom Filter(布隆过滤器)的概念和原理
目录
- 引子
-
布隆过滤器介绍
- 产生的契机
- 设计思想
- 优缺点与用途
- 假阳性率的计算
- Guava中的布隆过滤器
- redis实现布隆过滤器
- 总结
引子
最近在研究推荐系统中已读内容排除以及重复内容去重相关的问题,布隆过滤器是解决这类问题最好的工具之一,很值得专门写一篇文章来详细讲解。
在缓存穿透的场景中,解决方法:
第一种是缓存层缓存空值 将数据库中的空值也缓存到缓存层中,这样查询该空值就不会再访问DB,而是直接在缓存层访问就行。 但是这样有个弊端就是缓存太多空值占用了更多的空间,可以通过给缓存层空值设立一个较短的过期时间来解决,例如60s。
第二种是布隆过滤器 将数据库中所有的查询条件,放入布隆过滤器中, 当一个查询请求过来时,先经过布隆过滤器进行查,如果判断请求查询值存在,则继续查;如果判断请求查询不存在,直接丢弃。
布隆过滤器介绍
布隆过滤器(Bloom Filter,下文简称BF)由Burton Howard Bloom在1970年提出,是一种空间效率高的概率型数据结构。它专门用来检测集合中是否存在特定的元素。听起来是很稀松平常的需求,为什么要使用BF这种数据结构呢?
产生的契机
回想一下,我们平常在检测集合中是否存在某元素时,都会采用比较的方法。考虑以下情况:
- 如果集合用线性表存储,查找的时间复杂度为O(n)。
- 如果用平衡BST(如AVL树、红黑树)存储,时间复杂度为O(logn)。
-
如果用哈希表存储,并用链地址法与平衡BST解决哈希冲突(参考JDK8的HashMap实现方法),时间复杂度也要有O[log(n/m)],m为哈希分桶数。
总而言之,当集合中元素的数量极多时,不仅查找会变得很慢,而且占用的空间也会大到无法想象。BF就是解决这个矛盾的利器。
设计思想
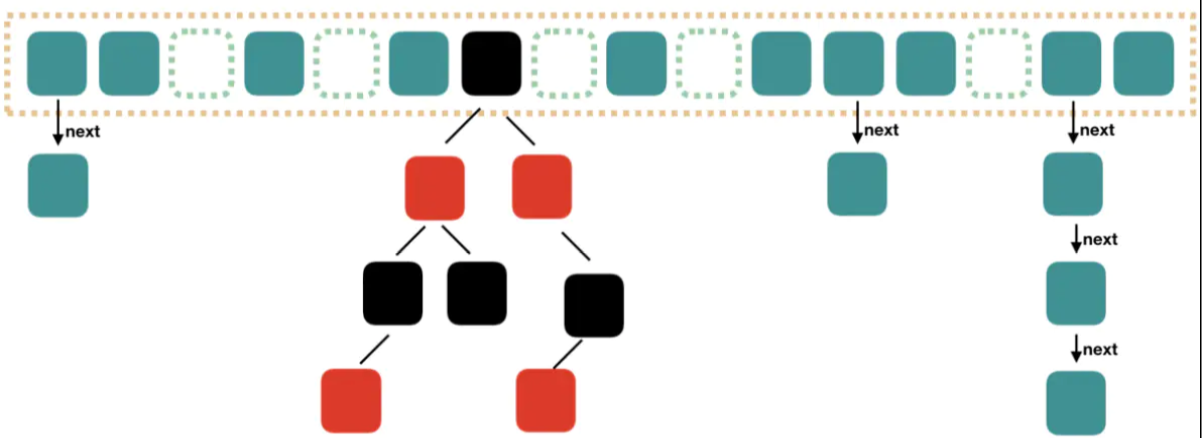
BF是由一个长度为m比特的位数组(bit array)与k个哈希函数(hash function)组成的数据结构。位数组均初始化为0,所有哈希函数都可以分别把输入数据尽量均匀地散列。
1、添加数据
当要插入一个元素时,将其数据分别输入k个哈希函数,产生k个哈希值。以哈希值作为位数组中的下标,将所有k个对应的比特置为1。
比如,下图hash1(x)=1,那么在第2个格子将0变为1(数组是从0开始计数的),hash2(x)=4,那么将第5个格子置位1,hash3(x)=12,那么将第13个格子置位1,依次类推。
2、判断时间是否存在?
知道了如何向布隆过滤器中添加一个数据,那么新来一个数据,我们如何判断其是否存在于这个布隆过滤器中呢?
很简单,我们只需要将这个新的数据通过上面自定义的几个哈希函数,分别算出各个值,然后看其对应的地方是否都是1,如果存在一个不是1的情况,那么我们可以说,该新数据一定不存在于这个布隆过滤器中。
反过来说,如果通过哈希函数算出来的值,对应的地方都是1,那么我们能够肯定的得出:这个数据一定存在于这个布隆过滤器中吗?
答案是否定的,因为多个不同的数据通过hash函数算出来的结果是会有重复的,所以会存在某个位置是别的数据通过hash函数置为的1。----“假阳性”(false positive)
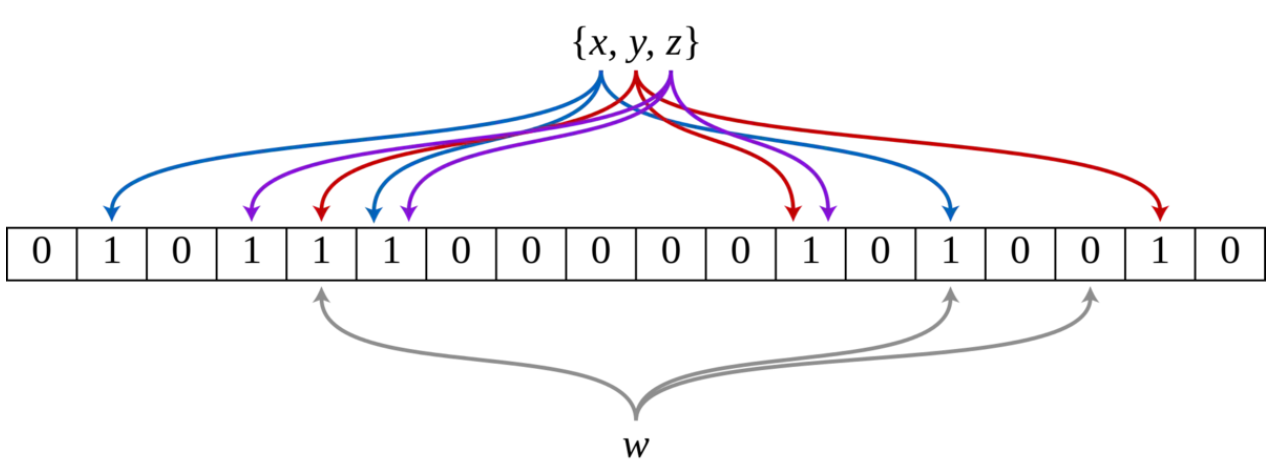
即:当要查询(即判断是否存在)一个元素时,同样将其数据输入哈希函数,然后检查对应的k个比特。如果有任意一个比特为0,表明该元素一定不在集合中。如果所有比特均为1,表明该集合有(较大的)可能性在集合中。为什么不是一定在集合中呢?因为一个比特被置为1有可能会受到其他元素的影响,这就是所谓“假阳性”(false positive)。相对地,“假阴性”(false negative)在BF中是绝不会出现的。
下图示出一个m=18, k=3的BF示例。集合中的x、y、z三个元素通过3个不同的哈希函数散列到位数组中。当查询元素w时,因为有一个比特为0,因此w不在该集合中。
优缺点与用途
BF的优点是显而易见的:
- 不需要存储数据本身,只用比特表示,因此空间占用相对于传统方式有巨大的优势,并且能够保密数据;
- 时间效率也较高,插入和查询的时间复杂度均为O(k);
- 哈希函数之间相互独立,可以在硬件指令层面并行计算。
但是,它的缺点也同样明显:
- 存在假阳性的概率,不适用于任何要求100%准确率的情境;
- 只能插入和查询元素,不能删除元素,这与产生假阳性的原因是相同的。我们可以简单地想到通过计数(即将一个比特扩展为计数值)来记录元素数,但仍然无法保证删除的元素一定在集合中。
所以,BF在对查准度要求没有那么苛刻,而对时间、空间效率要求较高的场合非常合适,本文第一句话提到的用途即属于此类。另外,由于它不存在假阴性问题,所以用作“不存在”逻辑的处理时有奇效,比如可以用来作为缓存系统(如Redis)的缓冲,防止缓存穿透。
假阳性率的计算
假阳性是BF最大的痛点,因此有必要权衡,比如计算一下假阳性的概率。为了简单一点,就假设我们的哈希函数选择位数组中的比特时,都是等概率的。当然在设计哈希函数时,也应该尽量满足均匀分布。
在位数组长度m的BF中插入一个元素,它的其中一个哈希函数会将某个特定的比特置为1。因此,在插入元素后,该比特仍然为0的概率是:




所以,在哈希函数的个数k一定的情况下:
- 位数组长度m越大,假阳性率越低;
- 已插入元素的个数n越大,假阳性率越高。
事实上,即使哈希函数不是等概率选择比特的,最终也会得出相同的结果,可以借助吾妻-霍夫丁不等式(Azuma-Hoeffding inequality)证明。
二、Bloomfilter实现
Bloom Filter 是一种多哈希函数映射的快速查找算法, 通常应用于大数据和高并发下的数据去重处理, 但是又不对准确率有严格的100%的正确率。
Bloom Filter过滤器的工作步骤为:
- 预设m 位长度的BitSet对象。
- 将去重对象经过K次hash,判断每次hash后的值在BitSet中对应索引位置的值是不是为1。
- 如果步骤2中每次获取的值都是1, 那么可以判定当前对象已经已经被存储过,可以被去重或者过滤。
2.1、参数设计
通过上面的描述, 相信大家对Bloom Filter有了大致的了解, 现在我们来列出下一个Bloom Filter需要的参数:
- 插入的的对象个数 n
- Bloom Filter 的误判率 P
- hash 函数的个数 K
- BitSet的位数 m
在实际的项目中, 欲插入的对象数目和误判率我们都可以预估和设定, 那么现在看来最重要的是如何设定m和k的值。对于上述参数的设定和评估, 都有计算公式:
2.2、误判率 P(true):
2.3、Hash 函数的个数 K:
求导之后:
2.4、BitArray数组的大小 m
通过联立误判率和hash 函数的k的两个公式可以得到:
通过上述公式可以求出:
有一些框架内已经内建了BF的实现,免去了自己实现的烦恼。下面以Guava为例,看看Google是怎么做的。
redis实现布隆过滤器
总结
本文讲解了布隆过滤器的产生、设计思路和应用场景,通过简单推导明确了其假阳性问题。另外,又通过阅读Guava中BloomFilter的相关源码,了解了设计布隆过滤器的技术要点。之后还会另外写文章讲述我们在生产环境中的具体应用。
转载:https://www.jianshu.com/p/bef2ec1c361f
https://www.jianshu.com/p/550278d10546
