
MapReduce学习
是计算向数据靠拢。
•MapReduce将复杂的、运行于大规模集群上的并行计算过程高度地抽象到了两个函数:Map和Reduce
MapReduce采用“分而治之”策略,一个存储在分布式文件系统中的大规模数据集,会被切分成许多独立的分片(split),这些分片可以被多个Map任务并行处理
MapReduce框架采用了Master/Slave架构,包括一个Master和若干个Slave。Master上运行JobTracker,Slave上运行TaskTracker


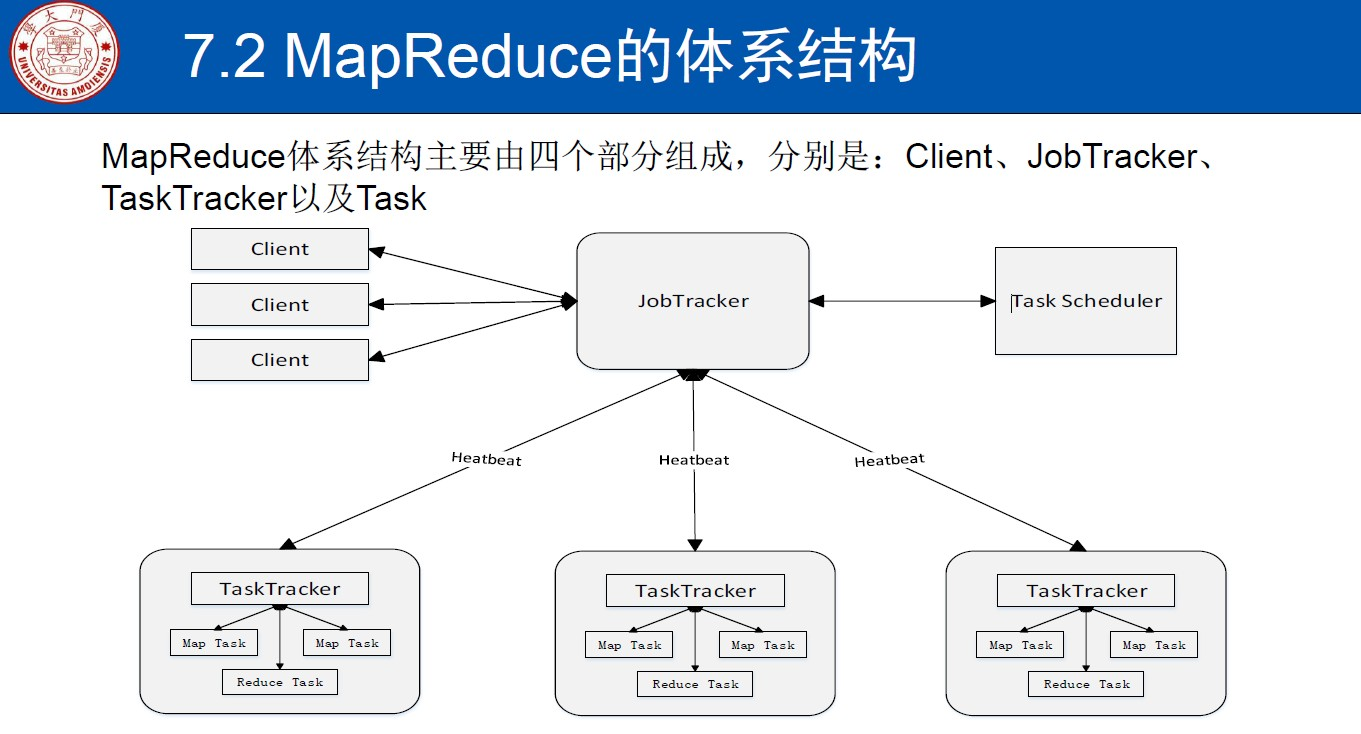
主要分为四部分:
1)客户端Client:
- 用户编写的MapReduce程序通过Client提交到JobTracker端
- 用户可通过Client提供的一些接口查看作业运行状态
2)作业跟踪器JobTracker:
- JobTracker负责资源监控和作业调度
- JobTracker监控所有TaskTracker与Job的健康状况,一旦发现失败,就将相应的任务转移到其他节点
- JobTracker会跟踪任务的执行进度、资源使用量等信息,并将这些信息告诉任务调度器(TaskScheduler),而调度器会在资源出现空闲时,选择合适的任务去使用这些资源
TaskScheduler负责具体的任务调度了,将任务分配到有空闲资源的TaskTracker去执行。
3)TaskTracker
•TaskTracker 会周期性地通过“心跳”将本节点上资源的使用情况和任务的运行进度汇报给JobTracker,同时接收JobTracker 发送过来的命令并执行相应的操作(如启动新任务、杀死任务等)
•TaskTracker 使用“slot”等量划分本节点上的资源量(CPU、内存等)。一个Task 获取到一个slot 后才有机会运行,而Hadoop调度器的作用就是将各个TaskTracker上的空闲slot分配给Task使用。
slot 分为Map slot 和Reduce slot 两种,分别供MapTask 和Reduce Task 使用
4)Task
Task 分为Map Task 和Reduce Task 两种,均由TaskTracker 启动
