
Tesseract-OCR4.0识别中文与训练字库实例
关于中文的识别,效果比较好而且开源的应该就是Tesseract-OCR了,所以自己亲身试用一下,分享到博客让有同样兴趣的人少走弯路。
文中所用到的身份证图片资源是百度找的,如有侵权可联系我删除。
一、准备工作
1、下载Tesseract-OCR引擎,注意要3.0以上才支持中文哦,按照提示安装就行。
最后下载4.0版本
2、下载chi_sim.traindata字库。要有这个才能识别中文。下好后,放到Tesseract-OCR项目的tessdata文件夹里面。
https://github.com/tesseract-ocr/tessdata/blob/master/chi_sim.traineddata
3、下载jTessBoxEditor,这个是用来训练字库的。
https://sourceforge.net/projects/vietocr/files/jTessBoxEditor/jTessBoxEditor-1.7.3.zip/download
- 为了识别方便建议放到环境变量中.
二、识别
1、进入cmd,进入到要识别的图片的路径下。
-解决bug
出现了这个错误. 下面的意思就是说不能加载’eng’语言包。请将tessdata的父文件夹路径设置为TESSDATA_PREFIX环境变量值,这个就是说在环境变量中新建一个系统变量,变量名称为TESSDATA_PREFIX,tessdata是放置语言包的文件夹,一般在你安装tesseract的目录下,即tesseract的安装目录就是tessdata的父目录,把TESSDATA_PREFIX的值设置为它就行了

2、输入命令
tesseract 图片名称 生成的结果文件的名称 字库
例如我的图片识别就是:
tesseract test.jpg result -l chi_sim

识别完后会生成result.txt文件

三、训练
1、将图片转换成tif格式,用于后面生成box文件。可以通过画图,然后另存为tif即可。
更改图片名字,这个是有要求的=。=
tif文面命名格式[lang].[fontname].exp[num].tif
lang是语言 fontname是字体
比如我们要训练自定义字库 mjorcen字体名normal
那么我们把图片文件重命名 mjorcen.normal.exp0.jpg在转tif。
2、生成box文件。
tesseract mjorcen.normal.exp0.jpg mjorcen.normal.exp0 -l chi_sim batch.nochop makebox
box文件和对应的tif一定要在相同的目录下,不然后面打不开。
3、打开jTessBoxEditor矫正错误并训练
打开train.bat

找到tif图,打开,并校正。切换到图片所指的路径
出现乱码 这是因为你软件设置字体的问题
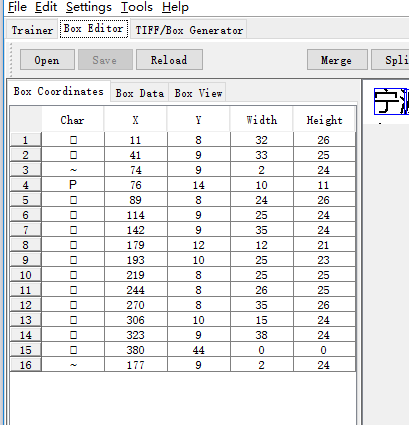
在setting>font 设置中文字体
进行矫正 主要就是坐标 位置的调整,注意 添加需要选择上一个文字才能分离


