
B树在数据库索引中的应用剖析
引言
关于数据库索引,google一个oracle index,mysql index总 有大量的结果,其中很多的使用方法推荐,**索引之n条经典建议云云。笔者认为,较之借鉴,在搞清楚了自己的需求的基础上,对备选方案的原理有个尽可能深 入全面的了解会更有利于我们的选择和决策。 因为某种方案或者技术呈现出某种优势(包括可能没有被介绍到的一定存在的限制),不是定义出来的,而是因为其实现机制决定的。就像LinkedList和 ArrayList分别适用于什么应用不是docment里面定义的,是由其本身的结构决定的。数据库的索引也是一样,不是厂商的文档这样规定,而是其原 理决定的。
本文只是重点介绍数据结构中最经典的树(B树)在数据库索引中最经典的的几种应用,也会涉及到几种数据库中对此支持的细微不同,以期比较完整的讲明 白其实现原理。最终会发现这几种被不同数据库厂商冠以不同名字东西原理上其实差不多,理论上其实是一个东西。本文只是略微空洞的介绍其实现,不涉及有任何 具体的使用建议。
关键字:B树 数据库索引 索引组织表(Index-Organized Tables) 聚集索引 非聚集索引 oracle mysql mssql
一、关于数据库索引
数据库索引的在维基中的定义:A database index is a data structure that improves the speed of data retrieval operations on a database table at the cost of additional writes and the use of more storage space to maintain the extra copy of data. Indexes are used to quickly locate data without having to search every row in a database table every time a database table is accessed. Indexes can be created using one or more columns of a database table, providing the basis for both rapid random lookups and efficient access of ordered records.
这个定义看上去挺长,就是为了对一个相对较大的数据结构访问快速方便,另外的存储了一个小的数据结构,依照某待检索个属性进行排序并且记录了该属性的记录在大的数据结构中的位置,以便快速的在大的数据结构中检索定位。如果index被翻译成目录可能更能抽象出其最本质的结构和作用。和其他很多计算机科学中的概念一样,index也是现实事物中的一种结构。由目录最容易想到的是图书馆的书籍管理,如果没有个目录,很难想象要从图书馆的那么多书架上找到一本书是多么困难的事情。
 当然映射的最好的是小时候厚厚的新华字典前面的目录,一般有两种,一种是拼音的,一种好像是笔画还是所谓的四角号码的。就是对于字典中数据根据两种属性不 同的索引。多出来的那么几十页纸(额外的存储)的好处就是帮助检索者快速定位到某个字典中某个字存储的页码。如果没有这个index,要查找字典的某个字 就只有来挨着翻页了(对应数据库索引的全表扫描full table scan)
当然映射的最好的是小时候厚厚的新华字典前面的目录,一般有两种,一种是拼音的,一种好像是笔画还是所谓的四角号码的。就是对于字典中数据根据两种属性不 同的索引。多出来的那么几十页纸(额外的存储)的好处就是帮助检索者快速定位到某个字典中某个字存储的页码。如果没有这个index,要查找字典的某个字 就只有来挨着翻页了(对应数据库索引的全表扫描full table scan)

(写完上文想着配个图,在google图片搜图片的时候搜到了这篇文章 ,直接摘录了,并为作者点个赞。我只是想做个数据库索引和字典索引的类别,作者居然做到了和B树索引的类别!)
二、关于B树索引
数据库中比较常用的索引结构有B树、 位图等。其中B树是几乎所有数据库的默认索引结构,也是用的最多的索引结构。
索引的基础作用是用于查找,数据结构的查找算法中最基本的是顺序查找,即从列表上逐个匹配是否找到关键字,其时间复杂度是O(n),当n比较大的时候是不能承受的。然后计算机科学提供的产找效率比较高的算法,即基于排序树的查找。B树(其实是B+ 树)是一种树数据结构,通常用于数据库和操作系统的文件系统中。特点是能够保持数据稳定有序,其插入与修改拥有较稳定的对数时间复杂度。 B+ 树的创造者 Rudolf Bayer 没有解释B代表什么。最常见的观点是B代表平衡(balanced),因为所有的叶子节点在树中都在相同的级别上。B也可能代表Bayer,或者是波音(Boeing),因为他曾经工作于波音科学研究实验室。
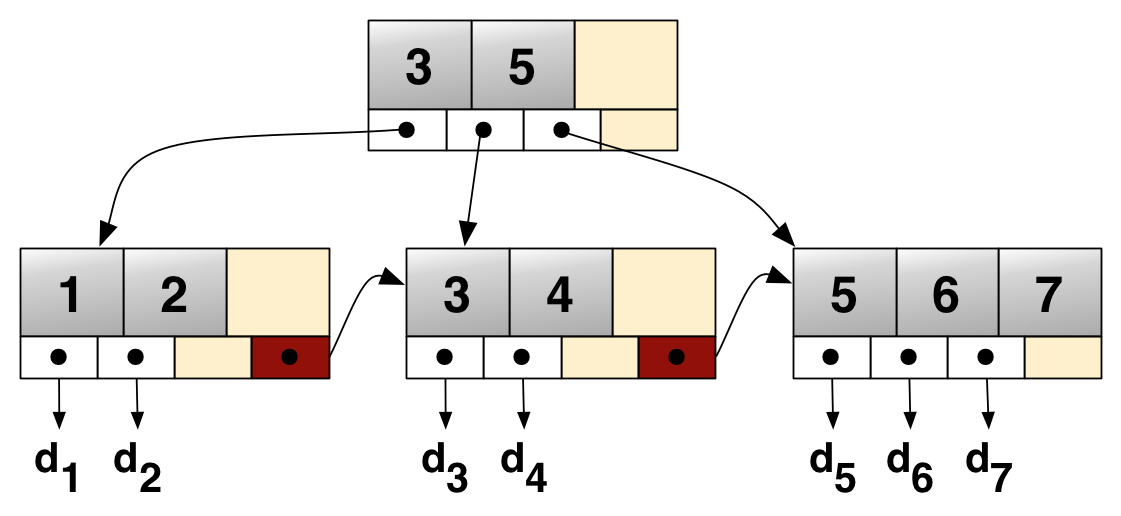
A simple B+ tree example linking the keys 1–7 to data values d1-d7. The linked list (red) allows rapid in-order traversal
Function:search(k) returntree_search(k,root); Function:tree_search(k,node) ifnode isaleaf then returnnode; switchkdo casek<k_0 returntree_search(k,p_0); casek_i≤k<k_{i+1} returntree_search(k,p_{i+1}); casek_d≤k returntree_search(k,p_{d+1});
关于B树的一个性质,一个度为d的B树,设节点为数N,则其树高h的上限为 logd((N+1)/2),检索一个值,其查找节点个数的时间复杂度为O(logdN)。这样使得在B树中检索一个节点最多需要h个节点,而数据库系统 中一般将一个节点的大小设定为一个页,每个节点一次IO。使B树的根节点常驻内存,则一次检索最多需要h-1次的I/O即可。 在集中数据库中采用的B树结构的索引,除了上面平衡树的公共特征外,结合数据库索引使用的需要,都有如下的结构要求。
- 内节点不存储data,只存储key;叶子节点不存储指针。 (oracle 中称为branch blocks 和 leaf blocks ;mssql中称为intermediate level nodes和leaf nodes)。内节点的作用是导航,叶子节点才是存数据data。不同的索引设计类型,叶节点这个data域存储的东西会有不同,导致查询也会不同。在后面会对照着详细介绍。
- 在叶子节点上都会有个双向的指针指向相邻的叶子节点。提高区间访问的性能。
通常在B树上有两个头指针,一个指向根节点,另一个指向关键字最小的叶子节点。因此可以对B树进行两种查找运算:一种是从最小关键字起顺序查找,另一种是从根节点开始,进行随机查找。
三、B树在数据库索引中的几种应用
结合数据库实现对B树结构的不同应用,主要是叶子节点存储的内容不同,我把B树其为两种:一种是叶节点存完整的行数据,一种是叶节点只是存一个指向实际数据行的指针。根据表数据存储格式不同,指针又分为物理指针和逻辑指针。这样B树的结构被我分成了三类:
- B树叶节点存完整数据的索引结构
- B树叶节点存物理指针的索引结构
- B树叶节点存逻辑指针的索引结构
因为几种数据库各自对这这几种种特征的索引的术语不同,其实归类不同。至少命名没有我这么不高大上的。为了讨论方便,且这样分了。
B树叶节点存物理指针的索引结构
这是最普通的一种索引结构。数据插入时时存储位置是随机的,主要是数据库内部块的空闲情况决定。这种表数据的存储结构称为堆表(heap table)(本来heap这个概念就是生成时候分配的)。在堆表(heap table)中记录是无序的,插入速度会比较快。但是查找一个数据会比较麻烦,需要扫描整个堆表才可以。如下图表T是最示意的一个简单表,表上有三列。前 面的十六进制数字仅仅是示意这一行的存储位置。

想想我们需要在表中找出c2=43的行,我们需要从第一行开始,逐行的检查每一行上c2的取值。直到找到第三行找到了。但还是需要扫描接下来的行,因为你不能保证下面在你扫描的前方还有没有另外一个或者多个c2=43的行存在。即几乎都要进行全表的扫描,查找一条记录的时间复杂度是O(N),N为记录行数。想想一个数据量比较大的表,这样的方式几乎是不可以接受的。
于是就有了索引的概念,即另外开辟一个存储结构,按照某个列进行排序,并记录该列每个行每个取值的行在表中的位置。这恐怕是索引最正宗最纯真的意思 了吧。回到我们字典的类比上,想我们的字典目录个某个笔画得到某个字在什么位置,靠的是在目录中存的页码这样一个到实际数据的指针。
因为前面提到的B树的优点,几乎所有的这类索引都采用B树结构。在叶节点上,叶节点的key是存储索引列在每行上的值,而对应的data域保存了该
行的一个引用。也可以理解为指向实际存储数据的指针。
如图中在C2上建立索引,记录按照C2的属性构建B树,并对应的一个指针记录该行数据的存储位置。则查找就是最简单的排序树的检索,前面也介绍过,其时间
复杂度为O(logdN),尽管右下角的堆表上的数据是无序的。同样要找到c2=43的记录行,从索引树上只要经过三个节点即可以找到,并通过指针找到对应的行。 
这是几种数据库中最典型的索引,结构也基本相同。 oracle中直接根据存储结构把这种索引称为B树索引,索引叶节点存储(key: rowid),其中rowid标识了该行的物理存储位置。
The leaf blocks contain every indexed data value and a corresponding rowid used to locate the actual row. Each entry is sorted by (key, rowid). Within a leaf block, a key and rowid is linked to its left and right sibling entries. The leaf blocks themselves are also doubly linked.
对于Mssql来说,当没有创建聚集索引的时候,即表示表是以堆的形式(heap structure)存储。同样叶节点也是存储(key: RID),其中RID指定数据存储物理位置的的行和页。
If the table is a heap, which means it does not have a clustered index, the row locator is a pointer to the row. The pointer is built from the file identifier (ID), page number, and number of the row on the page. The whole pointer is known as a Row ID (RID).
在Mysql中索引结构和表的存储方式都是和存储引擎相关,不同的存储引擎实现不同。两种比较常用的存储引擎中, myisam表上的数据总是按照堆的结果存储的,在myisam上的索引也都是采用上图类似的索引结构。详细点说myisam上的主键索引、唯一索引、辅 助索引都是这种结构。不同的是,主键索引要求选择的索引列是表的主键,唯一索引要求索引列保持取值的唯一性约束,而辅助索引没有这些要求。
B树叶节点存数据的索引结构
B树构造的另外一种索引,与其说是一种索引方式,倒不如说是以一种表数据的存储方式(oracle中就称之为索引组织表(Index-Organized Tables))。 这中结构的一个特点是B树的叶节点中和索引键对应存储的是实际的数据行。即(Key: Row)的结构。即在叶节点上完整的保存了数据行。 如图,在C3上构建索引,则整个表中的数据按照C3的顺序来存储。第一个叶节点上存储了C3=5和C3=25的完整的行,同时整个表按照列C3取值的顺序 在存储。

在oracle中,并不认为该种方式的存储是索引,而是更形象的称为索引组织表(Index-Organized Tables);在mssql中,这种结构正是其所谓的聚集索引(Clustered Index);在mysql中,因为索引属于存储引擎级别的概念,不同存储引擎对索引的实现方式是不同的,在常用的innodb和myisam存储引擎中,只有innodb是支持这种结构的,称之为(clustered index)。 即便三种数据库分别支持这种索引结构,其相互之间还是有些比较tricky的差别,这正是想对照着强调的。
在Oracle的索引组织表(Index-Organized Tables)根据主键排序后的顺序进行排列的,即索引的列必须是表的主键列,在建表的同时要指定主键约束,可以是单字段主键,也可以是复合主键约束。创建索引组织表时,必须要设定主键,否则报错。 引用来自Oracle Database Concepts 对Index-Organized Tables的描述:
An index-organized table is a table stored in a variation of a B-tree index structure. In a heap-organized table, rows are inserted where they fit. In an index-organized table, rows are stored in an index defined on the primary key for the table. Each index entry in the B-tree also stores the non-key column values.
在mysql的innodb的存储引擎中,InnoDB的数据文件本身要按主键聚集,按主键顺序存储。所以InnoDB要求表必须有主键,如果没有 显式指定,则MySQL系统会自动选择一个可以唯一标识数据记录的列作为主键,如果不存在这种列,则MySQL自动为InnoDB表生成一个隐含字段作为 主键,这个字段长度为6个字节,类型为长整形。
引用来自MySQL Manual关于clustered index的描述
- If you define a
PRIMARY KEYon your table,InnoDBuses it as the clustered index.- If you do not define a
PRIMARY KEYfor your table, MySQL picks the firstUNIQUEindex that has onlyNOT NULLcolumns as the primary key andInnoDBuses it as the clustered index.- If the table has no
PRIMARY KEYor suitableUNIQUEindex,InnoDBinternally generates a hidden clustered index on a synthetic column containing row ID values. The rows are ordered by the ID thatInnoDBassigns to the rows in such a table. The row ID is a 6-byte field that increases monotonically as new rows are inserted. Thus, the rows ordered by the row ID are physically in insertion order.
而在mssql中,关于该索引列的要求就没有那么高,并未要求改索引列必须是主键,也不要求该列上必须有唯一性约束。如果表上没有建聚集索引,当在 表上创建主键的时候,mssql会自动在该主键列上创建一个聚集索引。当在没有唯一约束的列上创建聚集索引是,mssql会自动的在重复的键值上添加一个 4 byte的uniqueifier使得该值唯一,这个对用户是透明的。
来自technet.microsoft 的Create Clustered Indexes
When you create a PRIMARY KEY constraint, a unique clustered index on the column or columns is automatically created if a clustered index on the table does not already exist and you do not specify a unique nonclustered index. The primary key column cannot allow NULL values.
B树叶节点存逻辑指针的索引结构
根据前面的描述,当表中数据按照传统堆方式组织的情况时,构造索引(非聚集)的B树的叶节点上上存储(key: rowid)这样的结构,即关联到数据行的物理指针;当数据本身是按照B树存储的时候,数据库认为有了逻辑标示一个行的标签,则叶节点上存储(key:clusterKey)这样的结构,即关联到对应的聚集索引键,聚集索引键扮演了一个逻辑指针。 如图,前面在C3上创建了聚集索引,C1上创建一个非聚集的索引,则在叶节点处存储了每行C3取值对应的聚集索引的键。如第三个叶子节点,C1对应的值为Inter,而对应的聚集索引在该行的值为151. 即通过151这个cluster key 来关联到实际数据行,数据行在另外一个B树上存储着。

因为几种数据库对于聚集索引的要求有细微差别,在存在聚集索引情况下的非聚集索引也相应的有所不同。 在oracle中,该索引称为辅助索引(Secondary Indexes on Index-Organized Tables)。因为oracle的索引组织表(Index-Organized Tables)的索引键必须是主键,则该辅助索引相应管理的是一个代表了主键的逻辑rowid。
As explained in “Rowid Data Types”, Oracle Database uses row identifiers called logical rowids for index-organized tables. A logical rowid is a base64-encoded representation of the table primary key. The logical rowid length depends on the primary key length.
在mysql的Innodb中,和oracle几乎完全相同,这种索引也称为辅助索引( secondary indexes)。因为其聚集索引列也是要求必须是主键,相应辅助索引关联的也是对应的主键。
引用来自MySQL Manual关于clustered index的描述
All indexes other than the clustered index are known as secondary indexes. In
InnoDB, each record in a secondary index contains the primary key columns for the row, as well as the columns specified for the secondary index.InnoDBuses this primary key value to search for the row in the clustered index.
在mssql中,这种索引称为非聚集索引(Nonclustered Index)。 在B树的页节点上存储索引列和聚集索引对应聚集索引键(clustered index key)。上面讨论聚集索引的时候说到过,mssql的聚集索引的列不要求唯一性,也不要求是主键。但是非聚集索引中为了能通过聚集索引键唯一定位到一行 数据,在重复的聚集索引键上会添加一个唯一标示来使得其唯一。

如上图在C3上有重复的值,按照mysql和oracle的要求,在该列上是不能创建聚集索引的,但是在mssql中,在该列上可以建聚集索引,在另外一列上的非聚集索引和聚集索引的关联如图。

保证C1上创建的非聚集索引的每一行数据都能通过聚集索引key唯一关联到聚集索引上某数据行上。 来自msdn的 no-clustered index
If the table has a clustered index, or the index is on an indexed view, the row locator is the clustered index key for the row. If the clustered index is not a unique index, SQL Server makes any duplicate keys unique by adding an internally generated value called a uniqueifier. This four-byte value is not visible to users. It is only added when required to make the clustered key unique for use in nonclustered indexes. SQL Server retrieves the data row by searching the clustered index using the clustered index key stored in the leaf row of the nonclustered index.
四、总结
整理一个列表更直观的表达其对照,会发现大部分都是相同的,除了术语上,或者某些约定限制的程度上。因为原理是一样的。因为结构相同,造成使用也是完全相同。如
- 根据聚集索引的检索方式;
- 有聚集索引的非聚集索引检索方式;
- 没有聚集索引的非聚集索引检索方式
|
数据库(存储引擎)/比较项目 |
oracle |
mssql |
mysql(innodb) |
mysql(myisam) |
|
|---|---|---|---|---|---|
|
表数据B树存储方式(聚集索引存在) |
支持表数据B树存储 |
Yes |
Yes |
Yes |
NO |
|
表数据B树存储名称 |
索引组织表(Index-Organized Tables) |
聚集索引(主键索引)clustered index |
不支持 |
||
|
聚集索引键要求 |
必须是主键 |
没有主键要求,也没有唯一性要求 |
必须是主键 |
不支持 |
|
|
B树叶节点结构 |
(Key:ROW) 索引key和整行数据 |
(Key:ROW) 索引key和整行数据 |
(Key:ROW) 索引key和整行数据 |
不支持 |
|
|
根据聚集索引访问数据行 |
聚集索引B树上检索聚集索引键,找到索引叶节点即访问到正行数据 |
聚集索引B树上检索聚集索引键,找到索引叶节点即访问到正行数据 |
聚集索引B树上检索聚集索引键,找到索引叶节点即访问到正行数据 |
不支持 |
|
|
索引(非聚集)名称 |
辅助索引 |
非聚集索引 |
辅助索引 |
不支持 |
|
|
索引(非聚集)B树叶节点结构 |
(Key:ClusterKey) 索引(非聚集)键和聚集索引键的对应关系。 |
(Key:ClusterKey) 索引(非聚集)键和,聚集索引键的对应关系。 |
(Key:ClusterKey) 索引(非聚集)键和,聚集索引键的对应关系。 |
不支持 |
|
|
根据索引(非聚集)访问数据行 |
1.检索索引(非聚集)B树定位到索引行所在叶节点,得到索引键对应的聚集索引键 2. 在聚集索引B树上检索聚集索引键,即访问到数据行 |
1.检索索引(非聚集)B树定位到索引行所在叶节点,得到索引键对应的聚集索引键 2. 在聚集索引B树上检索聚集索引键,即访问到数据行 |
1.检索索引(非聚集)B树定位到索引行所在叶节点,得到索引键对应的聚集索引键 2. 在聚集索引B树上检索聚集索引键,即访问到数据行 |
不支持 |
|
|
表数据堆存储方式heap structure (聚集索引不存在) |
索引(非聚集)名称 |
B树索引 |
非聚集索引 |
不支持 |
主键索引、唯一索引、辅助索引 |
|
索引(非聚集)B树叶节点结构 |
(Key:ROWID) 索引(非聚集)键和行存储物理位置 |
(Key:ROWID) 索引(非聚集)键和行存储物理位置 |
不支持 |
(Key:ROWID) 索引(非聚集)键和行存储物理位置 |
|
|
根据索引(非聚集)访问数据行 |
1. 从索引(非聚集)定位到索引行所在叶节点,即得到数据行的物理存储位置 2.直接根据物理存储位置从堆上访问数据行 |
1. 从索引(非聚集)定位到索引行所在叶节点,即得到数据行的物理存储位置 2.直接根据物理存储位置从堆上访问数据行 |
不支持 |
1. 从索引(非聚集)定位到索引行所在叶节点,即得到数据行的物理存储位置 2.直接根据物理存储位置从堆上访问数据行 |
|
再根据原理多分析一点,不是使用建议,只是这种结构提示给我们的信息。只说it is ,不说you should。
知道了聚集索引实现原理后,应该能理解为什么mysql的innodb不建议长字段做索引,mssql不大建议在长字段上面建聚集索引。因为所有辅 助索引都引用主索引,过长的主索引会令辅助索引变得过大。 聚集索引因为索引按照某个列在组织,如果在该列上的查找,包括范围查找会比较高效。因为数据组织有了约束,写入性能下降,插入/删除/更新聚集键值等,会 导致记录的物理移动、页拆分等额外的磁盘操作。同时其他非聚集的索引读数据时候,如果不能从其索引上未包含全部的查询列,需要关联表来查询,则会有两次查 询,一次是从非聚集索引上定位到聚集索引键,然后再从聚集索引键查到数据。
较之非聚集的索引,数据存储方式只有一种,聚集索引也就只能有一个,也就显得相对珍贵些。一般选择会要比较慎重些。知道了这些原理后,对于到底要不 要建聚集索引,其实就是选择以B树的形式组织表数据还是以堆表的方式组织表数据;如果决定是以B树的方式组织数据,到底在根据哪个列来创建B树,组织表数 据;其他的应该在哪些列上创建索引,也就不难回答。另外可以结合使用场景结合试验结果来做出满足要求的决策。
五、附录Database System Concepts 关于索引的一个介绍
原创文章。为了维护文章的版本一致、最新、可追溯,转载请注明: 转载自idouba
本文链接地址: B树在数据库索引中的应用剖析
posted on 2014-04-08 15:54 idouba.net 阅读(982) 评论(0) 编辑 收藏 举报

